轻量级分布式日志管理系统Graylog、Loki及ELK的分析和对比
1. 为什么需要集中的日志系统?
在分布式系统中,众多服务分散部署在数十台甚至是上百台不同的服务器上,要想快速方便的实现查找、分析和归档等功能,使用Linux命令等传统的方式查询到想要的日志就费时费力,更不要说对日志进行分析与归纳。
如果有一个集中的日志系统,便可以将各个不同的服务器上面的日志收集在一起,不仅能方便快速查找到相应的日志,还有可能在众多日志数据中挖掘到一些意想不到的关联关系。
作为DevOps工程师,会经常收到分析生产日志的需求。在机器规模较少、生产环境管理不规范时,可以通过分配系统账号,采用人肉的方式登录服务器查看日志。然而高可用架构中,日志通常分散在多节点,日志量也随着业务增长而增加。当业务达到一定规模、架构变得复杂,靠人肉登录主机查看日志的方式就会变得混乱和低效。解决这种问题的方法,需要构建一个日志管理平台:对日志进行汇聚和分析,并通过Web UI授权相关人员查看日志权限。
2. 日志系统选择与对比
关于企业级日志管理方案,比较主流的是ELK stack和Graylog。
常见的分布式日志系统解决方案有经典的ELK和商业的splunk。为什么没有选择上面的两种方案呢,原因主要是如下两种:
- ELK目前很多公司都在使用,是一种很不错的分布式日志解决方案,但是需要的组件多,部署和维护相对复杂,并且占用服务器资源多,此外kibana也在高版本中开始商业化。
- splunk是收费的商业项目,不在考虑范围。
3. 认识graylog

3.1 简介
graylog是一个简单易用、功能较全面的日志管理工具,graylog也采用Elasticsearch作为存储和索引以保障性能,MongoDB用来存储少量的自身配置信息,master-node模式具有很好的扩展性,UI上自带的基础查询与分析功能比较实用且高效,支持LDAP、权限控制并有丰富的日志类型和标准(如syslog,GELF)并支持基于日志的报警。
在日志接收方面通常是网络传输,可以是TCP也可以是UDP,在实际生产环境量级较大多数采用UDP,也可以通过MQ来消费日志。
3.2 优势
- 部署维护简单
- 资源占用较少
- 查询语法简单易懂(对比ES的语法…)
- 内置简单的告警
- 可以将搜索结果导出为 json
- UI 比较友好
3.3 graylog单机架构图

3.4 graylog集群架构
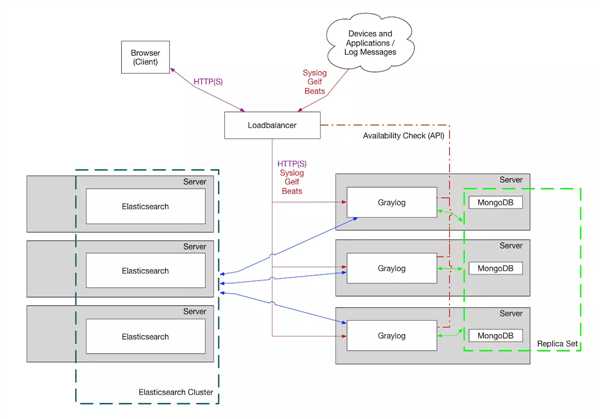
4、基于 GrayLog & ELK 的日志监控
Collector
FileBeat:轻巧占用资源少,但是功能有点弱。「想起了一些东西,都是泪」
Fluentd:个人理解在Logstash与FileBeat中间,可以简单处理一些日志,插件丰富「要再研究下」
自己弄:架构图里面只是mysql调用了自己实现的解析工具,但是其实当日志大到一定的量的还是必须自己来的,类似日志抽样、降级、控制频率等功能,是要真真切切的花费大量时间精力下去的一个sidecar并非动动嘴巴就能搞定的。「都是泪」
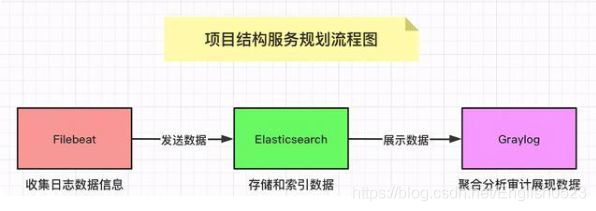
Queue
Kafka:王者地位「量小的时候也可以不用这个直接朝后面输出,有很多中间方案大家自己脑补」,不同的日志分不同的topic,严格区分日志所属类型,为后续消费打下基础,比如A业务进入A Topic并在日志中打上所属语言类型的Tag。
Consumer
Logstash:其实这个东西也可以作为收集端来使用,就是比较耗费资源有点重,还会莫名其妙挂了「应该是我不会玩」
GrayLog:本人最喜欢的一个组件,集解析、报警、简单分析、Dashboard、日志TTL的综合体,有这个东西吧其实Kibana就没啥用了,毕竟谁没事天天去分析日志。
Storage
ElasticSearch:全文索引Engine,其实并没有官方说的那么牛,当到一定的并发写入、大量查询之后其实根本不是加机器能解决的,怎么分shard,是按照天保存还是按照条数保存「我比较喜欢按照条数保存,这样可以保证每个index都差不多大小,对于reblance是有好处的,重复利用多盘」如何保存是需要不断调整的。「我们这边不讨论MongoDB去存日志,看着都不靠谱」
规范
其实日志系统最关键的是怎么打、什么格式打、但是这个东西需要消耗大量的时间去定义与各个部门Pk,遇到过大量不讲理的输出,直接线上Debug,600k的并发写入,日志又大又臭谁能扛得住「阿里云的SLS是真的很牛」
卷起袖子加油干,少动嘴,多动手,日志很好玩。在容器化的大环境下也越发的重要。


Flunted + Elasticsearch + Kibana的方案,发现有几个缺点:
-
不能处理多行日志,比如Mysql慢查询,Tomcat/Jetty应用的Java异常打印
-
不能保留原始日志,只能把原始日志分字段保存,这样搜索日志结果是一堆Json格式文本,无法阅读。
-
不符合正则表达式匹配的日志行,被全部丢弃。
| Graylog | ELK | Loki |
| Graylog是一个强大的平台,基于Scala语言开发。使用它能很容易对结构化和非结构化日志进行管理以及调试应用程序。它依赖Elasticsearch和MongoDB。Graylog的主服务从客户端节点获取数据,同时还提供Web接口,方便用户可视化聚合来的日志。 Graylog的优点包括以下方面: 1.免费的开源工具 2.相比ELK更优秀的报警功能 3.更好的交互,通过跟踪Graylog收到的错误堆栈,工程师可以了解源代码中的上下文。这大量节省了排错的时间和精力 4.强大的搜索功能,支持TB级别的查询 5.有归档功能,超过30天的所有内容都可以存储在廉价存储中,在出现查询需求时,可以重新导入到Graylog 6.Python库支持 |
目前,最著名的开源日志管理解决方案应该是ELK Stack,之所以称为Stack,是因为它不是一个软件包,而是由同一个团队开发的开源工具组合:Elasticsearch、Logstash、Kibana、及周边工具。 Elasticsearch:是一个非常强大和高度可伸缩的搜索引擎,可以存储大量数据并作为集群使用。在ELK Stack中主要存储收集来的日志,并根据设置的索引,进行日志检索。 Logstash:具有许多功能的日志转发器。支持多种类型的输入、过滤和输出。此外,Logstash可以处理许多编解码器,例如Json。 Kibana:用户界面,可以查看日志条目、创建炫酷的仪表盘。 ELK Stack的优点: 1.成名更早 2.知名度更高 |
|
【本文未完待续……敬请后期作者空了贴详细比较!】
总结
虽然两种解决方案在功能上非常相似,但仍有一些差异需要考虑。
两者之间最重要的区别在于,从一开始,Graylog就定位为强大的日志解决方案,而ELK则是大数据解决方案。 Graylog可以通过网络协议直接从应用程序接收结构化日志和标准syslog。相反,ELK是使用Logstash分析已收集的纯文本日志的解决方案,然后解析并将它们传递给ElasticSearch。
在ELK中,Kibana扮演仪表盘的角色并显示从Logstash收到的数据。Graylog在这点上更方便,因为它提供了单一应用程序解决方案(不包括ElasticSearch作为灵活的数据存储),具有几乎相同的功能。因此,部署所需的时间更短。此外,与ELK相比,Graylog开箱即用,且具有出色的权限系统,而Kibana则不具备此功能。作为Elasticsearch的粉丝,我更喜欢Graylog而不是ELK,因为它完全符合我在日志管理方面的需求。
Graylog具有直观的GUI,并提供警报、报告和自定义分析功能。最重要的是,它能在多个日志源和跨机房收集数TB的数据。基于这些优势,我更喜欢用Graylog而不是另一个具有类似功能的流行堆栈——ELK。