现代数据基础架构的新兴体系结构
在过去一年中,几乎所有关键行业指标都创下了历史新高,新产品类别的出现速度超过了大多数数据团队能够合理跟踪的速度。本文中发布一组数据基础架构。他们展示了当前分析和操作系统中最好的相关组件。
一、参考架构
所有数据基础架构用例的统一概览:

| 数据源 | 归集和转换 | 存储 | 分析和处理 | 转换 | 分析和输出 |
| 生成相关业务和可运行的数据 | 1)从现有业务系统中抽取数据 2)传输到存储,源和目标之间的对齐方案(L) 3)传输分析数据回所需业务系统 |
将数据存储在查询和处理系统可访问的格式中。 优化数据一致性,性能表现,降低成本和规模 |
转换高频代码(sql,python,java,scala)为低维护水平的数据处理作业。 使用分布式计算执行查询和数据模型 纳入历史分析和预测分析两方面分析 |
转换数据为结构化可供分析的数据 为数据转换架构规划处理资源 |
为决策者或者数据分析科学加提供洞察,合作的一系列接口 展示结果 在用户应用中嵌入数据模型 |
放大了机器学习以后的架构设计:

| 数据转换 | 模型训练及开发 | 模型接口 | 一体化 |
| 转换粗数据为模型训练可用数据,包含监督学习打标签等工作 | 根据处理后的数据训练模型-通常构建在公共数据语料库上预先训练的模型的本体 跟踪实验和模型训练过程,包括输入数据、使用的超功率计和 最终模型性能 作为迭代循环的一部分,分析、验证和审计模型性能,通常导致再培训和/或额外的数据收集和处理 通过编译到相关硬件目标并存储以便在推理阶段访问,准备用于部署的训练模型 |
根据输入数据实时(在线)或批量(离线)执行训练模型 监控生产模型的数据漂移、有害预测、性能下降等。 |
以结构化和可重复的方式将模型输出集成到面向用户的应用程序中 |
分析生态系统和操作生态系统都继续蓬勃发展。Snowflake等云数据仓库发展迅速,主要集中于SQL用户和商业智能用例。但其他技术的采用也加快了——例如,Databricks等数据仓库比以往任何时候都更快地增加了客户。与我们交谈的许多数据团队证实,异构性很可能会留在数据堆栈中。
其他核心数据系统(即摄取和转换)也被证明同样耐用。这在现代商业智能模式中尤其明显,Fivetran和dbt(或类似技术)的结合几乎无处不在。但这在某种程度上也适用于操作系统,其中出现了Databricks/Spark、Confluent/Kafka和Astronomer/Airflow等事实上的标准。
蓝图1:现代商业智能应用
为各种规模的公司提供云原生商业智能

什么没有改变:
数据复制(如Fivetran)、云数据仓库(如Snowflake)和基于SQL的数据建模(使用dbt)的组合继续构成了这种模式的核心。这些技术的采用有意义地增长,促使新竞争对手(如Airbyte和Firebolt)的资金和早期增长。
仪表板仍然是输出层中最常用的应用程序,包括Looker、Tableau、PowerBI和Superset等新进入者。
新增功能:
度量层(一个在数据仓库之上提供标准定义集的系统)引起了人们的极大兴趣。这已经引起了激烈的争论,包括它应该拥有什么功能、哪个供应商应该拥有它,以及它应该遵循什么规范。到目前为止,我们已经看到了几个可靠的纯游戏产品(如Transform和Supergrain),以及dbt在这一类别中的扩展。
反向ETL供应商已经有了显著的增长,特别是Hightouch和Census。这些产品的目的是利用数据仓库中的输出和见解更新运营系统,如CRM或ERP。
数据团队对新应用程序表现出更强的兴趣,以增强其标准仪表板,尤其是数据工作区(如Hex)。从广义上讲,新应用很可能是云数据仓库标准化程度不断提高的结果——一旦数据结构清晰且易于访问,数据团队自然会想利用它做更多的工作。
数据发现和可观测性公司激增,并筹集了大量资金(特别是蒙特卡洛和Bigeye)。虽然这些产品的好处很明显,即更可靠的数据管道和更好的协作,但随着客户发现相关的用例和预算,采用这些产品还相对较早。(技术说明:尽管在数据发现方面有几个可靠的新供应商,例如Select Star、隐喻、Stemma、Secoda、Castor,但我们已将种子阶段公司排除在图表之外。)
蓝图2:多模式数据处理
支持分析和操作用例的演进数据湖——也称为Hadoop难民的现代基础设施

较亮的框是新的或有意义的更改;浅色的盒子基本上保持不变。灰色框被认为与此蓝图不太相关。
什么没有改变:
数据处理(如Databricks、Starburst和Dremio)、传输(如Confluent和Airflow)和存储(AWS)的核心系统继续快速增长,并构成了这一蓝图的支柱。
多模式数据处理在设计上保持多样性,允许公司在分析和运营数据应用中采用最适合其特定需求的系统。
新增功能:
人们对数据湖的基础架构的认可度和清晰度越来越高。我们看到了广泛的供应商(包括AWS、Databricks、Google Cloud、Starburst和Dremio)和数据仓库先驱支持的这种方法。lakehouse的基本价值是将一个强大的存储层与一系列强大的数据处理引擎(如Spark、Presto、Druid/Clickhouse、Python库等)相结合。
存储层本身正在升级。虽然Delta、Iceberg和Hudi等技术不是新技术,但它们正在加速被采用,并被构建为商业产品。其中一些技术(尤其是冰山)还与Snowflake等云数据仓库互操作。如果异质性继续存在,这可能会成为多模式数据堆栈的关键部分。
流处理(即实时分析数据处理)的采用率可能会上升。虽然Flink等第一代技术还没有成为主流,但具有更简单编程模型(如Materialize和Upsolver)的新进入者正在获得早期采用,而且,有趣的是,来自现有Databricks和Confluent的流处理产品的使用也开始加速。
蓝图3:人工智能和机器学习
用于机器学习模型的健壮开发、测试和操作的架构
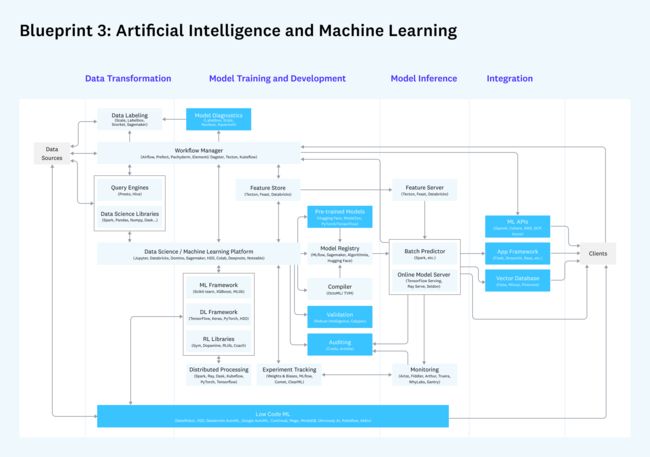
什么没有改变:
与2020年相比,如今用于模型开发的工具大体类似,包括主要的云供应商(如Databricks和AWS)、ML框架(如XGBoost和PyTorch)以及实验管理工具(如Weights&Biases和Comet)
实验管理已经有效地将模型可视化和调优归为独立的类别。
构建和操作机器学习堆栈非常复杂,需要专业知识。这个蓝图不适合胆小的人,而人工智能的产品化对许多数据团队来说仍然是一个挑战。
新增功能:
ML行业正在围绕以数据为中心的方法进行整合,强调复杂的数据管理而不是增量建模改进。这有几个含义:
数据标签(如Scale和Labelbox)的快速增长,以及对闭环数据引擎的兴趣日益增长,主要是基于特斯拉的Autopilot数据管道。
在批处理和实时用例中,功能商店(如Tecton)的采用率提高,这是以协作方式开发生产级ML数据的一种方式。
重新激发了对低代码ML解决方案(如Continuous和MindsDB)的兴趣,这些解决方案至少部分自动化了ML建模过程。这些更新的解决方案专注于将新用户(即分析师和软件开发人员)带入ML市场。
使用预先训练的模型正在成为默认,尤其是在NLP中,并为OpenAI和拥抱脸等公司提供了顺风顺水。围绕微调、成本和扩展,仍有一些有意义的问题需要解决。
ML的操作工具(有时称为MLops)正在变得更加成熟,它是围绕ML监控构建的,是最有需求的用例和即时预算。与此同时,一系列新的运营工具——尤其是验证和审计——正在出现,最终市场仍有待确定。
人们越来越关注开发人员如何将ML模型无缝集成到应用程序中,包括通过预先构建的API(例如OpenAI)、向量数据库(例如Pinecone)和更具见解的框架。