如何有效阅读文献
作为研究生要保持看文献的能力,以《面向大规模图像定位的高效优先匹配(Efficient & Effective Prioritized Matching for Large-Scale Image-Based Localization)》文献为例,本文记录了自己在学习过程中如何阅读文献技巧。
文章目录
-
- 一、标题
- 二、摘要
-
- 1、解决了什么问题,使用了什么方法
- 三、引言
-
- 1、描述了几类创新点(contributions)
- 2、基于xxx的描述
- 四、正文
-
- 1、系统框图
- 2、算法公式
- 3、站在作者的角度想问题
- 五、实验
-
- 1、从全局角度上看
- 2、描述图片
- 六、结论
一、标题
首先看到一篇论文的情况下,先去从标题看一下内容做的是什么,第一个做的是匹配(Matching),匹配是方法,目标作用于定位(Localization),场景是大规模(Large-Scale)。标题需要仔细斟酌。

二、摘要
只需要明白两个问题:
1、解决了什么问题,使用了什么方法
问题:大尺度的匹配和定位 large scale image-based localization
方法:优先匹配算法 a novel prioritized matching step
有的文献可能不会明确解决的是什么问题,摘要里面直接讲创新点也是可能的,然后用突出创新点的方式完成整个摘要,最终大家想得到的结果就是这个方法我能不能用到我自己的算法里面。
三、引言
简介部分一般会介绍一些其他算法的缺陷和本文算法的创新点。主要需要关注的是:其他算法有什么缺陷,本文算法的创新点是什么还需要注意可能会描述论文在XX论文的基础上进行提出的,那最好再把基础的论文再看一遍。
文献的创新点可以从一下几个方向去看
1、描述了几类创新点(contributions)
有可能描述了三个创新点,最后实际落脚到了一个创新点,那么他如何把这一个创新点展开写成三个的,并且建议多看一些高质量的论文,这样才能看出写法上的区别,一个是看贡献,用了哪些方法,用了这些方法怎么去实施,换位思考如果是自己的话应该如何实施,你有可能想不到作者想到的方式,那么作者在引言的部分可能会讲到他之前的一些工作,或者受激励于的一些工作,有可能和其他的算法研究的同一个问题,那么你就可以循着摘要点进去看用什么样的方法做的同样的问题
需要注意创新点有没有和其他文章类似的,最好能从作者的角度。想一下,他是如何想到这个算法的,从哪里得到的启发
2、基于xxx的描述
以及基于……(base on…)那么就在下载他的参考文献,对比他们之间的不同,比如这篇文章写到(This paper is based on our previous publications [7], [8].)

那么就证明[7][8]这两篇文献引出了目前这篇文献,那么目前这篇文献是怎么想到的从那个角度想到的,怎么立足于[7][8]两篇文献,形成这样的思维惯性,这样看到其他论文再能引发你自己的想法
四、正文
算法具体描述没有语言上没有什么大的问题,注意逻辑性
1、系统框图
一个好的作者整个系统框图是非常缜密的,每个部分之间的联系。框图中有些地方可能没有创新性,有些地方有创新性,
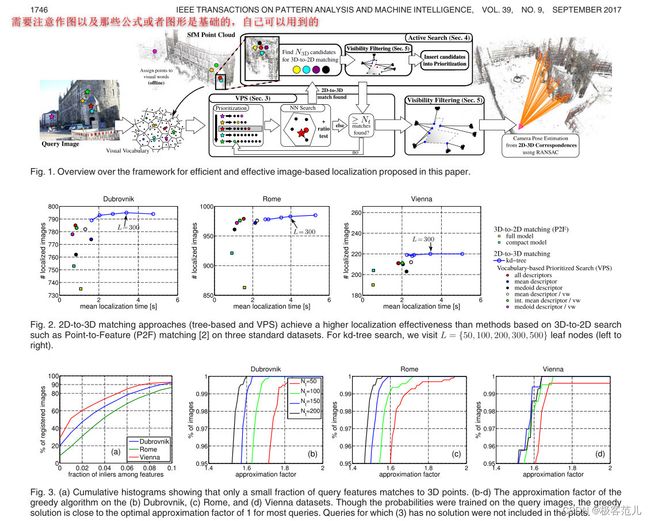
2、算法公式
找一些基础性的公式,需要注意作图以及哪些公式或者图形是基础的,自己可以用到的。

像这篇文章,基础的公式就是描述子的最佳匹配算法
3、站在作者的角度想问题
从中筛选内容,选择有价值的段落,联系几篇论文,形成这样的思维惯性,这样看到其他论文再能引发你自己的想法,这样就好自己有想法去创新,然后准备实施
五、实验
分析实验设计的步骤,为什么这么设计
1、从全局角度上看
查看逻辑性,学习实验为什么设计,对比数值是为什么
2、描述图片
作者对每副图片是怎么描述的,你会怎么描述,表达数据的方式,表格和图是不一样的,图更直观
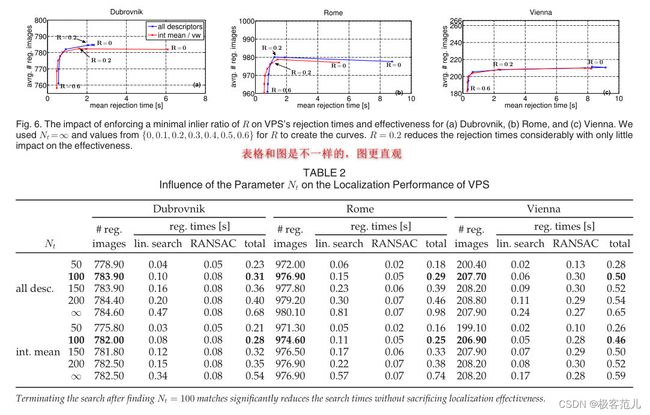
优先匹配算法
# 二部图的匹配关系
graph = {'a': {1}, 'b': {1, 2}, 'c': {1, 2, 3}, 'd': {2, 3, 4}, 'e': {3, 4, 10}, 'f': {4, 5, 6}, 'g': {5, 6, 7},
'h': {7, 8}, 'i': {9}}
from copy import deepcopy
class HK_algorithm(object):
def __init__(self, graph):
"""
初始化和接受配对关系图,初步处理
:param graph:为了方便操作,二部图的左右集合我们用不同的数据类型来表示
"""
self._graph = deepcopy(graph)
self._left_set = set(self._graph.keys())
self._right_set = set()
self._matching = {}
self._dfs_paths = []
self._dfs_alternately = {}
self.iter_times = 0
# 处理 右端点 的端点,放入 self._right
graph_values = set
for value in self._graph.values():
for i in value:
self._right_set.add(i)
print(self._right_set)
# 为了找增广路径, 需要将右端点,可以连接的左端点处理成为一个相应的 graph 字典
for left_node in self._left_set:
for neighbour in self._graph[left_node]:
if neighbour not in self._graph:
# 防止重复
self._graph[neighbour] = set()
self._graph[neighbour].add(left_node)
else:
self._graph[neighbour].add(left_node)
def breadth_first_search(self):
visited = set()
layers = [] # index = layer 按照层存储点 待遍历的点
layer = set()
for node in self._left_set:
if node not in self._matching:
layer.add(node)
layers.append(layer)
while True:
new_layer = set()
layer = layers[-1]
for node in layer:
if node in self._left_set:
visited.add(node)
for neighbour in self._graph[node]:
if neighbour not in visited and (
node not in self._matching or neighbour != self._matching[node]):
new_layer.add(neighbour)
else:
visited.add(node)
for neighbour in self._graph[node]:
if neighbour not in visited and (node in self._matching and neighbour == self._matching[node]):
new_layer.add(neighbour)
layers.append(new_layer)
if len(new_layer) == 0:
return layers
for node in new_layer:
if any(node in self._right_set and node not in self._matching for node in new_layer):
return layers
六、结论
有些论文的结论部分会有未来展望,可以看看,作为自己的新方向
一些大作者的展望,可以跟踪一下他近期的成果,多关注这方面的论文

总结:推荐IEEE TRANSACTIONS,论文质量都很高的