MySQL常用窗口函数
1、窗口函数概念
窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。简单的说窗口函数就是对于查询的每一行,都使用与该行相关的行进行计算。
窗口函数也叫OLAP函数(Online Analytical Processing,联机分析处理),可以对数据进行实时分析处理。窗口函数和group by有类似之处,其区别在于窗口会对每个分组之后的数据进行分别操作,而group by一般对分组之后的函数使用聚集函数汇总。
2.窗口函数和普通聚合函数的区别
①聚合函数是将多条记录聚合为一条;窗口函数是每条记录都会执行,有几条记录执行完还是几条。
②聚合函数也可以用于窗口函数。
3、窗口函数用法
<窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>)
<窗口函数> 的位置,可以放以下两种函数:
1) 专用窗口函数,包括后面要讲到的 rank, dense_rank, row_number 等专用窗口函数。
2) 聚合函数,如 sum, avg, count, max, min 等
需要强调的一点是:窗口函数是对 where 或者 group by 子句处理后的结果进行操作,所以窗口函数原则上只能写在 select 子句中。
MySQL常用窗口函数
| No | 名称 | 描述 |
| 1 | CUME_DIST() | 累积分配值 |
| 2 | PERCENT_RANK() | 排名值的百分比 |
| 3 | FIRST_VALUE() | 指定区间范围内的第一行的值 |
| 4 | LAG() | 取排在当前行之前的值 |
| 5 | LAST_VALUE() | 指定区间范围内的最后一行的值 |
| 6 | LEAD() | 取排在当前行之后的值 |
| 7 | NTH_VALUE() | 指定区间范围内第N行的值 |
| 8 | NTILE() | 将数据分到N个桶,当前行所在的桶号 |
| 9 | DENSE_RANK() | 当前行在其分区中的排名,稠密排序 |
| 10 | RANK() | 当前行在其分区中的排名,稀疏排序 |
| 11 | ROW_NUMBER() | 分区内当前行的行号 |
下面我们通过具体的表来验证各个窗口函数的区别及效果
Create table If Not Exists Employee (id int, name varchar(255), salary int, departmentId int)
Create table If Not Exists Department (id int, name varchar(255))
Truncate table Employee
insert into Employee (id, name, salary, departmentId) values ('1', 'Joe', '85000', '1')
insert into Employee (id, name, salary, departmentId) values ('2', 'Henry', '80000', '2')
insert into Employee (id, name, salary, departmentId) values ('3', 'Sam', '60000', '2')
insert into Employee (id, name, salary, departmentId) values ('4', 'Max', '90000', '1')
insert into Employee (id, name, salary, departmentId) values ('5', 'Janet', '69000', '1')
insert into Employee (id, name, salary, departmentId) values ('6', 'Randy', '85000', '1')
insert into Employee (id, name, salary, departmentId) values ('7', 'Will', '70000', '1')
Truncate table Department
insert into Department (id, name) values ('1', 'IT')
insert into Department (id, name) values ('2', 'Sales') 
1、row_number() over(partition by字段1 order by 字段2) 的结果是每一行记录生成一个序号,依次排序且排序的序号不会重复
SELECT
ROW_NUMBER() OVER (partition by DepartmentId order by Salary desc) AS ranking,
DepartmentId, Name, Salary
FROM employee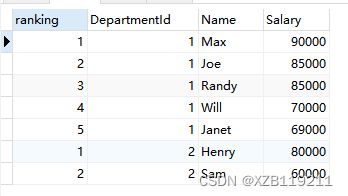
2、rank() over(partition by字段1 order by 字段2) 的结果会考虑排序字段值相同的情况,若排序字段的值相同则其序号是一样的,后续不同字段值的序号为(前一行序号+N,其中N为前一个字段值重复的行数),比如 1 1 3 4 4 4 7
SELECT
RANK() OVER (partition by DepartmentId order by Salary desc) AS ranking,
DepartmentId, Name, Salary
FROM employee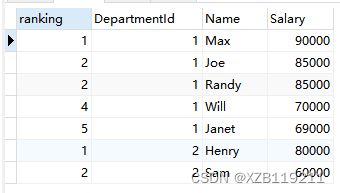
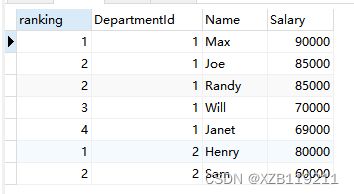
3、 dense_rank() over(partition by字段1 order by 字段2) 的结果也会考虑排序字段值相同的情况,即排序字段的值相同那么他们的序号是一样的,但是与rank() 的区别是后续不同字段值的序号为(前一行序号+1),比如 1 1 2 2 3 4 5
4、PERCENT_RANK() over(partition by字段1 order by 字段2) 的结果是排名制所占的百分比
SELECT
PERCENT_RANK() OVER (partition by DepartmentId order by Salary desc) AS ranking,
DepartmentId, Name, Salary
FROM employee