基于知识蒸馏的去雪、去雾、去雨算法
今天来详细学习一篇去雪、去雨、去雾三合一的去噪算法
代码地址:
https://github.com/fingerk28/Two-stage-Knowledge-For-Multiple-Adverse-Weather-Removal
论文地址:
https://openaccess.thecvf.com/content/CVPR2022/papers/Chen_Learning_Multiple_Adverse_Weather_Removal_via_Two-Stage_Knowledge_Learning_and_CVPR_2022_paper.pdf
前言
当下的去雪、去雨、去雾算法主要存在以下问题:
- 只能对单一恶劣天气进行去除,无法应用于真实环境
- 能够完成多种恶劣天气去除的算法模型十分复杂,不利于部署
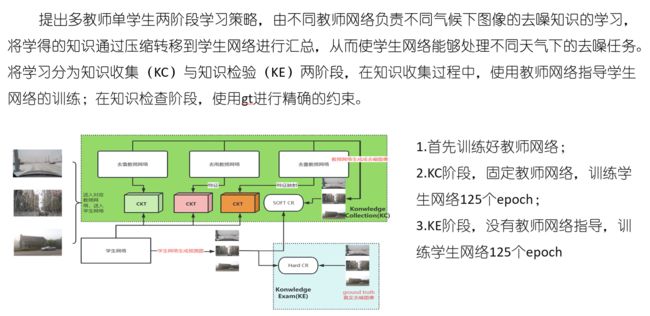
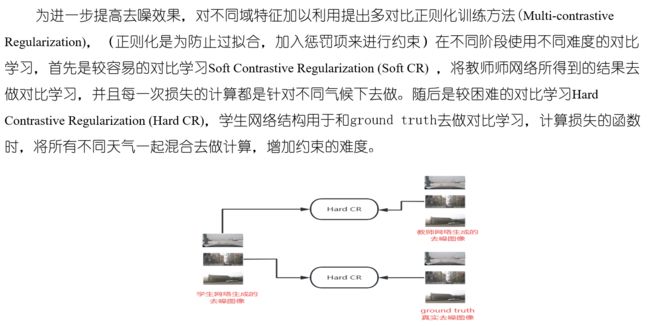
针对以上问题,提出基于知识蒸馏的多合一去雪、去雨、去雾算法,构建多教师单学生的学习网络,分别由多个教师网络负责不同恶劣天气的去噪任务,随后将学到的知识进行迁移到学生网络,进而使学生网络在保证模型体积足够小的同时还能拥有媲美教师网络的性能。
其结构图总览如下:
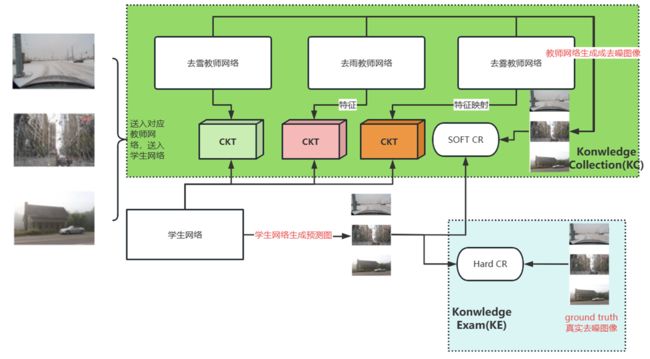
作者原图:
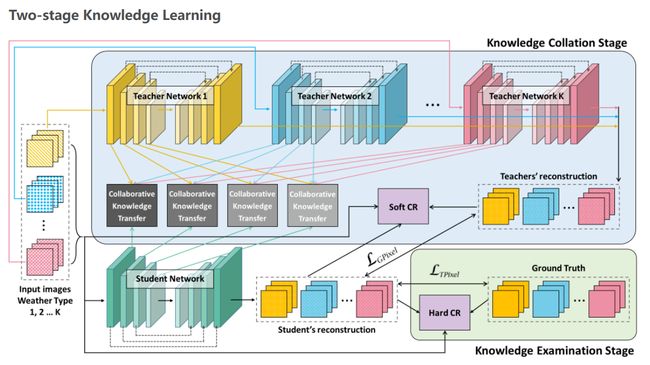
创新点概述
1.多教师单学生的两阶段学习策略
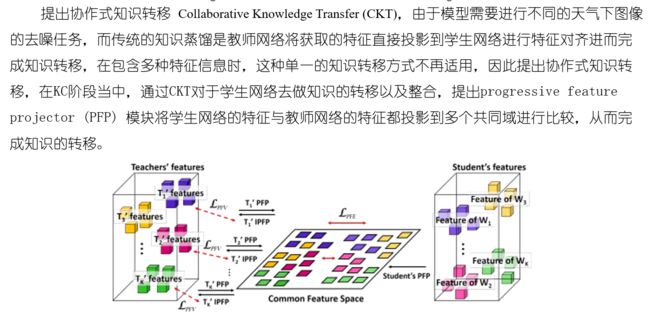
2.协作知识迁移模型
3.多对比正则化训练策略

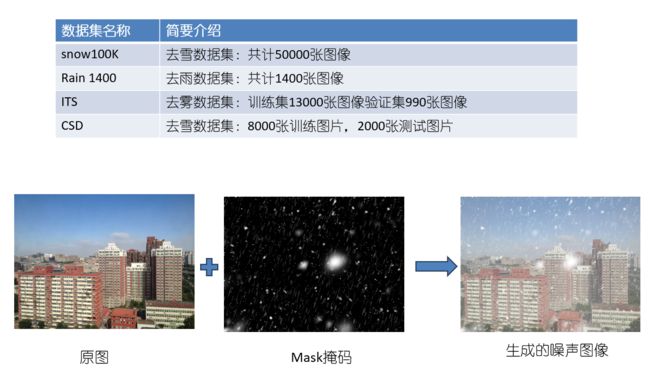
实验数据集
代码讲解
从结构上来看,其代码并不复杂,主要分为model(模型文件),utils(配置文件,包含数据集加载与评价),weights(权重文件,包含三个教师网络的预训练权重与一个学生网络的训练结果),train.py与inference.py
训练主体
初始化配置参数
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, default='models.MSBDN-RDFF.Net')
parser.add_argument('--dataset_train', type=str, default='utils.dataset.DatasetForTrain')
parser.add_argument('--dataset_valid', type=str, default='utils.dataset.DatasetForValid')
parser.add_argument('--meta_train', type=str, default='./meta/train/')
parser.add_argument('--meta_valid', type=str, default='./meta/valid/')
parser.add_argument('--save-dir', type=str, default="outputs")
parser.add_argument('--max-epoch', type=int, default=25)
parser.add_argument('--warmup-epochs', type=int, default=3)
parser.add_argument('--lr', type=float, default=2e-4)
parser.add_argument('--lr-min', type=float, default=1e-6)
parser.add_argument('--batch-size', type=int, default=32)
parser.add_argument('--num_workers', type=int, default=0)
parser.add_argument('--top-k', type=int, default=3)
parser.add_argument('--val-freq', type=int, default=2)
parser.add_argument('--teachers', default="weights/CSD-teacher.pth weights/Rain1400-teacher weights/ITS-OTS-teacher",type=str, nargs='+')
args = parser.parse_args()
writer = SummaryWriter(os.path.join(args.save_dir, 'log'))
设置随机种子,保证程序复现
# Set up random seed
random_seed = 19870522
torch.manual_seed(random_seed)
torch.cuda.manual_seed(random_seed)
np.random.seed(random_seed)
random.seed(random_seed)
print(Back.WHITE + 'Random Seed: {}'.format(random_seed) + Style.RESET_ALL)
print(Fore.RED + "---------------------------------------------------------------" + Style.RESET_ALL)
获取网络模型与数据集
# get the net and datasets function
net_func = get_func(args.model)
dataset_train_func = get_func(args.dataset_train)
dataset_valid_func = get_func(args.dataset_valid)
具体get_func方法,以生成model为例
def get_func(path):
module = path[:path.rfind('.')]#str.rfind(str, beg=0, end=len(string))
model_name = path[path.rfind('.') + 1:]
mod = importlib.import_module(module)#导入对象
net_func = getattr(mod, model_name)#getattr() 函数用于返回一个对象属性值。获取model.MSBDN的Net属性,即生成Net
return net_func
加载教师网络权重
# load teacher models
teacher_networks = []
for checkpoint_path in args.teachers:
checkpoint = torch.load(checkpoint_path)
teacher = net_func().cuda()
teacher.load_state_dict(checkpoint['state_dict'], strict=True)
teacher_networks.append(teacher)
加载数据集相关配置
# load meta files
meta_train_paths = sorted(glob(os.path.join(args.meta_train, '*.json')))
meta_valid_paths = sorted(glob(os.path.join(args.meta_valid, '*.json')))
# prepare the dataloader
train_dataset = dataset_train_func(meta_paths=meta_train_paths)
val_dataset = dataset_valid_func(meta_paths=meta_valid_paths)
train_loader = DataLoader(dataset=train_dataset, num_workers=args.num_workers, batch_size=args.batch_size,
drop_last=True, shuffle=True, collate_fn=Collate(n_degrades=len(teacher_networks)))
val_loader = DataLoader(dataset=val_dataset, num_workers=args.num_workers, batch_size=1, drop_last=False, shuffle=False)
生成CKT知识迁移模块
# Prepare the CKT modules
ckt_modules = nn.ModuleList([])
for c in [64, 128, 256, 256]:
ckt_modules.append(CKTModule(channel_t=c, channel_s=c, channel_h=c//2, n_teachers=len(teacher_networks)))
ckt_modules = ckt_modules.cuda()
损失函数,即多对比正则化训练策略设计
# prepare the loss function
criterions = nn.ModuleList([nn.L1Loss(), SCRLoss(), HCRLoss()]).cuda()
# prepare the optimizer and scheduler
linear_scaled_lr = args.lr * args.batch_size / 16
optimizer = torch.optim.Adam([{'params': model.parameters()}, {'params': ckt_modules.parameters()}],
lr=linear_scaled_lr, betas=(0.9, 0.999), eps=1e-8)
scheduler_cosine = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, args.max_epoch - args.warmup_epochs, eta_min=args.lr_min)
scheduler = GradualWarmupScheduler(optimizer, multiplier=1, total_epoch=args.warmup_epochs, after_scheduler=scheduler_cosine)
scheduler.step()
开启两阶段训练,分为前125epoch的知识收集阶段,后125epoch的知识验证阶段
for epoch in range(start_epoch, args.max_epoch + 1):
# training
if epoch <= 125:
train_kc_stage(model, teacher_networks, ckt_modules, train_loader, optimizer, scheduler, epoch, criterions)
else:
train_ke_stage(model, train_loader, optimizer, scheduler, epoch, criterions)
# validating
if epoch % args.val_freq == 0:
psnr, ssim = evaluate(model, val_loader, epoch)
# Check whether the model is top-k model
top_k_state = save_top_k(model, optimizer, scheduler, top_k_state, args.top_k, epoch, args.save_dir, psnr=psnr, ssim=ssim)
torch.save({'epoch': epoch, 'state_dict': model.state_dict(), 'ckt_module': ckt_modules.state_dict(),
'optimizer': optimizer.state_dict(), 'scheduler': scheduler.state_dict()},
os.path.join(args.save_dir, 'latest_model'))
评估模块
评估代码不进行梯度更新,且开启eval模式可以大幅减小显存占用
@torch.no_grad()
def evaluate(model, val_loader, epoch):
print(Fore.GREEN + "==> Evaluating")
print("==> Epoch {}/{}".format(epoch, args.max_epoch))
psnr_list, ssim_list = [], []
model.eval()
start = time.time()
pBar = tqdm(val_loader, desc='Evaluating')
for target, image in pBar:
if torch.cuda.is_available():
image = image.cuda()
target = target.cuda()
pred = model(image)
psnr_list.append(torchPSNR(pred, target).item())
ssim_list.append(pytorch_ssim.ssim(pred, target).item())
print("\nResults")
print("------------------")
print("PSNR: {:.3f}".format(np.mean(psnr_list)))
print("SSIM: {:.3f}".format(np.mean(psnr_list)))
print("------------------")
print('Costing time: {:.3f}'.format((time.time()-start)/60))
print('Current time:', time.strftime("%H:%M:%S", time.localtime()))
print(Fore.RED + "---------------------------------------------------------------" + Style.RESET_ALL)
global writer
writer.add_scalars('PSNR', {'val psnr': np.mean(psnr_list)}, epoch)
writer.add_scalars('SSIM', {'val ssim': np.mean(ssim_list)}, epoch)
return np.mean(psnr_list), np.mean(ssim_list)
知识收集阶段训练KC
def train_kc_stage(model, teacher_networks, ckt_modules, train_loader, optimizer, scheduler, epoch, criterions):
print(Fore.CYAN + "==> Training Stage 1")
print("==> Epoch {}/{}".format(epoch, args.max_epoch))
print("==> Learning Rate = {:.6f}".format(optimizer.param_groups[0]['lr']))
meters = get_meter(num_meters=5)
criterion_l1, criterion_scr, _ = criterions
model.train()
ckt_modules.train()
for teacher_network in teacher_networks:
teacher_network.eval()
start = time.time()
pBar = tqdm(train_loader, desc='Training')
for target_images, input_images in pBar:
# Check whether the batch contains all types of degraded data
if target_images is None: continue
# move to GPU
target_images = target_images.cuda()
input_images = [images.cuda() for images in input_images]
# Fix all teachers and collect reconstruction results and features from cooresponding teacher
preds_from_teachers = []
features_from_each_teachers = []
with torch.no_grad():
for i in range(len(teacher_networks)):
preds, features = teacher_networks[i](input_images[i], return_feat=True)
preds_from_teachers.append(preds)
features_from_each_teachers.append(features)
preds_from_teachers = torch.cat(preds_from_teachers)
features_from_teachers = []
for layer in range(len(features_from_each_teachers[0])):
features_from_teachers.append([features_from_each_teachers[i][layer] for i in range(len(teacher_networks))])
preds_from_student, features_from_student = model(torch.cat(input_images), return_feat=True)
# Project the features to common feature space and calculate the loss
PFE_loss, PFV_loss = 0., 0.
for i, (s_features, t_features) in enumerate(zip(features_from_student, features_from_teachers)):
t_proj_features, t_recons_features, s_proj_features = ckt_modules[i](t_features, s_features)
PFE_loss += criterion_l1(s_proj_features, torch.cat(t_proj_features))
PFV_loss += 0.05 * criterion_l1(torch.cat(t_recons_features), torch.cat(t_features))
T_loss = criterion_l1(preds_from_student, preds_from_teachers)
SCR_loss = 0.1 * criterion_scr(preds_from_student, target_images, torch.cat(input_images))
total_loss = T_loss + PFE_loss + PFV_loss + SCR_loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
meters = update_meter(meters, [total_loss.item(), T_loss.item(), PFE_loss.item(),
PFV_loss.item(), SCR_loss.item()])
pBar.set_postfix({'loss': '{:.3f}'.format(meters[0].avg)})
print("\nResults")
print("------------------")
print("Total loss: {:.3f}".format(meters[0].avg))
print("------------------")
print('Costing time: {:.3f}'.format((time.time()-start)/60))
print('Current time:', time.strftime("%H:%M:%S", time.localtime()))
print(Fore.RED + "---------------------------------------------------------------" + Style.RESET_ALL)
global writer
writer.add_scalars('loss', {'train total loss': meters[0].avg}, epoch)
writer.add_scalars('loss', {'train T loss': meters[1].avg}, epoch)
writer.add_scalars('loss', {'train PFE loss': meters[2].avg}, epoch)
writer.add_scalars('loss', {'train PFV loss': meters[3].avg}, epoch)
writer.add_scalars('loss', {'train SCR loss': meters[4].avg}, epoch)
writer.add_scalars('lr', {'Model lr': optimizer.param_groups[0]['lr']}, epoch)
writer.add_scalars('lr', {'CKT lr': optimizer.param_groups[1]['lr']}, epoch)
scheduler.step()
知识检验阶段训练KE
def train_ke_stage(model, train_loader, optimizer, scheduler, epoch, criterions):
start = time.time()
print(Fore.CYAN + "==> Training Stage2")
print("==> Epoch {}/{}".format(epoch, args.max_epoch))
print("==> Learning Rate = {:.6f}".format(optimizer.param_groups[0]['lr']))
meters = get_meter(num_meters=3)
criterion_l1, _, criterion_hcr = criterions
model.train()
pBar = tqdm(train_loader, desc='Training')
for target_images, input_images in pBar:
# Check whether the batch contains all types of degraded data
if target_images is None: continue
# move to GPU
target_images = target_images.cuda()
input_images = torch.cat(input_images).cuda()
preds = model(input_images, return_feat=False)
G_loss = criterion_l1(preds, target_images)
HCR_loss = 0.2 * criterion_hcr(preds, target_images, input_images)
total_loss = G_loss + HCR_loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
meters = update_meter(meters, [total_loss.item(), G_loss.item(), HCR_loss.item()])
pBar.set_postfix({'loss': '{:.3f}'.format(meters[0].avg)})
print("\nResults")
print("------------------")
print("Total loss: {:.3f}".format(meters[0].avg))
print("------------------")
print('Costing time: {:.3f}'.format((time.time()-start)/60))
print('Current time:', time.strftime("%H:%M:%S", time.localtime()))
print(Fore.RED + "---------------------------------------------------------------" + Style.RESET_ALL)
global writer
writer.add_scalars('loss', {'train total loss': meters[0].avg}, epoch)
writer.add_scalars('loss', {'train G loss': meters[1].avg}, epoch)
writer.add_scalars('loss', {'train HCR loss': meters[2].avg}, epoch)
writer.add_scalars('lr', {'Model lr': optimizer.param_groups[0]['lr']}, epoch)
scheduler.step()
model模型结构
其中,MSBDN即为:Multi-Scale Boosted Dehazing Network,它是一个去雾主干网络,这里用其作为骨干网络
协同知识迁移模块
class CKTModule(nn.Module):
def __init__(self, channel_t, channel_s, channel_h, n_teachers):
super().__init__()
self.teacher_projectors = TeacherProjectors(channel_t, channel_h, n_teachers)
self.student_projector = StudentProjector(channel_s, channel_h)
def forward(self, teacher_features, student_feature):
teacher_projected_feature, teacher_reconstructed_feature = self.teacher_projectors(teacher_features)
student_projected_feature = self.student_projector(student_feature)
return teacher_projected_feature, teacher_reconstructed_feature, student_projected_feature
多对比正则化训练
硬对比
class SCRLoss(nn.Module):
def __init__(self):
super().__init__()
self.vgg = Vgg19().cuda()
self.l1 = nn.L1Loss()
self.weights = [1.0/32, 1.0/16, 1.0/8, 1.0/4, 1.0]
def forward(self, a, p, n):
a_vgg, p_vgg, n_vgg = self.vgg(a), self.vgg(p), self.vgg(n)
loss = 0
d_ap, d_an = 0, 0
for i in range(len(a_vgg)):
d_ap = self.l1(a_vgg[i], p_vgg[i].detach())
d_an = self.l1(a_vgg[i], n_vgg[i].detach())
contrastive = d_ap / (d_an + 1e-7)
loss += self.weights[i] * contrastive
return loss
软对比
class HCRLoss(nn.Module):
def __init__(self):
super().__init__()
self.vgg = Vgg19().cuda()
self.l1 = nn.L1Loss()
self.weights = [1.0/32, 1.0/16, 1.0/8, 1.0/4, 1.0]
def forward(self, a, p, n):
a_vgg, p_vgg, n_vgg = self.vgg(a), self.vgg(p), self.vgg(n)
loss = 0
d_ap, d_an = 0, 0
for i in range(len(a_vgg)):
b, c, h, w = a_vgg[i].shape
d_ap = self.l1(a_vgg[i], p_vgg[i].detach())
# a_vgg[i].unsqueeze(1).expand(b, b, c, h, w): a_vgg[i][0, 0] == a_vgg[i][0, 1] == a_vgg[i][0, 2]...
# n_vgg[i].expand(b, b, c, h, w): a_vgg[i][0] == a_vgg[i][1] == a_vgg[i][2]..., but a_vgg[i][0, 0] != a_vgg[i][0, 1]
d_an = self.l1(a_vgg[i].unsqueeze(1).expand(b, b, c, h, w), n_vgg[i].expand(b, b, c, h, w).detach())
contrastive = d_ap / (d_an + 1e-7)
loss += self.weights[i] * contrastive
return loss