vLLM源码之分离式架构
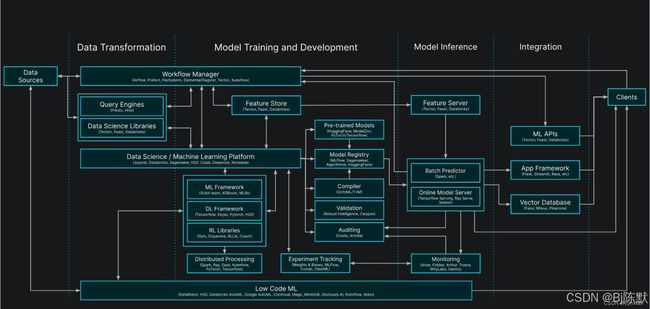
一、vLLM分离式架构概述
1. 基本概念
vLLM是一个用于高效地服务大语言模型(LLM)推理的库。其分离式架构是一种创新的设计理念,旨在优化LLM的运行效率。
这种架构将模型执行的不同阶段进行分离处理,主要包括请求处理、模型执行和结果输出等关键环节。
2. 设计目的
提升吞吐量。通过分离式架构,可以并行处理多个请求,避免不同请求在处理过程中的相互干扰,充分利用硬件资源,特别是在处理高并发请求时能显著提高系统的吞吐量。
优化内存使用。不同的模块可以有针对性地管理内存,例如在模型执行模块中,能够更有效地对模型参数和中间计算结果的内存进行分配和释放,减少内存碎片和不必要的内存占用。
二、关键组件及其分离机制
1. 请求队列(Request Queue)
功能:
这是分离式架构的前端组件,负责接收来自外部的请求。它会对请求进行初步的整理和排队,确保请求按照一定的顺序进入系统。
实现机制:
采用先进先出(FIFO)或基于优先级的队列管理方式。对于一些紧急或高优先级的请求,如来自关键业务场景的请求,可以赋予较高的优先级,使其能够优先进入模型执行阶段。同时,请求队列还可以进行请求的预处理,例如对请求的格式进行校验和转换,确保其符合后续模型执行的要求。
2. 模型执行引擎(Model Execution Engine)
功能:
这是核心组件,负责执行大语言模型的计算。它从请求队列中获取请求,并将请求数据输入到模型中进行推理计算。
实现机制:
采用了优化的张量并行和流水线并行技术。在张量并行方面,将模型的张量计算分配到多个GPU或其他计算单元上同时进行,加速模型的计算速度。例如,对于一个大型Transformer模型,其注意力机制和前馈神经网络的张量计算可以被分解到不同的计算单元上。在流水线并行方面,将模型的不同层划分为多个阶段,形成流水线作业,每个阶段在不同的计算单元上执行,这样当一个批次的输入在第一层计算时,下一批次的输入可以在前一批次进入第二层计算时开始进入第一层,提高了硬件利用率。
3. 缓存机制(Caching Mechanism)
功能:
为了减少重复计算,vLLM的分离式架构中包含了缓存组件。它用于存储模型已经计算过的结果,当遇到相似的请求时,可以直接从缓存中获取结果,而无需再次执行模型计算。
实现机制:
采用了基于键值对(Key Value)的缓存结构。通常以请求中的关键特征(如输入文本的哈希值等)作为键,以模型计算得到的结果作为值。同时,缓存机制还会定期对缓存进行清理和更新,避免缓存数据过期或占用过多的内存。例如,当模型参数更新后,相关的缓存数据需要被清除,以确保后续计算的准确性。
4. 结果输出组件(Result Output Component)
功能:
负责将模型执行引擎产生的结果进行整理和输出。它将结果按照请求的顺序或优先级进行排列,并将其返回给外部请求方。
实现机制:
在输出结果时,会对结果进行后处理,例如对模型生成的文本进行格式化、添加必要的标识等。同时,结果输出组件还会与请求队列进行交互,更新请求的状态,告知请求方其请求已经处理完成。
三、分离式架构的优势与挑战
1. 优势
可扩展性强:
由于各个组件是分离的,在需要扩展系统性能时,可以独立地对某一个组件进行升级或扩展。例如,当需要处理更多的请求时,可以增加请求队列的容量或者扩展模型执行引擎中的计算单元数量。
灵活性高:
可以方便地集成不同的大语言模型到vLLM架构中。因为模型执行引擎是相对独立的模块,只要符合一定的接口规范,就可以将新的模型引入系统进行推理计算。
资源优化:
不同组件可以根据自身的需求进行资源分配。如模型执行引擎可以根据模型的复杂度和计算需求,合理地分配GPU内存和计算资源,而请求队列和结果输出组件可以在CPU上高效运行,实现了不同硬件资源在系统中的合理配置。
2. 挑战
组件间通信开销:
由于各个组件是分离的,组件之间的通信成本可能会增加。例如,请求队列将请求传递给模型执行引擎,以及模型执行引擎将结果返回给结果输出组件时,需要进行数据传输和同步操作。如果处理不当,可能会导致系统性能下降。
一致性维护:
在有缓存机制和多组件协同工作的情况下,需要确保数据的一致性。当模型参数更新或者缓存数据发生变化时,需要保证整个系统的各个组件都能及时感知并做出相应的调整,否则可能会导致错误的结果输出。