上海大学计算机体系结构实验四 HPL安装和测试(虚拟机centos7.6环境下保姆级教程!)
上海大学计算机体系结构实验四 HPL安装和测试(虚拟机centos7.6环境下保姆级教程!)
CSDN上的安装测试有很多,但在实际安装过程中经常碰到博客的教程缺了中间的某个指令,或者漏了某个配置(写的不完全)导致报错的情况,一波三折下来直接心态搞崩,不过好在最后终于是成功了。
特此我详细记录下本次HPL安装和测试的过程,给自己一个参考,也给其他人一个参考。(本过程仅在我的centos7.6虚拟机上安装成功,若有其他报错问题可以评论区告诉我)
一. 实验环境
软件环境:
-
Linux(CentOS 7.6)
-
GCC和GFortran(编译器)
-
BLAS-3.8.0(用来做矩阵计算或者向量计算的库)
-
CBLAS(是BLAS的C语言接口)
-
MPICH-3.2.1(用于并行运算的工具)
-
HPL-2.3。
接下来的安装顺序也是按照BLAS-3.8.0->CBLAS->MPICH-3.2.1->HPL-2.3来进行。
二. 环境搭建
1、安装配置GCC和GFortran(这很重要,后面可能有人会出现G77不存在的报错,需要修改为GFortran)
检查环境:
gfortran -v
gcc -v
安装GCC和Fortran
sudo yum install gcc
sudo yum install gcc-gfortran
接下来的所有安装过程均在用户权限下完成,不要使用su进入root权限进行安装,否则会出现一些奇怪的错误(比如权限问题)
2、下载安装BLAS-3.8.0(用来做矩阵计算或者向量计算的库)
2.1首先进入主目录,一般是/home/(你的usr名称)页面,一般点击下图的主目录即可。
2.2 直接在主目录右键打开终端,通过wget指令联网(虚拟机要能够联网)下载BLAS-3.8.0,然后解压在主目录即可。
wget http://www.netlib.org/blas/blas-3.8.0.tgz
tar -xzf blas-3.8.0.tgz
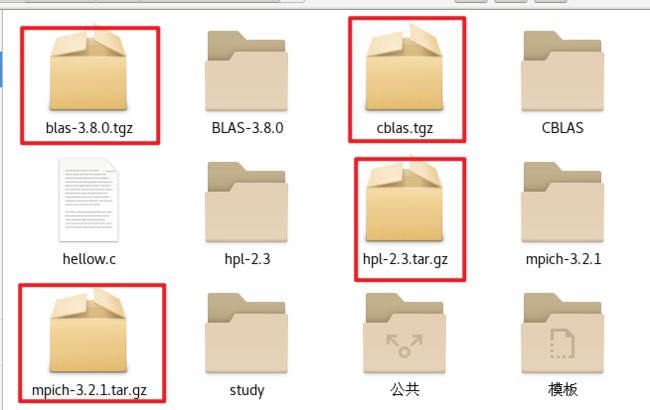
解压完成后如下图所示会出现两个文件,左边一个是下载的压缩包,右边那个是解压完成后的文件夹

2.3 输入下面两条指令编译生成blas_LINUX.a文件:make命令
![]()
cd BLAS-3.8.0
make
2.4 链接.o文件生成libblas.a文件
ar rv libblas.a *.o
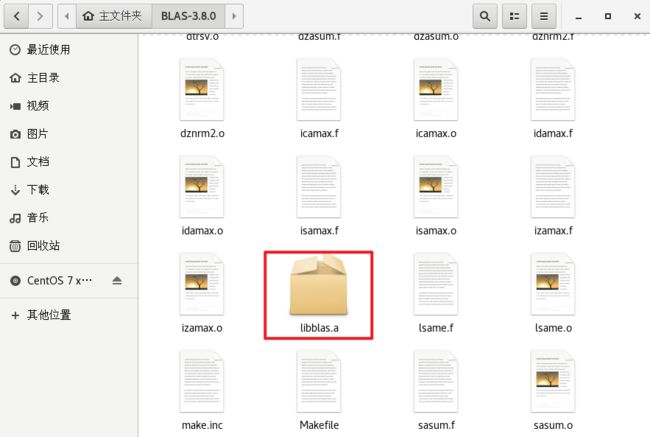
BLAS-3.8.0文件夹下应该能够找到libblas.a文件
2.5 复制一份blas_LINUX.a和libblas.a库文件到系统/usr/local/lib目录下(后续安装hpl配置环境时需要用到)
sudo cp blas_LINUX.a /usr/local/lib
至此BLAS-3.8.0安装完成
3、安装CBLAS(是BLAS的C语言接口)
3.1 回到主目录右键打开终端,输入指令下载cblas.tgz并解压
wget http://www.netlib.org/blas/blast-forum/cblas.tgz
tar -xzf cblas.tgz
解压完成后主目录出现如下图所示左边一个是下载的压缩包,右边那个是解压完成后的文件夹。

3.2 进入CBLS文件夹下,使用绝对路径将处于BLAS-3.8.0文件夹下的blas_LINUX.a库文件拷贝到CBLS文件夹下
cd CBLAS
cp /home/ldw(你的用户名称这里我是ldw)/BLAS-3.8.0/blas_LINUX.a ./
3.3 编译CBLS,CBLAS安装目录下的lib目录中产生一个静态链接库文件 cblas_LINUX.
首先将上一步编译成功的 libblas.a 复制到 CBLAS目录下的testing子目录
make命令编译所有的目录
这两句会在CBLAS安装目录下的lib目录中产生一个静态链接库文件 cblas_LINUX.a文件,后需要用到
cp /home/ldw(你的用户名称这里我是ldw)/BLAS-3.8.0/libblas.a testing
make

3.4 修改 Makefile.in 文件中的 BLLIB字段
vim Makefile.in
BLLIB = /home/ldw(你的用户名称这里我是ldw)/BLAS-3.8.0/blas_LINUX.a
修改完成后按ESC,然后输入“:wq”,最后按下回车键进行保存。

3.5 复制一份cblas_LINUX.a库文件到系统/usr/local/lib目录下(后续安装hpl配置环境时需要用到)
sudo cp lib/cblas_LINUX.a /usr/local/lib
/usr/local/lib目录下的文件,(后面两个文件没有也不要紧,如果后面发生了报错,可以从bblas和cblas文件夹下找到,然后复制进去)
![]()
3.6 测试运行(hpl安装完成后可以返回进行测试)
后续hpl若配置成功,会在cblas/testing文件夹下出现一些可执行文件,用来测试最终是否成功,hpl配置完成后可以回到此处进行二次检查(有的博客不需要hpl配置完成也会有,我不知道为什么,但是我配置时,安装完成cblas后并没有出现,只有当安装完成hpl才出现,大家根据情况自行测试)。
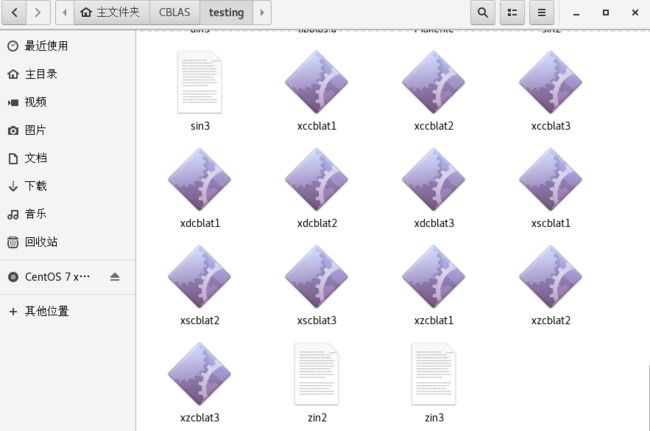
挑一个进行测试运行
./testing/xzcblat1

4、安装MPICH-3.2.1(用于并行运算的工具)
4.1 回到主目录右键打开终端,输入指令下载并解压mpich-3.2.1.tar.gz
wget http://www.mpich.org/static/downloads/3.2.1/mpich-3.2.1.tar.gz
tar xzf mpich-3.2.1.tar.gz
解压完成后在主目录下会出现该文件夹

4.2 输入下面两条指令进入mpich文件夹下并设置安装路径
这里的安装路径就是最终真正的安装路径,也是后面环境变量配置的位置。若想安装于其他位置只需要修改prefix=后面的即可,但环境变量也需要同步修改。(已修改,感谢同学指出问题)
cd mpich-3.2.1/
./configure --disable-cxx --prefix=/home/mpich-install 2>&1 | tee c.txt
4.3 编译
make 2>&1 | tee m.txt
4.4 安装
sudo make install 2>&1 | tee mi.txt
4.5 配置环境变量
重要:上面的步骤完成后,我们可以在/home文件夹下看到mpich-install文件夹,这个才是我们mpich真正安装的位置!后续hpl安装配置环境的时候用到的都是/home/mpich-install文件夹作为mpi安装的路径,而不是主目录下的!这一点坑了我好久
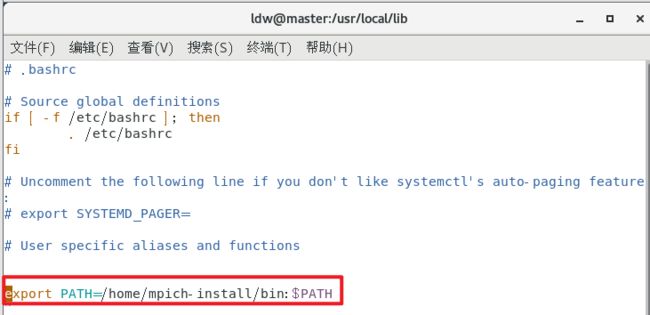
用vim配置环境同时用source命令重新加载配置
vim ~/.bashrc
export PATH=/home/mpich-install/bin:$PATH
source ~/.bashrc
4.6 查看前面工作是否成功
若出现mpicc未找到,则可能是上一步配置的环境出现了错误,不要配成/home/ldw(你的用户名称,这里我是ldw)/mpich-3.2.1,这个路径是错误的,不是mpi真正安装的地方,要与安装路径一致,可返回查看4.2
which mpicc && which mpiexec
mkdir machinefile
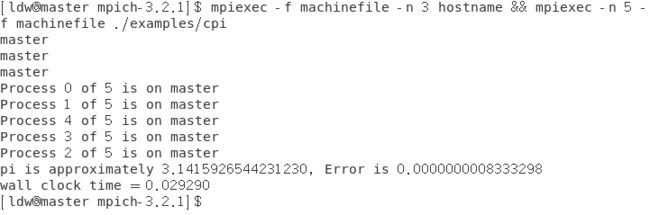
mpiexec -f machinefile -n 3 hostname && mpiexec -n 5 -f machinefile ./examples/cpi
最后一条指令会出现如下的运行结果
5、安装HPL-2.3
5.1 查看/usr/local/lib目录下是否存在blas_LINUX.a和cblas_LINUX.a文件,若没有,请仔细阅读上文的步骤2和3的结尾部分,需要复制一份进去。
/usr/local/lib目录下的文件,(后面两个文件没有也不要紧,如果后面发生了报错,可以从bblas和cblas文件夹下找到,然后复制进去)
![]()
5.2 回到主目录右键打开终端,输入指令下载并解压hpl测试包
wget http://www.netlib.org/benchmark/hpl/hpl-2.3.tar.gz
tar -xzf hpl-2.3.tar.gz
5.3 进入hpl-2.3文件夹,将setup文件夹下的Make.Linux_PII_CBLAS文件复制到hpl-2.3文件夹下(手动进入setup文件夹复制也行)。
cd hpl-2.3/
cp setup/Make.Linux_PII_CBLAS ./
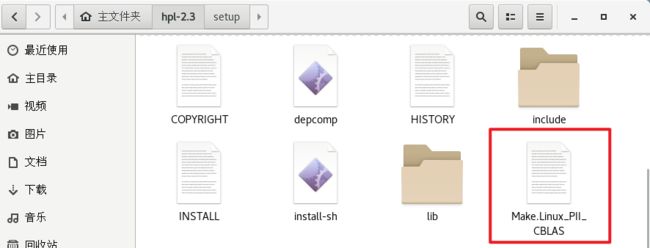
5.4 配置环境参数(这一步极其重要,配错了就GG)
vim Make.Linux_PII_CBLAS



![]()


配置完成后按ESC,然后输入“:wq”,最后按下回车键进行保存。
5.5 编译
make arch=Linux_PII_CBLAS
编译完成后在bin文件夹下会生成一个xhpl文件。
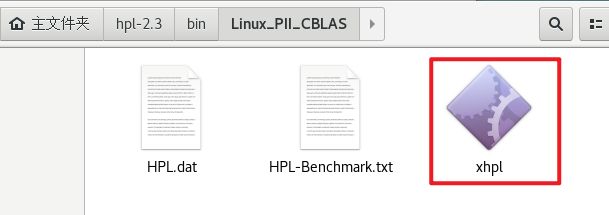
遇到libmpich.a文件缺少就是因为配置环境时mpich路径输入错误,不是主目录那个,而是/home/mpich-install那个
5.6 运行测试,将测试结果写入到HPL-Benchmark.txt文件中。
cd bin/Linux_PII_CBLAS
mpirun -np 4 ./xhpl > HPL-Benchmark.txt
测试结果文件长这样:

至此hpl安装成功!可以返回到步骤3进行CBLAS的二次测试
三、hpl的测试
3.1 查看cpu详细参数:
cat /proc/cpuinfo
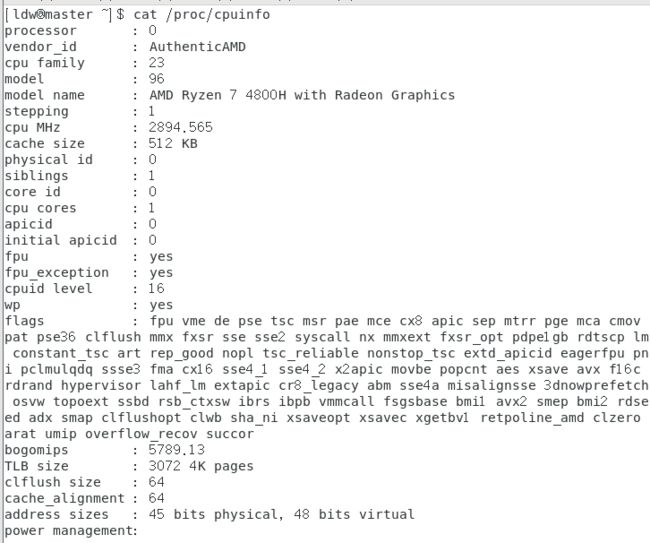
本虚拟机的逻辑cpu共有4个编号为0、1、2、3,分别属于4个物理cpu,编号分别为1、2、4、6,cpu主频为2894.565mhz(2.894565GHZ),每个cpu有一个核心,AMD的浮点运算单元数=8。
因此,本机器的分值计算速度=2.9GHz * 4 * 8=92.8Gflops
实验书上的描述:
1 修改HPL.dat设置运行参数
在HPL测试中,使用的参数选择与测试的结果有很大的关系。HPL中参数的设定是通过从一个配置文件HPL.dat中读取的,所以在测试前要改写HPL.dat文件,设置需要使用的各种参数,然后再开始运行测试程序。配置文件内容的结构如下:
HPLinpack benchmark input file //文件头,说明
Innovative Computing Laboratory, University of Tennessee
HPL.out output file name (if any) //如果使用文件保留输出结果,设定文件名
6 device out (6=stdout,7=stderr,file) //输出方式选择(stdout,stderr或文件)
2 # of problems sizes (N) //指出要计算的矩阵规格有几种
1960 2048 Ns //每种规格分别的数值
2 # of NBs //指出使用几种不同的分块大小
60 80 NBs //分别指出每种大小的具体值
2 # of process grids (P x Q-l //指出用几种进程组合方式
2 4 Ps //每对PQ具体的值
2 1 Qs
16.0 threshold //余数的阈值
1 # of panel fact //用几种分解方法
1 PFACTs (0=left, 1=Crout, 2=Right) //具体用哪种,0 left,1 crout,2 right
1 # of recursive stopping criterium //几种停止递归的判断标准
4 NBMINs (>= 1) //具体的标准数值(须不小于1)
1 # of panels in recursion //递归中用几种分割法
2 NDIVs //这里用一种NDIV值为2,即每次递归分成两块
1 # of recursive panel fact. //用几种递归分解方法
2 RFACTs (0=left, 1=Crout, 2=Right) //这里每种都用到(左,右,crout分解)
1 # of broadcast //用几种广播方法
3 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM) //指定具体哪种(有1-ring,1-ring Modified,2-ring,2ring Modified,Long以及long-Modified)
1 # of lookahead depth //用几种向前看的步数
1 DEPTHs (>=0) //具体步数值(须大于等于0)
2 SWAP (0=bin-exch,1=long,2=mix) //哪种交换算法(bin-exchange,long或者二者混合)
64 swapping threshold //采用混合的交换算法时使用的阈值
0 L1 in (0=transposed,1=no-transposed) form //L1是否用转置形式
0 U in (0=transposed,1=no-transposed) form //U是否用转置形式表示
1 Equilibration (0=no,1=yes) //是否采用平衡状态
8 memory alignment in double (> 0) //指出程序运行时内存分配中的采用的对齐方式
要得到调试出高的性能,必须考虑内存大小,网络类型以及拓扑结构,调试上面的参数,直到得出最高性能。
本次实验需要对以下三组参数进行设置:
2 # of problems sizes (N) //指出要计算的矩阵规格有几种
1960 2048 Ns //每种规格分别的数值指出要计算的矩阵规格有2种,规格是1960,2048
2 # of NBs //指出使用几种不同的分块大小
60 80 NBs //分别指出每种大小的具体值指出使用2种不同的分块大小,大小为60,80
2 # of process grids (P x Q-l //指出用几种进程组合方式
2 4 Ps //每对PQ具体的值
2 1 Qs
指出用2种进程组合方式,分别为(p=2,q=2) 和(p=4,q=1)
注:p=2,q=2时需要的进程数是p×q=2×2=4,运行时mpirun命令行中指定的进程数必须大于等于4
以上3组每组有两种情况,组合后一共有8种情况,将得到8个性能测试值,经过不断的调试将会得出一个最大的性能值,这就是得到的最高性能值。
以下是其中一个性能测试值,规格为2048,分块是60,p=2,q=2时,运行时间为:56.14,运算速度为0.8165 Gflops。PASSED代表结果符合要求。
============================================================================
T/V N NB P Q Time Gflops
\----------------------------------------------------------------------------
W13R2C4 2048 60 2 2 56.14 8.165e-01
\----------------------------------------------------------------------------
||Ax-b||_oo / ( eps * ||A||_1 * N ) = 0.0175089 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_1 * ||x||_1 ) = 0.0035454 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_oo * ||x||_oo ) = 0.0007503 ...... PASSED
============================================================================
设置参数

实际运行结果:
以下是其中一个性能测试值,规格为2048,分块是60,p=2,q=2时,运行时间为:0.30,运算速度为19.137 Gflops。PASSED代表结果符合要求。

3.2 进行性能测试
峰值速度随进程个数变化

其他配置不变,改变p、q的数量完成下列测试数据。
p*q=进程数=cpu个数

矩阵规模=1960,分块数量=60的情况下的一组测试,选择所有测试中峰值速度最大的一组填入表格
| CPU个数 | N | NB | P | Q | Time | Gflops | 参与运算主机名 |
|---|---|---|---|---|---|---|---|
| 1 | 1960 | 60 | 1 | 1 | 0.66 | 7.6447 | Ldw@master |
| 2 | 1960 | 60 | 1 | 2 | 0.34 | 14.800 | Ldw@master |
| 3 | 1960 | 60 | 1 | 3 | 0.25 | 20.259 | Ldw@master |
| 4 | 1960 | 60 | 2 | 2 | 0.2 | 24.91 | Ldw@master |
后续还有1960 80、2048 60、2048 80的测试,省略,留给大家自行测试了。。。
3.3 完成上述测试后比较和分析上面的测试结果,特别是如何能够得到高的性能测试值
-
可以看到,当矩阵规模和分块数一定的情况下,CPU个数和计算峰值速度成正比,CPU个数对计算峰值速度有着巨大的影响,CPU个数越多,计算速度越快。
-
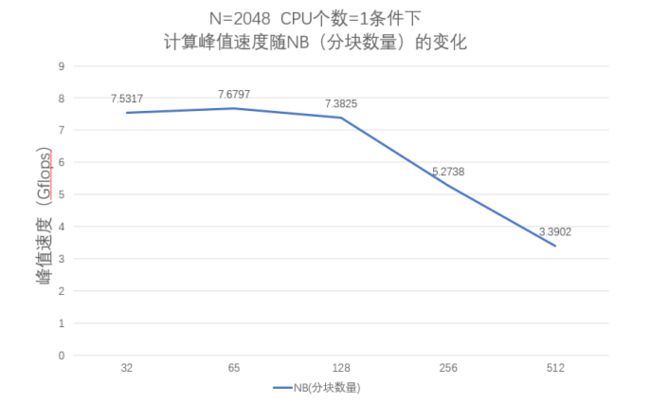
经过多次测试,分块大小对性能有很大的影响,NB的选择和软硬件许多因素密切相关。当矩阵规模一定的情况下,分块数量的提升不一定能够提升计算速度,在本机上,当矩阵规模N=2048,CPU数量=1时,NB分块数量大约在64左右计算峰值能够取到最大值(7.6797)。分块数量需要通过在小规模数据上不断调试而得出。
-
经过测试,p,q的选择对于计算峰值也有较大的影响,从上面的测试数据中可以看到,所有的最佳结果都是在p
因此在测试的时候可以让P=1,Q=n,这样可以在小规模数据时达到最快速度,便于调试出最优的分块大小NB,同时也能够获得高性能的测试值。
参考博客:
https://blog.csdn.net/no1xiaoqianqian/article/details/129223686?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-129223686-blog-51442603.235%5Ev32%5Epc_relevant_increate_t0_download_v2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-129223686-blog-51442603.235%5Ev32%5Epc_relevant_increate_t0_download_v2&utm_relevant_index=2
https://blog.csdn.net/sishuiliunian0710/article/details/20493101?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168377439916800215023273%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168377439916800215023273&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-20493101-null-null.142^v86^control,239^v2^insert_chatgpt&utm_term=%E5%AE%89%E8%A3%85hpl&spm=1018.2226.3001.4187
https://blog.csdn.net/kingdomkitty/article/details/80258364?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168379618616800192282030%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168379618616800192282030&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-80258364-null-null.142^v87^control,239^v2^insert_chatgpt&utm_term=%E5%AE%89%E8%A3%85mpich&spm=1018.2226.3001.4187