Python图像库PIL的类Image及其方法介绍
Python图像库PIL(Python Image Library)是python的第三方图像处理库,但是由于其强大的功能与众多的使用人数,几乎已经被认为是python官方图像处理库了。其官方主页为:PIL。 PIL历史悠久,原来是只支持python2.x的版本的,后来出现了移植到python3的库pillow,pillow号称是friendly fork for PIL,其功能和PIL差不多,但是支持python3。本文主要介绍PIL那些最常用的特性与用法,主要参考自:http://www.effbot.org/imagingbook

PIL可以做很多和图像处理相关的事情:
- 图像归档(Image Archives)。PIL非常适合于图像归档以及图像的批处理任务。你可以使用PIL创建缩略图,转换图像格式,打印图像等等。
- 图像展示(Image Display)。PIL较新的版本支持包括Tk PhotoImage,BitmapImage还有Windows DIB等接口。PIL支持众多的GUI框架接口,可以用于图像展示。
- 图像处理(Image Processing)。PIL包括了基础的图像处理函数,包括对点的处理,使用众多的卷积核(convolution kernels)做过滤(filter),还有颜色空间的转换。PIL库同样支持图像的大小转换,图像旋转,以及任意的仿射变换。PIL还有一些直方图的方法,允许你展
- 示图像的一些统计特性。这个可以用来实现图像的自动对比度增强,还有全局的统计分析等。
图像类Image class
Image类是PIL中的核心类,你有很多种方式来对它进行初始化,比如从文件中加载一张图像,处理其他形式的图像,或者是从头创造一张图像等。Image模块操作的基本方法都包含于此模块内。如open、save、conver、show…等方法。下面是PIL的 Image类中常用的方法和属性:
open方法
Image.open(file) ⇒ image
Image.open(file, mode) ⇒ image
要从文件加载图像,使用 open() 函数, 在 Image 模块(类):
代码如下:-------------------------------------------
from PIL import Image ##调用库,包含图像类
im = Image.open("3d.jpg") ##文件存在的路径,如果没有路径就是当前目录下文件
im.show()
运行结果:----------------------------------------------

需要知道的是在win的环境下im.show的方式为win自带的图像显示应用。打开并确认给定的图像文件。这个是一个懒操作;该函数只会读文件头,而真实的图像数据直到试图处理该数据才会从文件读取(调用load()方法将强行加载图像数据)。如果变量mode被设置,那必须是“r”。用户可以使用一个字符串(表示文件名称的字符串)或者文件对象作为变量file的值。文件对象必须实现read(),seek()和tell()方法,并且以二进制模式打开。
save方法
im.save(outfile,options…)
im.save(outfile, format, options…)
用 Image 类的 save() 方法保存文件的文件,使用给定的文件名保存图像。如果变量format缺省,如果可能的话,则从文件名称的扩展名判断文件的格式。该方法返回为空。关键字options为文件编写器提供一些额外的指令。如果编写器不能识别某个选项,它将忽略它。用户可以使用文件对象代替文件名称。在这种情况下,用户必须指定文件格式。文件对象必须实现了seek()、tell()和write()方法,且其以二进制模式打开。如果方法save()因为某些原因失败,这个方法将产生一个异常(通常为IOError异常)。如果发生了异常,该方法也有可能已经创建了文件,并向文件写入了一些数据。如果需要的话,用户的应用程序可以删除这个不完整的文件。
jpg 转换成png
#----------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im)
im.save("3d.png") ## 将"3d.jpg"保存为3d.png"
im = Image.open("3d.png") ##打开新的png图片
print(im.format, im.size, im.mode)
#-----------------------------------------------
执行 结果:

format属性
im.format ⇒ string or None
这个属性标识了图像来源,如果图像不是从文件读取它的值就是None。
#-----------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.format) ## 打印出格式信息
im.show()
#-----------------------------------------------

mode属性
im.mode ⇒ string
图像的模式,常见的mode 有 “L” (luminance) 表示灰度图像,“RGB”表示真彩色图像,和 “CMYK” 表示出版图像,表明图像所使用像素格式。如下表为常见的nodes描述:
| modes | Description |
| 1 | 1位像素,黑白图像,存成8位像素 |
| L | 8位像素,黑白 |
| P | 9位像素,使用调色板映射到任何其他模式 |
| RGB | 3*8位像素,真彩 |
| RGBA | 4*8位像素,真彩+透明通道 |
| CMYK | 4*8位像素,印刷四色模式或彩色印刷模式 |
| YCbCr | 3*8位像素,色彩视频格式 |
| I | 32位整型像素 |
| F | 33位浮点型像素 |
#---------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.mode) ## 打印模式属性
im.show()
#---------------------------------------------------------
convert方法
im.convert(mode)⇒ image
将当前图像转换为其他模式,并且返回新的图像。当从一个调色板图像转换时,这个方法通过这个调色板来转换像素。如果不对变量mode赋值,该方法将会选择一种模式,在没有调色板的情况下,使得图像和调色板中的所有信息都可以被表示出来。当从一个颜色图像转换为黑白图像时,PIL库使用ITU-R601-2 luma转换公式:
L = R * 299/1000 + G * 587/1000 + B * 114/1000
当转换为2位图像(模式“1”)时,源图像首先被转换为黑白图像。结果数据中大于127的值被设置为白色,其他的设置为黑色;这样图像会出现抖动。如果要使用其他阈值,更改阈值127,可以使用方法point()。为了去掉图像抖动现象,可以使用dither选项。
#-----------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
new_im = im.convert('P')
print(new_im.mode)
new_im.show()
#-----------------------------------------------

P模式
im.convert(“P”,**options) ⇒ image
这个与第一个方法定义一样,但是当“RGB”图像转换为8位调色板图像时能更好的处理。可供选择的选项为:
Dither=. 控制颜色抖动。默认是FLOYDSTEINBERG,与邻近的像素一起承担错误。不使能该功能,则赋值为NONE。
Palette=. 控制调色板的产生。默认是WEB,这是标准的216色的“web palette”。要使用优化的调色板,则赋值为ADAPTIVE。
Colors=. 当选项palette为ADAPTIVE时,控制用于调色板的颜色数目。默认是最大值,即256种颜色
im.convert(mode,matrix) ⇒ image
使用转换矩阵将一个“RGB”图像转换为“L”或者“RGB”图像。变量matrix为4或者16元组。
#-----------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.mode)
rgb2xyz = (0.412453,0.357580, 0.180423, 0,
0.212671,0.715160, 0.072169, 0,
0.019334,0.119193, 0.950227, 0 )
new_im = im.convert("L", rgb2xyz)
print(new_im.mode)
new_im.show()
原图 转换后图
size属性
im.size ⇒ (width, height)
图像的尺寸,按照像素数计算,它的返回值为宽度和高度的二元组(width, height)。
#----------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.size) ## 打印图像尺寸
im.show()
命令行显示图片的尺寸为426*306。

palette属性
im.palette ⇒ palette or None
颜色调色板表格。如果图像的模式是“P”,则返回Image Palette类的实例;否则,将为None。
如下为对非“P”模式下的图像进行palette信息显示。
#----------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.palette)
返回值为none

对图像进行convert操作,转换成“P”模式
#----------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
new_im = im.convert('P')
print(new_im.mode)
print(new_im.palette)
则返回值为ImagePalette类的实例。如下:

info属性
im.info ⇒ dictionary
存储图像相关数据的字典。文件句柄使用该字典传递从文件中读取的各种非图像信息。大多数方法在返回新的图像时都会忽略这个字典;因为字典中的键并非标准化的,对于一个方法,它不知道自己的操作如何影响这个字典。如果用户需要这些信息,需要在方法open()返回时保存这个字典。
#-------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.info)
执行结果:

new方法
Image.new(mode,size) ⇒ image
Image.new(mode, size,color) ⇒ image
使用给定的变量mode和size生成新的图像。Size是给定的宽/高二元组,这是按照像素数来计算的。对于单通道图像,变量color只给定一个值;对于多通道图像,变量color给定一个元组(每个通道对应一个值)。在版本1.1.4及其之后,用户也可以用颜色的名称,比如给变量color赋值为“red”。如果没有对变量color赋值,图像内容将会被全部赋值为0(为黑色)。如果变量color是空,图像将不会被初始化,即图像的内容全为0。这对向该图像复制或绘制某些内容是有用的。
下面将图像设置为128x128大小的红色图像:
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
n_im= Image.new("RGB", (128, 128), "#FF0000")
n_im.show()
效果如下:
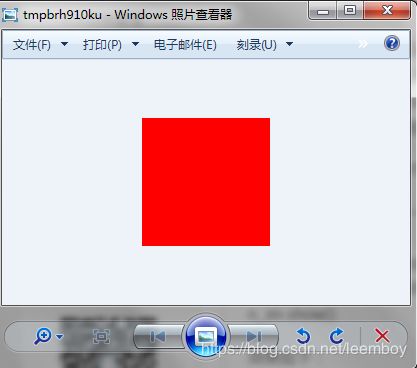
下图像为128x128大小的黑色图像,因为变量color不赋值的话,图像内容被设置为0,即黑色
#------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
n_im= Image.new("RGB", (128, 128))
n_im.show()
图像为128x128大小的绿色图像
#----------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
n_im= Image.new("RGB", (128, 128),"green")
n_im.show()
Copy方法
im.copy() ⇒ image
拷贝这个图像。如果用户想粘贴一些数据到这张图,可以使用这个方法,但是原始图像不会受到影响。
from PIL import Image
im = Image.open("3d.jpg")
im_copy = im.copy()
图像im_copy和im完全一样。
crop方法
im.crop(box) ⇒ image
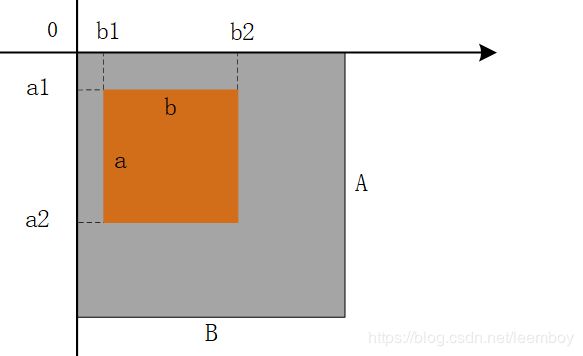
从当前的图像中返回一个矩形区域的拷贝。变量box是一个四元组,定义了左、上、右和下的像素坐标。用来表示在原始图像中截取的位置坐标,如box(100,100,200,200)就表示在原始图像中以左上角为坐标原点,截取一个100*100(像素为单位)的图像,为方便理解,如下为示意图box(b1,a1,b2,a2)。作图软件为Visio2016。这是一个懒操作。对源图像的改变可能或者可能不体现在裁减下来的图像中。为了获取一个分离的拷贝,对裁剪的拷贝调用方法load()。
#-------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
box = (20, 30, 300, 200) ##确定拷贝区域大小
region = im.crop(box) ##将im表示的图片对象拷贝到region中,大小为box
region.show()
#-------------------------------------

paste方法
im.paste(image,box)
将一张图粘贴到另一张图像上。变量box或者是一个给定左上角的2元组,或者是定义了左,上,右和下像素坐标的4元组,或者为空(与(0,0)一样)。如果给定4元组,被粘贴的图像的尺寸必须与区域尺寸一样。如果模式不匹配,被粘贴的图像将被转换为当前图像的模式。
#-------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
box=[0,0,100,100]
im_crop = im.crop(box)
print(im_crop.size,im_crop.mode)
im.paste(im_crop, (100,100)) ##(100,100,0,0)
im.paste(im_crop, (400,400,500,500))
im.show()
#-------------------------------------
filter方法
im.filter(filter) ⇒ image
返回一个使用给定滤波器处理过的图像的拷贝。具体参考图像滤波在ImageFilter 模块的应用,在该模块中,预先定义了很多增强滤波器,可以通过filter( )函数使用,预定义滤波器包括:BLUR、CONTOUR、DETAIL、EDGE_ENHANCE、EDGE_ENHANCE_MORE、EMBOSS、FIND_EDGES、SMOOTH、SMOOTH_MORE、SHARPEN。其中BLUR就是均值滤波,CONTOUR找轮廓,FIND_EDGES边缘检测,使用该模块时,需先导入。
#-------------------------------------
from PIL import Image
from PIL import ImageFilter ## 调取ImageFilter
imgF = Image.open("3d.jpg")
bluF = imgF.filter(ImageFilter.BLUR) ##均值滤波
conF = imgF.filter(ImageFilter.CONTOUR) ##找轮廓
edgeF = imgF.filter(ImageFilter.FIND_EDGES) ##边缘检测
imgF.show()
bluF.show()
conF.show()
edgeF.show()
#------------------------------------
blend方法
Image.blend(image1,image2, alpha) ⇒ image
使用给定的两张图像及透明度变量alpha,插值出一张新的图像。这两张图像必须有一样的尺寸和模式。
合成公式为:out = image1 (1.0 - alpha) + image2 alpha
若变量alpha为0.0,返回第一张图像的拷贝。若变量alpha为1.0,将返回第二张图像的拷贝。对变量alpha的值无限制。
#-------------------------------------
from PIL import Image
im1 = Image.open("3d.jpg")
im2 = Image.open("3dd.jpg")
print(im1.mode,im1.size)
print(im2.mode,im2.size)
im = Image.blend(im1, im2, 0.40)
im.show()
#-------------------------------------
需保证两张图像的模式和大小是一致的。
im1按照40%的透明度,im2按照60%的透明度,合成为一张。
split方法
im.split() ⇒ sequence
返回当前图像各个通道组成的一个元组。例如,分离一个“RGB”图像将产生三个新的图像,分别对应原始图像的每个通道(红,绿,蓝)。
#-------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
r,g,b = im.split()
print(r.mode)
print(r.size)
print(im.size)
#-------------------------------------
composite方法
Image.composite(image1,image2, mask) ⇒ image
复合类使用给定的两张图像及mask图像作为透明度,插值出一张新的图像。变量mask图像的模式可以为“1”,“L”或者“RGBA”。所有图像必须有相同的尺寸。
#-------------------------------------
from PIL import Image
im1 = Image.open("3d.jpg")
im2 = Image.open("3dd.jpg")
r,g,b = im1.split() ##分离出r,g,b
print(b.mode)
print(im1.mode,im1.size)
print(im2.mode,im2.size)
im = Image.composite(im1,im2,b)
im.show()
#-------------------------------------
b.mode为”L”,两图尺寸一致。
eval方法
Image.eval(image,function) ⇒ image
使用变量function对应的函数(该函数应该有一个参数)处理变量image所代表图像中的每一个像素点。如果变量image所代表图像有多个通道,那变量function对应的函数作用于每一个通道。注意:变量function对每个像素只处理一次,所以不能使用随机组件和其他生成器。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
def fun1(x):
return x*0.3
def fun2(y):
return y*2.0
im1_eval = Image.eval(im, fun1)
im2_eval = Image.eval(im, fun2)
im1_eval.show()
im2_eval.show()
#-------------------------------------------------------
merge方法
Image.merge(mode,bands) ⇒ image
合并类使用一些单通道图像,创建一个新的图像。变量bands为一个图像的元组或者列表,每个通道的模式由变量mode描述。所有通道必须有相同的尺寸。
变量mode与变量bands的关系:
len(ImageMode.getmode(mode).bands)= len(bands)
#-------------------------------------------------------
from PIL import Image
im1 = Image.open("3d.jpg")
im2 = Image.open("3dd.jpg")
r1,g1,b1 = im1.split()
r2,g2,b2 = im2.split()
print(r1.mode,r1.size,g1.mode,g1.size)
print(r2.mode,r2.size,g2.mode,g2.size)
new_im=[r1,g2,b2]
print(len(new_im))
im_merge = Image.merge("RGB",new_im)
im_merge.show()
#-------------------------------------------------------
merge操作
draft方法
im.draft(mode,size)
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.size,im.mode)
new_im = im.draft("L", (200,200))
print(new_im.size,new_im.mode)
new_im.show()
#-------------------------------------------------------
关键信息显示
转换效果
getbands方法
im.getbands()⇒ tuple of strings
返回包括每个通道名称的元组。例如,对于RGB图像将返回(“R”,“G”,“B”)。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.getbands())
#-------------------------------------------------------
getbbox方法
im.getbbox() ⇒ 4-tuple or None
计算图像非零区域的包围盒。这个包围盒是一个4元组,定义了左、上、右和下像素坐标。如果图像是空的,这个方法将返回空。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.getbbox())
#-------------------------------------------------------
getdata方法
im.getdata() ⇒ sequence
以包含像素值的sequence对象形式返回图像的内容。这个sequence对象是扁平的,以便第一行的值直接跟在第零行的值后面,等等。这个方法返回的sequence对象是PIL内部数据类型,它只支持某些sequence操作,包括迭代和基础sequence访问。使用list(im.getdata()),将它转换为普通的sequence。Sequence对象的每一个元素对应一个像素点的R、G和B三个值。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
sequ = im.getdata()
sequ0 = list(sequ)
print(sequ0[0])
print(sequ0[1])
print(sequ0[2])
#-------------------------------------------------------
getextrema方法
im.getextrema() ⇒ 2-tuple
返回一个2元组,包括该图像中的最小和最大值
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.getextrema())
#-------------------------------------------------------
该方法返回了R/G/B三个通道的最小和最大值的2元组。
getpixel方法
im.getpixel(xy) ⇒ value or tuple
返回给定位置的像素值。如果图像为多通道,则返回一个元组。该方法执行比较慢;如果用户需要使用python处理图像中较大部分数据,可以使用像素访问对象(见load),或者方法getdata()。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.getpixel((0,0)))
print(im.getpixel((4,0)))
r,g,b = im.split()
print(b.getpixel((11,8)))
#-------------------------------------------------------
直方图histogram方法
im.histogram()⇒ list
返回一个图像的直方图。这个直方图是关于像素数量的list,图像中的每个象素值对应一个成员。如果图像有多个通道,所有通道的直方图会连接起来(例如,“RGB”图像的直方图有768个值)。二值图像(模式为“1”)当作灰度图像(模式为“L”)处理。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
imhis = im.histogram()
print(len(imhis))
print(imhis[0])
print(imhis[150])
print(imhis[300])
#-------------------------------------------------------

im.histogram(mask)⇒ list
返回图像中模板图像非零地方的直方图。模板图像与处理图像的尺寸必须相同,并且要么是二值图像(模式为“1”),要么为灰度图像(模式为“L”)。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
r,g,b = im.split()
imhis = im.histogram()
print(r.mode)
print(len(imhis))
print(imhis[0])
print(imhis[150])
print(imhis[300])
#-------------------------------------------------------
load方法
im.load()
为图像分配内存并从文件中加载它(或者从源图像,对于懒操作)。正常情况下,用户不需要调用这个方法,因为在第一次访问图像时,Image类会自动地加载打开的图像。目前的版本,方法load()返回一个用于读取和修改像素的像素访问对象。这个访问对象像一个二维队列,如:
pix = im.load()
print pix[x, y]
pix[x, y] =value
通过这个对象访问比方法getpixel()和putpixel()快很多。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
pix = im.load()
print(pix[0,2])
#-------------------------------------------------------
im.paste(colour,box)
使用同一种颜色填充变量box对应的区域。对于单通道图像,变量colour为单个颜色值;对于多通道,则为一个元组。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
im.paste((256,256,0),(0,0,100,100)) ##(256,256,0)表示黄色
im.show()
#-------------------------------------------------------
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
im.paste("blue",(0,0,100,100)) ##或者“blue”
im.show()
#-------------------------------------------------------
im.paste(image,box, mask)
使用变量mask对应的模板图像来填充所对应的区域。可以使用模式为“1”、“L”或者“RGBA”的图像作为模板图像。模板图像的尺寸必须与变量image对应的图像尺寸一致。如果变量mask对应图像的值为255,则模板图像的值直接被拷贝过来;如果变量mask对应图像的值为0,则保持当前图像的原始值。变量mask对应图像的其他值,将对两张图像的值进行透明融合,如果变量image对应的为“RGBA”图像,即粘贴的图像模式为“RGBA”,则alpha通道被忽略。用户可以使用同样的图像作为原图像和模板图像。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
box=[300,300,400,400]
im_crop =im.crop(box)
r,g,b =im_crop.split()
im.paste(im_crop, (200,200,300,300), r)
im.show()
#-------------------------------------------------------
putdata方法
im.putdata(data)
im.putdata(data, scale, offset)
从sequence对象中拷贝数据到当前图像,从图像的左上角(0,0)位置开始。变量scale和offset用来调整sequence中的值:
pixel = value*scale + offset
如果变量scale忽略,则默认为1.0。如果变量offset忽略,则默认为0.0。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
r, g, b = im.split()
print(r.getpixel((0, 0)),r.getpixel((1, 0)),r.getpixel((2, 0)),r.getpixel((3, 0)),r.putdata([1, 2, 3, 4]),r.getpixel((0, 0)),r.getpixel((1, 0)),r.getpixel((2, 0)),r.getpixel((3, 0)),
#-------------------------------------------------------
resize方法
im.resize(size) ⇒ image
im.resize(size, filter) ⇒ image
返回改变尺寸的图像的拷贝。变量size是所要求的尺寸,是一个二元组:(width, height)。变量filter为NEAREST、BILINEAR、BICUBIC或者ANTIALIAS之一。如果忽略,或者图像模式为“1”或者“P”,该变量设置为NEAREST。在当前的版本中bilinear和bicubic滤波器不能很好地适应大比例的下采样(例如生成缩略图)。用户需要使用ANTIALIAS,除非速度比质量更重要。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
region = im.resize((400, 400)) ##重新设定大小
region.show()
#-------------------------------------------------------
rotate方法
im.rotate(angle) ⇒ image
im.rotate(angle,filter=NEAREST, expand=0) ⇒ image
返回一个按照给定角度顺时钟围绕图像中心旋转后的图像拷贝。变量filter是NEAREST、BILINEAR或者BICUBIC之一。如果省略该变量,或者图像模式为“1”或者“P”,则默认为NEAREST。变量expand,如果为true,表示输出图像足够大,可以装载旋转后的图像。如果为false或者缺省,则输出图像与输入图像尺寸一样大。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
im_45 = im.rotate(45)
im_30 = im.rotate(30, Image.NEAREST,1)
print(im_45.size,im_30.size)
im_45.show()
im_30.show()
#-------------------------------------------------------
seek方法
im.seek(frame)
在给定的文件序列中查找指定的帧。如果查找超越了序列的末尾,则产生一个EOFError异常。当文件序列被打开时,PIL库自动指定到第0帧上。
#-------------------------------------------------------
from PIL import Image
im_gif = Image.open("miaomiao.gif")
print(im_gif.mode)
im_gif.show() ##第0帧
im_gif.seek(1)
im_gif.show()
im_gif.seek(3)
im_gif.show()
#-------------------------------------------------------
tell方法
im.tell() ⇒ integer
返回当前帧所处位置,从0开始计算。
#-------------------------------------------------------
from PIL import Image
im_gif = Image.open("3d.gif")
print(im_gif.tell())
im_gif.seek(8)
print(im_gif.tell())
#-------------------------------------------------------
thumbnail方法
im.thumbnail(size)
im.thumbnail(size, filter)
修改当前图像,使其包含一个自身的缩略图,该缩略图尺寸不大于给定的尺寸。该方法计算一个合适的缩略图尺寸,使其符合当前图像的宽高比,调用方法draft()配置文件读取器,最后改变图像的尺寸。变量filter应该是NEAREST、BILINEAR、BICUBIC或者ANTIALIAS之一。如果省略该变量,则默认为NEAREST。注意:在当前PIL的版本中,滤波器bilinear和bicubic不能很好地适应缩略图产生。用户应该使用ANTIALIAS,图像质量最好。如果处理速度比图像质量更重要,可以选用其他滤波器。这个方法在原图上进行修改。如果用户不想修改原图,可以使用方法copy()拷贝一个图像。这个方法返回空。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
im.thumbnail((100,100))
#-------------------------------------------------------
transform方法
im.transform(size,method, data) ⇒ image
im.transform(size, method, data, filter) ⇒ image
用给定的尺寸生成一张新的图像,与原图有相同的模式,使用给定的转换方式将原图数据拷贝到新的图像中。在当前的PIL版本中,参数method为EXTENT(裁剪出一个矩形区域),AFFINE(仿射变换),QUAD(将正方形转换为矩形),MESH(一个操作映射多个正方形)或者PERSPECTIVE。变量filter定义了对原始图像中像素的滤波器。在当前的版本中,变量filter为NEAREST、BILINEAR、BICUBIC或者ANTIALIAS之一。如果忽略,或者图像模式为“1”或者“P”,该变量设置为NEAREST。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.size)
imtra = im.transform((200, 200), Image.EXTENT, (0, 0, 300, 300))
print(imtra.size)
imtra.show()
#-------------------------------------------------------
im.transform(size,EXTENT, data) ⇒ image
im.transform(size, EXTENT, data, filter) ⇒ image
从图像中裁剪一个区域。变量data为指定输入图像中两个坐标点的4元组(x0,y0,x1,y1)。输出图像为这两个坐标点之间像素的采样结果。例如,如果输入图像的(x0,y0)为输出图像的(0,0)点,(x1,y1)则与变量size一样。这个方法可以用于在当前图像中裁剪,放大,缩小或者镜像一个任意的长方形。它比方法crop()稍慢,但是与resize操作一样快。
im.transform(size, AFFINE, data) ⇒ image
im.transform(size, AFFINE,data, filter) ⇒ image
对当前的图像进行仿射变换,变换结果体现在给定尺寸的新图像中。变量data是一个6元组(a,b,c,d,e,f),包含一个仿射变换矩阵的第一个两行。输出图像中的每一个像素(x,y),新值由输入图像的位置(ax+by+c, dx+ey+f)的像素产生,使用最接近的像素进行近似。这个方法用于原始图像的缩放、转换、旋转和裁剪。
#-------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.size)
imtra = im.transform((200, 200), Image.AFFINE, (1,2,3,2,1,4))
print(imtra.size)
imtra.show()
#-------------------------------------------------------
im.transform(size,QUAD, data) ⇒ image
im.transform(size, QUAD, data, filter) ⇒ image
输入图像的一个四边形(通过四个角定义的区域)映射到给定尺寸的长方形。变量data是一个8元组(x0,y0,x1,y1,x2,y2,x3,y3),它包括源四边形的左上,左下,右下和右上四个角。
#----------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.size)
imtra = im.transform((200, 200), Image.QUAD, (0,0,0,500,600,500,600,0))
print(imtra.size)
imtra.show()
im.transform(size,PERSPECTIVE, data) ⇒ image
im.transform(size, PERSPECTIVE, data, filter) ⇒ image
对当前图像进行透视变换,产生给定尺寸的新图像。变量data是一个8元组(a,b,c,d,e,f,g,h),包括一个透视变换的系数。对于输出图像中的每个像素点,新的值来自于输入图像的位置的(a x + b y + c)/(g x + h y + 1), (d x+ e y + f)/(g x + h y + 1)像素,使用最接近的像素进行近似。这个方法用于原始图像的2D透视。
#-----------------------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
print(im.size)
imtra = im.transform((200, 200), Image.PERSPECTIVE, (1,2,3,2,1,6,1,2))
print(imtra.size)
imtra.show()
transpose方法
im.transpose(method)⇒ image
返回当前图像的翻转或者旋转的拷贝。变量方法的取值为:FLIP_LEFT_RIGHT,FLIP_TOP_BOTTOM,ROTATE_90,ROTATE_180,或ROTATE_270。
#---------------------------------------------------------------------------
from PIL import Image
im = Image.open("3d.jpg")
im.show()
im1=im.rotate(45)
im1.show() #逆时针旋转 45 度角。
im2=im.transpose(Image.FLIP_LEFT_RIGHT) #左右对换
im2.show()
im3=im.transpose(Image.FLIP_TOP_BOTTOM) #上下对换。
im3.show()
im4=im.transpose(Image.ROTATE_90) #旋转 90 度角。
im4.show()
im5=im.transpose(Image.ROTATE_180) #旋转 180 度角。
im5.show()
im6=im.transpose(Image.ROTATE_270) #旋转 270 度角。
im6.show()
#------------------------------------------------------------------------------
转载自 https://blog.csdn.net/leemboy/article/details/83792729