nn.embedding笔记
nn.embedding介绍
embedding就是词嵌入,将一个token转化为一个向量,其通常作为nlp模型的一个层.我们通常使用的nn.embedding通常分为两种情况:
①使用别人训练好的nn.embedding,这个时候通过nn.embedding我们能拿到每个token对应的正确向量。
②使用初始化的nn.embedding,这时生成的词向量只是随机的,没有任何意义,然后搭配bert、transformer、rnn等模型使用,在这些模型的训练过程种调整embedding层的参数,拿到正确表示token的词向量。
那么问题来了:
问题:bert不是可以用来为token生成词向量吗?那为什么在传入bert模型之前,就先将token词向量化呢,这个向量化有什么意义呢?
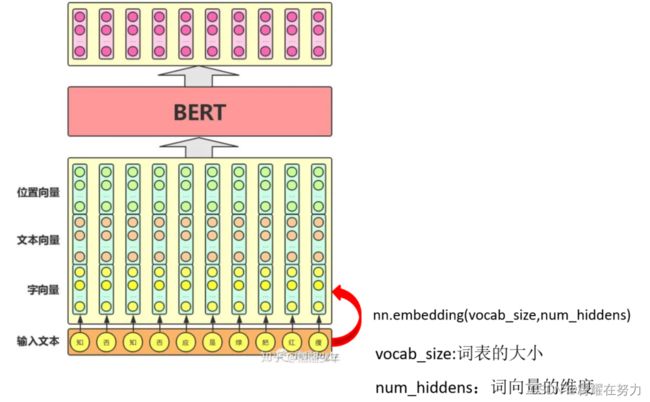
借助别人的图理解一下,图中红色箭头就是nn.embedding操作,将传入bert之前将token向量化,这么做也很为上述的两种情况:
①使用别人训练好的nn.embedding时:这种情况下,虽然这个embedding是别人训练好的,但是如果我们抽取特征生成词向量时,是需要考虑语义背景的呀,随意还是需要用bert去搞一下,抽背景。
②使用初始化的embedding时:其先构建一个vocab_size*num_hiddens的权重矩阵,然后随机初始化生成一组词向量,然后将随机初始化的词向量丢到bert里面,当bert训练时,在来调整权重矩阵,使其具备学习能力。
示例说明:
import torch
import torch.nn as nn
mlm_positions = torch.LongTensor([[1, 5, 2], [6, 1, 5]])
embedding = nn.Embedding(7, 4)
print(mlm_positions)
print(embedding(mlm_positions))第一次运行结果:
tensor([[1, 5, 2],
[6, 1, 5]])
tensor([[[-0.7632, -1.0630, -0.7553, -0.3377],
[ 0.8528, -1.4378, 0.0234, -0.0140],
[ 0.7554, 1.1693, -0.8603, -0.0214]],
[[ 0.1808, 1.1702, 0.0485, 0.1899],
[-0.7632, -1.0630, -0.7553, -0.3377],
[ 0.8528, -1.4378, 0.0234, -0.0140]]], grad_fn=) 第二次运行结果
tensor([[1, 5, 2],
[6, 1, 5]])
tensor([[[-0.9527, 1.1274, 0.0626, -1.6937],
[-0.1026, 0.0796, 0.5292, 1.0623],
[-0.2766, 1.6665, 0.9931, 1.7672]],
[[-0.5824, 0.8142, 1.5110, -0.3676],
[-0.9527, 1.1274, 0.0626, -1.6937],
[-0.1026, 0.0796, 0.5292, 1.0623]]], grad_fn=) 可以看到nn.embedding每次生成的词向量(初始化)都不相同,需要搭配具体的任务调整权重。