论文浅尝 | SimKGC:基于预训练语言模型的简单对比知识图谱补全

笔记整理:李雅新,天津大学硕士,研究方向为知识图谱补全
链接:https://dl.acm.org/doi/10.1145/3539597.3570483
动机
知识图谱补全 (KGC) 旨在对已知事实进行推理并推断缺失的链接。基于文本的方法从自然语言描述中学习实体表示,并且具有归纳KGC的潜力。然而,基于文本的方法的性能在很大程度上落后于基于图嵌入的方法,如TransE和RotatE。本文认为基于文本的方法的关键问题是进行有效的对比学习。为了提高学习效率,本文引入了三种类型的负采样: 批批内负采样、批前负采样和作为困难负样本的简单形式的自我负采样。结合InfoNCE损失,本文提出的模型SimKGC在多个基准数据集上的性能大大优于基于嵌入的方法。实验结果显示,在平均倒数秩(MRR)方面,本文的模型在WN18RR上比之前的SOTA模型提高了19%。
亮点
SimKGC的亮点主要包括:
(1)受对比学习的启发,引入三种类型的负采样来提升基于文本的KGC方法:批内负采样、批前负采样和自我负采样;
(2) 如果两个实体在知识图谱中通过一条短路径连接,两个实体更有可能相互关联。但是基于文本的KGC方法严重依赖语义匹配,而在一定程度上忽略了这种拓扑偏差,因此本文提出一种简单的重排策略,来缓解此类现象。
概念及模型
问题定义
知识图谱G是有向图,其中E表示实体,每个边可以表示为三元组 (h,r,t),其中h,r和t分别对应头实体,关系和尾实体。KGC的链接预测任务是在给定不完整G的情况下推断丢失的三元组。在广泛采用的实体排名评估协议下,尾实体预测 (h,r,?) 要求对给定h和r的所有实体进行排名,头实体预测 (?,r,t)与之类似。在本文中,对于每个三元组 (h,r,t),我们添加一个逆三元组 (t,r − 1,h),其中r − 1是r的逆关系。基于这样的重构,本文只需要处理尾部实体预测问题。
模型架构
SimKGC采用双编码器结构,使用相同的预训练模型初始化两个编码器但不共享参数。
给定一个三元组(h,r,t),第一个编码器BERT_hr用于计算头实体h的关系感知嵌入,本文不是直接使用第一个token的隐藏状态,而是使用均值池化和L2归一化来获得关系感知的嵌入ehr。类似地,第二编码器BERTt用于计算尾部实体t的嵌入et,BERTt的输入仅由实体t的文本描述组成。然后计算余弦相似度cos(ehr,et)
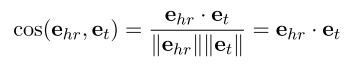
对于尾部实体预测 (h,r,?),计算ehr与E中所有实体之间的余弦相似性,并预测得分最大的实体:
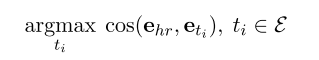
负样本
本文提出了三种负采样方法来提高训练效率。
批内负采样(IB):这是在视觉表征学习和密集文本检索等方面被广泛采用的策略。 同一批中的实体可以用作负样本。这种批内负样本允许双编码器模型有效重用实体嵌入。
批前负采样(PB):批内负采样的缺点是负采样的数量与批次大小相关。批前负采样使用来自先前批次的实体嵌入。由于这些嵌入是用前几轮训练的模型参数计算的,所以它们与批内负采样不一致。通常只使用1或2个前批次。
自负采样(SN):除了增加负样本的数量外,挖掘困难负样本对于改进对比表示学习也很重要。对于尾部实体预测 (h,r,?),基于文本的方法倾向于为头部实体h分配高分,这可能是因为文本重叠程度较高。为了缓解这个问题,本文提出了使用头部实体h困难负采样的自负样本。引入自我负样本可以减少模型对虚假文本匹配的依赖。
在训练过程中,将假阴性的样本去除,负样本集合可表示为:
![]()
基于图的重排策略
知识图谱通常具有空间局限性,与距离较远的实体相比,附近的实体更有可能相关。基于文本的方法擅于捕获语义相关性但无法捕获这种偏差,本文提出一种简单的重排策略:如果ti位于头部实体h的k-hop邻居Ek(h) 中,则根据训练集中的图将候选尾部实体ti的得分提高 α ≥ 0:
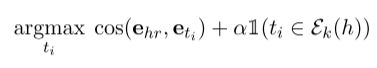
损失
在训练过程中,使用具有附加余量的InfoNCE损失
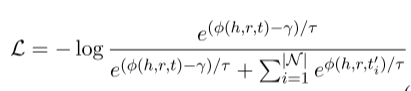
实验
本文使用的四个数据集如下所示:
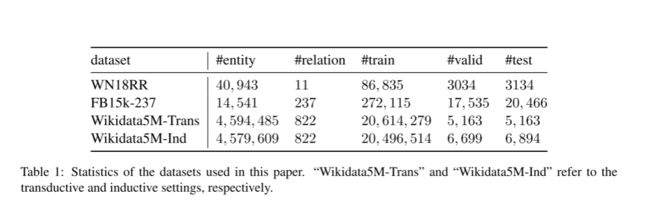
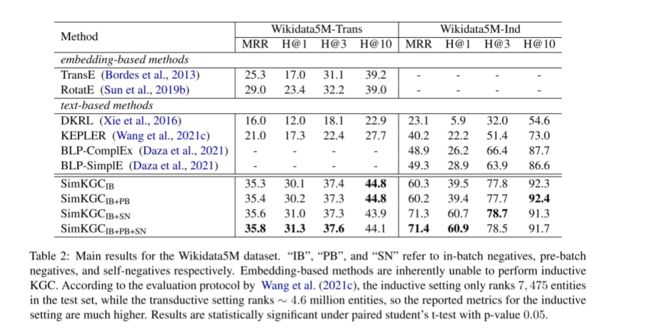
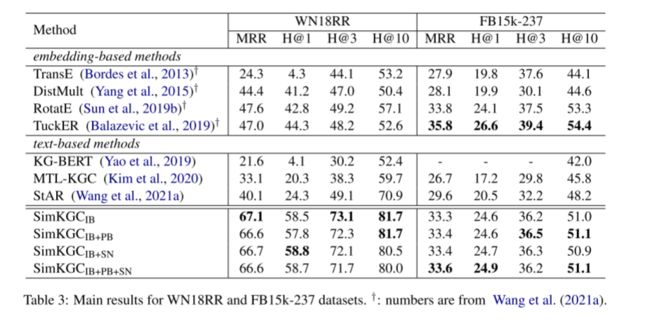
实验结果如下所示,本文提出的模型SimKGCIB + PB + SN在WN18RR、Wikidata5M-Trans和Wikidata5M-Ind数据集上的性能大大优于现有方法,但在FB15k-237数据集上略有落后 (MRR 33.6% vs 35.8%)。实验结果显示,仅使用批内负采样,SimKGC的表现就已经十分优异。
添加自负样本对于具有归纳设置的wikidata5m数据集很有帮助,MRR从60.3% 上升到71.3%。对于归纳KGC,基于文本的模型更依赖文本匹配。自负样本可以阻止模型简单地预测给定的头部实体。
总结
本文提出了一种简单的SimKGC方法来改进基于文本的知识图谱补全。本文认为基于文本的知识图谱补全的关键问题是如何进行有效的对比学习。利用对比学习领域的最新进展,SimKGC采用了双编码器体系结构,并结合了三种负采样策略。在WN18RR,FB15k-237和Wikidata5M数据集上的实验表明,SimKGC的性能大大优于SOAT的方法。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。