c++笔记
目录
- C++基础
-
- 变量前加*和加&的区别
-
- *介绍
- &介绍
- 内联函数
- 引用变量
- 引用参数
- 左值、右值和左值引用、右值引用
- 结构体
- 排序算法
-
- 归并排序
- 快速排序
- 二叉树遍历(先序、中序、后序)
- 函数
-
- 最大公约数 最小公倍数
- 位运算符
- 排序sort()
- C++ STL vector添加元素(push_back()和emplace_back())
- auto
- 上下取整
- 求和函数accumulate
- isupper()判断字符类型
- 幂指数pow()
- 交换数值swap()
- 最大、最小整数
- 截取字符串
- 向量迭代器vector::iterator it
- 二分查找函数 lower_bound()、upper_bound()
- Lambda表达式
-
- 捕获外部变量
- 数据结构
-
- 补码
- bitset位操作
- 数组vector
- 二维数组
-
- 初始化
- 遍历
- pair
- 栈、队列、优先级队列、链表
-
- 栈、队列、优先级队列、链表的相关操作:
- 优先级队列
-
- 重载运算符
- 哈希表
-
- [C++ set与map、unordered_map、unordered_set与哈希表](https://blog.csdn.net/qq_30815237/article/details/91047041)
- 字符串
- 链表
-
- 使用构造函数初始化结点
- 创建链表
- 遍历链表
- 链表尾部插入值
- 算法
-
- 字符串匹配KMP算法
C++基础
变量前加*和加&的区别
*介绍
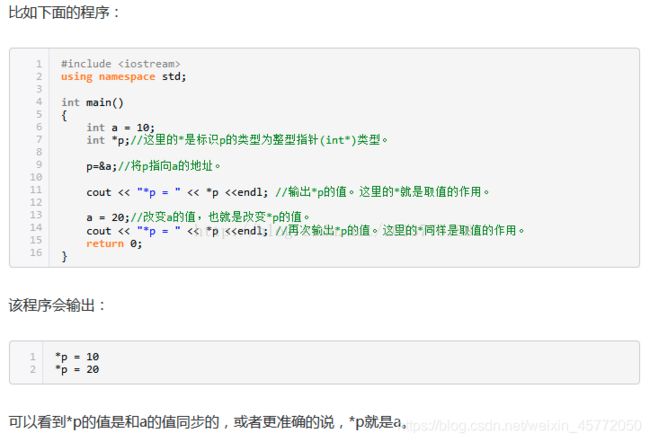
变量前加号,只有在变量为指针情况下才是合法的
当用于定义时,是标明该变量为指针类型
除此以外,*的作用是取值。
C++中的指针可以理解为一个地址的值,*用于取值时就是取出该地址中存储的值
&介绍
&:一个是取地址符作用,另一个是引用
 注意:&是取址符号。但&也可以有另一个用法,就是是其它变量的别名,如int &a=b;此时a就是b,b就是a,改变a的值也就改变了b的值。但声明时必须初始化,不能空声明,如:int &a是错的,int &a = b则可以
注意:&是取址符号。但&也可以有另一个用法,就是是其它变量的别名,如int &a=b;此时a就是b,b就是a,改变a的值也就改变了b的值。但声明时必须初始化,不能空声明,如:int &a是错的,int &a = b则可以
内联函数
内联函数inline:引入内联函数的目的是为了解决程序中函数调用的效率问题,这么说吧,程序在编译器编译的时候,编译器将程序中出现的内联函数的调用表达式用内联函数的函数体进行替换,而对于其他的函数,都是在运行时候才被替代。这其实就是个空间换时间。所以内联函数一般都是1-5行的小函数。在使用内联函数时要留神:
1.在内联函数内不允许使用循环语句和开关语句;
2.内联函数的定义必须出现在内联函数第一次调用之前;
3.类结构中所在的类说明内部定义的函数是内联函数。
引用变量
int rats=101;
int & rodents=rats;
int *prats=&rats;
- 指针与引用的区别:
表达式rodents和prats都可以同rats互换,表达式&rodents和prats都可以同&rats互换。从这一点来说,引用看上去像伪装的指针。
区别:必须在声明引用时将其初始化。
引用更接近const指针,必须在创建时进行初始化,一旦与某个变量关联起来,就一直效忠于它。也就是说 int & rodents=rats;实际上是int * const pr=&rats;的伪装表示。其中,引用rodents扮演的角色与表达式pr相同。
引用参数
-
临时变量、引用参数和const
1)函数引用的实参不能为表达式或类型不同的变量。
2)在引用变量形参前加const,编译器在下面两种情况下生成临时变量:
实参类型正确,但不是左值;
实参类型不正确,但可以转换为正确的类型。 -
将引用参数声明为常量数据的引用的理由:
1)可以避免无意中修改数据
2)使函数能够处理const和非const实参,否则只能接受非const数据
3)使函数能够正确声明并使用临时变量 -
使用引用参数的原因
1)能够修改调用函数中的数据对象
2)提高程序运行速度 -
何时使用引用参数
1)如果数据对象很小,按值传递
2)如果数据对象是数组,只能使用指针
3)如果数据对象是结构,则使用引用或指针
4)如果数据对象是类对象,则使用引用
左值、右值和左值引用、右值引用
左值和右值:
C++中左值(lvalue)和右值(rvalue)是比较基础的概念,虽然平常几乎用不到,但C++11之后变得十分重要,它是理解 move/forward 等新语义的基础。
左值与右值这两个概念是从 C 中传承而来的,左值指既能够出现在等号左边,也能出现在等号右边的变量;右值则是只能出现在等号右边的变量。
int a; // a 为左值
a = 3; // 3 为右值
- 左值是可寻址的变量,有持久性;
- 右值一般是不可寻址的常量,或在表达式求值过程中创建的无名临时对象,短暂性的。
左值和右值主要的区别之一是左值可以被修改,而右值不能。
左值引用和右值引用:
- 左值引用:引用一个对象;
- 右值引用:就是必须绑定到右值的引用,C++11中右值引用可以实现“移动语义”,通过 && 获得右值引用。
int x = 6; // x是左值,6是右值
int &y = x; // 左值引用,y引用x
int &z1 = x * 6; // 错误,x*6是一个右值
const int &z2 = x * 6; // 正确,可以将一个const引用绑定到一个右值
int &&z3 = x * 6; // 正确,右值引用
int &&z4 = x; // 错误,x是一个左值
右值引用和相关的移动语义是C++11标准中引入的最强大的特性之一,通过std::move()可以避免无谓的复制,提高程序性能。
结构体
struct node{
int data;
string str;
char x;
//注意构造函数最后这里没有分号哦!
node() :x(), str(), data(){} //无参数的构造函数数组初始化时调用
node(int a, string b, char c) :data(a), str(b), x(c){}//有参构造
};
排序算法
归并排序
两种方法:
递归法(Top-down)
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针到达序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
迭代法(Bottom-up) - 将序列每相邻两个数字进行归并操作,形成ceil(n/2)个序列,排序后每个序列包含两/一个元素
- 若此时序列数不是1个则将上述序列再次归并,形成ceil(n/4)个序列,每个序列包含四/三个元素
- 重复步骤2,直到所有元素排序完毕,即序列数为1
快速排序
排序算法的思想非常简单,在待排序的数列中,我们首先要找一个数字作为基准数(这只是个专用名词)。为了方便,我们一般选择第 1 个数字作为基准数(其实选择第几个并没有关系)。接下来我们需要把这个待排序的数列中小于基准数的元素移动到待排序的数列的左边,把大于基准数的元素移动到待排序的数列的右边。这时,左右两个分区的元素就相对有序了;接着把两个分区的元素分别按照上面两种方法继续对每个分区找出基准数,然后移动,直到各个分区只有一个数时为止。
这是典型的分治思想,即分治法。
二叉树遍历(先序、中序、后序)
- 先序:考察到一个节点后,即刻输出该节点的值,并继续遍历其左右子树。(根左右)
- 中序:考察到一个节点后,将其暂存,遍历完左子树后,再输出该节点的值,然后遍历右子树。(左根右)
- 后序:考察到一个节点后,将其暂存,遍历完左右子树后,再输出该节点的值。(左右根)
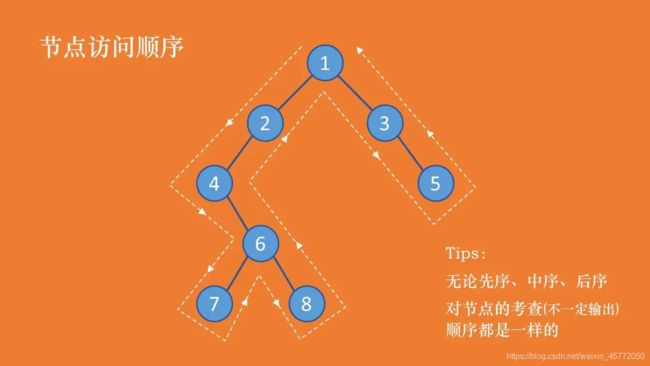
先序:1 2 4 6 7 8 3 5
中序:4 7 6 8 2 1 3 5
后序:7 8 6 4 2 5 3 1
函数
最大公约数 最小公倍数
#include 位运算符
位运算符作用于位,并逐位执行操作。&、 | 和 ^ 的真值表如下所示:
| p | q | p & q | p|q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
^运算可用于找唯一数:对于一个元素为整数的数列,其中只有一个数只出现过一次,其他的数都是出现两次,要求找到并输出那唯一一个数。
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 如果同时存在于两个操作数中,二进制 AND 运算符复制一位到结果中。 | (A & B) 将得到 12,即为 0000 1100 |
| | | 如果存在于任一操作数中,二进制 OR 运算符复制一位到结果中。 | (A | B) 将得到 61,即为 0011 1101 |
| ^ | 如果存在于其中一个操作数中但不同时存在于两个操作数中,二进制异或运算符复制一位到结果中。 | (A ^ B) 将得到 49,即为 0011 0001 |
| ~ | 二进制补码运算符是一元运算符,具有"翻转"位效果,即0变成1,1变成0。 | (~A ) 将得到 -61,即为 1100 0011,一个有符号二进制数的补码形式。 |
| << | 二进制左移运算符。左操作数的值向左移动右操作数指定的位数。 | A << 2 将得到 240,即为 1111 0000 |
| >> | 二进制右移运算符。左操作数的值向右移动右操作数指定的位数。 | A >> 2 将得到 15,即为 0000 1111 |
排序sort()
vector<int> nums={1,2,2,3,1,3,5,4,3,-1,-2,-3};
sort(nums.begin(), nums.end(),less<int>());//默认升序
sort(nums.begin(), nums.end(),greater<int>());//降序
C++ STL vector添加元素(push_back()和emplace_back())
完成同样的操作,push_back() 的底层实现过程比 emplace_back() 更繁琐,换句话说,emplace_back() 的执行效率比 push_back() 高。因此,在实际使用时,建议大家优先选用 emplace_back()。
可以用来给容器中添加元素的函数有 2 个,分别是 push_back() 和 emplace_back() 函数。
emplace_back() 和 push_back() 的区别,就在于底层实现的机制不同。push_back() 向容器尾部添加元素时,首先会创建这个元素,然后再将这个元素拷贝或者移动到容器中(如果是拷贝的话,事后会自行销毁先前创建的这个元素);而 emplace_back() 在实现时,则是直接在容器尾部创建这个元素,省去了拷贝或移动元素的过程。
auto
int arr[10];
for(int i=0;i<10;i++)
arr[i]=i;
for(auto &a:arr)
std::cout << a;
上下取整
floor(2.5) = 2
ceil(2.5) = 3
求和函数accumulate
accumulate定义在#include中,前两个参数是定义序列的输入迭代器,第三个参数是和的初值;第三个参数的类型决定了返回值的类型。第二个版本的第 4 个参数是定义应用到总数和元素之间的二元函数对象。这时,我们在必要时可以定义自己的加法运算。原函数声明如下:
template<class InputIterator, class Type>
Type accumulate(
InputIterator _First,
InputIterator _Last,
Type _Val
);
template<class InputIterator, class Type, class Fn2>
Type accumulate(
InputIterator _First,
InputIterator _Last,
Type _Val,
BinaryOperation _Binary_op
);
| 参数 | 描述 |
|---|---|
| _First | 指定范围内第一个迭代的值或者结合操作选项使用。 |
| InputIterator _Last | 指定范围内最后一个迭代值或者结合操作项使用。 |
| _Val | 要计算的初始值。 |
| _Binary_op | 运用于指定范围内所有元素和前面计算得到结果的参数。 |
#include isupper()判断字符类型
ASCII编码:48~57为0到9十个阿拉伯数字; 65~90为26个大写英文字母; 97~122号为26个小写英文字母。
isdigit(char);//判断字符是否为数字
isalpha(char);//判断字符是否为字母
isupper(char);//判断字符是否为大写字母
islower(char);//判断是否是小写字母
tolower();//大写转化为小写字母
toupper();//小写转化为大写字母
幂指数pow()
底数为x,幂指数为a,计算得x的a次方:
pow(x,a);
交换数值swap()
swap(a,b);
最大、最小整数
INT_MAX和INT_MIN分别表示最大、最小整数,定义在头文件limits.h中
INT_MAX + 1 = INT_MIN
INT_MIN - 1 = INT_MAX
abs(INT_MIN) = INT_MIN
比较有趣的是,INT_MAX + 1 < INT_MAX, INT_MIN - 1 > INT_MIN, abs(INT_MIN) < 0.
截取字符串
string str="one#two#three",st;
stringstream str_str(str);
while (getline(str_str, st, '#'))
cout << st<< endl;
输出结果:
one
two
three
向量迭代器vector::iterator it
verctor 就是创建了一个名字叫v的向量容器。
vector 是定义向量迭代器
例如输出v(vector)中的值,可以:
vector<int>::iterator it
for(it=v.begin();it!=v.end();it++)
cout<<*it<<endl;
vector::iterator 可以改变vector中的元素值。
vector::const_iterator 只能访问容器内元素,但不能改变其值。
二分查找函数 lower_bound()、upper_bound()
#includeauto pos = lower_bound(arr.begin(), arr.end(), num); |
从数组的begin位置到end-1位置二分查找第一个大于或等于num的数字,找到返回该数字的地址,不存在则返回end。 |
|---|---|
auto pos = upper_bound(arr.begin(), arr.end(), num); |
从数组的begin位置到end-1位置二分查找第一个大于num的数字,找到返回该数字的地址,不存在则返回end。 |
auto pos = lower_bound(arr.begin(), arr.end(), num, greater()); |
从数组的begin位置到end-1位置二分查找第一个小于或等于num的数字,找到返回该数字的地址,不存在则返回end。 |
auto pos = upper_bound(arr.begin(), arr.end(), num, greater();) |
从数组的begin位置到end-1位置二分查找第一个小于num的数字,找到返回该数字的地址,不存在则返回end。 |
set |
如果存在,则返回set中第一个大于等于a的元素的迭代器;如果不存在,则返回rec.end()。 |
- 在set中,【其余三个函数类似】【区别】因为set本身为有序集合,所以自带lower_bound函数,即可直接调用(rec.lower_bound(a));
- 通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。【函数返回值是迭代器vector::iterator, 指向查找出来的元素】
Lambda表达式
原博文链接
Lambda表达式完整的声明格式如下:
[capture list] (params list) mutable exception-> return type { function body }
| 参数 | 含义 |
|---|---|
| capture list | 捕获外部变量列表 |
| params list | 形参列表 |
| mutable指示符 | 用来说用是否可以修改捕获的变量 |
| exception | 异常设定 |
| return type | 返回类型 |
| function body | 函数体 |
此外,我们还可以省略其中的某些成分来声明“不完整”的Lambda表达式,常见的有以下3种:
| 格式 | 解释 |
|---|---|
| [capture list] (params list) -> return type {function body} | 声明了const类型的表达式,这种类型的表达式不能修改捕获列表中的值 |
| [capture list] (params list) {function body} | 省略了返回值类型,但编译器可以根据规则推断出Lambda表达式的返回类型 |
| [capture list] {function body} | 省略了参数列表,类似普通函数中的无参函数 |
示例:
#include 捕获外部变量
1、值捕获
值捕获和参数传递中的值传递类似,被捕获的变量的值在Lambda表达式创建时通过值拷贝的方式传入,因此随后对该变量的修改不会影响影响Lambda表达式中的值,在Lambda表达式函数体中不能修改该外部变量的值。
int main()
{
int a = 123;
auto f = [a] { cout << a << endl; };
a = 321;
f(); // 输出:123
}
2、引用捕获
使用引用捕获一个外部变量,只需要在捕获列表变量前面加上一个引用说明符&。引用捕获的变量使用的实际上就是该引用所绑定的对象。
int main()
{
int a = 123;
auto f = [&a] { cout << a << endl; };
a = 321;
f(); // 输出:321
}
3、隐式捕获
上面的值捕获和引用捕获都需要我们在捕获列表中显示列出Lambda表达式中使用的外部变量。除此之外,我们还可以让编译器根据函数体中的代码来推断需要捕获哪些变量,这种方式称之为隐式捕获。隐式捕获有两种方式,分别是[=]和[&]。[=]表示以值捕获的方式捕获外部变量,[&]表示以引用捕获的方式捕获外部变量。
int main()
{
int a = 123;
auto f = [=] { cout << a << endl; }; // 值捕获
f(); // 输出:123
}
int main()
{
int a = 123;
auto f = [&] { cout << a << endl; }; // 引用捕获
a = 321;
f(); // 输出:321
}
4、混合方式
| 捕获形式 | 说明 |
|---|---|
| [] | 不捕获任何外部变量 |
| [变量名, …] | 默认以值得形式捕获指定的多个外部变量(用逗号分隔),如果引用捕获,需要显示声明(使用&说明符) |
| [this] | 以值的形式捕获this指针 |
| [=] | 以值的形式捕获所有外部变量 |
| [&] | 以引用形式捕获所有外部变量 |
| [=, &x] | 变量x以引用形式捕获,其余变量以传值形式捕获 |
| [&, x] | 变量x以值的形式捕获,其余变量以引用形式捕获 |
修改捕获变量
有没有办法可以修改值捕获的外部变量呢?这是就需要使用mutable关键字,该关键字用以说明表达式体内的代码可以修改值捕获的变量,
int main()
{
int a = 123;
auto f = [a]()mutable { cout << ++a; }; // 不会报错
cout << a << endl; // 输出:123
f(); // 输出:124
}
数据结构
补码
二进制位第一位为符号位,0为正数,1为负数。
| 原码 | 补码 |
|---|---|
| 0 | 0 |
| 正数 | 本身 |
| 负数 | 符号位以外所有位取反后+1 |
bitset位操作
#include 数组vector
vector.push_back(1);//队列尾部插入1
vector.pop_back();//删除队尾元素
vector.erase(vector.begin()+5);//删除第6个元素
a.erase(a.begin()+1,a.begin()+3); //删除a中第1个(从第0个算起)到第2个元素,也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+3(不包括它)
vector.erase(remove(vector.begin(), vector.end(), 0), vector.end());//删除vector中的全部0
a.assign(b.begin(), b.begin()+3); //b为向量,将b的0~2个元素构成的向量赋给a
a.assign(4,2); //是a只含4个元素,且每个元素为2
a.back(); //返回a的最后一个元素
a.front(); //返回a的第一个元素
a.clear(); //清空a中的元素
a.empty(); //判断a是否为空,空则返回ture,不空则返回false
a.pop_back(); //删除a向量的最后一个元素
a.insert(a.begin()+1,5); //在a的第1个元素(从第0个算起)的位置插入数值5,如a为1,2,3,4,插入元素后为1,5,2,3,4
a.insert(a.begin()+1,3,5); //在a的第1个元素(从第0个算起)的位置插入3个数,其值都为5
a.insert(a.begin()+1,b+3,b+6); //b为数组,在a的第1个元素(从第0个算起)的位置插入b的第3个元素到第5个元素(不包括b+6),如b为1,2,3,4,5,9,8 ,插入元素后为1,4,5,9,2,3,4,5,9,8
a.size(); //返回a中元素的个数;
a.capacity(); //返回a在内存中总共可以容纳的元素个数
a.resize(10); //将a的现有元素个数调至10个,多则删,少则补,其值随机
a.resize(10,2); //将a的现有元素个数调至10个,多则删,少则补,其值为2
a.reserve(100); //将a的容量(capacity)扩充至100,也就是说现在测试a.capacity()的时候返回值是100.这种操作只有在需要给a添加大量数据的时候才显得有意义,因为这将避免内存多次容量扩充操作(当a的容量不足时电脑会自动扩容,当然这必然降低性能)
a.swap(b); //b为向量,将a中的元素和b中的元素进行整体性交换
几种重要的算法,使用时需要包含头文件:
#include二维数组
这里简单叙述一下C++ 构建二维动态数组
int **p;
p = new int*[10]; //注意,int*[10]表示一个有10个元素的指针数组
for (int i = 0; i < 10; ++i)
{
p[i] = new int[5];
}
初始化
1、一维数组(无大小限制):vector
2、二维数组(无大小限制):vector
3、定义一个二维的动态数组,有10行,每一行用一个vector存储这一行的数据。所以每一行的长度是可以变化的。之所以用到vector(0)是对vector初始化,否则不能对vector存入元素:vector< vector
4、二维数组r行c列: vector
5、先定义好二维数组结构,在直接赋值
//得到一个5行3列的数组
//由vector实现的二维数组,可以通过resize()的形式改变行、列值
int i,j;
vector<vector<int>> array(5);
for (i = 0; i < array.size(); i++)
array[i].resize(3);
for(i = 0; i < array.size(); i++)
{
for (j = 0; j < array[0].size();j++)
{
array[i][j] = (i+1)*(j+1);
}
}
注:对于二维数组Array, Array.size()表示行数,Array[0].size() 表示列数;
https://blog.csdn.net/qq_24153697/article/details/76595198
遍历
1、利用迭代器
void reverse_with_iterator(vector<vector<int>> vec)
{
if (vec.empty())
{
cout << "The vector is empty!" << endl;
return;
}
vector<int>::iterator it;
vector<vector<int>>::iterator iter;
vector<int> vec_tmp;
cout << "Use iterator : " << endl;
for(iter = vec.begin(); iter != vec.end(); iter++)
{
vec_tmp = *iter;
for(it = vec_tmp.begin(); it != vec_tmp.end(); it++)
cout << *it << " ";
cout << endl;
}
}
2、得到行、列大小,利用下标进行遍历
void reverse_with_index(vector<vector<int>> vec)
{
if (vec.empty())
{
cout << "The vector is empty!" << endl;
return;
}
int i,j;
cout << "Use index : " << endl;
for (i = 0; i < vec.size(); i++)
{
for(j = 0; j < vec[0].size(); j++)
cout << vec[i][j] << " ";
cout << endl;
}
}
pair
- 定义与赋值
pair的两个元素可以属于不同数据类型,甚至可以是vector。
pair<T1, T2> p1; //创建一个空的pair对象(使用默认构造),它的两个元素分别是T1和T2类型,采用值初始化
p1 = make_pair(v1, v2); //给两个元素分别赋值v1和v2,make_pair用来生成新的pair对象
pair<T1, T2> p2(v1, v2); //创建一个pair对象,它的两个元素分别是T1和T2类型,值分别为v1和v2
pair<T1, T2> p3(p1); //拷贝构造
//通过first和second来访问pair的两个元素。
pair<string,int> p("hello",1);
cout<<p.first<<" "<<p.second;
两个pair的比较遵循字典序,是依次比较两个元素得到的。
也就是说先比较p1.first和p2.first,如果相等,再比较p1.second和p2.second。
//根据first的值升序排序
bool cmp1(pair<int,int>a,pair<int,int>b)
{
return a.first < b.first;
}
//根据second的值升序排序
bool cmp2(pair<int, int>a, pair<int, int>b)
{
return a.second < b.second;
}
int main()
{
vector<pair<int, int>>vec;
vec.push_back({ 1,2 });
vec.push_back({ 4,2 });
vec.push_back({ 3,3 });
vec.push_back({ 2,1 });
sort(vec.begin(), vec.end(), cmp1);
cout << "根据first的值升序排序:" << endl;
for (auto it = vec.begin();it != vec.end();it++)
{
cout << "(" << it->first << "," << it->second << ")" << endl;
}
sort(vec.begin(), vec.end(), cmp2);
cout << "根据second的值升序排序:" << endl;
for (auto it = vec.begin();it != vec.end();it++)
{
cout << "(" << it->first << "," << it->second << ")" << endl;
}
}
栈、队列、优先级队列、链表
栈、队列、优先级队列、链表的相关操作:
| 操作名称 | 栈 | 队列 | 链表 | 优先级队列 |
|---|---|---|---|---|
| 定义 | stack |
queue |
list |
priority_queue |
| 返回栈顶(队首)元素 | s.top() |
q.front() |
l.front() |
q.top() |
| 返回队尾元素 | q.back() |
l.back() |
||
| 在栈顶(队尾)压入新元素 | s.push() |
q.push() |
l.push_back() |
q.push() (并排序) |
| 删除栈顶(队首)元素 | s.pop() |
q.pop() |
l.pop_front() |
q.pop() |
| 判断是否为空 | s.empty() |
q.empty() |
l.empty() |
q.empty() |
| 返回元素个数 | s.size() |
q.size() |
l.size() |
q.size() |
queue<pair<char, int>> q;//定义
q.emplace(s[i], i);//队尾插入
//注:emplace可以插入pair,push不可以
q.pop();//弹出队首元素
q.empty();//判断队列为空
链表操作
Lst1.assign() 给list赋值
Lst1.back() 返回最后一个元素
Lst1.begin() 返回指向第一个元素的迭代器
Lst1.clear() 删除所有元素
Lst1.empty() 如果list是空的则返回true
Lst1.end() 返回末尾的迭代器
Lst1.erase() 删除一个元素
Lst1.front() 返回第一个元素
Lst1.get_allocator() 返回list的配置器
Lst1.insert() 插入一个元素到list中
Lst1.max_size() 返回list能容纳的最大元素数量
Lst1.merge() 合并两个list
Lst1.pop_back() 删除最后一个元素
Lst1.pop_front() 删除第一个元素
Lst1.push_back() 在list的末尾添加一个元素
Lst1.push_front() 在list的头部添加一个元素
Lst1.rbegin() 返回指向第一个元素的逆向迭代器
Lst1.remove() 从list删除元素
Lst1.remove_if() 按指定条件删除元素
Lst1.rend() 指向list末尾的逆向迭代器
Lst1.resize() 改变list的大小
Lst1.reverse() 把list的元素倒转
Lst1.size() 返回list中的元素个数
Lst1.sort() 给list排序
Lst1.splice() 合并两个list
Lst1.swap() 交换两个list
Lst1.unique() 删除list中重复的元素
优先级队列
priority_queue本质是一个堆。
- 头文件是
#include - 关于priority_queue中元素的比较
模板申明带3个参数:priority_queue,其中Type 为数据类型,Container为保存数据的容器,Functional 为元素比较方式。
Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。STL里面默认用的是vector。
2.1 比较方式默认用operator<,所以如果把后面2个参数缺省的话,优先队列就是大顶堆(降序),队头元素最大。
priority_queue q;//默认升序
priority_queue <int,vector<int>,greater<int> > q;//升序队列
priority_queue <int,vector<int>,less<int> >q;//降序队列
重载运算符
#include 哈希表
Leetcode 1两数之和
unordered_map<int, int> hashtable;
for (int i = 0; i < nums.size(); ++i) {
auto it = hashtable.find(target - nums[i]);
if (it != hashtable.end()) {
return {it->second, i};
}
hashtable[nums[i]] = i;
}
return {};
unordered_map
- 头文件 #include
- 定义
template < class Key, // unordered_map::key_type
class T, // unordered_map::mapped_type
class Hash = hash<Key>, // unordered_map::hasher
class Pred = equal_to<Key>, // unordered_map::key_equal
class Alloc = allocator< pair<const Key,T> > // unordered_map::allocator_type
> class unordered_map;
用法
string key="123";
int value=4;
unordered_map<string, int> unomap;//创建一个key为string类型,value为int类型的unordered_map
unomap.emplace(key, value);//使用变量方式,插入一个元素
unomap.emplace("456", 7);//也可以直接写上key和value的值
cout<<unomap["123"];//通过key值来访问value
cout<<endl;
for(auto x:unomap)//遍历整个map,输出key及其对应的value值
cout<<x.first<<" "<<x.second<<endl;
for(auto x:unomap)//遍历整个map,并根据其key值,查看对应的value值
cout<<unomap[x.first]<<endl;
unordered_map的用法
[查找元素是否存在]
若有unordered_map;查找x是否在map中
方法1: 若存在 mp.find(x)!=mp.end()
方法2: 若存在 mp.count(x)!=0
[插入数据]
map.insert(Map::value_type(1,"Raoul"));
[遍历map]
unordered_map<key,T>::iterator it;
(*it).first; //the key value
(*it).second //the mapped value
for(unordered_map<key,T>::iterator iter=mp.begin();iter!=mp.end();iter++)
cout<<"key value is"<<iter->first<<" the mapped value is "<< iter->second;
//也可以这样
for(auto& v : mp)
print v.first and v.second
C++ set与map、unordered_map、unordered_set与哈希表
unordered_map和map:
unordered_map存储机制是哈希表。unordered_map不会根据key的大小进行排序,存储时是根据key的hash值判断元素是否相同,即unordered_map内部元素是无序的。
map是红黑树,红黑树内的数据时有序的,里面的元素可以根据键进行自动排序。map中的元素是按照二叉搜索树存储,进行中序遍历会得到有序遍历。
如果需要内部元素自动排序,使用map,不需要排序使用unordered_map
unordered_set和set:
unordered_set基于哈希表,是无序的。
set实现了红黑树的平衡二叉检索树的数据结构,插入元素时,它会自动调整二叉树的排列,把元素放到适当的位置,以保证每个子树根节点键值大于左子树所有节点的键值,小于右子树所有节点的键值;另外,还得保证根节点左子树的高度与右子树高度相等。平衡二叉检索树使用中序遍历算法,检索效率高于vector、deque和list等容器,另外使用中序遍历可将键值按照从小到大遍历出来。
| 方法 | 功能 |
|---|---|
| begin() | 返回set容器的第一个元素 |
| erase | 删除一个元素 |
| end() | 返回set容器的最后一个元素 |
| size | 获取元素的个数 |
| clear | 清空 |
字符串
字符串后拼接数字
string str;
int num;
str+='0' + num;
str.push_back('0' + num);
string类常见操作
1.增加:+, append, insert, push_back
2.删除:clear, pop_back, erase
3.修改:replace, assign, swap
4.大小:size, length, capacity, max_size, resize, reserve
5.判断:empty, compare, >=, <=, >, <
6.遍历:begin, end, front, back, at, find
7.其他:getline, string转换, substr
1.增加函数:
//使用+
string s1("abc");
string s2("def");
string s3=s1+s2;
//使用append: vector没有append
s1.append(s2); //不能用a1.append("def")
s1.append(3,'K');
s1.append(s2,1,2);//增加s2从1位开始的两位字符
//使用insert:跟vector的insert不一样,vector的insert第一个元素一定是一个迭代器,不能是整数,而string的insert都可以使用
s1.insert(2,"def");
s1.insert(2,s2,1,2); //插入s2的1位开始的两个字符
s1.insert(2,s2);
s1.insert(s1.begin(),'1');
s1.insert(s1.begin(),3,'1');
2.删除函数:
//使用erase:跟vector不一样,vector使用的迭代arr.begin()+n
//string可以使用迭代器和数字,并且使用迭代器和数字是代表的含义不一样
s1.erase(1,2); //从1位开始的两个字符
s1.erase(1); //删除1位后面的所有字符
s1.erase(s1.begin()+1); //只删除1位的字符
3.修改函数:
//使用replace
string s1="1234567";
s1.replace(2,3,"abcdefg",2,4); //用cdef替换345
s1.replace(2,3,5,'0'); //用5个0替换345
//使用assign
s1.assign(4,'a');
//使用swap
s1.swap(s2);
swap(s1,s2);
4.判断函数:
//使用compare
string s("abcd");
s.compare("abcd"); //返回0
s.compare("dcba"); //返回一个小于0的值
s.compare("ab"); //返回大于0的值
s.compare(s); //相等
s.compare(0,2,s,2,2); //用"ab"和"cd"进行比较 小于零
s.compare(1,2,"bcx",2); //用"bc"和"bc"比较。
//使用<,>
string s1("real");
string s2("abdc");
int a = s1 > s2;
cout << a << endl; //输出1
5.查找子串:
//使用find
s.find(s1);//查找s中第一次出现s1的位置,并返回(包括0)
s.rfind(s1);//查找s中最后次出现s1的位置,并返回(包括0)
s.find_first_of(s1);//查找在s1中任意一个字符在s中第一次出现的位置,并返回(包括0)
s.find_last_of(s1);//查找在s1中任意一个字符在s中最后一次出现的位置,并返回(包括0)
s.fin_first_not_of(s1);// 查找s中第一个不属于s1中的字符的位置,并返回(包括0)
s.fin_last_not_of(s1);//查找s中最后一个不属于s1中的字符的位置,并返回(包括0)
idx=a.find(b);//在a中查找b.
if(idx == string::npos )//不存在。
6.截取子串
s.substr(pos, n);//截取s中从pos开始(包括0)的n个字符的子串,并返回
s.substr(pos);//截取s中从从pos开始(包括0)到末尾的所有字符的子串,并返回
7.替换子串
s.replace(pos, n, s1);//用s1替换s中从pos开始(包括0)的n个字符的子串
8.其他函数:
//使用getline
string str;
getline(cin,str);
//string转换
string a=“1234”;
int b=atoi(a.c_str());
b=stoi(a);
string c="12345678910";
long d=stol(c);
int a=123;
string b=to_string(a);
原文链接:https://blog.csdn.net/weixin_43930512/article/details/91041396
链表
使用构造函数初始化结点
struct ListNode
{
double value;
ListNode *next;
//构造函数
ListNode(double valuel, ListNode *nextl = nullptr)
{
value = value1;
next = next1;
}
};
创建链表
使用 ListNode 的构造函数版本,可以很轻松地创建一个链表,方法是读取文件中的值并将每个新读取的值添加到已经累积的值链表的开头。
例如,使用numberList作为链表头,使用 numberFile 作为输入文件对象,则以下代码将读取存储在某个文本文件中的数字,并将它们排列在链表中:
ListNode *numberList = nullptr;
double number;
while (numberFile >> number)
{
//创建一个结点以保存该数字
numberList = new ListNode(number, numberList);
}
遍历链表
ListNode *ptr = numberList;
while (ptr != nullptr)
{
cout << ptr->value << " "; //处理结点(显示结点内容)
ptr = ptr->next; //移动到下一个结点
}
链表尾部插入值
void AddToTail(ListNode** pHead, int Value)
{
ListNode* pNew = new ListNode();
pNew->val = Value;
pNew->next = nullptr;
if(*pHead == nullptr){
*pHead = pNew;}
else{
ListNode* pNode = *pHead;
while(pNode->next != nullptr)
pNode = pNode->next;
pNode->next = pNew;}
}
AddToTail(&add, sum);//调用
算法
字符串匹配KMP算法
链接1
链接2

public static int[] getNext(String ps) {
char[] p = ps.toCharArray();
int[] next = new int[p.length];
next[0] = -1;
int j = 0;
int k = -1;
while (j < p.length - 1) {
if (k == -1 || p[j] == p[k]) {
next[++j] = ++k;
}
else {
k = next[k];
}
}
return next;
}
public static int KMP(String ts, String ps) {
char[] t = ts.toCharArray();
char[] p = ps.toCharArray();
int i = 0; // 主串的位置
int j = 0; // 模式串的位置
int[] next = getNext(ps);
while (i < t.length && j < p.length) {
if (j == -1 || t[i] == p[j]) { // 当j为-1时,要移动的是i,当然j也要归0
i++;
j++;
}
else {//i不需要回溯了 i = i - j + 1;
j = next[j]; // j回到指定位置
}
}
if (j == p.length) {
return i - j;//返回模式串在匹配的字符串中开始的位置
}
else {
return -1;
}
}
//kmp
vector<int> getNext(String s) {
int n = s.size();
vector<int> fail(n, -1);
for (int i = 1; i < n; ++i) {
int j = fail[i - 1];
while (j != -1 && s[j + 1] != s[i]) {
j = fail[j];
}
if (s[j + 1] == s[i]) {
fail[i] = j + 1;
}
}
return fail
}