大数据学习05-Kafka分布式集群部署
系统环境:centos7
软件版本:jdk1.8、zookeeper3.4.8、hadoop2.8.5
本次实验使用版本 kafka_2.12-3.0.0
一、安装
Kafka官网

将安装包上传至linux服务器上

解压
tar -zxvf kafka_2.12-3.0.0.tgz -C /home/local/
移动目录至kafka
mv kafka_2.12-3.0.0/ kafka
二、部署
配置Kafka环境
vi /etc/profile
添加如下配置
#kafka
export KAFKA_HOME=/home/local/kafka
export PATH=$PATH:${KAFKA_HOME}/bin
修改server.properties文件
vim /home/local/kafka/config/server.properties
修改参数如下:
broker.id=0
listeners=PLAINTEXT://192.168.245.200:9092
log.dirs=/tmp/kafka-logs
zookeeper.connect=192.168.245.200:2181,192.168.245.201:2181,192.168.245.202:2181
参数说明:
broker.id : 集群内全局唯一标识,每个节点上需要设置不同的值
listeners:这个IP地址也是与本机相关的,每个节点上设置为自己的IP地址
log.dirs :存放kafka消息的
zookeeper.connect : 配置的是zookeeper集群地址
分发kafka安装目录
for i in {1..2};do scp -r /home/local/kafka root@slave${i}:/home/local/;done
三、启动
进入kafka安装目录下
./bin/kafka-server-start.sh ./config/server.properties &
kafka相关命令
创建topic
kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
显示所有topic
kafka-topics.sh --list --bootstrap-server localhost:9092
产生消息
kafka-console-producer.sh --broker-list localhost:9092 --topic test
消费消息
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
删除topic
kafka-topics.sh --delete --bootstrap-server localhost:9092 --topic test
四、flink与kafka结合示例
首先 ,构建maven工程,加入flink与kafka的一些依赖:
4.0.0
org.example
bigdata-kafka_2.12-3.0.0
1.0-SNAPSHOT
bigdata-kafka_2.12-3.0.0
http://www.example.com
UTF-8
1.8
1.8
1.14.0
2.11.2
org.apache.flink
flink-java
${flink-version}
org.apache.flink
flink-streaming-java_2.11
${flink-version}
org.apache.flink
flink-clients_2.11
${flink-version}
org.apache.flink
flink-connector-kafka_2.11
${flink-version}
junit
junit
4.11
test
第一个,flink生产者示例代码:
package com.example;
import org.apache.commons.lang3.RandomStringUtils;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.io.Serializable;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.245.200:9092");
DataStream<String> stream = env.addSource(new SimpleStringGenerator());
stream.addSink(new FlinkKafkaProducer<String>("test", new SimpleStringSchema(), props));
env.execute();
}
}
class SimpleStringGenerator implements SourceFunction<String>, Serializable {
private static final long serialVersionUID = 1L;
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (isRunning) {
String str = RandomStringUtils.randomAlphanumeric(5);
ctx.collect(str);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
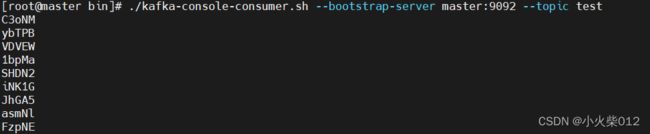
因为flink是生产者,需要启动一个kafka的消费者终端,然后运行本示例:
启动kafka
bin/kafka-server-start.sh config/server.properties &
启动一个kafka的消费者终端
bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic test
终端内容
第二个,flink消费者示例代码:
package com.example;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class KafkaConsumerApp {
public static void main(String[] args) {
try {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "master:9092");
properties.setProperty("group.id", "flink");
DataStream<String> stream = env.addSource(new FlinkKafkaConsumer<String>("test", new SimpleStringSchema(), properties));
stream.map(new MapFunction<String, Object>() {
@Override
public Object map(String value) throws Exception {
return "flink: " + value;
}
}).print();
env.execute("consumer");
} catch (Exception e) {
e.printStackTrace();
}
}
}
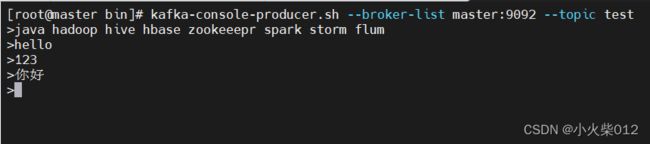
为了测试,我们先开启一个生产者,不断往kafka中发送消息。
kafka-console-producer.sh --broker-list master:9092 --topic test
终端
控制台
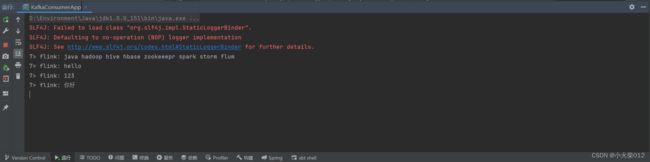
打印结果符合预期,flink与kafka结合的示例就演示完成了,主要的还是熟悉flink编程。