django celery 结合使用
简介
本文主要介绍django和celery结合使用的案例。
celery 是一个异步任务的调度工具,可以完成一些异步任务和定时任务。
本文使用djcelery来完成django和celery的结合使用。
该案例在github中django_celery_demo
流程
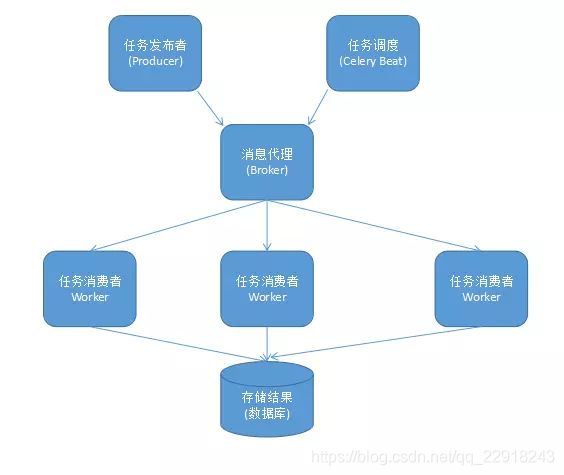
任务发布者(Producer)将任务丢到消息队列(Broker)中,任务消费者(worker)从消息代理中获取任务执行,然后将保存存储结果(backend)。
celery-beat
celery 有个定时功能,通过定时去将task丢到broker中,然后worker去执行任务。但是有个确定是,该定时任务必须硬编写到代码中,不可在程序运行中动态增加任务。使用djcelery可以将定时任务写入到数据库中,然后通过操作数据库操作定时任务。
案例1
访问接口,异步调用程序中task
配置celery
安装djcelery
pip install django_celery
在settings中设置celery配置
代码: django_celery_demo/settings.py
import djcelery
djcelery.setup_loader() # 加载djcelery
# 允许的格式
CELERY_ACCEPT_CONTENT = ['pickle', 'json', 'yaml']
BROKER_URL = 'redis://localhost:6379/1' # redis作为中间件
BROKER_TRANSPORT = 'redis'
CELERYBEAT_SCHEDULER = 'djcelery.schedulers.DatabaseScheduler' # 定时任务使用数据库来操作
CELERY_RESULT_BACKEND = 'djcelery.backends.database:DatabaseBackend' # 结果存储到数据库中
# worker 并发数
CELERY_CONCURRENCY = 2
# 指定导入task任务
CELERY_IMPORTS = {
'tasks.tasks'
}
celery app 配置
代码: django_celery_demo/celery.py
import os
import django
from celery import Celery, shared_task
from celery.schedules import crontab
from celery.signals import task_success
from django.conf import settings
from django.utils import timezone
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'django_celery_demo.settings')
django.setup()
app = Celery('django_celery_demo')
app.config_from_object('django.conf:settings') # celery app 加载 settings中的配置
app.now = timezone.now # 设置时间时区和django一样
# 加载每个django app下的tasks.py中的task任务
app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)
# 这个一个task
@app.task(bind=True)
def debug_task(self):
print('Request: {0!r}'.format(self.request))
# 异步执行这个task
debug_task.delay()
创建djcelery中的表
会自动创建djcelery中的表。里面有保存定时记录、结果记录等等表。
python manage.py migrate
在view中异步执行task
在app中创建addtask
代码: demo/tasks.py
from celery import shared_task
@shared_task(name="add")
def add(a, b):
return int(a) + int(b)
创建view去异步执行该task
代码: demo/views.py
from django.http import HttpResponse
from demo.tasks import add as add_task
def add(request):
a = request.GET["a"]
b = request.GET["b"]
add_task.delay(a, b)
return HttpResponse("success")
url中配置view
from demo.views import add
urlpatterns = [
path('add', add),
]
运行celery worker
celery -A django_celery_demo worker -l info
运行项目
python manage.py runserver 0:8888
访问接口
http://127.0.0.1:8888/add?a=1&b=2
结果: 返回success,在worker中可以看到add任务被调用,并且结果是3
![]()
案例2
定时调用异步任务
定时任务简介
有两种定时任务方式,这里使用的是常见的crontab,与linux一毛一样,方便很多。
配置
配置和案例1中一样。
定时任务
硬编码中创建定时任务
每分钟调用一次add task
代码: django_celery_demo/celery.py
# 这个是硬编码的定时任务
app.conf.beat_schedule = {
'aa': {
'task': 'add',
'schedule': crontab(minute="*/1"),
'args': (2, 4)
},
}
开启celery beat
celery beat -A django_celery_demo -l info
这个服务会将数据库中的定时任务丢到broker 中
管理worker 进程
使用supervisor来管理worker进程。
基本操作
安装
pip install supervisor
生成默认配置文件
echo_supervisord_conf > /etc/supervisor/supervisord.conf
命令
supervisorctl
| 命令 | 描述 |
|---|---|
| status | |
| reread | 读取配置文件 |
| update | 加载最新的进程 |
| stop 进程名 | |
| start 进程名 | |
| reload | 重新加载配置 |
配合celery使用
在supervisord.conf中添加下面的配置。
[include]
; files = relative/directory/*.ini
files = /home/jim/conf/supervisor/supervisord.conf.d/*.conf
创建配置文件/home/jim/conf/supervisor/supervisord.conf.d/celeryd_worker.conf,添加下面配置
[program:celeryworker]
command=celery -A datahub_poster worker -l info
directory=/home/hadoop/jim/projs/datahub_poster
stdout_logfile=/yun/jim/log/supervisor/celeryworker.log
;stderr_logfile=/yun/jim/log/supervisor/celeryworker_err.log
redirect_stderr=true
autorestart=true
autostart=true
numprocs=1
startsecs=10
stopwaitsecs = 600
priority=15
[program:celerybeat]
command=celery -A datahub_poster beat -l info
directory=/home/hadoop/jim/projs/datahub_poster
stdout_logfile=/yun/jim/log/supervisor/celerybeat.log
;stderr_logfile=/yun/jim/log/supervisor/celerybeat_err.log
redirect_stderr=true
autorestart=true
autostart=true
numprocs=1
startsecs=10
stopwaitsecs = 600
priority=15
[program:celery_flower]
command=celery -A datahub_poster flower --port=5555
directory=/home/hadoop/jim/projs/datahub_poster
stdout_logfile=/yun/jim/log/supervisor/celery_flower.log
;stderr_logfile=/yun/jim/log/supervisor/celery_flower_err.log
redirect_stderr=true
autorestart=true
autostart=true
numprocs=1
startsecs=10
stopwaitsecs = 600
priority=15
[inet_http_server]
port=127.0.0.1:9001
使用配置文件启动supervisor
supervisord -c /etc/supervisor/supervisord.conf
问题
- 在supervisorctl status时,出现
http://localhost:9001 refused connection错误。
解决办法:
在配置文件supervisord.conf中添加
[inet_http_server]
port=127.0.0.1:9001
然后再update或reload以下。
使用flower监控celery
可以通过flower监控celery中的worker、task等等。
安装flower
pip install flower
运行
celery flower --broker=redis://localhost:6379/0
欢迎关注,互相学习,共同进步~
我的个人博客
我的微信公众号:编程黑洞