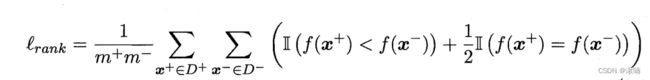【机器学习】吃瓜教程 | 西瓜书 + 南瓜书 (1)
文章目录
- 一、绪论
-
- 1、什么是机器学习?
- 2、基本术语
- 3、假设空间
- 4、归纳偏好
- 5、发展历程
- 二、模型评估与选择
-
- A、一种训练集一种算法
-
- 2.1 经验误差 与 过拟合
- 2.2 评估方法
-
- a) 留出法
- b) 交叉验证法
- c) 自助法
- d) 调参与最终模型
- 2.3 性能度量
-
- a) 错误率与精度
- b) 查准率、查全率与F1
- 2.4比较检验
-
- a) 假设检验
- b) 交叉验证 t 检验
- c) McNemar 检验
- d) Friedman 检验与 nenyl 后续检验
- B、一种训练集多种算法
-
-
- a) ROC与AUC
-
- C、多种训练集一种算法
-
-
- a) 代价敏感错误率与代价曲线
- b) 偏差 和 方差
-
一、绪论
1、什么是机器学习?
机器学习 是研究 如何通过计算手段,利用经验(数据)产生模型算法(学习算法),并用模型算法对新的情况(数据)作出相应的判断。
初学者容易混淆的概念:
人工智能:让机器变得像人一样拥有智能的学科。
机器学习:让计算机像人一样能从数据中学习出规律的一类算法
深度学习:神经网络类的机器学习算法。
因此,范围来说 人工智能 > 机器学习 > 深度学习
2、基本术语
- 数据集:数据的集合,其中每条记录是关于一个事件或对象(这里是一个西瓜)的描述,称为一个"示例" (instance)或"样本" (sample).
- 训练集:用于学习的数据
- 属性(特征):数据的单个特征属性,如瓜的色泽,反映事件或对象在某方面的表现或性质的事项。
- 属性值:属性的具体取值,如瓜的色泽是"青绿" ,还是"乌黑"。
- 属性空间(样本空间、输入空间) :对于每一条属性,都在坐标轴上用一个方向表示,并由次张成的空间。
- 特征向量:一个示例在属性空间内的坐标向量。
- 维数:一个样本的特征数
- “学习”或“训练”:从数据中学的模型的过程,这个过程是通过执行某个学习算法来完成的。
通过“学习”或“训练”,找到数据之间的某种潜在关系,称为“假设”。“假设”可以不断逼近“真相”。
-
标记:算法学习过程中对训练数据作出的判断.
-
样例:拥有建立模型时需获得训练样本的“结果”信息(”标记“)的事例
-
输出空间 的范围,分为
二分类任务、多分类任务和回归任务。其中二分类和多分类任务的预测值为离散值,而回归任务的预测值为连续值。 -
在算法通过“学习”训练集后得到了模型,为了检验模型的有效性(算法的学习效果),在 ”测试样本”(已知真实结果的数据集)上进行测试,
-
将被学习的事物分为许多“簇”(自动形成),簇之间可能存在潜在的一些关系,称为“聚类”。
-
根据训练数据是否拥有标记信息分为:监督学习(以分类和回归为代表),半监督学习和无监督学习(以聚类为代表)。
分类:预测值是整数,分为 二分类和多分类。例如,二分类:吃不吃瓜? 多分类 : 吃什么瓜?
回归:预测值是实数,如,西瓜什么时候最低价?
聚类的分类,由机器自行分类,我们并不知道具体分几类 。
明确机器学习的目标是为了优化后的模型在对新样本进行预测的时候误差更小(“泛化”),而不仅是在训练样本上表现的更加优异。
这两点有较大的差异。为了实现强泛化能力,因此希望每个样本是独立地从分布上采取的,也就是“独立同分布”。
3、假设空间
- 归纳和演绎是科学推理的两大基本手段。
a) 演绎 是 是从一般到特殊的"特化"的过程,即从 基础原理 推演出具体状况。
b) 归纳 是 特殊到一般的 "泛化"过程,即从 具体的事实 归结出 一般性规律 。
- 归纳学习有狭义与广义之分。
广义的归纳学习大体相当于从样例中学习
狭义的归纳学习则要求从训练数据中学得概念(concept) ,因此亦称为 “概念学习"或"概念形成” (目前的研究、应用比较少,太难了)- 从样例中学习是一个归纳过程,因此称为“归纳学习”。
- 概念学习,最基本的是布尔概念学习,即对“是”“不是”的目标概念。
a) 学习的过程是一个在所有假设组成的空间中进行搜索的过程,搜索目标是找到与训练集匹配的假设(即能够将训练集中样本判断正确的假设)。
b) 搜索过程可以不断删除与正确不一致的假设和与错误一致的假设(在搜索时的选择不同删除的假设不同,搜索可以通过自顶向下,从一般到特殊,自底向上,从特殊到一般),这就是我们学习的结果。
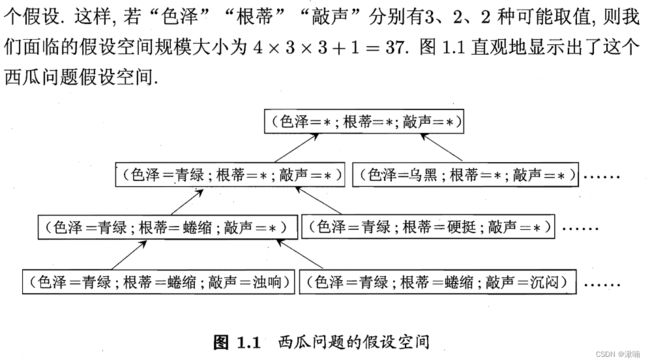
现实问题中假设空间很大,但学习过程是基于有限的样本训练集上进行的,因此可能会多个假设与训练集一致,即存在一个与训练集一致的“假设集合”,称之为 “版本空间” 。
c) 假设的表示一旦确定,假设空间及其规模大小酒确定了。如西瓜问题。
4、归纳偏好
- 归纳偏好 : .机器学习算法在学习过程中对某种类型假设的偏好。
任何一个有效的机器学习算法必有其归纳偏好,否则它将被假设空间中看似在训练集上"等效"的假设所迷惑,而无法产生确定的学习结果。一个没有算法偏好的模型,其判断结果是没有意义的。
同一个数据集能够训练出不同的模型。
- 偏好原则: 奥卡姆剃刀:如选择最简单的那个,或者按照其他需求。
- 若考虑所有潜在的问题,则所有学习算法都一样好,要谈论算法的相对优劣,必须要针对具体的学习问题。
- NFL定理
5、发展历程
推理期(逻辑推理能力)——知识期(人总结知识交给计算机)——知识期(机器自己学习知识)——学习期
机器学习:机械学习(死记硬背),示教学习(从指令中学习),类比学习(通过观察和发现学习),归纳学习(从样例中学习)。
机器学习是一种程序,具有自我改善的能力,人为干预越少越好。
二、模型评估与选择
A、一种训练集一种算法
2.1 经验误差 与 过拟合
-
错误率(error rate) : 分类错误的样本数占样本总数的比例。即如果在
m个样本中有a个样本分类错误,则错误率
E = a m E=\frac{a}{m} E=ma -
精度(accuracy):精度 = 1 - 错误率,精度常写为百分比形式(1-E)×100%
评判一个学习器训练得好不好的指标主要是 错误率 和 精度 。
-
误差期望 / 误差 (error) :学习器的实际预测输出与样本的真实输出之间的差异。一般用“误差”代指。
-
训练误差(training error)/经验误差(empirical error):学习器在训练集上的误差
-
泛化误差(generaliazation error):学习器在新样本上的误差。
在多种误差中,,我们希望得到泛化误差小的学习器。然而,我们事先并不知道新样本是什么样,实际能做的是努力使经验误差最小化。在很多情况下,我们可以学得一个经验误差很小、在训练集上表现很好的学习器。
为了达到这个目的,应该从训练样本中尽可能学出适用于所有样本的“普遍规律”,这样在遇到新的样本时,才能做出准确的判断。 -
过拟合 :学习器把训练样本学得"太好",导致把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,导致泛化性能下降的现象。
-
欠拟合:与过拟合相对的现象。
导致过/欠拟合的原因:学习能力过于强大,将训练样本不太一般的特性都学习到了;而欠拟合是因为学习能力较差造成的。
解决过/欠拟合的方法:欠拟合比较容易克服,可能增加学习轮数,或者扩大决策树的分支等;而过拟合则很麻烦,是机器学习面临的关键障碍,各类算法都必然带有一些针对过拟合的措施,但无法彻底避免,我们能做到的只是“缓解”

2.2 评估方法
在训练学习模型时,我们可通过实验测试 (测试集) 来学习器的泛化误差进行评估并进而做出选择。
现实任务中,我们有很多的学习算法可以选择,泛化误差不可事先预估,而训练误差又由于过拟合的存在而不适合作为评估标准,那么到底如何进行模型的评估与选择呢?
通常使用 测试集(testing set)来测试学习器对新样本的判别能力(假设测试样本也是从真实分布中独立同分布采样而得),同时需要尽可能使测试集与训练集互斥。一般将样本分为测试集T和训练集S,常见的划分方法如下:
a) 留出法
留出法(hold-out):直接将数据集 D分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,即D=S ∪T, S ∩ T= Ø 。在 S 上训练出模型后,用 T 来评估其测试误差,作为对泛化误差的估计。
常见划分方法:
1、简答的三七分、二八分,但注意训练集与测试机同分布
2、进行多次随机划分,训练多个模型,最后取平均值。
b) 交叉验证法
原理:k折交叉验证。
将数据 分为 个大小相似的互斥子集, D = D1 ∪ D2∪… ∪ Dk, D~ i~ ∩ Dj = ø (í 每个子集尽可 保持数据分布的一致性,即从 通过分层采样得到。每次用
k-1个子集的并集作为训练集?余 的那个子集作测试集;这样就可获得组训练试集,从而可进行 次训练和测试, 最终返回的是 测试结果的均值。
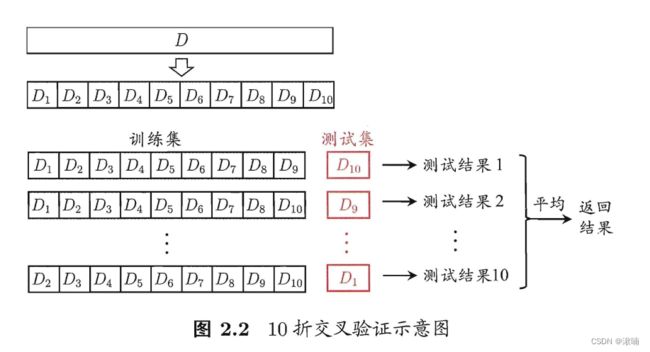
缺点:数据较大时,对算力要求高
与留出法相似,“10次 10 折交叉验证法”与“100次留出法”都是进行了 100 次训练/测试。
c) 自助法
原理:

适用场所:数据集较小,难以划分的时候,能从初始数据集中产生多个不同的训练集。
缺点:改变初始数据集分布,会引入估计偏差
d) 调参与最终模型
验证集
数据进入后每层神经网络有多少个神经元,每层大小的参数,多数是人为规定的,比较难调参。
调
3个参数,每个参数5个候选值,则一个数据集就会有 35 个模型需要考察。
因此,为了调参,会选择加入一个数据集,验证集。
训练集训练,验证集看结果,调参,再看验证集结果参数调完,最后再测试集上看结果。
2.3 性能度量
对学习器的泛化性能进行评估,除了实验评估的方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量(performance measure)
性能度量反映了任务需求,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果;模型的“好坏”是相对的,不仅取决于算法和数据,还决定与任务需求。
在预测任务中?给定样例集 = {(x1 , y1) , (x2, y2), . . . , (xm, ym)} 其中y1 是示例 xi 的真实标记.要评估学习器 的性能,就要把学习器预测结果 f(x)与真实标记 进行比较 。
- 回归任务最常用的性能度量是均方误差(mean squared error)。
- 分类错误率定义:

- 精度定义:

4.,对于数据分布 D 和概率密度函数 p(.) 错误率与精度可分别描述为:
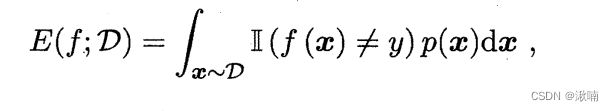
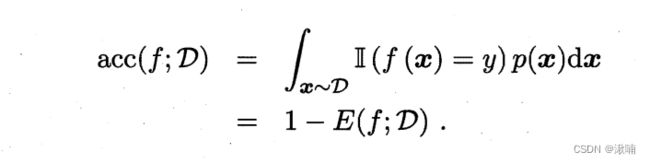
ps,Ⅱ(.)是指示函数,括号内为真取1,否则取0。
性能度量指标较多,但是一般常用的只有错误率、精度、查准率、查全率、F1、ROC 和 AUC。
a) 错误率与精度
-
错误率(error rate) : 分类错误的样本数占样本总数的比例。即如果在
m个样本中有a个样本分类错误,则错误率
E = a m E=\frac{a}{m} E=ma -
精度(accuracy):精度 = 1 - 错误率,精度常写为百分比形式(1-E)×100%
评判一个学习器训练得好不好的指标主要是 错误率 和 精度 。
错误率与精度 适用于二分类/多分类任务,是分类任务中最常用的两种性能度量。
b) 查准率、查全率与F1
- 查准率(precision):被学习器预测为正例的样例中有多大比例是真正例。如,挑出的西瓜中有多少比例是好瓜
- 查全率(recall):所有正例当中有多大比例被学习器预测为正例,所有好瓜中有多少比例被挑了出来。
- 分类结果混淆矩阵

查准率P=TP/(TP+FP); 查全率R=TP/(TP+FN),
查准率与查全率是一对矛盾的度量。
- 以查准率为纵轴、查全率为横轴作图,得到一个曲线称为 P-R曲线 。若一个学习器的P-R曲线,完全包住另一个学习器P-R曲线,则前者优于后者;若两者有交叉,则以平衡点的大小来进行对比。(平衡点(break-event point,简称BER):查准率=查全率时的取值)
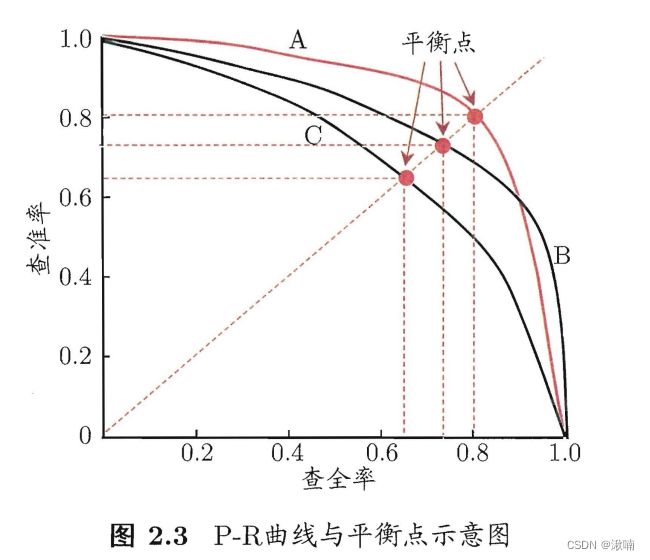
但,BEF 太过于简化,因此多用 F1(基于查准率与查全率的调和平均)
F1 = 2×P×R /(P+R) = 2×TP(样本总数+TP-TN)
P-R反向关系原理
我们定的分类阈值也会对最终的预测结果产生影响。假设评分高为正类,评分低为负类。阈值设置的比较低的时候,假正类少,假负类多。阈值设置的高时,假正类多,假负类比较少。对于下图判断是否为5的结果中:
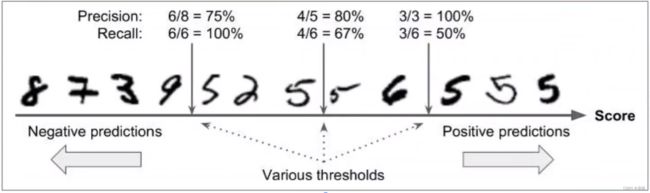
- 如果对预测比较严格,如 阈值为 5 ,此时,4 个 5 被预测出来,查准率 为 80%,查全率 为 67%。
- 如果对预测特别严格,如 阈值为 3 ,此时,3 个 5 被预测出来,查准率 为 100% ,查全率 为 50%。
- 如果对预测比较宽松,如 阈值为 8, 此时,6 个 5 被预测出来,查准率 为 75% ,所有的 5 都被查出来,查全率 为 100% 。
总结 : 把门的规则严,则准确率高;反之,则低。
那么阈值应该怎么确定?
确定最优阈值的方法主要有:
- 使用平衡点 BEP(Break-Even-Point )
R = P 时, B 与 P 的值
- F1度量
- Fbeta


为了能够综合考察查准率和查全率,总是 希望在 n 个二分类混淆矩阵,即,n个二分类实现的多分类问题
先分别计算,再求平均值。
先在各混淆矩阵上分别计算出查准率和查全率,记为 (P1, R1) ,…,(Pn, Rn) 再计算平均值,从而得到"宏查准率" (macro-P) “宏查全率” (macro-R) ,以及相应的"宏F1" (macro-F1)

先求平均值,再分别计算 准确率 和 查全率 。



2.4比较检验
a) 假设检验
b) 交叉验证 t 检验
c) McNemar 检验
d) Friedman 检验与 nenyl 后续检验
B、一种训练集多种算法
-
P-R 曲线
a)
b) 比较 ABC 三个模型的好坏
可以看见 B 与 A 都优于 C, 但 AB 存在交叉,无法判断谁更优
则对于AB有- 法一:比较AB面积大小,其在一定程度上表征了模型的优劣性,但这个值不容易被估算。
- 法二:F1
- 法三:Fbeta;
a) ROC与AUC
- ROC(Receiver Operating Characteristic,接受者操作特性曲线),是指在特定条件下,以在不同判断标准下所得的「预判错误率」为横坐标,以「预判正确率」为纵坐标,得到的多个点的连线,就是ROC曲线。
- ROC曲线由两个变量TPR和FPR组成,这个组合以FPR对TPR,即是以代价(costs)对收益(benefits)。
横坐标为「FPR」,在所有的负样本中,分类器预测错误的比例。FPR=负样本判为正的数量/(负样本判为正的数量+负样本判为负的数量)。
F P R = F P F P + T N FPR = \frac{FP}{FP + TN } FPR=FP+TNFP
纵坐标为「TPR」在所有的正样本中,分类器预测正确的比例(等于Recall)。TPR=正样本判为正的数量/(正样本判为正的数量+正样本判断为负数量)。
T P R = T P T P + F N TPR = \frac{TP}{TP + FN } TPR=TP+FNTP
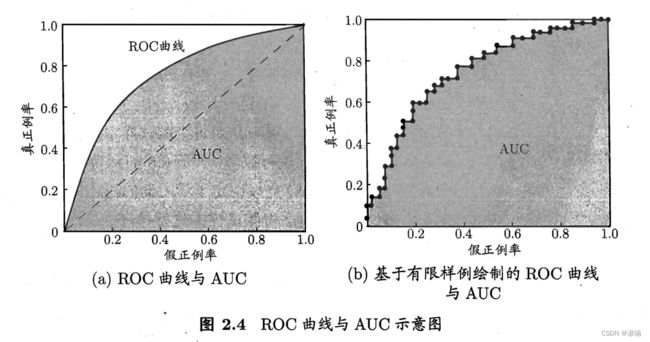
- AUC(Area Under Curve) 被定义为ROC曲线下与坐标轴围成的面积,在1*1坐标系中,AUC的取值范围在0.5和1之间。AUC越接近1.0,预测效果越好;等于0.5时,真实性最低,无应用价值。
- AUC的物理意义正样本的预测结果大于负样本的预测结果的概率。所以AUC反应的是分类器对样本的排序能力。

- 排序损失
给定 m+ 个正例和 m- 个反例令 D+ 和 D- 分别表示正、反例集合则排序“损失”(loss)定义为