Hive学习笔记
1、Hive概念
Hive是一个构建在Hadoop上数仓框架, 可以将HDFS上格式化文件映射成一张张表,本质就是将SQL转换成MapReduce任务进行运算。它本身不存任何数据,真实数据都是存在HDFS上,元数据一般存在关系型数据库(比如mysql)。支持MapReduce计算引擎、Spark和Tez这两种分布式计算引擎
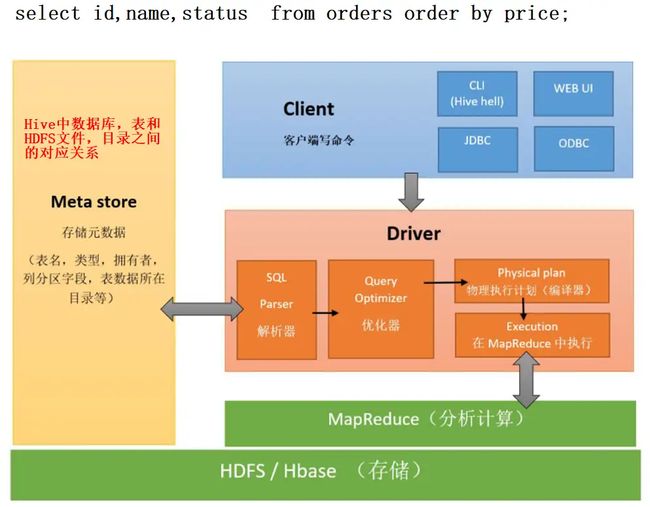
组成:
- 客服端: Client CLI
- 元数据:类似字典的目录,主要用来存数据库、表、表字段、表所属数据库、分区等数据所在目录,默认存在自带的derby数据库,推荐存在mysql
- 驱动器:
- (1)解析器(SQL Parser): 将SQL字符转换成抽象语法树AST,这一步一般使用都是第三方工具库完成,比如antlr,对AST进行语法分析,比如表是否存在,字段是否存在,SQL语句是否有误
- (2)编译器(Physical Plan): 将AST编译生成逻辑执行计划
- (3)优化器(Query Optimizer): 对逻辑执行计划进行优化
- (4)执行器(Execution): 把逻辑执行计划转换成可以运行的物理计划,对于Hive来说,就是MR/Spark
- 存储和执行: Hive使用HDFS存储, 使用MapReduce进行计算
2、Hive安装注意事项
- 需要解决hadoop、hive之间guava版本差异问题,一般是将hadoope的包复制给hive
cp /export/server/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar ./hive/lib/
- 添加mysql jdbc驱动包到hive lib目录下:mysql-connector-java-x.x.x-bin.jar
- 要提前安装好mysql
- 新增hive-site.xml和修改过hive环境变量并添加到hadoop_home中
3、Hive操作
3.1、Hive常见交互方式
- bin/hive : 进入hive终端操作
- hive -e “sql” :不进入终端
- Beeline Client:通过连接Hiveserver2服务器,进行hive操作
3.2、Hive数据库和表操作
3.2.1、数据库操作
Hive数据库默认存放位置是HDFS中/user/hive/warehouse, 可以通过hive-site.xml的属性来修改存放位置
<name> hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
数据库基本操作,基本跟mysql一致
# 创建数据库
hive> create data if not exists test;
# 创建数据库并指定hdfs存储位置 -》 create database 数据库名 location 位置
hive> create database test2 location '/myhive'
# 选择数据库
hive> use test;
# 删除数据库,注意,如果有表存在,则会删除失败
hive> drop database test;
# 强制删除,并将表也一起删除
hive> drop database test cascade;
3.2.2、表操作
1、表字段类型
| 分类 | 类型 | 描述 | 字面量示例 |
|---|---|---|---|
| 原始类型 | BOOLEAN | true/false | TRUE |
| TINYINT | 1字节的有符号整数 -128~127 | 1Y | |
| SMALLINT | 2个字节的有符号整数,-32768~32767 | 1S | |
| INT | 4个字节的带符号整数(-2147483648~2147483647) | 1 | |
| BIGINT | 8字节带符号整数 | 1L | |
| FLOAT | 4字节单精度浮点数1.0 | ||
| DOUBLE | 8字节双精度浮点数 | 1.0 | |
| DEICIMAL | 任意精度的带符号小数 | 1.0 | |
| STRING | 字符串,变长 | “a”,’b’ | |
| VARCHAR | 变长字符串 | “a”,’b’ | |
| CHAR | 固定长度字符串 | “a”,’b’ | |
| BINARY | 字节数组 | ||
| TIMESTAMP | 时间戳,毫秒值精度 | 122327493795 | |
| DATE | 日期 | ‘2016-03-29’ | |
| Time | 时分秒 | ‘12:35:46’ | |
| DateTime | 年月日 时分秒 | ||
| 复杂类型 | ARRAY | 有序的的同类型的集合 | [“beijing”,“shanghai”] |
| MAP | key-value,key必须为原始类型,value可以任意类型 | {key: value} | |
| STRUCT | 字段集合,类型可以不同 | struct(‘1’,1,1.0) |
2、语法
(1)新建表
-- 注意[]是表示该参数可选。并不是要写[] --
create [external] -- 创建一个外部表,该表的数据存储在外部文件系统中,而不是 Hive 的默认位置。
table [if not exists] table name --在表不存在的情况下才创建表。
[(字段名 字段类型 [comment 字段注释], ...)]
[comment 表注释]
[partition by (字段名 字段类型 [comment 字段注释], ...)] --定义表的分区列。根据这些分区列,表数据可以在 HDFS 上分区存储
[clustered by (字段名, ..)] -- 指定表的聚簇列,用于进行数据的物理排序和分桶。
[sorted by (字段名 [ASC|DESC], ...)] --指定表的表排序列,用于在聚簇列的基础上进行进一步的排序。
[INTO num_buckets(桶数量) buckets] --将表的数据分成指定数量的桶,以便更高效地执行某些查询。
[row format row_format(行格式)] -- 指定表数据行格式,如存储方式、分隔符(delimited fields terminated by '\t')
[stored as file_format(文件格式)] -- 指定表数据文件格式,如TEXTFILE、Parquet、ORC等
[location hdfs_path(hdfs路径)] -- 指定表数据在HDFS上存储位置
-- 根据查询结果创建表语法
create table 表名 as select * from 查询表名;
-- 根据已存在表结构建表
create table 表名 like 已存在表名;
-- 查询表信息
desc formatted 表名;
-- 删除表名, 注意:删除内部表之后,所有内容都会被删除,删除外部表则不会,数据仍在hdfs
drop table 表名;
-------------------例子------------------------
-- 例子
CREATE EXTERNAL TABLE IF NOT EXISTS cases (
case_id INT COMMENT '案例ID',
case_name STRING COMMENT '案例名称',
case_description STRING COMMENT '案例描述',
case_date DATE COMMENT '案例日期',
case_status STRING COMMENT '案例状态'
)
COMMENT '案例表'
PARTITIONED BY (case_category STRING COMMENT '案例分类')
CLUSTERED BY (case_id) SORTED BY (case_date ASC) INTO 10 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC
LOCATION '/user/hive/warehouse/cases';
-- 根据查询结果新建表
create table stu as select * from stu2;
-- 复制表结构
create table stu like stu2;
-- 复杂类型建表例子
-- Array类型
create external table hive_array(name string, work_locations array<string>)
row format delimited fields terminated by '\t'
-- map类型 1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
create table 表名(id int, name string, members map<string,string>, age int)
row format delimited fields terminated by ','
collection items terminated by '#'
map keys terminated by ':';
collection items terminated by ','; -- 表示数组类型字段中元素分隔符是','
-- struct类型
create table 表名(ip, string, info struct<name:string, age:int>) row format delimited fields terminated by '#' collection items terminated by ':';
(2)表数据加载方式
- 使用hadoop fs -put 将数据文件上传到表目录文件夹
- 使用load命令来加载
- 通过inser into加载
- 通过查询方式加载数据
- 多插入模式加载
-- 数据加载语法,
-- 1、insert into
insert into table 表名 [partition(分区名=分区值, ..)] values(值, 值,...)
-- 2、查询
insert overwrite table 表名 [partition(分区名=分区值)] select * | (字段,...) from 表名;
-- 3、加载
load data [LOCAL] INPATH '路径' [overwrite] | into table 表名 [partition (分区字段名=分区值,...)];
-- LOAD DATA:用于将数据加载到 Hive 表中。
-- LOCAL(可选):表示数据文件位于本地文件系统而不是 HDFS。如果不指定 LOCAL 关键字,则数据文件被视为位于 HDFS 上。
-- INPATH '/export/data/datas/student.txt':指定数据文件的路径。可以是本地文件系统路径(使用 LOCAL 关键字)或 HDFS 路径(默认情况下)。
-- OVERWRITE(可选):表示如果表中已存在数据,则覆盖现有数据。如果不使用 OVERWRITE,则新数据将追加到现有数据后面。
-- INTO TABLE student:指定数据加载的目标表为名为 student 的表。
-- PARTITION (partcol1=val1, ...)(可选):指定要加载数据的特定分区。如果表有分区列,并且希望将数据加载到特定分区中,可以使用该选项。
-- 例子
load data local inpath '/export/data/a.txt' into table stu6;
load data inpath '/export/data/a.txt' overwrite into table stu6;
-- 4、多插入加载,将一张表拆开成两部分
create table score_first( sid string,cid string) partitioned by (month string) row format delimited fields terminated by '\t' ;
create table score_second(cid string,sscore int) partitioned by (month string) row format delimited fields terminated by '\t';
-- 将score表的前两个字段查询出来插入到score_first
-- 将score表的后两个字段查询出来插入到score_second
insert overwrite table score_first partition(month='202006') select sid,cid
insert overwrite table score_second partition(month = '202006') select cid,sscore;
注意: 桶表数据加载,只能通过insert overwrite来实现。无法通过dfs -put 和 load data
insert overwrite table 桶表名 数据
(3)表数据查询
-- 语法
select [all | distinct] 字段,字段,... -- all返回所有行,distinct返回唯一的行
from 表名 where 查询条件
group by col_list([字段,字段,...]) -- 按照指定列列表进行分组
having 筛选条件 -- 分组结果上,使用聚合函数进行下一步过来,只能用于group by分组统计语句
order by col_list -- 按照列列表排序, 例子:id, name
[cluster by col_list | [distribute by col_list] [sort by col_list]]
-- cluster by col_list 聚类排序,将指定列列表进行物理排序,相似值聚集在一起
-- distribute by col_list 指定分布数据的列列表 sort by col_list对分布数据进行排序, 如果两者col_list相同,等同于cluster by
[limit number] -- 限制查询结果行数
select [字段,...] from 表名;
select 字段名, 字段 as 新字段名 from 表名;
select * from 表名 where 条件
-- 联合查询结果拼接
select_sql1(查询语句) union all select_sql2(查询语句2)
-------------------------join连接--------------------------------
---- 内连接 -- 两个表中都存在与连接条件相匹配的数据才会被保留下来。
select * from 表名1 t, 表名2 c where t.tid = c.tid; #隐式内连接
select * from 表名1 t inner join 表名2 c on t.tid = c.tid; #显式内连接
select * from 表名1 t join 表名2 c on t.tid = c.tid;
--- 左连接 left join 左边所有符合条件的记录都会被返回
select * from 表名1 t left join 表名2 c on t.tid = c.tid
--- 右连接 right join 右边所有符合条件的记录都会被返回
select * from 表名1 t right join 表名2 c on t.tid = c.tid
-- 满外连接 full join ,返回所有表中符合的记录,字段没有符合的值就用null代替
select * from 表名1 t full join 表名2 c on t.tid = c.tid
注意:操作符号带有>或<,则只要出现单一方是NULL值,则结果为NULL, <=>和=类似,只不过它是会返回NULL
(4) 分区操作
-- 多分区联合查询
select * from 表名 where 分区名=分区值 union all select * from 表名 where 分区名=分区值;
-- 查看分区
show partitions 表名;
-- 添加分区
alter table 表名 add partition(分区字段名=分区值);
alter table 表名 add partition(分区字段名=分区值) partition(分区字段名=分区值); --添加多个分区
-- 删除分区
alter table 表名 drop partition(分区字段名=分区值);
--- ------------------动态分区----------------------------
--hive3.x不支持该参数,2.x支持,是否开启动态分区功能,默认false关闭。
set hive.exec.dynamic.partition=true;
-- 动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区。nonstrict模式:表示允许所有的分区字段都可以使用动态分区。
set hive.exec.dynamic.partition.mode=nonstrict;
-- 默认值:100 ,在每个执行MR的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。
set hive.exec.max.dynamic.partitions.pernode=1000;–单个节点上的mapper/reducer允许创建的最大分区
-- 允许动态分区的最大数量, 默认值:1000
set hive.exec.max.dynamic.partitions=1500;
-- 一个mapreduce作业能创建的HDFS文件最大数 , 默认值:100000
set hive.exec.max.created.files=100000;
-- 在动态分区插入产生空结果时是否抛出异常, 默认值:false
set hive.error.on.empty.partition=false;
-------------------动态分区表------------------------
create table test4(
id int,
name string,
score int
)
partitioned by (xxx string, yyy string) -- 一个分区字段为一级,这里个两个分区字段,所以为二级分区
row format delimited fields terminated by ',';
-- 动态分区主要看select最后两个字段,这里是xxx,yyy分区是根据date_val、sex来分区
insert overwrite table test4 partition (xxx,yyy) select id,name,score,date_val ,sex from test3;
(5) 修改表
-- 修改表名
alter table old_table_name rename to new_table_name
-- 添加列
alter table 表名 add columns(字段名 字段类型, 字段名 字段类型);
-- 修改类
alter table 表名 change column 列名 新列名 类型;
(6)数据导出
-- 1、insert 导出
-- 加了local表示导出到本地,加了row format表示格式化导出,没有加local则导出到HDFS上
insert overwrite [local] directory '路径' [row format 行格式] 查询语句
-- 2、hive shell导出
hive -e sql|script > 路径
hive -e "select * from score;" > /export/s.txt
-- export 导出
export table score to hdfs路径;
3.2.3、Hive转化函数
| 语法结构 | 说明 | 例子 |
|---|---|---|
| cast(表达式 as 数据类型) | 类型转化 | select cast(12.35 as int); |
| concat(str1, str2,…) | 字符/字符串拼接 | concat(‘a’,‘b’) |
| concat_ws(分隔符,str,str1,…) | 根据分隔符拼接字符串 | str | str1| str2 |
| collect_set(col)/collect_list(col) | 将某字段的值进行去重汇总,产生array类型字段,可以搭配concat_ws使用 | collect_set(ename) |
| explode函数 | ||
| explode(col) | 将hive一列中复杂的array或者map结构拆分成多行。 | |
| explode(ARRAY) | 数组的每个元素生成一行 | |
| explode(MAP) | map中每个key-value对,生成一行,key为一列,value为一列 | |
| LATERAL VIEW 侧视图函数 | ||
| LATERAL VIEW udtf函数(参数) 表别名 AS 列别名 | 将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。 | |
| reflect函数 | 在sql中调用java中的静态方法 | select reflect(“java.lang.Math”,“max”,col1,col2) from test_udf; |
select deptno,concat_ws("|",collect_set(ename)) as ems from emp group by deptno;
select deptno,name from emp2 lateral view explode(names) tmp_tb as name;
select reflect("java.lang.Math","max",col1,col2) from test_udf;
3.2.4、Hive的函数
注意:Hive 窗口函数通常需要搭配 OVER 子句一起使用。OVER 子句用于指定窗口函数在结果集中的计算范围和排序方式
1、窗口函数
| 函数 | 作用 | 特点 |
|---|---|---|
| ROW_NUMBER | 为结果集中每一行分配一个唯一的连续的整数序号 | 不处理重复值,参考rn3 |
| RANK | 为结果集中的每一行分配一个排名序号。 | 重复值分配相同的序号,具体参考rn1列 |
| DENSE_RANK | 为结果集中的每一行分配一个排名序号。不会跳过排名值 | 重复值分配相同的序号,但是不会跳行,参考rn2列数据 |
# 案例
0: jdbc:hive2://node3:10000> select cookieid, createtime, pv,
RANK() OVER(PARTITION by cookieid order by pv desc) as rn1,
dense_rank() over(partition by cookieid order by pv desc) as rn2,
row_number() over(partition by cookieid order by pv desc) as rn3
from windows1 where cookieid='cookie1';
# 结果集如下:
+-----------+-------------+-----+------+------+------+
| cookieid | createtime | pv | rn1 | rn2 | rn3 |
+-----------+-------------+-----+------+------+------+
| cookie1 | 2018-04-12 | 7 | 1 | 1 | 1 |
| cookie1 | 2018-04-11 | 5 | 2 | 2 | 2 |
| cookie1 | 2018-04-16 | 4 | 3 | 3 | 3 |
| cookie1 | 2018-04-15 | 4 | 3 | 3 | 4 |
| cookie1 | 2018-04-13 | 3 | 5 | 4 | 5 |
| cookie1 | 2018-04-14 | 2 | 6 | 5 | 6 |
| cookie1 | 2018-04-10 | 1 | 7 | 6 | 7 |
+-----------+-------------+-----+------+------+------+
| 函数 | 作用 | 解释 |
|---|---|---|
| sum | 对窗口的每一行column列值求和 | 每一行进行累加 |
| Avg | 对窗口的每一行column列值求平均值 | 每一行进行累加后求平均值 |
| min | 对窗口的每一行column列值求最小值 | 每一行比较最小值 |
| max | 对窗口的每一行column列值求最大值 | 每一行比较最大值 |
| 如果sql没有加order by排序,则默认直接计算分组内所有,而不会一行一行累加计算, 具体参考下面结果集2 |
0: jdbc:hive2://node3:10000> select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime) as pv1,
avg(pv) over(partition by cookieid order by createtime) as pv2,
min(pv) over(partition by cookieid order by createtime) as pv3
from windows2;
+-----------+-------------+-----+------+---------------------+------+
| cookieid | createtime | pv | pv1 | pv2 | pv3 |
+-----------+-------------+-----+------+---------------------+------+
| cookie1 | 2018-04-10 | 1 | 1 | 1.0 | 1 |
| cookie1 | 2018-04-11 | 5 | 6 | 3.0 | 1 |
| cookie1 | 2018-04-12 | 7 | 13 | 4.333333333333333 | 1 |
| cookie1 | 2018-04-13 | 3 | 16 | 4.0 | 1 |
| cookie1 | 2018-04-14 | 2 | 18 | 3.6 | 1 |
| cookie1 | 2018-04-15 | 4 | 22 | 3.6666666666666665 | 1 |
| cookie1 | 2018-04-16 | 4 | 26 | 3.7142857142857144 | 1 |
| cookie2 | 2018-04-10 | 2 | 2 | 2.0 | 2 |
| cookie2 | 2018-04-11 | 3 | 5 | 2.5 | 2 |
| cookie2 | 2018-04-12 | 5 | 10 | 3.3333333333333335 | 2 |
| cookie2 | 2018-04-13 | 6 | 16 | 4.0 | 2 |
| cookie2 | 2018-04-14 | 3 | 19 | 3.8 | 2 |
| cookie2 | 2018-04-15 | 9 | 28 | 4.666666666666667 | 2 |
| cookie2 | 2018-04-16 | 7 | 35 | 5.0 | 2 |
+-----------+-------------+-----+------+---------------------+------+
# 注意,如果没有加order by排序,则默认直接计算分组内所有,而不会一行一行累加计算
0: jdbc:hive2://node3:10000> select cookieid,createtime,pv,
sum(pv) over(partition by cookieid) as pv1,
avg(pv) over(partition by cookieid) as pv2,
min(pv) over(partition by cookieid) as pv3
from windows2;
+-----------+-------------+-----+------+---------------------+------+
| cookieid | createtime | pv | pv1 | pv2 | pv3 |
+-----------+-------------+-----+------+---------------------+------+
| cookie1 | 2018-04-10 | 1 | 26 | 3.7142857142857144 | 1 |
| cookie1 | 2018-04-16 | 4 | 26 | 3.7142857142857144 | 1 |
| cookie1 | 2018-04-15 | 4 | 26 | 3.7142857142857144 | 1 |
| cookie1 | 2018-04-14 | 2 | 26 | 3.7142857142857144 | 1 |
| cookie1 | 2018-04-13 | 3 | 26 | 3.7142857142857144 | 1 |
| cookie1 | 2018-04-12 | 7 | 26 | 3.7142857142857144 | 1 |
| cookie1 | 2018-04-11 | 5 | 26 | 3.7142857142857144 | 1 |
| cookie2 | 2018-04-16 | 7 | 35 | 5.0 | 2 |
| cookie2 | 2018-04-15 | 9 | 35 | 5.0 | 2 |
| cookie2 | 2018-04-14 | 3 | 35 | 5.0 | 2 |
| cookie2 | 2018-04-13 | 6 | 35 | 5.0 | 2 |
| cookie2 | 2018-04-12 | 5 | 35 | 5.0 | 2 |
| cookie2 | 2018-04-11 | 3 | 35 | 5.0 | 2 |
| cookie2 | 2018-04-10 | 2 | 35 | 5.0 | 2 |
+-----------+-------------+-----+------+---------------------+------+
窗口帧
| 语法结构例子 | 解释 | 说明 |
|---|---|---|
| ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING | 窗口帧在当前行的前三行和后一行之间 | 参考下列结果集pv1 |
| ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING | 窗口帧在当前行和窗口的最后一行之间 | 参考下列结果集pv2 |
| ROWS BETWEEN 3 PRECEDING AND CURRENT ROW | 窗口帧在当前行的前三行和当前行之间 | 参考下列结果集pv3 |
| ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW | 窗口帧在窗口的第一行和当前行之间 | 参考下列结果集pv3 |
# preceding: 往前
# following: 往后
# current row:当前行
# unbounded preceding: 到前面起点
# unbounded following: 到后面终点
0: jdbc:hive2://node3:10000> select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING) as pv1,
sum(pv) over(partition by cookieid order by createtime ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) as pv2,
sum(pv) over(partition by cookieid order by createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) as pv3,
sum(pv) over(partition by cookieid order by createtime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as pv4
from windows2;
+-----------+-------------+-----+------+------+------+------+
| cookieid | createtime | pv | pv1 | pv2 | pv3 | pv4 |
+-----------+-------------+-----+------+------+------+------+
| cookie1 | 2018-04-10 | 1 | 6 | 26 | 1 | 1 |
| cookie1 | 2018-04-11 | 5 | 13 | 25 | 6 | 6 |
| cookie1 | 2018-04-12 | 7 | 16 | 20 | 13 | 13 |
| cookie1 | 2018-04-13 | 3 | 18 | 13 | 16 | 16 |
| cookie1 | 2018-04-14 | 2 | 21 | 10 | 17 | 18 |
| cookie1 | 2018-04-15 | 4 | 20 | 8 | 16 | 22 |
| cookie1 | 2018-04-16 | 4 | 13 | 4 | 13 | 26 |
| cookie2 | 2018-04-10 | 2 | 5 | 35 | 2 | 2 |
| cookie2 | 2018-04-11 | 3 | 10 | 33 | 5 | 5 |
| cookie2 | 2018-04-12 | 5 | 16 | 30 | 10 | 10 |
| cookie2 | 2018-04-13 | 6 | 19 | 25 | 16 | 16 |
| cookie2 | 2018-04-14 | 3 | 26 | 19 | 17 | 19 |
| cookie2 | 2018-04-15 | 9 | 30 | 16 | 23 | 28 |
| cookie2 | 2018-04-16 | 7 | 25 | 7 | 25 | 35 |
+-----------+-------------+-----+------+------+------+------+
错误类型
1、guava.jar版本不同导致

方法:
查看/export/server/hadoop-3.1.4/share/hadoop/common/lib和/export/server/hive-3.1.2/lib下guava包

![]()
解决方案:用hive高版本的包替换hadoop低版本的包
2 、SLF4J 问题
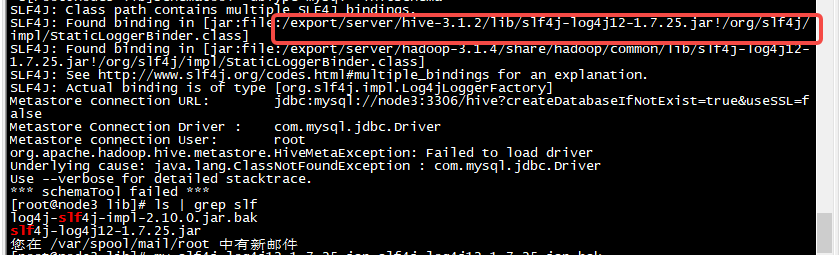
解决方法:将这个包移除