【Python】数据分析+数据挖掘——变量列的相关操作
前言
在Python和Pandas中,变量列操作指的是对DataFrame中的列进行操作,包括但不限于选择列、重命名列、添加新列、删除列、修改列数据等操作。这些操作可以帮助我们处理数据、分析数据和进行特征工程等。
变量列的相关操作
概述
下面将会列出一些基本的操作指令
# 查看df的前number条数据,不填数字默认为5
df.head(number)
# 查看df的后number条数据,不填数字默认为5
df.tail(number)
# 数据框的基本信息
df.info()
# 列出所有的变量名
df.columns
# 修改变量列名
df.rename()
# 筛选单个相关的变量名
df.column_name # 还有一个表达 df['column_name']
# 筛选多个相关的变量名
df[['column_name1','column_name2'...]]
# 删除变量列
df.drop()
案例数据表university_rank.csv
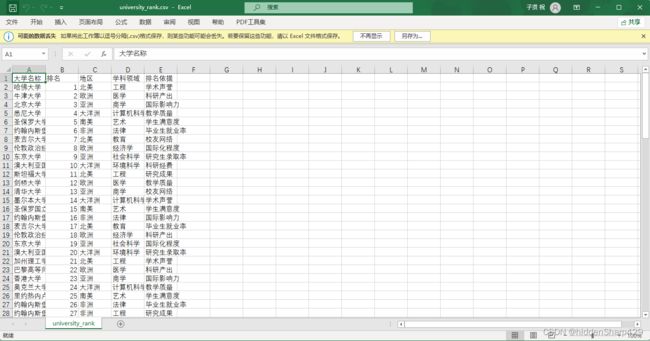
In[0]:
import pandas as pd # 引入pandas库
df = pd.read_csv("university_rank.csv") # 读取文件
df.head() # 显示文件头的记录(默认前五条)
out[0]:
| 大学名称 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|
| 排名 | ||||
| 1 | 哈佛大学 | 北美 | 工程 | 学术声誉 |
| 2 | 牛津大学 | 欧洲 | 医学 | 科研产出 |
| 3 | 北京大学 | 亚洲 | 商学 | 国际影响力 |
| 4 | 悉尼大学 | 大洋洲 | 计算机科学 | 教学质量 |
| 5 | 圣保罗大学 | 南美 | 艺术 | 学生满意度 |
In[1]:
df.tail() # 查看文件末的记录(默认后五条)
out[1]:
| 大学名称 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|
| 排名 | ||||
| 96 | 圣保罗国立大学 | 南美 | 计算机科学 | 研究生录取率 |
| 97 | 约翰内斯堡大学 | 非洲 | 环境科学 | 学术声誉 |
| 98 | 麦吉尔大学 | 北美 | 艺术 | 学生满意度 |
| 99 | 伦敦政治经济学院 | 欧洲 | 法律 | 国际影响力 |
| 100 | 东京大学 | 亚洲 | 教育 | 毕业生就业率 |
可以看的出来无论是df.head()还是df.tail(),如果里面不填写相关的参数,那么默认只查询5条记录。
那么接下来我们尝试一下给它们传入一些参数
In[2]:
number = 10 # 设置一个参数
df.head(number) # 传入参数
out[2]:
| 大学名称 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|
| 排名 | ||||
| 1 | 哈佛大学 | 北美 | 工程 | 学术声誉 |
| 2 | 牛津大学 | 欧洲 | 医学 | 科研产出 |
| 3 | 北京大学 | 亚洲 | 商学 | 国际影响力 |
| 4 | 悉尼大学 | 大洋洲 | 计算机科学 | 教学质量 |
| 5 | 圣保罗大学 | 南美 | 艺术 | 学生满意度 |
| 6 | 约翰内斯堡大学 | 非洲 | 法律 | 毕业生就业率 |
| 7 | 麦吉尔大学 | 北美 | 教育 | 校友网络 |
| 8 | 伦敦政治经济学院 | 欧洲 | 经济学 | 国际化程度 |
| 9 | 东京大学 | 亚洲 | 社会科学 | 研究生录取率 |
| 10 | 澳大利亚国立大学 | 大洋洲 | 环境科学 | 科研经费 |
注意:在jupyter notebook中默认情况下,如果DataFrame的行数超过一定阈值,默认情况下,Jupyter Notebook 会自动省略 DataFrame 中的行,显示前面几行和最后几行,并用省略号 ... 表示省略的行。这个阈值默认是 60 行,也就是说,当 DataFrame 的行数超过 60 行时,Jupyter Notebook 会自动省略中间的部分,只显示前几行和最后几行数据,您可以使用pd.set_option来调整Jupyter Notebook中DataFrame的显示行数和列数的限制。
# 设置显示的最大行数和列数为None,表示不限制
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
In[3]:
df.info() # 快速了解 DataFrame数据是否有缺失值、了解数据类型是否正确,以及预估内存占用情况。
out[3]:
Int64Index: 100 entries, 1 to 100
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 大学名称 100 non-null object
1 地区 100 non-null object
2 学科领域 100 non-null object
3 排名依据 100 non-null object
dtypes: object(4)
memory usage: 3.9+ KB
变量列的重命名
案例数据表university_rank.csv
我们先看一下DataFrame的列分别有什么,使用df.columns函数来查看
In[4]:
df = pd.read_csv("university.csv") # 读取文件
df.columns # 展示该DataFrame的列名
out[4]:
Index(['大学名称', '地区', '学科领域', '排名依据'], dtype='object')
在Pandas中有很多函数的作用都是重复的,故不需要掌握全部有关变量列重命名的函数,在这个案例中可以使用df.columns来修改列的名称,只需要给其赋值一个(列表)list就行
In[5]:
df.columns = ['university_name', 'site', 'area', 'rank_info'] # 更改列名
df # 展示新DataFrame
out[5]:
| university_name | site | area | rank_info | |
|---|---|---|---|---|
| 排名 | ||||
| 1 | 哈佛大学 | 北美 | 工程 | 学术声誉 |
| 2 | 牛津大学 | 欧洲 | 医学 | 科研产出 |
| 3 | 北京大学 | 亚洲 | 商学 | 国际影响力 |
| 4 | 悉尼大学 | 大洋洲 | 计算机科学 | 教学质量 |
| 5 | 圣保罗大学 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... |
| 96 | 圣保罗国立大学 | 南美 | 计算机科学 | 研究生录取率 |
| 97 | 约翰内斯堡大学 | 非洲 | 环境科学 | 学术声誉 |
| 98 | 麦吉尔大学 | 北美 | 艺术 | 学生满意度 |
| 99 | 伦敦政治经济学院 | 欧洲 | 法律 | 国际影响力 |
| 100 | 东京大学 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 4 columns
这里如果要使用df.columns = []来修改列名,则必须的要给出的list的大小与原DataFrame的变量列的数量一致,所以这里如果变量列很多,但是需要修改的列名却只有若干个的话,建议使用df.rename()来操作
df.rename(
# 修改列标签的字典
columns = {
'old_attribute1':'new_attribute1',
'old_attribute2':'new_attribute2',
...
},
# 修改行标签的字典
index
# 是否在原DataFrame上修改
inplace = False
)
In[6]:
new_df = df.rename(
columns={
'university_name': '学校名称',
'site': '地点'
}
) # 不在原df进行列的重命名
print(new_df) # 打印新的df
print(df) # 打印旧的df
out[6]:
学校名称 地点 area rank_info
排名
1 哈佛大学 北美 工程 学术声誉
2 牛津大学 欧洲 医学 科研产出
3 北京大学 亚洲 商学 国际影响力
4 悉尼大学 大洋洲 计算机科学 教学质量
5 圣保罗大学 南美 艺术 学生满意度
.. ... ... ... ...
96 圣保罗国立大学 南美 计算机科学 研究生录取率
97 约翰内斯堡大学 非洲 环境科学 学术声誉
98 麦吉尔大学 北美 艺术 学生满意度
99 伦敦政治经济学院 欧洲 法律 国际影响力
100 东京大学 亚洲 教育 毕业生就业率
[100 rows x 4 columns]
university_name site area rank_info
排名
1 哈佛大学 北美 工程 学术声誉
2 牛津大学 欧洲 医学 科研产出
3 北京大学 亚洲 商学 国际影响力
4 悉尼大学 大洋洲 计算机科学 教学质量
5 圣保罗大学 南美 艺术 学生满意度
.. ... ... ... ...
96 圣保罗国立大学 南美 计算机科学 研究生录取率
97 约翰内斯堡大学 非洲 环境科学 学术声誉
98 麦吉尔大学 北美 艺术 学生满意度
99 伦敦政治经济学院 欧洲 法律 国际影响力
100 东京大学 亚洲 教育 毕业生就业率
[100 rows x 4 columns]
若设置inplace = True则在原df上进行修改,因此就不需要进行赋值操作了。
In[7]:
df.rename(
columns={
'university_name': '学校名称',
'site': '地点',
'area': '学科领域',
'rank_info': '排名依据'
},
inplace=True
) # 在原df进行修改
print(df) # 打印新df
out[7]:
大学名称 地区 学科领域 排名依据
排名
1 哈佛大学 北美 工程 学术声誉
2 牛津大学 欧洲 医学 科研产出
3 北京大学 亚洲 商学 国际影响力
4 悉尼大学 大洋洲 计算机科学 教学质量
5 圣保罗大学 南美 艺术 学生满意度
.. ... ... ... ...
96 圣保罗国立大学 南美 计算机科学 研究生录取率
97 约翰内斯堡大学 非洲 环境科学 学术声誉
98 麦吉尔大学 北美 艺术 学生满意度
99 伦敦政治经济学院 欧洲 法律 国际影响力
100 东京大学 亚洲 教育 毕业生就业率
[100 rows x 4 columns]
补充:
有时候df.columns函数会搭配tolist函数
column_list = df.columns.tolist()
print(column_list)
变量列的筛选
在Pandas中对变量列筛选的函数冗余度很高,在这里只详细介绍一下最简单的方法
# 筛选单个列
df.column_name # column_name是您想要筛选的列标签
# 筛选多个列
df[['column_name1','columns_name2']]
案例数据表university_rank.csv
In[8]:
df = pd.read_csv("university_csv") # 读取案例文件
df.学校名称 # 使用df.column_name来筛选单列
out[7]:
排名
1 哈佛大学
2 牛津大学
3 北京大学
4 悉尼大学
5 圣保罗大学
...
96 圣保罗国立大学
97 约翰内斯堡大学
98 麦吉尔大学
99 伦敦政治经济学院
100 东京大学
Name: 学校名称, Length: 100, dtype: object
注意这里的df.column_name返回的数据类型结果是numpy中的Series
In[9]:
type(df.学校名称)
out[9]:
pandas.core.series.Series
其实不用 . 运算符也可以进行单列的筛选,使用df['column_name']拥有一样的效果,不过一般在对新增变量列的时候才会使用,也就是说当使用.来进行单列筛选的时候必须保证该DataFrame有该列,而使用df.["column_name"]则不需要。
In[10]:
df['学校名称']
out[10]:
排名
1 哈佛大学
2 牛津大学
3 北京大学
4 悉尼大学
5 圣保罗大学
...
96 圣保罗国立大学
97 约翰内斯堡大学
98 麦吉尔大学
99 伦敦政治经济学院
100 东京大学
Name: 学校名称, Length: 100, dtype: object
进行多列的筛选的时候需要使用列表嵌套
In[11]:
df[['学校名称', '排名依据']]
out[11]:
| 学校名称 | 排名依据 | |
|---|---|---|
| 排名 | ||
| 1 | 哈佛大学 | 学术声誉 |
| 2 | 牛津大学 | 科研产出 |
| 3 | 北京大学 | 国际影响力 |
| 4 | 悉尼大学 | 教学质量 |
| 5 | 圣保罗大学 | 学生满意度 |
| ... | ... | ... |
| 96 | 圣保罗国立大学 | 研究生录取率 |
| 97 | 约翰内斯堡大学 | 学术声誉 |
| 98 | 麦吉尔大学 | 学生满意度 |
| 99 | 伦敦政治经济学院 | 国际影响力 |
| 100 | 东京大学 | 毕业生就业率 |
100 rows × 2 columns
补充:
除了使用方括号 [] 运算符来筛选列,还可以使用 loc 属性、使用 iloc 属性
# loc:
# 假设 df 是一个 DataFrame,'column_name' 是您想要筛选的列标签
selected_column = df.loc[:, 'column_name'] # 筛选column_name列以及其前面的所有列
# iloc
# 假设 df 是一个 DataFrame,column_index 是您想要筛选的列的索引(从 0 开始)
selected_column = df.iloc[:, column_index]
删除变量列
要删除 DataFrame 中的变量列,可以使用 drop() 方法或 del 关键字。下面主要介绍这两种方法~
df.drop(
# 要删除的行索引或列标签。可以是单个值或一个包含多个值的列表
labels = [],
# 需要删除的列名的列表
columns = [],
# 用于指定要删除的行索引。可以是单个值或一个包含多个值的列表。与 axis=0 一起使用
index = [],
# 指定要删除的是行还是列。默认为 0,即删除行。如果要删除列,则应设置为 1
axis = 0
# 是否在在df上进行修改
inplace = False
)
案例数据表university_rank.csv
In[12]:
df = db
df.drop(
columns=['地区', '学科领域']
)
out[12]:
| 大学名称 | 排名依据 | |
|---|---|---|
| 排名 | ||
| 1 | 哈佛大学 | 学术声誉 |
| 2 | 牛津大学 | 科研产出 |
| 3 | 北京大学 | 国际影响力 |
| 4 | 悉尼大学 | 教学质量 |
| 5 | 圣保罗大学 | 学生满意度 |
| ... | ... | ... |
| 96 | 圣保罗国立大学 | 研究生录取率 |
| 97 | 约翰内斯堡大学 | 学术声誉 |
| 98 | 麦吉尔大学 | 学生满意度 |
| 99 | 伦敦政治经济学院 | 国际影响力 |
| 100 | 东京大学 | 毕业生就业率 |
100 rows × 2 columns
使用 del 关键字则是直接在原始 DataFrame 上进行删除,也就是在df.drop()中inplace参数默认为True
添加变量列
如果是对已有的变量列进行赋值则可以直接使用df.column_name = ?来对已有的column_name进行赋值
如果是想创建一个变量类则需要使用df[new_column_name] = '?' 来创建’new_column_name’,并且全部赋值成'?'
案例数据表university_rank.csv
In[13]:
df = pd.read_csv("university_rank.csv") # 读取案例数据
df # 展示案例数据
out[13]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 北美 | 工程 | 学术声誉 |
| 1 | 牛津大学 | 2 | 欧洲 | 医学 | 科研产出 |
| 2 | 北京大学 | 3 | 亚洲 | 商学 | 国际影响力 |
| 3 | 悉尼大学 | 4 | 大洋洲 | 计算机科学 | 教学质量 |
| 4 | 圣保罗大学 | 5 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 南美 | 计算机科学 | 研究生录取率 |
| 96 | 约翰内斯堡大学 | 97 | 非洲 | 环境科学 | 学术声誉 |
| 97 | 麦吉尔大学 | 98 | 北美 | 艺术 | 学生满意度 |
| 98 | 伦敦政治经济学院 | 99 | 欧洲 | 法律 | 国际影响力 |
| 99 | 东京大学 | 100 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 5 columns
In[14]:
df.地区 = "未知" # 使用`.`运算符进行对已有的变量列进行赋值
df # 展示修改后的表
out[14]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 未知 | 工程 | 学术声誉 |
| 1 | 牛津大学 | 2 | 未知 | 医学 | 科研产出 |
| 2 | 北京大学 | 3 | 未知 | 商学 | 国际影响力 |
| 3 | 悉尼大学 | 4 | 未知 | 计算机科学 | 教学质量 |
| 4 | 圣保罗大学 | 5 | 未知 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 未知 | 计算机科学 | 研究生录取率 |
| 96 | 约翰内斯堡大学 | 97 | 未知 | 环境科学 | 学术声誉 |
| 97 | 麦吉尔大学 | 98 | 未知 | 艺术 | 学生满意度 |
| 98 | 伦敦政治经济学院 | 99 | 未知 | 法律 | 国际影响力 |
| 99 | 东京大学 | 100 | 未知 | 教育 | 毕业生就业率 |
100 rows × 5 columns
使用df['column_name']来对原有的列进行赋值或者创建一个新的列
In[15]:
df = pd.read_csv("university_rank.csv") # 重新读一下数据表
df["入学人数"] = "未知" # 创建一个新的列,并且赋值为"未知"
df # 展示一下新的df
out[15]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | 入学人数 | |
|---|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 北美 | 工程 | 学术声誉 | 未知 |
| 1 | 牛津大学 | 2 | 欧洲 | 医学 | 科研产出 | 未知 |
| 2 | 北京大学 | 3 | 亚洲 | 商学 | 国际影响力 | 未知 |
| 3 | 悉尼大学 | 4 | 大洋洲 | 计算机科学 | 教学质量 | 未知 |
| 4 | 圣保罗大学 | 5 | 南美 | 艺术 | 学生满意度 | 未知 |
| ... | ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 南美 | 计算机科学 | 研究生录取率 | 未知 |
| 96 | 约翰内斯堡大学 | 97 | 非洲 | 环境科学 | 学术声誉 | 未知 |
| 97 | 麦吉尔大学 | 98 | 北美 | 艺术 | 学生满意度 | 未知 |
| 98 | 伦敦政治经济学院 | 99 | 欧洲 | 法律 | 国际影响力 | 未知 |
| 99 | 东京大学 | 100 | 亚洲 | 教育 | 毕业生就业率 | 未知 |
100 rows × 6 columns
使用df['column_name']的方法虽然简单,但是只能在列的末尾添加新的列,下面将介绍一个新的添加变量列的方法。
DataFrame支持插入的变量列自定义位置、列名、值、是否重名等,具体使用方法为df.insert
df.insert(
# 插入变量列的索引,第一个变量列为0,依次类推
loc
# 插入变量列的名称,是一个字符串
column
# 变量值,可以是单个标量值(如整数、浮点数、字符串等),也可以是一个与 DataFrame 行数相同长度的列表或 Series
value
# 是否允许重名
allow_duplicate = False
)
In[16]:
df = pd.read_csv("university_rank.csv") # 重新读入一下案例数据表
df.insert(loc=2, column="创办时间", value="未知") # 使用df.insert来插入新列表
df
out[16]:
| 大学名称 | 排名 | 创办时间 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 未知 | 北美 | 工程 | 学术声誉 |
| 1 | 牛津大学 | 2 | 未知 | 欧洲 | 医学 | 科研产出 |
| 2 | 北京大学 | 3 | 未知 | 亚洲 | 商学 | 国际影响力 |
| 3 | 悉尼大学 | 4 | 未知 | 大洋洲 | 计算机科学 | 教学质量 |
| 4 | 圣保罗大学 | 5 | 未知 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 未知 | 南美 | 计算机科学 | 研究生录取率 |
| 96 | 约翰内斯堡大学 | 97 | 未知 | 非洲 | 环境科学 | 学术声誉 |
| 97 | 麦吉尔大学 | 98 | 未知 | 北美 | 艺术 | 学生满意度 |
| 98 | 伦敦政治经济学院 | 99 | 未知 | 欧洲 | 法律 | 国际影响力 |
| 99 | 东京大学 | 100 | 未知 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 6 columns
变量列的四则运算
对DataFrame类型数据进行运算时需要考虑到库支持类型是否满足运行需求,常用的库有math\numpy
numpy库中的运算可以支持Series类型数据而math库中并不支持,需要使用别的函数来进行类型转换
注:在添加变量列的时候也可以进行四则运算
案例数据表university_rank.csv
In[17]:
import numpy as np # 为了进行运算,先导入numpy库
df = pd.read_csv("university_rank.csv") # 读取案例数据表
df["入学人数"] = 1000 # 在列末尾新增一个变量列并赋值1000
df.入学人数 = np.sqrt(df.入学人数) # 对新增的变量列进行运算
df # 展示运算后的数据表
out[17]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | 入学人数 | |
|---|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 北美 | 工程 | 学术声誉 | 31.622777 |
| 1 | 牛津大学 | 2 | 欧洲 | 医学 | 科研产出 | 31.622777 |
| 2 | 北京大学 | 3 | 亚洲 | 商学 | 国际影响力 | 31.622777 |
| 3 | 悉尼大学 | 4 | 大洋洲 | 计算机科学 | 教学质量 | 31.622777 |
| 4 | 圣保罗大学 | 5 | 南美 | 艺术 | 学生满意度 | 31.622777 |
| ... | ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 南美 | 计算机科学 | 研究生录取率 | 31.622777 |
| 96 | 约翰内斯堡大学 | 97 | 非洲 | 环境科学 | 学术声誉 | 31.622777 |
| 97 | 麦吉尔大学 | 98 | 北美 | 艺术 | 学生满意度 | 31.622777 |
| 98 | 伦敦政治经济学院 | 99 | 欧洲 | 法律 | 国际影响力 | 31.622777 |
| 99 | 东京大学 | 100 | 亚洲 | 教育 | 毕业生就业率 | 31.622777 |
100 rows × 6 columns
如果不想在原来的DataFrame上进行修改,则可以使用df.assign
In[18]:
df = pd.read_csv("university_rank.csv")
df["入学人数"] = 10000
df1 = df.assign(入学人数=np.sqrt(df.入学人数))
print(df)
print(df1)
out[18]:
大学名称 排名 地区 学科领域 排名依据 入学人数
0 哈佛大学 1 北美 工程 学术声誉 10000
1 牛津大学 2 欧洲 医学 科研产出 10000
2 北京大学 3 亚洲 商学 国际影响力 10000
3 悉尼大学 4 大洋洲 计算机科学 教学质量 10000
4 圣保罗大学 5 南美 艺术 学生满意度 10000
.. ... ... ... ... ... ...
95 圣保罗国立大学 96 南美 计算机科学 研究生录取率 10000
96 约翰内斯堡大学 97 非洲 环境科学 学术声誉 10000
97 麦吉尔大学 98 北美 艺术 学生满意度 10000
98 伦敦政治经济学院 99 欧洲 法律 国际影响力 10000
99 东京大学 100 亚洲 教育 毕业生就业率 10000
[100 rows x 6 columns]
大学名称 排名 地区 学科领域 排名依据 入学人数
0 哈佛大学 1 北美 工程 学术声誉 100.0
1 牛津大学 2 欧洲 医学 科研产出 100.0
2 北京大学 3 亚洲 商学 国际影响力 100.0
3 悉尼大学 4 大洋洲 计算机科学 教学质量 100.0
4 圣保罗大学 5 南美 艺术 学生满意度 100.0
.. ... ... ... ... ... ...
95 圣保罗国立大学 96 南美 计算机科学 研究生录取率 100.0
96 约翰内斯堡大学 97 非洲 环境科学 学术声誉 100.0
97 麦吉尔大学 98 北美 艺术 学生满意度 100.0
98 伦敦政治经济学院 99 欧洲 法律 国际影响力 100.0
99 东京大学 100 亚洲 教育 毕业生就业率 100.0
[100 rows x 6 columns]
如果是用math库,那么就需要使用apply进行中间转化,将Series转换成math库支持的类型进行运算
In[19]:
import math # 使用math库中的运算函数
df = pd.read_csv("university_rank.csv")
df["入学人数"] = 10000
df.入学人数 = df.入学人数.apply(math.sqrt) # 需要使用apply函数进行类型转换
df # 展示新数据表
out[19]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | 入学人数 | |
|---|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 北美 | 工程 | 学术声誉 | 100.0 |
| 1 | 牛津大学 | 2 | 欧洲 | 医学 | 科研产出 | 100.0 |
| 2 | 北京大学 | 3 | 亚洲 | 商学 | 国际影响力 | 100.0 |
| 3 | 悉尼大学 | 4 | 大洋洲 | 计算机科学 | 教学质量 | 100.0 |
| 4 | 圣保罗大学 | 5 | 南美 | 艺术 | 学生满意度 | 100.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 南美 | 计算机科学 | 研究生录取率 | 100.0 |
| 96 | 约翰内斯堡大学 | 97 | 非洲 | 环境科学 | 学术声誉 | 100.0 |
| 97 | 麦吉尔大学 | 98 | 北美 | 艺术 | 学生满意度 | 100.0 |
| 98 | 伦敦政治经济学院 | 99 | 欧洲 | 法律 | 国际影响力 | 100.0 |
| 99 | 东京大学 | 100 | 亚洲 | 教育 | 毕业生就业率 | 100.0 |
100 rows × 6 columns
假如是对所有的cell进行运算而不是单独的几列进行运算,那么就可以使用df.applymap方法
In[20]:
df[["排名", "入学人数"]].applymap(math.sqrt)
out[20]:
| 排名 | 入学人数 | |
|---|---|---|
| 0 | 1.000000 | 10.0 |
| 1 | 1.414214 | 10.0 |
| 2 | 1.732051 | 10.0 |
| 3 | 2.000000 | 10.0 |
| 4 | 2.236068 | 10.0 |
| ... | ... | ... |
| 95 | 9.797959 | 10.0 |
| 96 | 9.848858 | 10.0 |
| 97 | 9.899495 | 10.0 |
| 98 | 9.949874 | 10.0 |
| 99 | 10.000000 | 10.0 |
100 rows × 2 columns
结束语
如果有疑问欢迎大家留言讨论,你如果觉得这篇文章对你有帮助可以给我一个免费的赞吗?我们之间的交流是我最大的动力!