实时采集Canal快速入门
目录
目录
目录
一. 简介
1. CDC是什么
2. CDC的使用场景有哪些?
3. 目前CDC的技术分类
基于查询的 CDC实现:
基于日志的 CDC:
4. Canal工作原理:
二 组件简介:
1. 组件canal-server
2.instance模块:
3. 主要参数介绍:
需要自己决定的必配项
2. 建议开启的可优化配置参数
三.快速入门示例:
四. 组件canal-adapt
配置介绍:
一. 简介
canal是一种面向 数据库 的实时CDC(change data capture)技术。
1. CDC是什么
CDC是(change data capture),翻译过来就是 捕获数据变更。通常数据处理上,我们说的 CDC 技术主要面向 数据库的变更,是一种用于捕获数据库中数据变更的技术。
2. CDC的使用场景有哪些?
- 数据同步, 用于备份容灾
- 数据分发,一个数据源分发给多个下游存储( mysql, kafka, rabbitMQ, rocketMQ, ElasticSearch,Hbase等)
- 数据采集,面向数据仓库 / 数据湖 的ETL数据集成
3. 目前CDC的技术分类
根据实现机制可以分为两个方向,基于查询和基于日志。
- 基于查询是就是select进行全表扫描过滤出变更的数据。
- 基于日志就是连续实时读取数据库的操作log,例如msyql的binlog
-
基于查询的 CDC实现:
离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据
缺点:
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
-
无法保障实时性,基于离线调度存在天然的延迟。
-
影响数据库性能
-
基于日志的 CDC:
实时消费日志,流处理。例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
特点:
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
- 对数据库影响小。由于它是读取binlog,对数据库或者业务来说,都不是侵入式的。

FlinkCDC入门demo可以参考我的另一篇: FlinkCDC同步Mysql
4. Canal工作原理:
canal是基于日志的CDC,实时性高,对数据库性能影响小(canal官网介绍大概有1%的影响)
它是连续实时读取mysql数据库的操作log(binlog)并解析发送到下游。大概过程如下
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)

目前支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x、
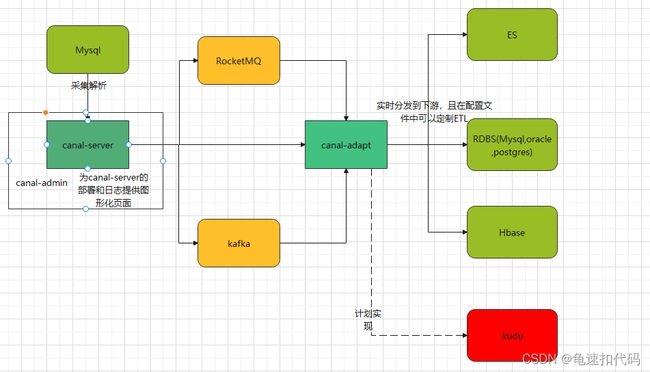
二 组件简介:
- canal-server,采集源数据库的binlog,并发送到配置的目的存储。或者发送到指定的tcp端口等待客户端消费。。
- canal-adapt,集成的canal-client端。可以实现数据同步和ETL功能。消费上游组件(包括canal-server,kafka,TCP)。同步到目的存储(包括关系型数据库(mysql,postgresql,oracle),ES,Hbase)。且可全量同步源数据库到目标存储系统(但不建议使用全量同步,我实践中全量同步Mysql到mysql时通常会发生锁获取失败)。
- canal-admin,提供webUI, 方便canal-server集群部署和日志查看
将上图的细化
1. 组件canal-server
架构:它负责采集数据库的binlog,并发送到配置的存储。那么它怎么采集多个数据库,发送到不同的存储地。它是由instance配置决定的。下图是canal-server的架构图,一个server可以有多个instance,每个instance对应着一个数据队列

2.instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
总结来说就是,instance决定去哪里采集binlong,采集后怎么处理,存储,分发到不同地方。并将消费binlog的文件,消费的位置等元数据保存下来。
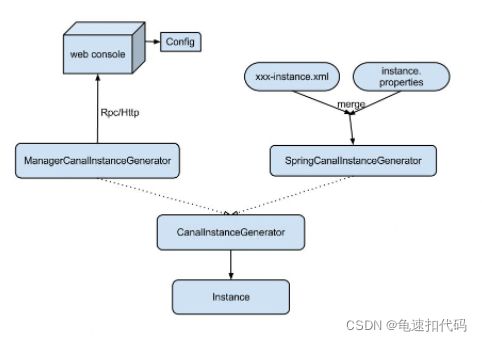
它的配置的管理方式有两种
- 一种是基于manager的管理方式,要自己是实现canalconfigclient然后接入自己的管理系统
- 另外一种是基于本地的spring.xml的spring配置方式。一般都用这种,这种配置方式包含了两种配置文件,xxx-instance.xml 和 instance.properties
感兴趣想深挖的可以查看官方文档:canal简介 , canal参数介绍
3. 主要参数介绍:
每个instance的构建,都由2个配置文件决定。canal.properties和自己的instance.properties。
通常将所有instance通用的配置放到 canal.properties
- 数据分发存储技术,TCP,Kafka,RocketMQ,RabbitsMQ等
- 存储地址(TCP的端口, kafka,rocketMQ 集群的地址)
- 存储技术相关的配置,比如kafka的事务,是否开启压缩
- 是否配置canal-admin
各自的instance的 instance.properties
- 采集的数据库地址
- 采集时使用的用户名和密码
- 采集的过滤分发策略
-
需要自己决定的必配项
canal.properties
| canal.destinations |
当前server上部署的instance列表 |
| canal.serverMode |
canal-server的分发模式,TCP, kafka,RocketMQ,RabbitsMQ。 默认是 TCP |
| canal.port |
TCP 端口,默认值 11111 |
| canal.zkServers |
若搭建HA 集群,必须配置 zk集群地址 |
| canal.mq.transaction |
是否开启队列的事务 |
| kafka.bootstrap.servers |
kafka集群地址 |
| kafka.acks |
ack模式 |
instance.properties
| canal.instance.mysql.slaveId |
伪装成 mysql slave的编号,确保唯一。不能重复 |
| canal.instance.master.address |
采集目标数据库的地址 IP:port |
| canal.instance.dbUsername |
采集用的用户名 |
| canal.instance.dbPassword |
对应的密码 |
| canal.instance.filter.regex |
采集的目标 数据库和表名,可以使用简单的正则表达式。采集整库,多个库,一个库的多个表等 |
| canal.instance.filter.black.regex |
采集过滤掉哪些库和表 |
| canal.mq.topic |
分发的目的地是kafka。这是兜底的topic |
| canal.mq.dynamicTopic |
动态的决定哪些表发到哪些topic |
| canal.mq.partitionsNum |
存放的partiton数量 |
| canal.mq.partitionHash |
动态分发的话,发往partition的规则。按库有序,按表有序,按主键有序 |
2. 建议开启的可优化配置参数
canal.properties
| canal.auto.scan |
开启自动扫描配置文件,开启后canal会自动扫描目录下的instance目录。修改了的配置,会动态加载; 目录少了的就会删掉相应的instance。多了就新增, |
| canal.auto.scan.interval |
扫描的周期,单位是 秒 |
| canal.instance.filter.query.dcl |
是否过滤数据控制语言,建议开启 |
| canal.instance.filter.query.ddl |
是否过滤数据定义语言,建议开启 |
三.快速入门示例:
canal实时采集同步mysql到kafka为例
-
开启mysql的binlog,并设置模式为 row 模式
先查看是否开启,默认是不开启show variables like 'log_bin';
若是off,则没有开启。修改配置文件 my.ini 后重启mysql, 修改内容如下log-bin=mysql-bin # 开启 binlog binlog-format=ROW # 选择 ROW 模式 server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复,本文单机版的。 -
创建一个canal同步使用的mysql用户,并授权SELECT, REPLICATION SLAVE, REPLICATION CLIENT (最低要求)
CREATE USER [用户名]IDENTIFIED BY [密码]'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON [数据库.表] TO '[用户名]'@'%'; -- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ; FLUSH PRIVILEGES;以用户名为canal,密码也是canal,并授权当前地址的所有库表为例
CREATE USER canal IDENTIFIED BY 'canal'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; -- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ; FLUSH PRIVILEGES; -
配置canal.propertes。
告知canal-server,采集下游是kafka,kafka地址,并开启kafka事务# canal采集存放的组件,本次采用kafka canal.serverMode = kafka # 开启 kafka的事务 canal.mq.transaction = true # kafka集群的地址 kafka.bootstrap.servers = 20.20.20.41:9092,20.20.20.42:9092,20.20.20.43:9092,20.20.20.44:9092 -
配置 instance.properties
告知 采集链接信息( Mysql的地址,用户密码),到kafka的策略(单/多topic,单/多partition)
在conf目录下新建一个目录,例子: kafkaExample。
并拷贝example中的instance.properties到我们自己的instance目录(kafkaExample)
编辑kafkaExample/instance.properties
mkdir -p /opt/canal/conf/kafkaExample cp /opt/canal/conf/example/instance.properties /opt/canal/conf/kafkaExample vi /opt/canal/conf/kafkaExample/instance.properties############### 告知采集数据库的信息 #################### # 伪装成 mysql slave的编号,确保唯一 canal.instance.mysql.slaveId=1235 # 采集的 目标数据库的地址 , 本例是 L3线的投放日志库 canal.instance.master.address=117.48.195.167:30042 # 采集的用户名 canal.instance.dbUsername=canal # 采集的用户密码 canal.instance.dbPassword=xxxxxxxx ############# 告知如何存放 kafka ######################## # 采集的目标 数据库和表名, 本例 库名是 skyeye_ad_log,表名是模糊匹配 log_use_click_<日期> canal.instance.filter.regex=skyeye_ad_log\\.log_user_click_.*,skyeye_ad_log\\.log_app_login_.*,skyeye_ad_log\\.log_report_callback_.* # 采集 哪些数据表 到 哪个topic, 本例都是采集到 一个topic canal.mq.dynamicTopic=adServingL3:skyeye_ad_log\\.log_user_click_.*;adServingL3:skyeye_ad_log\\.log_app_login_.*;adServingL3:skyeye_ad_log\\.log_report_callback_.* # 存放在 多少个分区,本例是 所有的分区,topic的分区为12个,提高并发 canal.mq.partitionsNum=12 # 分区的策略, 本例是 安装 表的主键值来进行分区投递,保证不会有数据热点,同时保证同一个id的操作记录是有序的 canal.mq.partitionHash=.*\\..*:$pk$canal.instance.filter.regex: 相当于总开关,采集哪些数据库和表。 中间使用 逗号分隔 ' , ' 可以使用正则匹配。
canal.mq.dynamicTopic: 动态决定哪些表的数据到哪个 topic。决定是否 单topic,中间用 分号 “ ;”隔开。
canal.mq.partitionsNum: 配合dynamicTopic,决定存放多少个分区中。
canal.mq.partitionHash: 如果是多分区,如何将数据分发到 不同分区。可以按照 表级别 分发到分区,也可以按照 主键级 分发。
canal.mq.topic: 兜底topic, 即总开关 如果进来的有,表1,表2,表3. 动态dynamicTopic决定了表1,表2分发到指定的topic 1, topic2.。 那么剩下的 表3,则存放到 兜底topic。kafka分发的灵活性
-
启动canal
sh /opt/canal/bin/startup.sh -
测试
新建一张表,是在上述的配置内。然后操作表内数据,增删改。观察kafka是否采集到
四. 组件canal-adapt
适配同步落地功能
- 客户端启动器
- 同步管理REST接口
- 日志适配器, 作为DEMO
- 关系型数据库的数据同步(表对表同步), ETL功能
- HBase的数据同步(表对表同步), ETL功能
- ElasticSearch多表数据同步,ETL功能
-
配置介绍:
通用的配置文件 application.yaml
定义配置
- canal地址
- 采集的源地址(源数据库)
- 目标适配器类型(关系型数据库,ES, HBase) 以及地址
- 适配器采集通路的分组
canal.conf:
canalServerHost: 127.0.0.1:11111 # 对应单机模式下的canal server的ip:port
zookeeperHosts: slave1:2181 # 对应集群模式下的zk地址, 如果配置了canalServerHost, 则以canalServerHost为准
mqServers: slave1:6667 #or rocketmq # kafka或rocketMQ地址, 与canalServerHost不能并存
flatMessage: true # 扁平message开关, 是否以json字符串形式投递数据, 仅在kafka/rocketMQ模式下有效
batchSize: 50 # 每次获取数据的批大小, 单位为K
syncBatchSize: 1000 # 每次同步的批数量
retries: 0 # 重试次数, -1为无限重试
timeout: # 同步超时时间, 单位毫秒
mode: tcp # kafka rocketMQ # canal client的模式: tcp kafka rocketMQ
srcDataSources: # 源数据库
defaultDS: # 自定义名称
url: jdbc:mysql://127.0.0.1:3306/mytest?useUnicode=true # jdbc url
username: root # jdbc 账号
password: 121212 # jdbc 密码
canalAdapters: # 适配器列表
- instance: example # canal 实例名或者 MQ topic 名
groups: # 分组列表
- groupId: g1 # 分组id, 如果是MQ模式将用到该值
outerAdapters: # 分组内适配器列表
- name: logger # 日志打印适配器
......
- name: rdb # 关系型数据库 适配器
key: oracle1 # 指定adapter的唯一key, 与表映射配置中outerAdapterKey对应
properties:
jdbc.driverClassName: oracle.jdbc.OracleDriver # jdbc驱动名, 部分jdbc的jar包需要自行放致lib目录下
jdbc.url: jdbc:oracle:thin:@localhost:49161:XE # 目标数据库 jdbc url
jdbc.username: mytest # jdbc username
jdbc.password: m121212 # jdbc password
threads: 5
- name: hbase # Hbase 适配器
properties:
hbase.zookeeper.quorum: 127.0.0.1
hbase.zookeeper.property.clientPort: 2181
zookeeper.znode.parent: /hbase
- name:
key: exampleKey # ES 适配器
name: es6 # or es7
hosts: 127.0.0.1:9300 # es 集群地址, 逗号分隔
properties:
mode: transport # or rest # 可指定transport模式或者rest模式
# security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch # es cluster name关系型数据库映射文件的配置
- 对应application的 哪个 适配器( group 和 key)
- 对应的 映射文件, 同步的 目的库和表,同步的字段。
- DDL,DML是否同步
修改conf/rdb/ 下的文件
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
destination: example # cannal的instance或者MQ的topic
groupId: # 对应MQ模式下的 groupId, 只会同步对应groupId的数据
outerAdapterKey: oracle1 # adapter key, 对应上面配置outAdapters中的key
concurrent: true # 是否按主键hash并行同步, 并行同步的表必须保证主键不会更改及主键不能为其他同步表的外键!!
dbMapping:
database: mytest # 源数据源的database/shcema
table: user # 源数据源表名
targetTable: mytest.tb_user # 目标数据源的库名.表名
targetPk: # 主键映射
id: id # 如果是复合主键可以换行映射多个,前面的是源表,后面的是目的表。区分大小写
# mapAll: true # 是否整表映射, 要求源表和目标表字段名一模一样 (如果targetColumns也配置了映射,则以targetColumns配置为准)
targetColumns: # 字段映射, 格式: 目标表字段: 源表字段, 如果字段名一样源表字段名可不填
id:
name:
role_id:
c_time:
test1: DDL和 DML的同步
文件跟上面的一致
dataSourceKey: defaultDS
destination: example
outerAdapterKey: mysql1
concurrent: true
dbMapping:
mirrorDb: true
database: mytest 源库和目标库的 schema(库名) 要一模一样