1、感知机

感知机
感知机接收多个输入信号,输出一个信号,上图是一个接收两个输入信号的感知机的例子。 x1、 x2是输入信号,y是输出信号, w1、 w2是权重(w是weight的首字母)。图中的○称为“神经元”或者“节点”。输入信号被送往神经元时,会被分别乘以固定的权重(w1x1、 w2x2)。神经元会计算传送过来的信号的总和,只有当这个总和超过了某个界限值时,才会输出1。这也称为“神经元被激活” 。这里将这个界限值称为阈值,用符号 θ表示。
上述内容可以使用如下数据公式表示:

感知机表达式
2、感知机应用-逻辑门电路

逻辑与门电路
与门是有两个输入和一个输出的门电路,与门仅在两个输入均为1时输出1,其他时候则输出0。输入信号和输出信号的对应的“真值表”如下:
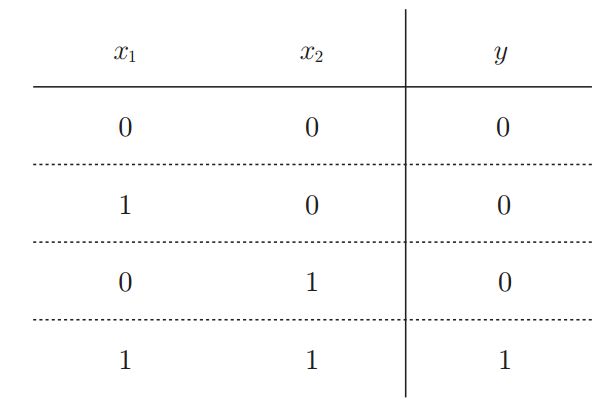
与门真值表
考虑用感知机来表示这个与门,确定能满足图上真值表的 w1、 w2、 θ的值。当
(w1, w2, θ) = (0.5, 0.5, 0.7) 或(w1, w2, θ)=(0.5, 0.5, 0.8)都满足与门的条件。
3、感知机变形-权重和偏置
把 (w1, w2, θ)中的θ换成-b,于是就可以用如下公式来表示感知机的行为。

权重偏置感知机表达式
虽然有一个符号不同,但表达的内容是完全相同的。此处, b称为偏置, w1和w2称为权重。感知机通过公式可以实现与门逻辑关系,是否其他数字电子钟的逻辑门也可以实现尼?
4、异或门引出感知机缺陷

异或门
异或门仅当x1或x2中的一方为1时,才会输出1。真值表如下:

真值表
能否通过上述数据公式实现异或门尼?
下面通过画图分析观察
与门:

与门坐标系绘图
与门在坐标系上的图像如上,可以通过一条直线将结果分开
异或门:
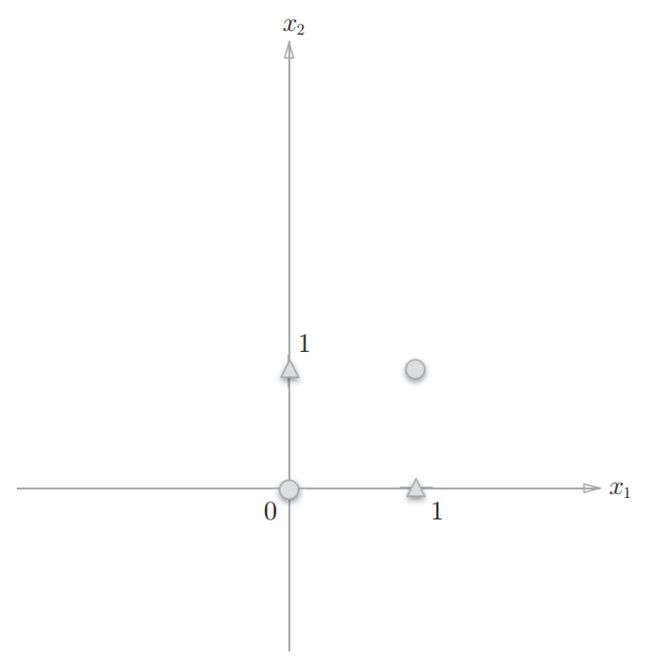
异或门
异或门无法通过直线将结果分开,可以通过曲线分开

曲线分割异或门结果
参照上面与门数学公式可以看出,感知机的局限性就在于它只能表示由一条直线分割的空间。异或门弯曲的曲线无法用感知机表示。
5、异或门弯曲曲线如何实现-多层感知机
异或门
数字电路中异或门可以通过组合与门、与非门、或门实现异或门
上图中把s1作为与非门的输出,把s2作为或门的输出,填入真值表中。观察x1、 x2、 y,可以发现确实符合异或门的输出。

异或门真值表
下面试着用感知机的表示方法(明确地显示神经元)来表示这个异或门,如下图:
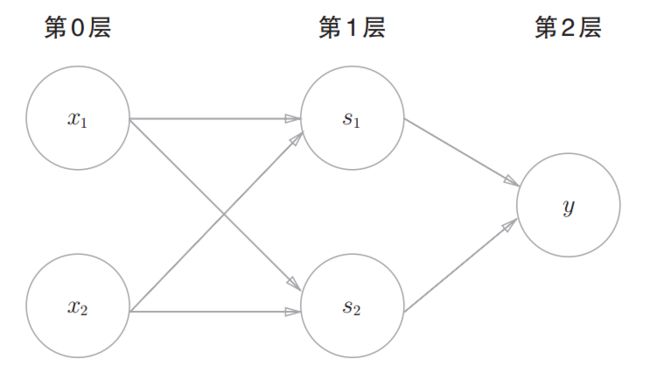
2层感知机
上图中将最左边的一列称为第0层,中间的一列称为第1层,最右边的一列称为第2层。与门、或门是单层感知机,而异或门是2层感知机。叠加了多层的感知机也称为多层感知机。
在2层感知机中,先在第0层和第1层的神经元之间进行信号的传送和接收,然后在第1层和第2层之间进行信号的传送和接收,该运行过程可以比作流水线的组装作业。第1段(第1层)的工人对传送过来的零件进行加工,完成后再传送给第2段(第2层)的工人。第2层的工人对第1层的工人传过来的零件进行加工,完成这个零件后出货(输出)。
BP神经网络
一 BP 神经网络简介
(1)BP神经网络在深度学习的地位
BP神经网络被称为“深度学习之旅的开端”,是神经网络的入门算法。
各种高大上的神经网络都是基于BP网络出发的,最基础的原理都是由BP网络而来[1],另外由于BP神经网络结构简单,算法经典, 是神经网络中应用最广泛的一种。
(2)什么是BP神经网络
BP神经网络(back propagation neural network)全称是反向传播神经网络。
神经网络发展部分背景如下[2]:
开始发展——在人工神经网络的发展历史上,感知机网络曾对人工神经网络的发展发挥了极大的作用,它的出现曾掀起了人们研究人工神经元网络的热潮。单层感知网络(M-P模型)做为最初的神经网络,具有模型清晰、结构简单、计算量小等优点。
只能解决线性可分——但是,随着研究工作的深入,人们发现它还存在不足,例如无法处理非线性问题,即使计算单元的作用函数不用阀函数而用其他较复杂的非线性函数,仍然只能解决解决线性可分问题.不能实现某些基本功能,从而限制了它的应用。
多层前馈网络——增强网络的分类和识别能力、解决非线性问题的唯一途径是采用多层前馈网络,即在输入层和输出层之间加上隐含层。
BP神经网络登场——20世纪80年代中期,David Runelhart。Geoffrey Hinton和Ronald W-llians、DavidParker等人分别独立发现了误差反向传播算法,简称BP,系统解决了多层神经网络隐含层连接权学习问题,并在数学上给出了完整推导。人们把采用这种算法进行误差校正的多层前馈网络称为BP网。
BP神经网络具有任意复杂的模式分类能力和优良的多维函数映射能力,解决了简单感知器不能解决的异或和一些其他问题。从结构上讲,BP网络具有输入层、隐藏层和输出层;从本质上讲,BP算法就是以网络误差平方为目标函数、采用梯度下降法来计算目标函数的最小值。
为解决非线性问题,BP神经网络应运而生。
那么什么是BP神经网络?稍微专业点的解释要怎么说呢?
BP神经网络是一个非常经典的网络结构。整个网络结构包含了:一层输入层,一到多层隐藏层,一层输出层。它既可以处理线性问题,也可以处理非线性问题。学习过程由信号的正向传播和误差的反向传播两个过程组成。我们可以利用误差反向传播算法进行迭代,使误差逐渐减少到我们的接受范围内。
二 算法原理
很喜欢最简单的神经网络--Bp神经网络一文对算法原理的解释,语言活泼,案例简单,由浅入深。
文中提到所谓的 AI 技术,本质上是一种数据处理处理技术,它的强大来自于两方面:1.互联网的发展带来的海量数据信息;2.计算机深度学习算法的快速发展。AI 其实并没有什么神秘,只是在算法上更为复杂[3]。
我们从上面的定义出发来解释BP神经网络的原理。
(1)网络结构
BP神经网络整个网络结构包含了:一层输入层,一到多层隐藏层,一层输出层。
一般说L层神经网络,指的是有L个隐层,输入层和输出层都不计算在内的[6]。
输入层——神经网络中的第一层。它需要输入信号并将它们传递到下一层。它不对输入信号做任何操作,并且没有关联的权重和偏置值[4]
隐藏层——除输入层和输出层以外的其他各层叫做隐藏层。隐藏层不直接接受外界的信号,也不直接向外界发送信号。隐藏层在神经网络中的作用:中间的黑盒子,可以认为是不同功能层的一个总称。[5]
输出层——网络的最后一层,它接收来自最后一个隐藏层的输入,输出模型预测的结果值。

结构图
(2)正向传播
BP神经网络模型训练的学习过程由信号的正向传播和误差的反向传播两个过程组成。
什么是信号的正向传播?顾名思义,就是结构图从左到右的运算过程。
正向传播就是让信息从输入层进入网络,依次经过每一层的计算,得到最终输出层结果的过程。
我们来看看结构图中每个小圆圈是怎么运作的。我们把小圈圈叫做神经元,是组成神经网络的基本单元。
上一层的输出数据作为小圈圈的输入数据,先加权求和加偏置b,然后代入激活函数f(x)计算,结果输出。

先对输入数据加权求和加偏置:
激活函数有很多选择(relu,sigmod,tanh等),不过都不是很复杂的函数,这里令
,x代入函数计算结果作为神经元的输出。
是不是很简单,每个小圈圈都在做这样的“加权求和+函数代入计算”的工作。
正向传播就是输入数据经过一层一层的神经元运算、输出的过程,最后一层输出值作为算法预测值y'。
(3)反向传播/back propagation是指什么?
前面正向传播的时候我们提到权重w、偏置b,但我们并不知道权重w、偏置b的值应该是什么。关于最优参数的求解,我们在线性回归、逻辑回归两章中有了详细说明。大致来讲就是:
【步骤一】基于算法预测值和实际值之间的损失函数L(y',y):
【步骤二】然后基于梯度下降原理跟新参数:
,这里
是梯度下降学习率。
还记得高中的时候我们求曲线的极大值极小值就是对曲线求导,求导值为0的点一定是个极值点。梯度下降就是通过对参数求偏导获得最优参数的方法。
BP神经网络全称 back propagation neural network,back propagation反向传播是什么?
反向传播的建设本质上就是寻找最优的参数组合,和上面的流程差不多,根据算法预测值和实际值之间的损失函数L(y',y),来反方向地计算每一层的z、a、w、b的偏导数,从而更新参数。
对反向传播而言,输入的内容是预测值和实际值的误差,输出的内容是对参数的更新,方向是从右往左,一层一层的更新每一层的参数。
BP神经网络通过先正向传播,构建参数和输入值的关系,通过预测值和实际值的误差,反向传播修复权重;读入新数据再正向传播预测,再反向传播修正,...,通过多次循环达到最小损失值,此时构造的模型拥有最优的参数组合。
(4)案例详解
以一个简单的BP神经网络为例,由3个输入层,2层隐藏层,每层2个神经元,1个输出层组成。

首先做正向传播操作。
【输入层】传入
【第一层隐藏层】
对于
神经元而言,传入
,加权求和加偏置激活函数处理后,输出
;
对于
神经元而言,传入
,加权求和加偏置函数处理后,输出
;
输出:
【第二层隐藏层】
对于
神经元而言,传入
,加权求和加偏置激活函数处理后,输出
;
对于
神经元而言,传入
,加权求和加偏置激活函数处理后,输出
;
输出:
【输出层】
对于输出层神经元而言,输入
,加权求和加偏置激活函数处理后,输出
,输出的是一个值
第一次运行正向传播这个流程时随用随机参数就好,通过反向传播不断优化。因此需要在一开始对
设置一个随机的初始值。
然后反向传播修正参数
首先计算正向传播输出值
与实际值的损失
,是一个数值。所谓反向是从右到左一步步来的,先回到
,修正参数
。
以此类推,通过对损失函数求偏导跟新参数
,再跟新参数
。这时又回到了起点,新的数据传入又可以开始正向传播了。
(5)基于keras的代码构建
keras可以快速搭建神经网络,例如以下为输入层包含7129个结点,一层隐藏层,包含128个结点,一个输出层,是二分类模型。
import kerasmodel=keras.Sequential()model.add(keras.layers.Dense(7129,input_dim=7129,kernel_initializer='normal',activation='tanh'))model.add(keras.layers.Dense(128,kernel_initializer='normal',activation='tanh'))model.add(keras.layers.Dense(2,kernel_initializer='normal',activation='softmax'))model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])history=model.fit(x_train,y_train,epochs=6,batch_size=200,verbose=1)# 一个epoch=所有训练样本的一个正向传递和一个反向传递
神经网络反向传播的优化目标为loss,可以观察到loss的值在不断的优化。

可以通过model.get_layer().get_weights()获得每一层训练后的参数结果。通过model.predict()预测新数据。
(6)如何解决非线性问题?
至此,BP神经网络的整个运算流程已经过了一遍。之前提到BP神经网络是为解决非线性问题应运而生的,那么为什么BP神经网络可以解决非线性问题呢?
还记得神经元里有一个激活函数的操作吗?神经网络通过激活函数的使用加入非线性因素。
通过使用非线性的激活函数可以使神经网络随意逼近复杂函数,从而使BP神经网络既可以处理线性问题,也可以处理非线性问题。
为什么激活函数的使用可以加入非线性因素[7]?
【线性和非线性的理解】
区分线性模型和非线性模型,主要是看一个乘法式子中自变量x前的系数w,如果w只影响一个x,那么此模型为线性模型。
例如:
任意
只影响一个
,所以是线性函数
任意
不仅被
影响,还受到
的影响,所以是非线性函数
【激活函数加入的非线性因素】
以上述案例为例,神经元H11输出为
(线性)
神经元H12输出为
(线性)
到第二层神经元H21
此时的任意
不仅被
影响,还受到
的影响,所以是非线性函数。
激活函数就是这样加入的非线性因素的
三、算法拓展
(1)和逻辑回归的关系
其实逻辑回归算法可以看作只有一个神经元的单层神经网络,只对线性可分的数据进行分类。
输入参数,加权求和,sigmoid作为激活函数计算后输出结果,模型预测值和实际值计算损失Loss,反向传播梯度下降求编导,获得最优参数。

BP神经网络是比 Logistic Regression 复杂得多的模型,它的拟合能力很强,可以处理很多 Logistic Regression处理不了的数据,但是也更容易过拟合。
具体用什么算法还是要看训练数据的情况,没有一种算法是使用所有情况的。
(2)和前馈型网络的关系
前馈型网络
各神经元接收前一层的输入,并输出给下一层,没有反馈。
节点分为两类,即输入节点和计算节点,每一个计算节点可有多个输入,但只有一个输出,通常前馈型网络可分为不同的层,第i层的输入只与第[i-1]层的输出相连,输入与输出节点与外界相连,而其他中间层则称为隐层。
常见的前馈神经网络有BP网络,RBF网络等。
(3)BP神经网络优缺点
BP神经网络的一个主要问题是:结构不好设计。
网络隐含层的层数和单元数的选择尚无理论上的指导,一般是根据经验或者通过反复实验确定。
但是BP神经网络简单、易行、计算量小、并行性强,目前仍是多层前向网络的首选算法。
作者:巴拉巴拉_9515
链接:https://www.jianshu.com/p/9037890c9b65
来源:
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。