Nature Scientific Report- 阅读DNA‑influenced automated behavior detection on twitter through ..
目录
摘要
绪论
相关工作
提出的工作
实验设计和讨论
数据收集和注释
结论
摘要
Twitter 是一个著名的微博网站,允许用户使用推文进行互动,到 2021 年第二季度,它的日活跃用户几乎达到 2.06 亿。Twitter 机器人的比例随着它们的受欢迎程度而上升。机器人检测对于打击错误信息和保护在线披露的可信度至关重要。
当前的机器人检测方法依赖于 Twitosphere 的拓扑结构,忽略了配置文件之间的异质性。
此外,大多数技术都包含监督学习,这在很大程度上取决于大规模训练集。
因此,为了克服这些问题,我们提出了一种新颖的基于熵的框架来检测仅利用用户行为的相关机器人。
具体而言,收集用户的实时数据并将他们的在线行为建模为 DNA 序列。然后我们确定 DNA 序列的概率分布并计算相对熵以评估分布之间的距离。
熵值小于固定阈值的帐户代表机器人。在实时 Twitter 数据中进行的大量实验证明,所提出的检测技术优于最先进的方法,精度 = 0.9471,召回率 = 0.9682,F1 分数 = 0.9511,准确度 = 0.9457。
绪论
Twitter 是一个流行的微博平台,允许用户表达他们的意见并建立社交联系。由于开放平台和匿名性等特点,它已成为机器人 1 成长的理想媒介。
Twitter 机器人是运行自动化任务的软件应用程序。尽管人们普遍认为所有机器人都是恶意的,但 Twitter 的指导方针允许使用自动机器人。但是,它禁止将机器人用于非法目的 2 。
@big ben clock 等一些机器人是良性的,它模仿了原始的 Big Ben clock 3 。
还有其他恶意机器人参与各种非法活动,例如发送垃圾邮件、产生虚假人气、发布错误信息、在线骚扰、恐怖主义和限制言论自由权 4 。
机器人程序最近的一个问题是有关 COVID-19 大流行的错误信息的传播。根据对已知机器人程序数据集的分析,在 COVID-19 上传播错误信息的个人资料中,近 66% 是机器人程序 5 。
他们传播 QAnon 等阴谋论,并传播来自党派新闻网站 6 的 URL。这种错误信息在现实生活中的一个后果包括羟氯喹药物不足,因为人们认为它会增强对 COVID-19 的保护,因此需求量很大 7 。
此外,误导性信息会对人们接种 COVID-19 8 疫苗的意愿产生负面影响。事实也证明,推特机器人在不同场景中发挥了重要作用,例如公开选举 9 和股票微博 10 。
因此,从 Twitter 环境中删除恶意机器人变得至关重要。大多数机器人检测方法分析多个特征,并结合使用已知机器人数据集训练的机器学习分类器来确定配置文件是否是自动化的 11 。然而,在使用机器学习分类器 12 时,特征选择是一项具有挑战性的任务。
针对不同的目标对类似特征的用户行为进行建模和分析。当代的一系列研究已经通过使用生物信息学方法分析用户行为来检测机器人13-17。在这项研究中,我们提出了一种新的方法来检测相关的机器人只利用用户的行为。DNA 碱基(A、 C、 T 或 G)用于定义执行的在线用户活动。因此,DNA 串对应于用户时间线中的活动序列。DNA 序列用概率分布表示,它们的相似度用相对熵量化。在这里,概率分布中的相似程度可以作为自动化的一个指标。熵的范围在0和1之间,其中0表示分布具有相似的信息18。因此,随着熵的降低,相应的概率轮廓是一个机器人增加。以下是提议工作的主要贡献。
提出的方法分析用户的行为,通过考虑个人资料的时间轴和特点,他们作为 DNA 序列。
我们计算与 DNA 序列相对应的概率分布的相对熵,并估计存在的相似程度。通过评估熵值,机器人被从人类中分类出来。
拟议方法的性能在实时推特数据集中计算,并与最新技术进行比较。
此篇文章的结构如下。第 2 节,简要讨论文献调查。第 3 节介绍了使用 DNA 建模在 Twitter 上提出的基于熵的自动化检测。第 4 节描述了实验设计和讨论,并重点概述了决策阈值的选择、所提出模型的实证结果以及与最先进方法的比较。它还解释了用于性能评估的真实 Twitter 数据集集合和基线数据集。第 5 节总结了本文。
相关工作
文献介绍了与我们的提案相关的已取得有趣成果的研究。相关工作在两大类下进行讨论。第一个涉及基于熵的方法。第二篇回顾了基于 DNA 建模的机器人检测方法。
基于熵的方法。多项研究工作都关注基于熵的特征来检测 Twitter 上的自动化行为。受他们的启发,提出了一种使用近似熵和样本熵的机器人检测方法 19 。用户定期发布的推文数量是考虑的主要时间特征。数据中存在的规律性数量使用熵估计进行量化,该熵估计用作机器人的指标。实时数据集上的实验表明,近似熵和样本熵提供了 85% 准确率和 80% 准确率的显着结果,仅考虑单个特征。熵在机器人检测中的重要性通过熵与配置文件类别(机器人或人类)之间的强负相关使用点双列相关得到证明。
基于 DNA 建模的方法。受遗传学的启发,先前的研究 13-17 使用从用户帐户发布的推文中生成的 DNA 序列对 Twitter 用户的行为活动进行了建模。检测配置文件中自动化的指标是序列相似性。使用最长公共子串 (LCS) 评估 DNA 序列之间的相似性。分析从推文的类型和内容开发的 LCS (最长公共子串)曲线意味着基于类型的建模提供了更高的效率 13,14。 DNA 建模与遗传算法相结合,以创建新机器人的进化 DNA 序列 15。变异和交叉是用于开发现代机器人的遗传算法。先进的机器人检测系统测试的进化机器人行为证明它们成功地逃避了检测。此外,该研究还检查了人类行为的分布,这些分布被证明是高度异质的 16、17。
推理。Chu 等[20]和 Gilary 等[19]以前的研究证明,熵准确地反映了机器人和人类行为之间的差异。虽然熵估计在机器人检测中具有重要意义,但目前对它的研究还不多。现有的基于熵的监督方法在文献中有许多缺点。这些技术采用了广泛的特征,其中从 Twitter 中提取某些特征既费时又昂贵 12。训练受监督的机器学习算法需要一个标记数据集,其中包括各种机器人 26 基于熵的属性和行为。很难检测具有特定类型机器人(如虚假追随者或社交机器人)的有限训练集的通用机器人。此外,机器人会进化 15,使用过时数据学习的机器学习分类器无法检测进化的机器人 27。此外,这些数据不反映机器人的当前特征,这是更新的 Twitter 政策 2020 28 的结果。使用半监督方法可以改善监督机器人检测策略的缺点。
基于 DNA 建模的机器人检测是一个相对较新的研究领域。它具有足够的通用性,可以在不依赖特定属性的情况下识别机器人行为。因此,有更多的改进机会。 LCS 目前被用于识别机器人,它只检测一组遵循相同模式的机器人。因此,遵循独特模式的机器人不会被发现。
所提出的技术解决了文献的缺点。基于 DNA 分析范式,我们提取了表征用户时间线的 DNA 序列。然后,我们从使用 DNA 序列中的相对熵计算的相似性指数中检测相关机器人。通过这种技术,仅使用一个特征就可以准确地检测出遵循不同模式的相关机器人。
这项研究的主要优势只有一个单一的功能: 帐户时间表被使用。此外,该模型不使用任何传统的监督分类器。因此,没有对训练阶段的要求。通过半监督方法实现,减少了对手工标记数据集的需求。从而减少了实验中使用的注释数据。利用最少的资源,提出的方法检测通用的相关机器人,而不是任何特定类型的机器人在监督技术。
提出的工作
在我们以前的工作中,我们计算了用户帐户的时间特征的熵,以通过自动相关检测机器人19。在本文中,我们扩展了以前的工作,以通过计算用户行为的相对熵来检测相关的机器人。图1解释了所提出的机器人检测方法的框架。设计的方法包括集合实时数据集,然后是三个主要阶段。在初始阶段,我们将用户行为作为DNA序列建模,如SECT3.1中所述。 第3.2节给出了构建相应概率分布的详细概述。最后,在3.3,我们使用相对熵分析相似性,该相似性充当检测机器人的参数。

将用户行为建模为DNA序列。用户行为通过为用户执行的每个活动分配DNA来建模为DNA序列。因此,DNA序列表示用户的时间表。 DNA碱基的数量和解释可以根据要求修改。我们将用户配置文件(u)定义为DNA碱基的字符串,
![]()
其中,U 中的 DNA 碱基 (bi) 是来自有限集 F 的元素

每个用户活动都通过分配一个 Fi 元素进行编码。我们通过按时间顺序扫描他们的时间线并分配适当的 DNA 碱基来获取用户的 DNA 序列。在所提出的方法中,我们根据共享的推文的类型和内容分配 DNA 碱基。由于这些特征在检测机器人13,14,29,30中被证明是有效的,因此用户发布的每条推文都被分配了一个独特的DNA碱基,如表1所示(即a -纯推文,T-纯提及,G-纯转发,C-带媒体/ url的推文)。对于每个配置文件,我们可以提取长度为3200条tweet的DNA序列,因为Twitter API限制了3200条tweet。

DNA序列的概率分布。最初,我们分配四个向量值对应于 0 和 1 之间的四个碱基以获得概率分布。这些值是根据特定 DNA 碱基在机器人检测中的重要性分配的。在这个范例中,我们指定了-→ T = 0.2,-→ A = 0.4,-→ G = 0.6,和-→ C = 0.8。较大的向量值被赋予代表转推和带有媒体/URL 的推文的 DNA 碱基,因为大多数机器人传播转推/媒体/URL。然后将 DNA 序列表示为离散概率分布 31。
我们定义长度为 n 的 DNA 序列的概率分布为 ( p1 , p2 , p3 , . . . , pn ),

其中(αi,βi)表示第i个碱基在DNA序列中的位置,-→βi表示对应的第i个碱基的向量值。βn是将表示DNA序列中碱基的向量相加得到的。例如,DNA 序列 (ATGC) 的概率分布是,
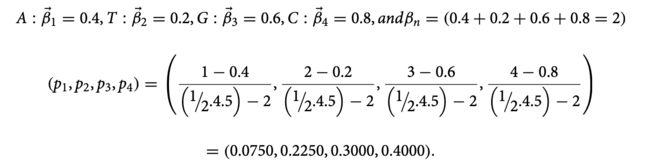
离散概率分布的证明:

由式(1)和(2),我们可以证明(p1,p2,p3,...,pn)是一个离散概率分布。
通过相对熵来衡量相似性。熵是衡量数据集 32 中随机程度的指标。在 DNA 中,熵量化了序列 33 中的可重复性。我们计算对应于各个用户配置文件的所有 DNA 序列的概率分布。最后,我们估计所有分布对之间的相对熵 34, 35 以确定相似性指数。在这项研究中,我们使用相似性度量作为识别机器人的指标。所有熵度量都具有相同的属性,即完全随机数据获得最高的熵分数。低熵分数表示包含重复模式的序列。因此,如果一对分布的熵较低,则相应配置文件是相关机器人的概率较高。
问题定义: 对于一对 DNA 序列,给定离散概率分布 μ1 = (p1,p2,. . ,pn)和 μ2 = (q1,q2,. . ,qn) ,μ1相对于 μ2的相对熵 Ren (μ1,μ2)定义如下,
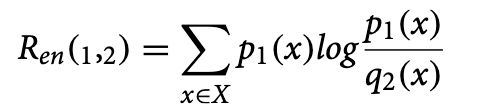
µ2 相对于 µ1 的相对熵 Ren(µ2 , µ1) 定义如下,

相似度指数定义如下,
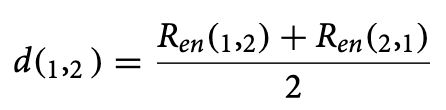
因此,我们可以计算一对 DNA 序列之间的相似性指数。基于 d(µ1 , µ2) 分数,对应于概率分布的一对用户帐户被分类为机器人或人类。算法 1 讨论了计算相对熵和相似性指数的算法。

实验设计和讨论
本部分讨论了提出的工作的实验设置。如图1所示,提出的机器人检测方法由四部分组成: 数据收集和注释、将用户行为建模为 DNA 序列、构建每个 DNA 序列的概率分布以及计算相对熵。
数据收集和注释
由于多种原因,拟议的研究利用了一个新的真实世界 Twitter 数据集。主要原因是研究以印度机器人为中心。因此,我们从印度最受欢迎的主题标签中收集了机器人。其次,学术界承认,用于机器人检测的人工标记 Twitter 数据集有限 36。之前的研究使用了具有某些机器人类型的机器人数据集,例如社交机器人 27 或假粉丝 12。为了进行有效的机器人检测,训练数据集应该反映范围广泛的机器人的行为,而不是单一类型。此外,使用 Twitter API 收集的数据集必须符合最新的开发者政策28。最后,Twitter每月停用数百万个机器人。结果,一些旧数据集的账户被禁止、删除或保密37。
图2解释了通过 Twitter API 收集数据的流程图。由于大多数机器人的目标是热门故事,话题标签的选择是至关重要的。在这项研究中,我们考虑的标签是 # 冠状病毒疫苗,# FarmBills2020,# 印度股票市场,# jallikattu,# 裙带关系主义,# NRC,# 权利,# sterlite,# 泰米尔,# 泰米尔纳德邦,# 反对莫迪,# 农民抗议,和 # 纳伦德拉莫迪。

这些标签在不同时期都很活跃,以确保所进行的分析没有偏见。Twitter 爬虫使用标准搜索 API 收集在特定 # 标签上发推的配置文件的屏幕名称。然后,user_ timeREST API 通过检查索引的关键字提取单个配置文件的数据集,并提供符合搜索条件的 twitter 帖子。在2020年8月至2021年7月期间,使用 Twitter 标准 API 语言参数: lang = “ es”以英语提取数据集(≈7,353,600条 tweet)。使用 status _ count 和 create _ at API 属性,每天共享至少2条 tweet 的配置文件将被过滤,因为研究表明,真正的配置文件每天共享2到500条 tweet。
我们建立通过众包 39 收集的数据的基本事实,众包将帐户标记为机器人或人类。众包由一组计算机科学研究生作为测试人员进行,他们手动注释每个配置文件。每个测试人员检查 80 个个人资料,并根据时间线、帐户功能、相册和个人资料照片将它们分为机器人或人类。该组分为四个小组,所有四个小组都分析每个配置文件以提高分类准确性。将四支队伍的成绩进行汇总,汇总方式为结果分类。 Twitter 也有不构成威胁的机器人 40 ,使用 Twitter API Is-Verified 功能排除此类配置文件。最终数据集包含 1094 个机器人和 1204 个人类的约 2300 个配置文件,每个配置文件具有以下字段:Tweet-Id、Timestamp 和 Tweet。
基线数据集。基线数据集包含来自完整数据集的 800 个配置文件作为训练数据和 1500 个配置文件作为测试数据。我们考虑两个有限的数据集:Group_1 和 Group_2,每个大小为 400,平衡机器人和人类作为训练数据集。它们用于固定决策阈值。我们在测试数据集中验证了所提出模型的经验结果。使用 Bootstrap 技术,我们从 1500 个配置文件中提取了 5 个测试数据集:Test_1、Test_2、Test_3、Test_4 和 Test_5,每个大小为 600,其中 36.8% 是新配置文件 41 。基线数据集包括 800 个与机器人和人类平衡的账户,用于分析 DNA 模式,以及 1200 个账户作为来自收集的原始数据的测试数据。我们在测试数据集中评估所提出模型的实证结果。我们使用 Bootstrap 技术从 1200 个配置文件 Test_1、Test_2、Test_3、Test_4 和 Test_5 中提取 5 个测试数据集。
提取 DNA 序列和概率分布。在这个阶段,对应于每个 Twitter 用户的 DNA 序列被提取,一个字符串编码用户的时间线。用户执行的每项活动都使用独特的 DNA 碱基进行编码(即)A-plain 推文、T-plain 提及、G-plain 转推、带有媒体(照片和 URL)的 C-tweet。最后,我们定义了每个 DNA 序列的概率分布,如第 3.2节中所讨论的。
修复相对熵的决策阈值。 Twitter 机器人检测是一种二元分类,其中决策阈值将配置文件二分为类机器人或类人类。此处,决策阈值是一个介于 0 和 1 之间的 d(µ1 , µ2) 值。


这些分析是在三个维度中进行的: (机器人,机器人) ,(机器人,人类)和(人类,人类)。表2解释了在 Group _ 1和 Group _ 2上进行的确定决策阈值的实验。在每个数据集中,我们使用不同数量的帐户执行四次迭代,如表2所示。在每次迭代中,我们计算机器人集(bot,bot)、人类集(human,human)和机器人和人类集(bot,human)中的所有组合对的 d (μ1,μ2)。然后我们考虑他们的手段作为最终结果。(bot,bot)的平均d(µ1,µ2)得分明显小于(bot,人类)和(人类,人类)。此外,由于它们的异质模式,(bot,人类)和(人类,人类)的平均d(µ1,µ2)得分相对较高。这种变化证明,通过相对熵计算的相似性指数与Twitter帐户类别具有显着关系,并且熵与机器人负相关。

分类的强候选分裂点是检测所有相关机器人(即)(bots,bots)的阈值。最佳决策阈值是根据 (bots, bots) 的所有迭代中 d(µ1 , µ2 ) 的样本最大值确定的。因此,可以检测到遵循多种模式的相关机器人。观察表 2 中的读数,获得的最佳决策阈值为 0.12。
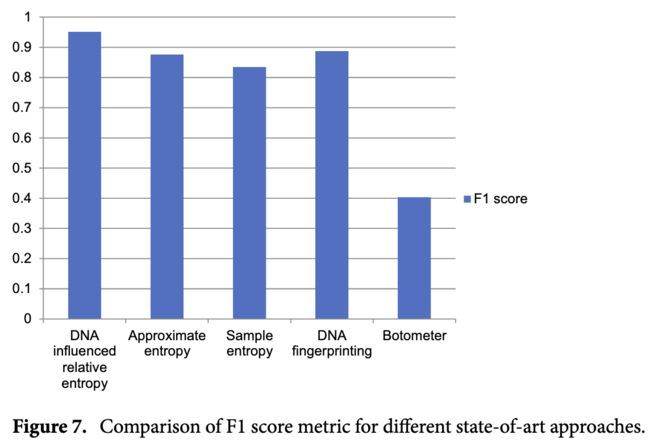
绩效评估。基于以下指标分析所提出方法的性能:精度、召回率、未命中率、准确性(ACC)、F1 分数(召回率和精度的调和平均值)和马修斯相关系数(MCC)。表 3 说明了所提出技术在以下测试数据集上的性能:Test_1、Test_2、Test_3、Test_4 和 Test_5。我们的技术与基于熵的时间模式方法 19、基于 DNA 建模的研究 13,14,16 和机器人检测工具 Botometer 42,43 进行了比较。

将提出的方法与我们以前的工作进行了比较,该方法强调了时间模式中近似熵和样品熵的计算。该技术涉及自相关分析,并仅考虑一个功能。在这里,通过分析时间模式中存在的规律性来检测到单个机器人。此外,使用点生物相关性证明了机器人帐户和熵之间的关系。
我们检查了test_dataset中近似熵和样品熵的性能。结果表明,近似熵检测到机器人比样品熵更好,而F1测量值= 0.8759,精度= 0.8561。而样品熵产生F1测量= 0.8349,准确性= 0.8033。我们还将我们的研究与基于DNA建模的方法进行了比较。社会指纹13,14,16是基于DNA建模的研究中使用的主要概念。在他们的基础研究中,用户活动作为DNA序列,考虑三个特征:推文,转发和答复。最后,通过使用最长的共同基因(LCS)算法分析序列中的相似性来识别Twitter机器人。
最后,我们将我们的模型与 Botometer 42,43进行了比较,后者被用于各种研究44-46,作为他们分析的一个关键特征。因此,可以合理地得出结论,认为 Botometer 是一种事实上的机器人检测范式。它通过评估1000个特征来计算0到1之间的概率值。在 Group _ 1和 Group _ 2数据集上计算了不同阈值的分类精度,认为准确度最高的阈值是理想的。根据实证研究结果,我们选择阈值为0.43,这与Botometer团队的结果一致。
所提出的使用相对熵和其他最先进方法的受 DNA 影响的机器人检测的性能比较如图 3、4、5、6、7 和 8所示。 用于各种指标。所提出的模态通过实现平均 F1score = 0.9511 和平均精度 = 0.9457 优于其他技术。它仅使用一个特征(即)配置文件的时间轴,就超越了 Botometer 工具 18,19。 Social Fingerprinting13,14,16 使用 LCS,结果只检测遵循相同模式的机器人。通过所提出的方法实现的召回率 = 0.9681 证实了我们的说法,即即使是遵循独特模式的相关机器人也能被检测到。此外,我们的技术不会分析广泛的特征或训练阶段以提供更高的性能。





或者,我们仅使用配置文件的时间线。基于这些有趣的结果,可以预见基于熵的方法在高级机器人检测中的应用潜力。将不同的熵模型与用户行为的压缩统计数据关联起来,以DNA序列为模型,是检测相关机器人的一个很有前途的研究方向。
结论
在这项研究中,仅使用一个功能设计了一种新颖的机器人检测框架:用户的时间线。这些实验是在通过更新的 Twitter API 收集的实时 Twitter 数据集和 2020 Twitter 开发者政策中进行的。该数据集包括 1094 个机器人和 1204 个人类,每个机器人都有以下字段:Tweet-Id、Timestamp 和 Tweet。该研究仅关注用户时间线上发布的推文。对于每个 Twitter 个人资料,他们的 DNA 序列是用四个碱基 A(普通推文)、T(普通提及)、G(普通转发)和 C(带有媒体/URL 的推文)提取的,并将它们表示为概率分布。
最后,通过对所有概率分布的相对熵Ren(μ1, μ2)和Ren(μ2, μ1)的均值计算相似度指数d(μ1, μ2),用于检测相关机器人。我们提出的研究的底线是确定概率分布之间的相似度,作为机器人检测的指标。根据从相对熵得出的相似性分数,正在检查的 Twitter 个人资料被归类为机器人或合法个人资料。简而言之,相关机器人具有更高的相似性,从而导致低熵。由此产生的性能指标分数是 test_datasets 结果的平均值。我们通过相对熵比较了 Twitter 上受 DNA 影响的自动行为检测与机器人检测工具 Botometer42,43 和 DNA 指纹识别13,14 的性能。我们的技术比 F1 测量值 = 0.9511 和准确度 = 0.9457 的最先进方法提供了显着的结果。
这项研究工作的优点是多方面的。提议的 Twitter 上受 DNA 影响的自动行为检测通过相对熵检测 Twitter 机器人具有更好的准确性、F1 分数和召回率。它通过识别通用机器人而不是任何特定类型来增强性能。提议的模式仅利用一个主要功能:用户时间线。它减少了使用的注释数据量。由于模态不使用任何典型的机器学习算法,因此它没有任何训练阶段。因此,所提出的技术可以用最少的资源检测相关的机器人。对于未来的研究,我们计划使用推文活动的时间维度来扩展基于 DNA 的建模。基于时间线的特征和时间线特征可以一起考虑,以检测在特定时间段活跃的相关机器人。时间特征和时间线特征功能互补,设计出更健壮的机器人检测范例。将具有不同采样周期的推文速率和具有熵估计的时间线活动结合使用的新模型是一个有前途的研究方向。