5.4 文本处理
这里主要介绍常见分词和词云的制作方法。
无论是英文文本还是中文文本,都可以把它们看成是由很多词语组成的句子。通常处理文本的第一步就是需要进行分词,也就是从句子中拆分出各个词语。
对于英文文本,不同的词语一般空格分隔,因此分词比较简单:
strs = 'to be or not to be'
print(strs.split())
输出为:['to', 'be', 'or', 'not', 'to', 'be']
而对于中文文本,不同的词语之间没有天然的分隔符:

因此需要一些第三方的模块来处理,比如jieba模块。
首先需要导入jieba模块,可以在PyCharm中选择File-Settings,在项目解释器(Project Interpreter)中点击最右边的加号按钮:
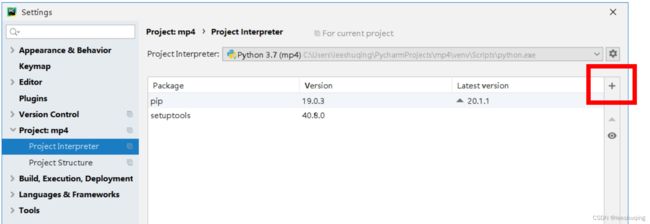
然后在搜索框中输入jieba,即可点击左下角的安装包(Install Package)完成安装。
代码为:
import jieba
strs = '南京市长江大桥欢迎你'
print(jieba.lcut(strs))
输出为:['南京市', '长江大桥', '欢迎', '你']
这是jieba模块提供的lcut精确模式。它同时还有其他模式,如全模式:
import jieba
strs = '南京市长江大桥欢迎你'
print(jieba.lcut(strs, cut_all=True))
输出为:['南京', '南京市', '京市', '市长', '长江', '长江大桥', '大桥', '欢迎', '你']
还有折中模式:
import jieba
strs = '南京市长江大桥欢迎你'
print(jieba.lcut_for_search(strs))
输出为:['南京', '京市', '南京市', '长江', '大桥', '长江大桥', '欢迎', '你']
大家可以通过这些不同的输出观察各自的效果。这里没有哪种好哪种不好的说法,关键要根据分词后的处理要求来选择。
有了分词后,就可以完成词云制作。词云都很多制作方法,这里介绍wordcloud模块(安装过程同jieba):
import jieba
import wordcloud
strs = '南京市长江大桥欢迎你'
words = jieba.lcut(strs)
words = ' '.join(words)
wc = wordcloud.WordCloud(font_path="msyh.ttc")
wc.generate(words)
wc.to_file("img.png")
首先解释下代码:
1)第五行将第四行分词后的各个词语列表元素使用join方法拼接成了一个新的字符串,不妨来专门来看下这个方法的使用:
import jieba
strs = '南京市长江大桥欢迎你'
words = jieba.lcut(strs)
words = ' '.join(words)
print(words)
输出为:南京市 长江大桥 欢迎 你。
可以看出,join的意思就是将当前字符串空格作为连接符,去连接参数列表中的所有字符串元素,形成一个完整字符串。最后的效果类似于英文文本,也使用空格分隔了不同的词语。只有这样的文本,才能作为wordcloud模块制作词云的原始文本。因此,wordcloud其实原本就是为了适合英文词云处理的,为此中文文本才需要这样的空格连接处理。
2)第六行是设置词云,其中必须要指定中文字体(通过中文字体文件名称),否则会出现乱码。常见的中文字体文件为:
微软雅黑 msyh.ttc
宋体 simsun.ttc
楷体 simkai.ttf
黑体 simhei.ttf
3)最后两行是生成词云。请注意,生成的词云是一张图片,位于当前项目的文件夹中,因此你可以在PyCharm项目中看到这张图片:
双击即可查看:

默认的词云都是方形,因此可以设置不同的图片外观,形成多变的词云效果,比如有这个图片:

相应的代码修改为:
import jieba
import wordcloud
import matplotlib.pyplot as plt
strs = '南京市长江大桥欢迎你'
words = jieba.lcut(strs)
words = ' '.join(words)
img = plt.imread('heart.jpg') # 加载图片
wc = wordcloud.WordCloud(background_color='white', font_path="msyh.ttc", mask=img) # 设置生成图片的形状
wc.generate(words)
wc.to_file("img.png")
其中增加了新的加载图片的模块matplotlib,同时利用该模块的imread方法读取图片,并将读取的图片作为mask参数值设置了词云。效果为:

这里的词云效果似乎还很一般,一般词语越多,整体词云越接近所需要的形状。

同时,这些效果都是动态生成,每次运行结果可能都不一样。
配套学习资源、慕课视频:
Python大数据分析-李树青 https://www.njcie.com/python/
https://www.njcie.com/python/