【Linux系统编程】文件IO
------------->【Linux系统编程/网络编程】(学习目录汇总) <--------------
目录
-
- 1.linux man 1 2 3的作用
- 2.open函数
-
- 2.1函数原型
- 2.2函数参数
- 2.3函数返回值
- 3.close()函数
-
- 3.1函数原型
- 3.2函数参数
- 4.read()函数
-
- 4.1函数原型
- 4.2函数参数
- 4.3函数返回值
- 5.write()函数
-
- 5.1函数原型
- 5.2函数参数
- 5.3函数返回值
- 6.小案例:用read()和write()函数实现copy功能
- 7.系统调用和库函数比较—预读入缓输出
- 8.阻塞和非阻塞
- 9.fcntl()函数
-
- 9.1fcntl函数原型:
- 9.2函数参数:
- 9.3函数返回值
- 10.lseek()函数
-
- 10.1函数原型
- 10.2 函数参数
- 10.3 函数返回值
- 11.truncate()/ftruncate()函数
- 12.目录项和inode
- 13.stat()/lstate()函数
-
- 13.1 函数原型
- 13.2 函数参数
- 13.3 各种操作
- 13.目录操作函数
-
- 13.1opendir()函数
- 13.2readdir()函数
- 13.3closedir()函数
- 14.文件描述符复制和重定向(dup(),dup2()命令)
- 15.文件描述符
1.linux man 1 2 3的作用
1、Standard commands (标准命令)
2、System calls (系统调用)
3、Library functions (库函数)
4、Special devices (设备说明)
5、File formats (文件格式)
6、Games and toys (游戏和娱乐)
7、Miscellaneous (杂项)
8、Administrative Commands (管理员命令)
9 其他(Linux特定的), 用来存放内核例行程序的文档。
说明:
系统调用 Linux内核提供的函数
库调用 c语言标准库函数和编译器特定库函数
例子:
man 1 cd
man 2 open
man 3 printf
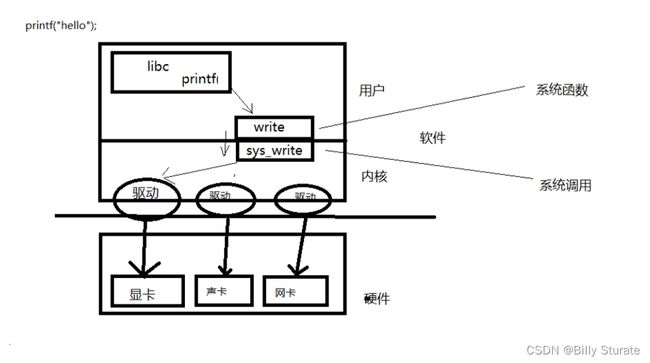
一个小案例:
C 标准函数和系统函数调用关系。一个 helloworld 如何打印到屏幕。
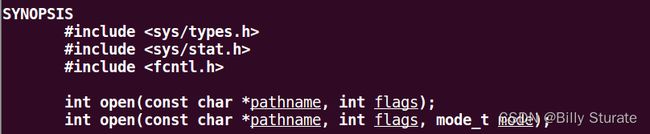
2.open函数
2.1函数原型
manpage 第二卷(系统调用函数),输入man 2 open指令
open函数如下,有两个版本的
-
open是一个系统函数, 只能在linux系统中使用, windows不支持
-
fopen 是标准c库函数, 一般都可以跨平台使用, 可以这样理解:
在linux中 fopen底层封装了Linux的系统API open
在window中, fopen底层封装的是 window 的 api
2.2函数参数
-
pathname文件路径 -
flags文件打开方式:只读,只写,读写,创建,添加等。O_RDONLY, O_WRONLY, O_RDWR,O_CREAT,O_APPEND,O_TRUNC,O_EXCL,O_NONBLOCK -
mode参数,用来指定文件的权限,数字设定法。文件权限 = mode & ~umask。参数3使用的前提, 参2指定了O_CREAT。 用来描述文件的访问权限。
2.3函数返回值
当open出错时,程序会自动设置errno,可以通过strerror(errno)来查看报错数字的含义
以打开不存在文件为例:

执行该代码,结果如下:

3.close()函数
3.1函数原型
int close(int fd)
3.2函数参数
- fd 表示改文件的文件描述符,open的返回值
- 返回值 成功为0 失败返回-1
小案例:
int fd;
fd=open("tmp.txt",O_RDONLY);
close(fd);
4.read()函数
4.1函数原型
#include 4.2函数参数
- fd: 文件描述符,open () 函数的返回值,通过这个参数定位打开的磁盘文件
- buf: 是一个传出参数,指向一块有效的内存,用于存储从文件中读出的数据
- count: buf 指针指向的内存的大小,指定可以存储的最大字节数
4.3函数返回值
- 大于 0: 从文件中读出的字节数,读文件成功
- 等于 0: 代表文件读完了,读文件成功
- -1: 读文件失败了,并设置 errno
如果返回-1: 并且 errno = EAGIN 或 EWOULDBLOCK, 说明不是read失败,而是read在以非阻塞方式读一个设备文件(网络文件),并且文件无数据。
5.write()函数
5.1函数原型
#include 5.2函数参数
- fd: 文件描述符,open () 函数的返回值,通过这个参数定位打开的磁盘文件
- buf: 指向一块有效的内存地址,里边有要写入到磁盘文件中的数据
- count: 要往磁盘文件中写入的字节数,一般情况下就是 buf 字符串的长度,strlen (buf)
5.3函数返回值
- 大于 0: 成功写入到磁盘文件中的字节数
- -1: 写文件失败了
6.小案例:用read()和write()函数实现copy功能
// 文件的拷贝
#include 7.系统调用和库函数比较—预读入缓输出
下面写两个文件拷贝函数,一个用read/write实现,一个用fputc/fgetc实现,比较他们两个之间的速度
fputc/fgetc实现
#include 下面修改read那边的缓冲区,一次拷贝一个字符。
// 文件的拷贝
#include 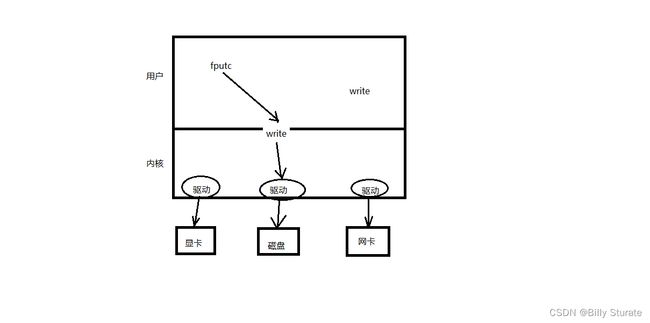
我猜很多人会觉得,read/write函数会比fputc/fgetc这些c语言标准库函数更快,因为read/write函数是系统调用函数,更接近linux内核。
其实不然,实际上fputc/fgetc会更快,为什么呢?下面我来分析一下
原因分析:
read/write,每次写一个字节,由于在用户区没缓冲区,会疯狂进行内核态和用户态的切换,所以非常耗时。
fgetc/fputc,在用户区有个缓冲区,所以它并不是一个字节一个字节地写进,内核和用户切换就比较少
所以系统函数并不是一定比库函数牛逼,能使用库函数的地方就使用库函数。
标准IO函数自带用户缓冲区,系统调用无用户级缓冲。系统缓冲区是都有的。
这就是预读入,缓输出机制。

8.阻塞和非阻塞
阻塞、非阻塞: 是设备文件、网络文件的属性。
产生阻塞的场景。 读设备文件。读网络文件。(读常规文件无阻塞概念。)
/dev/tty – 终端文件。
open(“/dev/tty”, O_RDWR|O_NONBLOCK) — 设置 /dev/tty 非阻塞状态。(默认为阻塞状态)
小案例:从标准输入读,写到标准输出
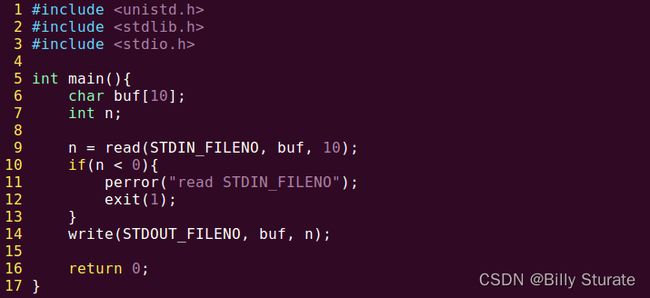
执行程序,就会发现程序在阻塞等待输入

下面是一段更改非阻塞读取终端的代码:
#include 执行,如图所示:
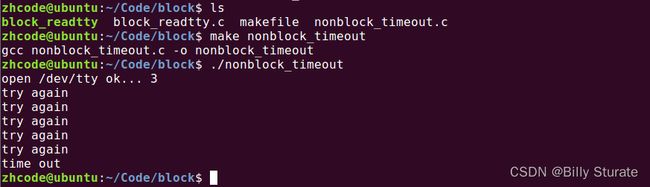
9.fcntl()函数
fcntl用来改变一个已经打开的文件的访问控制属性
重点掌握两个参数的使用, F_GETFL,F_SETFL
9.1fcntl函数原型:
#include 9.2函数参数:
fd文件描述符cmd 命令,决定了后续参数个数- 获取文件状态:
F_GETFL - 设置文件状态:
F_SETFL
9.3函数返回值
int flgs = fcntl(fd, F_GETFL);
flgs |= O_NONBLOCK
fcntl(fd, F_SETFL, flgs);
一个小案例:
终端文件默认是阻塞读的,这里用fcntl将其更改为非阻塞读:
#include 10.lseek()函数
系统函数 lseek 的功能是比较强大的,我们既可以通过这个函数移动文件指针,也可以通过这个函数进行文件的拓展。
10.1函数原型
#include 10.2 函数参数
- fd: 文件描述符,open () 函数的返回值,通过这个参数定位打开的磁盘文件
- offset: 偏移量,需要和第三个参数配合使用
- whence: 通过这个参数指定函数实现什么样的功能
SEEK_SET: 从文件头部开始偏移 offset 个字节SEEK_CUR: 从当前文件指针的位置向后偏移 offset 个字节SEEK_END: 从文件尾部向后偏移 offset 个字节
10.3 函数返回值
- 成功:文件指针从头部开始计算总的偏移量
- 失败: -1
一个小案例:
写一个句子到空白文件,完事调整光标位置,读取刚才写那个文件。
这个示例中,如果不调整光标位置,是读取不到内容的,因为读写指针在内容的末尾
#include 应用场景:
1. 文件的“读”、“写”使用同一偏移位置。
2. 使用lseek获取文件大小(返回值接收)
3. 使用lseek拓展文件大小:要想使文件大小真正拓展,必须【引起IO操作】。
小案例:
用lseek的偏移来读取文件大小
用lseek实现文件拓展:
// lseek.c
// 拓展文件大小
#include 11.truncate()/ftruncate()函数
truncate/ftruncate 这两个函数的功能是一样的,可以对文件进行拓展也可以截断文件。使用这两个函数拓展文件比使用 lseek 要简单。这两个函数的函数原型如下:
// 拓展文件或截断文件
#include 函数参数:
- path: 要拓展 / 截断的文件的文件名
- fd: 文件描述符,open () 得到的
- length: 文件的最终大小
- 文件原来 size > length,文件被截断,尾部多余的部分被删除,文件最终长度为 length
- 文件原来 size < length,文件被拓展,文件最终长度为 length
函数返回值:
成功返回 0; 失败返回值 - 1
truncate () 和 ftruncate () 两个函数的区别在于一个使用文件名一个使用文件描述符操作文件,功能相同。
不管是使用这两个函数还是使用 lseek () 函数拓展文件,文件尾部填充的字符都是 0。
小案例:
直接拓展文件。
int ret = truncate("dict.cp", 250);
12.目录项和inode
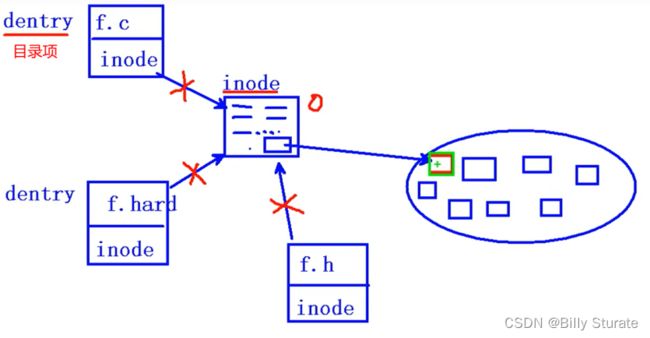
一个文件主要由两部分组成,dentry(目录项)和inode
inode本质是结构体,存储文件的属性信息,如:权限、类型、大小、时间、用户、盘快位置…
也叫做文件属性管理结构,大多数的inode都存储在磁盘上。
少量常用、近期使用的inode会被缓存到内存中。
所谓的删除文件,就是删除inode,但是数据其实还是在硬盘上,以后会覆盖掉。
13.stat()/lstate()函数
用来获取文件或目录的详细属性信息包括文件系统状态,(从第二个参数结构体中获取)
13.1 函数原型
#include 二者的区别:
lstat (): 得到的是软连接文件本身的属性信息
stat (): 得到的是软链接文件关联的文件的属性信息(存在符号穿透)
13.2 函数参数
pathname:文件名,要获取这个文件的属性信息buf:传出参数,文件的信息被写入到了这块内存中
这个函数的第二个参数是一个结构体类型,这个结构体相对复杂,通过这个结构体可以存储得到的文件的所有属性信息,结构体原型如下:
struct stat {
dev_t st_dev; // 文件的设备编号
ino_t st_ino; // inode节点
mode_t st_mode; // 文件的类型和存取的权限, 16位整形数 -> 常用
nlink_t st_nlink; // 连到该文件的硬连接数目,刚建立的文件值为1
uid_t st_uid; // 用户ID
gid_t st_gid; // 组ID
dev_t st_rdev; // (设备类型)若此文件为设备文件,则为其设备编号
off_t st_size; // 文件字节数(文件大小) --> 常用
blksize_t st_blksize; // 块大小(文件系统的I/O 缓冲区大小)
blkcnt_t st_blocks; // block的块数
time_t st_atime; // 最后一次访问时间
time_t st_mtime; // 最后一次修改时间(文件内容)
time_t st_ctime; // 最后一次改变时间(指属性)
};
13.3 各种操作
获取文件大小
下面调用 stat () 函数,以代码的方式演示一下如何得到某个文件的大小:
#include 获取文件类型
文件的类型信息存储在 struct stat 结构体的 st_mode 成员中,它是一个 mode_t 类型,本质上是一个 16 位的整数。Linux API 中为我们提供了相关的宏函数,通过对应的宏函数可以直接判断出文件是不是某种类型,这些信息都可以通过 man 文档(man 2 stat)查询到。
相关的宏函数原型如下:
// 类型是存储在结构体的这个成员中: mode_t st_mode;
// 这些宏函数中的m 对应的就是结构体成员 st_mode
// 宏函数返回值: 是对应的类型返回-> 1, 不是对应类型返回0
S_ISREG(m) is it a regular file?
- 普通文件
S_ISDIR(m) directory?
- 目录
S_ISCHR(m) character device?
- 字符设备
S_ISBLK(m) block device?
- 块设备
S_ISFIFO(m) FIFO (named pipe)?
- 管道
S_ISLNK(m) symbolic link? (Not in POSIX.1-1996.)
- 软连接
S_ISSOCK(m) socket? (Not in POSIX.1-1996.)
- 本地套接字文件
在程序中通过宏函数判断文件类型,实例代码如下:
int main()
{
// 1. 定义结构体, 存储文件信息
struct stat myst;
// 2. 获取文件属性 english.txt
int ret = stat("./hello", &myst);
if(ret == -1)
{
perror("stat");
return -1;
}
printf("文件大小: %d\n", (int)myst.st_size);
// 判断文件类型
if(S_ISREG(myst.st_mode))
{
printf("这个文件是一个普通文件...\n");
}
if(S_ISDIR(myst.st_mode))
{
printf("这个文件是一个目录...\n");
}
if(S_ISLNK(myst.st_mode))
{
printf("这个文件是一个软连接文件...\n");
}
return 0;
}
13.目录操作函数
13.1opendir()函数
在目录操作之前必须要先通过 opendir () 函数打开这个目录,函数原型如下:
#include - 参数: name -> 要打开的目录的名字
- 返回值: DIR*, 结构体类型指针。打开成功返回目录的实例,打开失败返回 NULL
13.2readdir()函数
目录打开之后,就可以通过 readdir () 函数遍历目录中的文件信息了。每调用一次这个函数就可以得到目录中的一个文件信息,当目录中的文件信息被全部遍历完毕会得到一个空对象。先来看一下这个函数原型:
// 读目录
#include - 参数:dirp -> opendir () 函数的返回值
- 返回值:函数调用成功,返回读到的文件的信息,目录文件被读完了或者函数调用失败返回 NULL
- 函数返回值 struct dirent 结构体原型如下:
struct dirent {
ino_t d_ino; /* 文件对应的inode编号, 定位文件存储在磁盘的那个数据块上 */
off_t d_off; /* 文件在当前目录中的偏移量 */
unsigned short d_reclen; /* 文件名字的实际长度 */
unsigned char d_type; /* 文件的类型, linux中有7中文件类型 */
char d_name[256]; /* 文件的名字 */
};
关于结构体中的文件类型 d_type,可使用的宏值如下
DT_BLK:块设备文件
DT_CHR:字符设备文件
DT_DIR:目录文件
DT_FIFO :管道文件
DT_LNK:软连接文件
DT_REG :普通文件
DT_SOCK:本地套接字文件
DT_UNKNOWN:无法识别的文件类型
通过 readdir () 函数遍历某一个目录中的文件:
// 打开目录
DIR* dir = opendir("/home/test");
struct dirent* ptr = NULL;
// 遍历目录
while( (ptr=readdir(dir)) != NULL)
{
.......
}
13.3closedir()函数
目录操作完毕之后,需要通过 closedir() 关闭通过 opendir() 得到的实例,释放资源。函数原型如下:
// 关闭目录, 参数是 opendir() 的返回值
int closedir(DIR *dirp);
- 参数:dirp-> opendir () 函数的返回值
- 返回值:目录关闭成功返回 0, 失败返回 -1
14.文件描述符复制和重定向(dup(),dup2()命令)
请看这篇博客,写的很好
点我查看
15.文件描述符

如上图所示,是我们的虚拟地址空间,其中0-3G为用户区,3-4G为内核区,其中我们的PCB进程控制块就在内核区,它的本质是一个结构体,在这个结构体中有一个成员变量 file_struct *file 指向文件描述符表。 从应用程序使用角度,该指针可理解记忆成一个字符指针数组,下标 0/1/2/3/4…找到文件结构体。本质是一个键值对 0、1、2…都分别对应具体地址。但键值对使用的特性是自动映射,我们只操作键不直接使用值。 新打开文件返回文件描述符表中未使用的最小文件描述符。
STDIN_FILENO 0 标准输入 (键盘)
STDOUT_FILENO 1 标准输出(显示器)
STDERR_FILENO 2 标准错误
一个进程默认打开最大文件的个数 1024。