爬虫框架 - feapder
官方文档:https://feapder.com
github:https://github.com/Boris-code/feapder
更新日志:https://github.com/Boris-code/feapder/releases
爬虫管理系统:http://feapder.com/#/feapder_platform/feaplat
爬虫在线工具库:http://www.spidertools.cn
爬虫管理系统:http://feapder.com/#/feapder_platform/feaplat
验证码识别库:https://github.com/sml2h3/ddddocr
:https://zhuanlan.zhihu.com/p/411085904
1、feapder 简介
对于学习 Python 爬虫的人来说,Scrapy 这个框架是一个绕不过去的槛。它是一个非常重量级的 Python 爬虫框架,如果你想要做一些复杂的爬虫项目,可能就需要用到它。
但是,由于 Scrapy 框架很复杂,它的学习成本也非常高,学习的道路上布满了很多坑,并且都很难找到解决办法。对于初学者来说,学习 Scrapy 框架需要极大的耐心和勇气,一般人很有可能在中途就放弃了。既然有痛点,肯定就有人来抚慰。类似于 Scrapy 的开源爬虫框架 --- feapder,它的架构逻辑和 Scrapy 类似,但是学习成本非常低,不需要繁琐的配置,不需要复杂的项目架构,也可以轻松应对复杂爬虫需求。
- feapder是一款上手简单,功能强大的Python爬虫框架,内置 AirSpider、Spider、TaskSpider、BatchSpider 四种爬虫解决不同场景的需求。
- 支持断点续爬、监控报警、浏览器渲染、海量数据去重等功能。
- 更有功能强大的爬虫管理系统feaplat为其提供方便的部署及调度
通用版、完整版:区别在于完整版支持基于内存去重。
通用版:pip3 install feapder
完整版:pip3 install feapder[all]

2、使用 feapder
轻量爬虫 - AirSpider
创建爬虫
创建爬虫的语句跟 Scrapy 类似:feapder create -s air_spider_test
请选择爬虫模板
> AirSpider
Spider
TaskSpider
BatchSpider
运行完成后,就会在当前目录下生成一个 report_spider.py 的文件,打开文件后,我们可以看到一个初始化的代码:
import feapder
class AirSpiderTest(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
AirSpiderTest().start()
默认生成的代码继承了feapder.AirSpider,包含 start_requests 及 parser 两个函数,含义如下:
- feapder.AirSpider:轻量爬虫基类
- start_requests:初始任务下发入口
- feapder.Request:基于requests库类似,表示一个请求,支持requests所有参数,同时也可携带些自定义的参数,详情可参考Request
- parser:数据解析函数
- response:请求响应的返回体,支持xpath、re、css等解析方式,详情可参考Response
除了start_requests、parser两个函数。系统还内置了下载中间件等函数,具体支持可参考BaseParser
自定义解析函数
东方财富网的股票研报数据:https://data.eastmoney.com/report/
开发过程中解析函数往往不止有一个,除了系统默认的 parser 外,还支持自定义解析函数,比如我要写一个自己的解析函数,写法如下:
def start_requests(self):
yield feapder.Request(
url="https://data.eastmoney.com/xg/",
callback=self.parse_func
)
def parse_func(self, request, response):
html = response.content.decode("utf-8")
print(html)只需要在 Request 请求中加个 callback 参数,将自定义解析函数名放进去即可。不指定时默认回调 parser。
携带参数
如果你需要将请求中的一些参数带到解析函数中,你可以这样做:
def start_requests(self):
yield feapder.Request(
url="https://data.eastmoney.com/xg/",
callback=self.parse_func,
custom_arg_1='custom_arg_1',
)
def parse_func(self, request, response):
custom_arg_1 = request.custom_arg_1
html = response.content.decode("utf-8")
print(html)在 Request 里面添加你需要携带的参数,在解析函数中通过 request.xxx 就可以获取到。
下载中间件
下载中间件用于在请求之前,对请求做一些处理,如添加cookie、header等。写法如下:
def download_midware(self, request):
request.headers = {
"Connection": "keep-alive",
"Cookie": "xxx=0f1ac887e1e3e484715bf0e3f148dbd8;",
"User-Agent": "xxx",
"Host": "www.xxx.xxx"
}
return request这里我主要添加了一些请求头信息,模拟真实浏览器访问场景。request.参数, 这里的参数支持requests所有参数,同时也可携带些自定义的参数,详情可参考Request
默认所有的解析函数在请求之前都会经过此下载中间件
自定义下载中间件
与自定义解析函数类似,下载中间件也支持自定义,只需要在feapder.Request参数里指定个download_midware回调即可,写法如下:
def start_requests(self):
yield feapder.Request("https://www.baidu.com", download_midware=self.xxx)
def xxx(self, request):
"""
我是自定义的下载中间件
:param request:
:return:
"""
request.headers = {'User-Agent':"lalala"}
return request
自定义的下载中间件只有指定的请求才会经过。其他未指定下载中间件的请求,还是会经过默认的下载中间件
校验
校验函数, 可用于校验 response 是否正确。若函数内抛出异常,则重试请求。若返回 True 或 None,则进入解析函数,若返回 False,则抛弃当前请求。可通过 request.callback_name 区分不同的回调函数,编写不同的校验逻辑。
def validate(self, request, response):
if response.status_code != 200:
raise Exception("response code not 200") # 重试失败重试机制
框架支持重试机制,下载失败或解析函数抛出异常会自动重试请求。上面的校验中,我们抛出异常,就可以触发重试机制。
例如下面代码,校验了返回的code是否为200,非200抛出异常,触发重试
def parse(self, request, response):
if response.status_code != 200:
raise Exception("非法页面")
默认最大重试次数为100次,我们可以引入配置文件或自定义配置来修改重试次数,详情参考配置文件
爬虫配置
爬虫配置支持自定义配置或引入配置文件setting.py的方式。
配置文件:在工作区间的根目录下引入setting.py,具体参考配置文件
我们可以在配置里面配置 数据库信息、Redis 信息、日志信息等等。
这里给出一份最全的配置,各位自己可以从这些配置中选一些自己需要的进行配置。
import os
# MYSQL
MYSQL_IP = ""
MYSQL_PORT = 3306
MYSQL_DB = ""
MYSQL_USER_NAME = ""
MYSQL_USER_PASS = ""
# REDIS
# IP:PORT
REDISDB_IP_PORTS = "xxx:6379"
REDISDB_USER_PASS = ""
# 默认 0 到 15 共16个数据库
REDISDB_DB = 0
# 数据入库的pipeline,可自定义,默认MysqlPipeline
ITEM_PIPELINES = ["feapder.pipelines.mysql_pipeline.MysqlPipeline"]
# 爬虫相关
# COLLECTOR
COLLECTOR_SLEEP_TIME = 1 # 从任务队列中获取任务到内存队列的间隔
COLLECTOR_TASK_COUNT = 100 # 每次获取任务数量
# SPIDER
SPIDER_THREAD_COUNT = 10 # 爬虫并发数
SPIDER_SLEEP_TIME = 0 # 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5
SPIDER_MAX_RETRY_TIMES = 100 # 每个请求最大重试次数
# 浏览器渲染下载
WEBDRIVER = dict(
pool_size=2, # 浏览器的数量
load_images=False, # 是否加载图片
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
driver_type="CHROME", # CHROME 或 PHANTOMJS,
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path=None, # 浏览器路径,默认为默认路径
render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
)
# 重新尝试失败的requests 当requests重试次数超过允许的最大重试次数算失败
RETRY_FAILED_REQUESTS = False
# request 超时时间,超过这个时间重新做(不是网络请求的超时时间)单位秒
REQUEST_LOST_TIMEOUT = 600 # 10分钟
# 保存失败的request
SAVE_FAILED_REQUEST = True
# 下载缓存 利用redis缓存,由于内存小,所以仅供测试时使用
RESPONSE_CACHED_ENABLE = False # 是否启用下载缓存 成本高的数据或容易变需求的数据,建议设置为True
RESPONSE_CACHED_EXPIRE_TIME = 3600 # 缓存时间 秒
RESPONSE_CACHED_USED = False # 是否使用缓存 补采数据时可设置为True
WARNING_FAILED_COUNT = 1000 # 任务失败数 超过WARNING_FAILED_COUNT则报警
# 爬虫是否常驻
KEEP_ALIVE = False
# 设置代理
PROXY_EXTRACT_API = None # 代理提取API ,返回的代理分割符为\r\n
PROXY_ENABLE = True
# 随机headers
RANDOM_HEADERS = True
# requests 使用session
USE_SESSION = False
# 去重
ITEM_FILTER_ENABLE = False # item 去重
REQUEST_FILTER_ENABLE = False # request 去重
# 报警 支持钉钉及邮件,二选一即可
# 钉钉报警
DINGDING_WARNING_URL = "" # 钉钉机器人api
DINGDING_WARNING_PHONE = "" # 报警人 支持列表,可指定多个
# 邮件报警
EMAIL_SENDER = "" # 发件人
EMAIL_PASSWORD = "" # 授权码
EMAIL_RECEIVER = "" # 收件人 支持列表,可指定多个
# 时间间隔
WARNING_INTERVAL = 3600 # 相同报警的报警时间间隔,防止刷屏; 0表示不去重
WARNING_LEVEL = "DEBUG" # 报警级别, DEBUG / ERROR
LOG_NAME = os.path.basename(os.getcwd())
LOG_PATH = "log/%s.log" % LOG_NAME # log存储路径
LOG_LEVEL = "DEBUG"
LOG_COLOR = True # 是否带有颜色
LOG_IS_WRITE_TO_CONSOLE = True # 是否打印到控制台
LOG_IS_WRITE_TO_FILE = False # 是否写文件
LOG_MODE = "w" # 写文件的模式
LOG_MAX_BYTES = 10 * 1024 * 1024 # 每个日志文件的最大字节数
LOG_BACKUP_COUNT = 20 # 日志文件保留数量
LOG_ENCODING = "utf8" # 日志文件编码
OTHERS_LOG_LEVAL = "ERROR" # 第三方库的log等级
自定义配置: 使用类变量__custom_setting__:
class AirSpiderTest(feapder.AirSpider):
__custom_setting__ = dict(
PROXY_EXTRACT_API="代理提取地址",
)
上例是配置代理提取地址,以便爬虫使用代理,自定义配置支持配置文件中的所有参数。
配置优先级: 自定义配置 > 配置文件,即自定义配置会覆盖配置文件里的配置信息,不过自定义配置只对自己有效,配置文件可以是多个爬虫公用的
AirSpider不支持去重,因此配置文件中的去重配置无效
数据入库
框架内封装了MysqlDB、RedisDB,与pymysql不同的是,MysqlDB 使用了线程池,且对方法进行了封装,使用起来更方便。RedisDB 支持 哨兵模式、集群模式。
如果你在 setting 文件中配置了数据库信息,你就可以直接使用:
import feapder
from feapder.db.mysqldb import MysqlDB
from feapder.db.redisdb import RedisDB
class AirSpiderTest(feapder.AirSpider):
__custom_setting__ = dict(
MYSQL_IP="localhost",
MYSQL_PORT=3306,
MYSQL_DB="feapder",
MYSQL_USER_NAME="feapder",
MYSQL_USER_PASS="feapder123"
)
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.db = MysqlDB()
如果没有配置,你也可以在代码里面进行配置:
db = MysqlDB(
ip="localhost",
port=3306,
user_name="feapder",
user_pass="feapder123",
db="feapder"
)
建立数据库连接后,你就可以使用这个框架内置的数据库增删改查函数进行数据库操作了。具体方法可以根据代码提示来查看:

MysqlDB 的具体使用方法见 MysqlDB
RedisDB 的具体使用方法见 RedisDB
框架也支持数据自动入库,详见数据自动入库
浏览器渲染下载
采集动态页面时(Ajax渲染的页面),常用的有两种方案。一种是找接口拼参数,这种方式比较复杂但效率高,需要一定的爬虫功底;另外一种是采用浏览器渲染的方式,直接获取源码,简单方便
def start_requests(self):
yield feapder.Request("https://news.qq.com/", render=True)
在返回的Request中传递render=True即可
框架支持CHROME和PHANTOMJS两种浏览器渲染,可通过配置文件进行配置。相关配置如下:
# 浏览器渲染
WEBDRIVER = dict(
pool_size=1, # 浏览器的数量
load_images=True, # 是否加载图片
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
driver_type="CHROME", # CHROME 或 PHANTOMJS,
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path=None, # 浏览器路径,默认为默认路径
render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
)
自定义下载器
自定义下载器即在下载中间件里下载,然后返回response即可,如使用httpx库下载以便支持http2
import feapder
import httpx
class AirSpeedTest(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("http://www.baidu.com")
def download_midware(self, request):
with httpx.Client(http2=True) as client:
response = client.get(request.url)
return request, response
def parse(self, request, response):
print(response)
if __name__ == "__main__":
AirSpeedTest(thread_count=1).start()
注意,解析函数里的response已经变成了下载中间件返回的response,而非默认的。若想用xpath、css等解析功能,写法如下
import feapder
import httpx
from feapder.network.selector import Selector
class AirSpeedTest(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("http://www.baidu.com")
def download_midware(self, request):
with httpx.Client(http2=True) as client:
response = client.get(request.url)
return request, response
def parse(self, request, response):
selector = Selector(response.text)
title = selector.xpath("//title/text()").extract_first()
print(title)
完整的代码示例
AirSpider:https://github.com/Boris-code/feapder/blob/master/tests/air-spider/test_air_spider.py
浏览器渲染:feapder/test_rander.py at master · Boris-code/feapder · GitHub
示例 ( AirSpider ):豆瓣电影top250
import feapder
class SpiderTest(feapder.AirSpider):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.62",
}
pass
def start_requests(self):
for page_num in range(1, 11):
index = (page_num - 1) * 25
# https://movie.douban.com/top250?start=50&filter=
url = f"https://movie.douban.com/top250?start={index}&filter="
yield feapder.Request(url, headers=self.headers)
def parse(self, request, response):
movie_name_list = response.xpath('//div[@class="item"]//div[@class="hd"]/a/span[1]/text()').extract()
movie_url_list = response.xpath('//div[@class="item"]//div[@class="hd"]/a/@href').extract()
movie_info_list = list(zip(movie_name_list, movie_url_list))
list(map(lambda x=None: print(x), movie_info_list))
for movie_info in movie_info_list:
movie_name, movie_url = movie_info
yield feapder.Request(
movie_url, callback=self.parse_movie_detail, movie_name=movie_name,
headers=self.headers
) # callback 为回调函数
def parse_movie_detail(self, request, response):
"""
解析详情
"""
# 取 movie_url
movie_url = request.url
# 取 movie_name
movie_name = request.movie_name
# 解析正文
content = response.xpath('string(//div[@class="subject clearfix"])').extract_first()
print("movie_url", movie_url)
print("movie_name", movie_name)
print("content", content.strip())
if __name__ == "__main__":
SpiderTest(thread_count=2).start()
运行效果:

分布式爬虫:Spider ( 普通分布式爬虫 )
分布式说白了就是启动多个进程,处理同一批任务。Spider支持启动多份,且不会重复发下任务,我们可以在多个服务器上部署启动,也可以在同一个机器上启动多次。
Spider 是一款基于redis的分布式爬虫,适用于海量数据采集,支持断点续爬、爬虫报警、数据自动入库等功能
- 普通 分布式 爬虫:就是初始的 url 是通过 start_requests 这个函数 yield 后,框架自动添加到 redis 中,如果再次启动一个爬虫 实例,则这个爬虫实例首先会检查对应的 redis_key 里面有没有任务,如果有任务,则直接从 redis_key 队列里面获取任务并进行抓取,如果没有,则执行 start_requests 添加任务。查看源码注释可以看到 start_requests 是添加 初始 url 用的
- 任务 分布式 爬虫:是直接从 redis_key 队列里面取任务
创建项目
创建项目这一步不是必须的,一个脚本可以解决的需求,可直接创建爬虫。若需求比较复杂,需要写多个爬虫,那么最好用项目形式把这些脚本管理起来。
命令:feapder create -p spider-project
创建好项目后,开发时我们需要将项目设置为工作区间,否则引入非同级目录下的文件时,编译器会报错。不过因为main.py在项目的根目录下,因此不影响正常运行。
设置工作区间方式(以pycharm为例):项目->右键->Mark Directory as -> Sources Root
创建 爬虫
命令:feapder create -s spider_test
请选择爬虫模板
AirSpider
> Spider
TaskSpider
BatchSpider
生成代码如下
import feapder
class SpiderTest(feapder.Spider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
__custom_setting__ = dict(
REDISDB_IP_PORTS="localhost:6379", REDISDB_USER_PASS="", REDISDB_DB=0
)
def start_requests(self):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
SpiderTest(redis_key="xxx:xxx").start()
因 Spider 是基于 redis 做的分布式,因此模板代码默认给了 redis 的配置方式,连接信息需按真实情况修改。redis 配置信息如下:
# redis 表名
# 任务表模版
TAB_REQUESTS = "{redis_key}:z_requests"
# 任务失败模板
TAB_FAILED_REQUESTS = "{redis_key}:z_failed_requests"
# 数据保存失败模板
TAB_FAILED_ITEMS = "{redis_key}:s_failed_items"
# 爬虫状态表模版
TAB_SPIDER_STATUS = "{redis_key}:h_spider_status"
# 用户池
TAB_USER_POOL = "{redis_key}:h_{user_type}_pool"# REDIS
# ip:port 多个可写为列表或者逗号隔开 如 ip1:port1,ip2:port2 或 ["ip1:port1", "ip2:port2"]
REDISDB_IP_PORTS = os.getenv("REDISDB_IP_PORTS")
REDISDB_USER_PASS = os.getenv("REDISDB_USER_PASS")
REDISDB_DB = int(os.getenv("REDISDB_DB", 0))
# 适用于redis哨兵模式
REDISDB_SERVICE_NAME = os.getenv("REDISDB_SERVICE_NAME")
Spider参数:redis_key 为 redis 中存储任务等信息的 key 前缀,如 redis_key="feapder:spider_test",则redis中会生成如下

更详细的说明可查看 Spider进阶
AirSpider支持的方法Spider都支持,使用方式一致
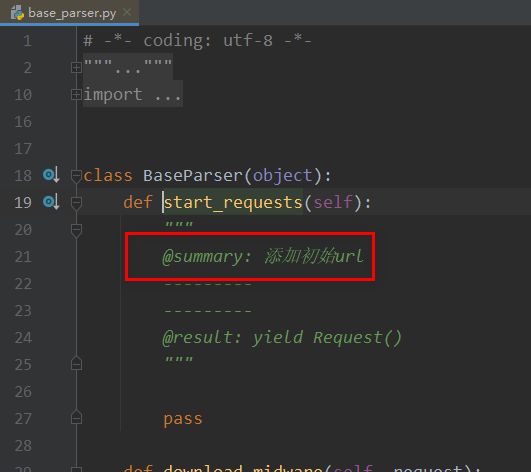
redis 全部配置
class Spider(
BaseParser, Scheduler
): # threading 中有name函数, 必须先继承BaseParser 否则其内部的name会被Schedule的基类threading.Thread的name覆盖
"""
@summary: 为了简化搭建爬虫
---------
"""def __init__(
self,
redis_key=None,
min_task_count=1,
check_task_interval=5,
thread_count=None,
begin_callback=None,
end_callback=None,
delete_keys=(),
keep_alive=None,
auto_start_requests=None,
batch_interval=0,
wait_lock=True,
**kwargs
):
"""
@summary: 爬虫
---------
@param redis_key: 任务等数据存放在redis中的key前缀
@param min_task_count: 任务队列中最少任务数, 少于这个数量才会添加任务,默认1。start_monitor_task 模式下生效
@param check_task_interval: 检查是否还有任务的时间间隔;默认5秒
@param thread_count: 线程数,默认为配置文件中的线程数
@param begin_callback: 爬虫开始回调函数
@param end_callback: 爬虫结束回调函数
@param delete_keys: 爬虫启动时删除的key,类型: 元组/bool/string。 支持正则; 常用于清空任务队列,否则重启时会断点续爬
@param keep_alive: 爬虫是否常驻
@param auto_start_requests: 爬虫是否自动添加任务
@param batch_interval: 抓取时间间隔 默认为0 天为单位 多次启动时,只有当前时间与第一次抓取结束的时间间隔大于指定的时间间隔时,爬虫才启动
@param wait_lock: 下发任务时否等待锁,若不等待锁,可能会存在多进程同时在下发一样的任务,因此分布式环境下请将该值设置True
---------
@result:
"""
super(Spider, self).__init__(
redis_key=redis_key,
thread_count=thread_count,
begin_callback=begin_callback,
end_callback=end_callback,
delete_keys=delete_keys,
keep_alive=keep_alive,
auto_start_requests=auto_start_requests,
batch_interval=batch_interval,
wait_lock=wait_lock,
**kwargs
)self._min_task_count = min_task_count
self._check_task_interval = check_task_intervalself._is_distributed_task = False
self._is_show_not_task = False
数据自动入库
除了导入MysqlDB这种方式外,Spider支持数据自动批量入库。我们需要将数据封装为一个item,然后返回给框架即可。步骤如下:
创建item,命令参考命令行工具。这里我们创建了个SpiderDataItem, 生成的代码如下:
from feapder import Item
class SpiderDataItem(Item):
"""
This class was generated by feapder.
command: feapder create -i spider_data.
"""
def __init__(self, *args, **kwargs):
# self.id = None # type : int(10) unsigned | allow_null : NO | key : PRI | default_value : None | extra : auto_increment | column_comment :
self.title = None # type : varchar(255) | allow_null : YES | key : | default_value : None | extra : | column_comment :
给item赋值,然后yield返回即可,代码示例:

返回item后,item会流经到框架的ItemBuffer, ItemBuffer每.05秒或当item数量积攒到5000个,便会批量将这些item批量入库。表名为类名去掉Item的小写,如SpiderDataItem数据会落入到spider_data表。
Item详细介绍参考Item
调试
开发过程中,我们可能需要针对某个请求进行调试,常规的做法是修改下发任务的代码。但这样并不好,改来改去可能把之前写好的逻辑搞乱了,或者忘记改回来直接发布了,又或者调试的数据入库了,污染了库里已有的数据,造成了很多本来不应该发生的问题。
本框架支持 Debug 爬虫,可针对某条任务进行调试,写法如下:
if __name__ == "__main__":
spider = SpiderTest.to_DebugSpider(
redis_key="feapder:spider_test",
request=feapder.Request("http://www.baidu.com")
)
spider.start()对比下之前的启动方式
spider = SpiderTest(redis_key="feapder:spider_test")
spider.start()
可以看到,代码中 to_DebugSpider方法可以将原爬虫直接转为debug爬虫,然后通过传递request参数抓取指定的任务。
通常结合断点来进行调试,debug模式下,运行产生的数据默认不入库
除了指定request参数外,还可以指定request_dict参数,request_dict接收字典类型,如request_dict={"url":"http://www.baidu.com"}, 其作用于传递request一致。request 与 request_dict 二者选一传递即可
运行多个Spider
通常,一个项目下可能存在多个爬虫,为了规范,建议启动入口统一放到项目下的main.py中,然后以命令行的方式运行指定的文件。
例如如下项目:

项目中包含了两个spider,main.py写法如下:
from spiders import *
from feapder import Request
from feapder import ArgumentParser
def test_spider():
spider = test_spider.TestSpider(redis_key="feapder:test_spider")
spider.start()
def test_spider2():
spider = test_spider.TestSpider2(redis_key="feapder:test_spider2")
spider.start()
def test_debug_spider():
# debug爬虫
spider = test_spider.TestSpider.to_DebugSpider(
redis_key="feapder:test_spider", request=Request("http://www.baidu.com")
)
spider.start()
if __name__ == "__main__":
parser = ArgumentParser(description="Spider测试")
parser.add_argument(
"--test_spider", action="store_true", help="测试Spider", function=test_spider
)
parser.add_argument(
"--test_spider2", action="store_true", help="测试Spider2", function=test_spider2
)
parser.add_argument(
"--test_debug_spider",
action="store_true",
help="测试DebugSpider",
function=test_debug_spider,
)
parser.start()
这里使用了ArgumentParser模块,使其支持命令行参数,如运行test_spider
执行:python3 main.py --test_spider
示例:分布式爬虫
:https://github.com/Boris-code/feapder/tree/master/tests/spider
示例:抓取 美女校花
注意:二次运行时卡住,不继续抓取。因爬虫支持分布式和任务防丢,为防止任务抢占和任务丢失,巧妙的利用了redis有序集合来存储任务。
策略:有序集合有个分数,爬虫取任务时,只取小于当前时间戳分数的任务,同时将任务分数修改为当前时间戳+10分钟,当任务做完时,再主动将任务删除。
目的:将取到的任务分数修改成10分钟后,可防止其他爬虫节点取到同样的任务,同时当爬虫意外退出后,任务也不会丢失,10分钟后还可以取到。但也会导致有时爬虫启动时,明明有任务,却处于等待任务的情况。
- 解决方法 1:可将任务清空,重新抓取,可直接操作redis清空,或通过传参方式
- 解决方法 2:手动修改任务分数为小于当前时间戳的分数
代码
# -*- coding: utf-8 -*-
import feapder
import pathlib
import copy
class ExampleSpider(feapder.Spider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
__custom_setting__ = dict(
REDISDB_IP_PORTS="127.0.0.1:6379", REDISDB_USER_PASS="", REDISDB_DB=0
)
def start_requests(self):
yield feapder.Request(f"https://www.uu44.me/xiaohua/")
yield feapder.Request(f"https://www.uu44.me/xiaohua/p2.html")
yield feapder.Request(f"https://www.uu44.me/xiaohua/p3.html")
def parse(self, request, response):
response.code = "GB18030"
# 提取网站title
print(response.xpath("//title/text()").extract_first())
# 提取网站描述
# print(response.xpath("//meta[@name='description']/@content").extract_first())
print("网站地址: ", response.url)
tag_a_href_list = response.xpath('//ul[@id="pins"]//li//span[1]/a/@href').extract()
tag_a_text_list = response.xpath('//ul[@id="pins"]//li//span[1]/a/text()').extract()
tuple_list = list(zip(tag_a_text_list, tag_a_href_list))
# list(map(lambda x=None: print(x), tuple_list))
for info in tuple_list:
a_text, a_href = info
yield feapder.Request(url=a_href, xxx_info=dict(info=info), callback=self.parse_home_page)
def parse_home_page(self, request, response):
xxx_info = request.xxx_info
image_url_list = response.xpath('//div[@class="main-image"]//img/@src').extract()
for image_url in image_url_list:
temp_dict = copy.deepcopy(xxx_info)
temp_dict['image_url'] = image_url
yield feapder.Request(url=image_url, callback=self.download_image, xxx_info=temp_dict)
pass
def download_image(self, request, response):
image_url = request.url
xxx_info = request.xxx_info
dir_name = xxx_info['info'][0]
file_name = image_url.split('/')[-1].split('.')[0]
if not pathlib.Path(f'./{dir_name}').exists():
pathlib.Path(f'./{dir_name}').mkdir()
with open(f'./{dir_name}/{file_name}.jpg', 'wb') as f:
f.write(response.content)
pass
if __name__ == "__main__":
ExampleSpider(redis_key="example_spider", thread_count=10).start()
运行结果截图:( 程序只抓取了每个人主页的第一页,没有进行翻页抓取 )

分布式爬虫:TaskSpider (任务爬虫)
TaskSpider是一款分布式爬虫,内部封装了取种子任务的逻辑,内置支持从 redis 或者 mysql 获取任务,也可通过自定义实现从其他来源获取任务
创建项目
参考 Spider
创建爬虫
feapder create -s task_spider_test
请选择爬虫模板
AirSpider
Spider
> TaskSpider
BatchSpider
示例代码:
import feapder
from feapder import ArgumentParser
class TaskSpiderTest(feapder.TaskSpider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
# redis 必须,mysql可选
__custom_setting__ = dict(
REDISDB_IP_PORTS="localhost:6379",
REDISDB_USER_PASS="",
REDISDB_DB=0,
MYSQL_IP="localhost",
MYSQL_PORT=3306,
MYSQL_DB="feapder",
MYSQL_USER_NAME="feapder",
MYSQL_USER_PASS="feapder123",
)
def add_task(self):
# 加种子任务 框架会调用这个函数,方便往redis里塞任务,但不能写成死循环。实际业务中可以自己写个脚本往redis里塞任务
self._redisdb.zadd(self._task_table, {"id": 1, "url": "https://www.baidu.com"})
def start_requests(self, task):
task_id, url = task
yield feapder.Request(url, task_id=task_id)
def parse(self, request, response):
# 提取网站title
print(response.xpath("//title/text()").extract_first())
# 提取网站描述
print(response.xpath("//meta[@name='description']/@content").extract_first())
print("网站地址: ", response.url)
# mysql 需要更新任务状态为做完 即 state=1
# yield self.update_task_batch(request.task_id)
def start(args):
"""
用mysql做种子表
"""
spider = TaskSpiderTest(
task_table="spider_task", # 任务表名
task_keys=["id", "url"], # 表里查询的字段
redis_key="test:task_spider", # redis里做任务队列的key
keep_alive=True, # 是否常驻
)
if args == 1:
spider.start_monitor_task()
else:
spider.start()
def start2(args):
"""
用redis做种子表
"""
spider = TaskSpiderTest(
task_table="spider_task2", # 任务表名
task_table_type="redis", # 任务表类型为redis
redis_key="test:task_spider", # redis里做任务队列的key
keep_alive=True, # 是否常驻
use_mysql=False, # 若用不到mysql,可以不使用
)
if args == 1:
spider.start_monitor_task()
else:
spider.start()
if __name__ == "__main__":
parser = ArgumentParser(description="测试TaskSpider")
parser.add_argument("--start", type=int, nargs=1, help="用mysql做种子表 (1|2)", function=start)
parser.add_argument("--start2", type=int, nargs=1, help="用redis做种子表 (1|2)", function=start2)
parser.start()
# 下发任务 python3 task_spider_test.py --start 1
# 采集 python3 task_spider_test.py --start 2
main 函数为命令行参数解析,分别定义了两种获取任务的方式。
- start 函数为从 mysql 里获取任务,前提是需要有任务表。
- start2 函数为从 redis 里获取任务,指定了根任务的 key 为 spider_task2,key 的类型为 zset
启动:TaskSpider 分为 master 及 work 两种程序
- master 负责下发任务,监控批次进度,创建批次等功能:spider.start_monitor_task()
- worker 负责消费任务,抓取数据:spider.start()
TaskSpider 相关参数
"""
@summary: 调度器
---------
@param redis_key: 爬虫 request 及 item 存放 redis 中的文件夹。( 即 key 前缀 )
@param thread_count: 线程数,默认为配置文件中的线程数
@param begin_callback: 爬虫开始回调函数
@param end_callback: 爬虫结束回调函数
@param delete_keys: 爬虫启动时删除的key,类型: 元组/bool/string。 支持正则
@param keep_alive: 爬虫是否常驻,默认否
@param auto_start_requests: 爬虫是否自动添加任务
@param batch_interval: 抓取时间间隔 默认为0 天为单位 多次启动时,只有当前时间与第一次抓取结束的时间间隔大于指定的时间间隔时,爬虫才启动
@param wait_lock: 下发任务时否等待锁,若不等待锁,可能会存在多进程同时在下发一样的任务,因此分布式环境下请将该值设置True
@param task_table: 任务表, 批次爬虫传递
---------
@result:
"""
add_task:
框架内置的函数,在调用 start_monitor_task 时会自动调度此函数,用于初始化任务种子,若不需要,可直接删除此函数。上面示例是向 redis 的 spider_task2 的 key 加了个值为 {"id": 1, "url": "https://www.baidu.com"} 的种子
示例:抓取 美女 图片
添加任务。这里通过爬虫加添任务。
# -*- coding: utf-8 -*-
import feapder
import pathlib
from feapder.db.redisdb import RedisDB
class ExampleSpider(feapder.Spider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
__custom_setting__ = dict(
REDISDB_IP_PORTS="127.0.0.1:6379", REDISDB_USER_PASS="", REDISDB_DB=0
)
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.redis_db = RedisDB()
pass
def start_requests(self):
yield feapder.Request(f"https://www.toopic.cn/dnbz/?q=-23-65---.html&px=hot")
def parse(self, request, response):
image_title_list = response.xpath('//div[@class="bd"]/a/img/@title').extract()
image_url_list = response.xpath('//div[@class="bd"]/a/@href').extract()
tuple_list = list(zip(image_title_list, image_url_list))
# list(map(lambda x=None: print(x), tuple_list))
task_list = []
for tuple_info in tuple_list:
image_title, image_url = tuple_info
task_dict = {
'url': image_url,
'image_title': image_title,
}
task_list.append(task_dict)
# ###################################################################
# self.redis_db.zadd(table='spider_test:z_requests', values=task_list)
# 向 redis 中 key 是 spider_task2 的队列中添加任务
self.redis_db.zadd(table='spider_task2', values=task_list)
# ###################################################################
next_page = response.xpath('//div[@class="page"]//a[contains(text(), "下一页")]/@href').extract_first()
if next_page:
print(f'next_page ---> {next_page}')
yield feapder.Request(url=next_page, callback=self.parse)
if __name__ == "__main__":
ExampleSpider(redis_key="example_spider", thread_count=10).start()redis 里面任务:

创建 TaskSpider
import feapder
import pathlib
from feapder import ArgumentParser
class TaskSpiderTest(feapder.TaskSpider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
# redis 必须,mysql可选
__custom_setting__ = dict(
REDISDB_IP_PORTS="127.0.0.1:6379",
REDISDB_USER_PASS="",
REDISDB_DB=0,
# MYSQL_IP="127.0.0.1",
# MYSQL_PORT=3306,
# MYSQL_DB="feapder",
# MYSQL_USER_NAME="feapder",
# MYSQL_USER_PASS="feapder123",
)
# def add_task(self):
# # 加种子任务 框架会调用这个函数,方便往redis里塞任务,但不能写成死循环。实际业务中可以自己写个脚本往redis里塞任务
# self._redisdb.zadd(self._task_table, {"id": 1, "url": "https://www.gushiwen.cn/"})
# self._redisdb.zadd(self._task_table, {"id": 2, "url": "https://www.gushiwen.cn/"})
# self._redisdb.zadd(self._task_table, {"id": 3, "url": "https://www.gushiwen.cn/"})
def start_requests(self, task):
"""
master
1. 如果有 self.add_task 函数,start_monitor_task 会自动调用
2. 如果没有 self.add_task 函数,
则 start_monitor_task 会自动 从 task_table 表里面取任务
然后再调用 self.start_requests 把 yield 的 Request 放到 redis_key 中
3.
"""
"""
worker
"""
url = task['url']
yield feapder.Request(url, task_dict=task)
def parse(self, request, response):
task_dict = request.task_dict
web_title = response.xpath("//title/text()").extract_first()
web_description = response.xpath("//meta[@name='description']/@content").extract_first()
web_url = response.url
image_url = response.xpath('//td//img/@src').extract_first()
print(f'image_url ---> {image_url}')
yield feapder.Request(url=image_url, callback=self.download_image, task_dict=task_dict)
# mysql 需要更新任务状态为做完 即 state=1
# yield self.update_task_batch(request.task_id)
pass
def download_image(self, request, response):
image_url = response.url
task_dict = request.task_dict
image_title = task_dict['image_title']
dir_name = image_title
file_name = image_url.split('/')[-1].split('.')[0]
if not pathlib.Path(f'./{dir_name}').exists():
pathlib.Path(f'./{dir_name}').mkdir()
with open(f'./{dir_name}/{file_name}.jpg', 'wb') as f:
f.write(response.content)
pass
def start_func(args):
"""
用redis做种子表
"""
spider = TaskSpiderTest(
task_table="spider_task2", # 任务表名( master 用来加任务用)
task_table_type="redis", # 任务表类型为redis
redis_key="spider_test", # redis里做任务队列的 key 前缀
keep_alive=True, # 是否常驻
use_mysql=False, # 若用不到 mysql,可以不使用
thread_count=10
)
if args == 1:
spider.start_monitor_task()
else:
spider.start()
if __name__ == "__main__":
# start_func(args=1)
start_func(args=2)
passTaskSpider 分两部分:
- master 用来从任务队列中读取任务,并封装成 feapder.Request 再次放到 redis_key 的队列中。如下,执行 start_func(arg=1),执行完后可以停掉,也可以不用停。( 注意:这里会有 mysql 链接报错,不用管,因为不使用 mysql 。 )
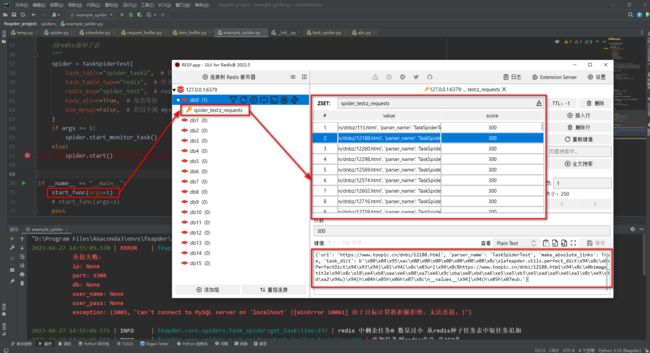
- worker 从 redis_key 读取 封装的 feapder.Request 开始请求并下载 web。
这里执行 start_func(args=2) 函数。

分布式爬虫:BatchSpider (批次爬虫)
BatchSpider 是一款分布式批次爬虫,对于需要周期性采集的数据,优先考虑使用本爬虫。
BatchSpider 和 TaskSpider 区别:
- TaskSpider:如果加上 crontab 定时添加任务,其实就相当于 BatchSpider。
- BatchSpider:自带定时任务,不需要手动管理,定时任务是从 mysql 中读取并添加。
创建项目
参考 Spider
创建爬虫
命令参考:命令行工具
示例:
feapder create -s batch_spider_test
请选择爬虫模板
AirSpider
Spider
TaskSpider
> BatchSpider
生成如下
import feapder
class BatchSpiderTest(feapder.BatchSpider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
__custom_setting__ = dict(
REDISDB_IP_PORTS="localhost:6379",
REDISDB_USER_PASS="",
REDISDB_DB=0,
MYSQL_IP="localhost",
MYSQL_PORT=3306,
MYSQL_DB="feapder",
MYSQL_USER_NAME="feapder",
MYSQL_USER_PASS="feapder123",
)
def start_requests(self, task):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
spider = BatchSpiderTest(
redis_key="xxx:xxxx", # 分布式爬虫调度信息存储位置
task_table="", # mysql中的任务表
task_keys=["id", "xxx"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
batch_record_table="xxx_batch_record", # mysql中的批次记录表
batch_name="xxx(周全)", # 批次名字
batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24
)
# spider.start_monitor_task() # 下发及监控任务
spider.start() # 采集
因BatchSpider是基于redis做的分布式,mysql来维护任务种子及批次信息,因此模板代码默认给了redis及mysql的配置方式,连接信息需按真实情况修改
配置信息:
- REDISDB_IP_PORTS: 连接地址,若为集群或哨兵模式,多个连接地址用逗号分开,若为哨兵模式,需要加个REDISDB_SERVICE_NAME参数
- REDISDB_USER_PASS: 连接密码
- REDISDB_DB:数据库
BatchSpider参数:
- redis_key:redis中存储任务等信息的key前缀,如redis_key="feapder:spider_test", 则redis中会生成如下
-
task_table:mysql中的任务表,为抓取的任务种子,需要运行前手动创建好
-
task_keys:任务表里需要获取的字段,框架会将这些字段的数据查询出来,传递给爬虫,然后拼接请求
-
task_state:任务表里表示任务完成状态的字段,默认是state。字段为整形,有4种状态(0 待抓取,1抓取完毕,2抓取中,-1抓取失败)
-
batch_record_table:批次信息表,用于记录批次信息,由爬虫自动创建
-
batch_name: 批次名称,可以理解成爬虫的名字,用于报警等
-
batch_interval:批次周期 天为单位 若为小时 可写 1 / 24
启动:BatchSpider 分为 master 及 work 两种程序
- master负责下发任务,监控批次进度,创建批次等功能,启动方式:spider.start_monitor_task()
- worker负责消费任务,抓取数据,启动方式:spider.start()
更详细的说明可查看 BatchSpider进阶
任务表
任务表为存储任务种子的,表结构需要包含id、任务状态两个字段,如我们需要对某些地址进行采集,设计如下

建表语句:
CREATE TABLE `batch_spider_task` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`url` varchar(255) DEFAULT NULL,
`state` int(11) DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
也许有人会问,为什么要弄个任务表,直接把种子任务写到代码里不行么。答:可以的,可以用AirSpider或Spider这么搞。BatchSpider面向的场景是周期性抓取,如我们有1亿个商品需要更新,不可能把这1亿个商品id都写代码里,还是需要存储到一张表里,这个表即为任务表。
为了保证每个商品都得以更新,需要引入抓取状态字段,本例为state字段。state字段有4种状态(0 待抓取,1抓取完毕,2抓取中,-1抓取失败)。框架下发任务时,会优先分批下发状态为0的任务到redis任务队列,并将这些已下发的任务状态更新为2,当0都下发完毕且redis任务队列中无任务,这时框架会检查任务表里是否还有状态为2的任务,若有则将这些任务视为丢失的任务,然后将这些状态为2的任务置为0,再次分批下发到redis任务队列。直到任务表里任务状态只有1和-1两种状态,才算采集完毕
1 和 -1 两种状态是开发人员在代码里自己维护的。当任务做完时将任务状态更新为1,当任务无效时,将任务状态更新为-1。更新方法见更新任务状态
注意:每个批次开始时,框架默认会重置状态非-1的任务为0,然后重新抓取。-1的任务永远不会抓取
拼接任务
def start_requests(self, task):
pass
任务拼接在start_requests里处理。这里的task参数为BatchSpider启动参数中指定的task_keys对应的值
如表batch_spider_task,现有任务信息如下:

启动参数配置如下,注意task_keys=["id", "url"]:
def crawl_test(args):
spider = test_spider.TestSpider(
redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置
task_table="batch_spider_task", # mysql中的任务表
task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
batch_record_table="batch_spider_batch_record", # mysql中的批次记录表
batch_name="批次爬虫测试(周全)", # 批次名字
batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24
)
if args == 1:
spider.start_monitor_task() # 下发及监控任务
else:
spider.start() # 采集
这时,start_requests的task参数值即为任务表里id与url对应的值。
def start_requests(self, task):
# task 为在任务表中取出的每一条任务
id, url = task # id, url为所取的字段,main函数中指定的
yield feapder.Request(url, task_id=id)
task值的获取方式,支持以下几种:
# 列表方式
id, url = task
id = task[0]
url = task[1]
# 字典方式
id, url = task.id, task.url
id, url = task.get("id"), task.get("url")
id, url = task["id"], task["url"]
更新任务状态
任务的完成状态与失败状态需要自己维护,为了更新这个状态,我们需要在请求中携带任务id,常规写法为
yield feapder.Request(url, task_id=id)
当任务解析完毕后,可使用如下方法更新
yield self.update_task_batch(request.task_id, 1) # 更新任务状态为1
这个更新不是实时的,也会先流经ItemBuffer,然后在数据入库后批量更新
处理无效任务
有些任务,可能就是有问题的,我们需要将其更新为-1,防止爬虫一直重试。除了在解析函数中判断当前任务是否有效外,框架还提供了两个函数
def exception_request(self, request, response):
"""
@summary: 请求或者parser里解析出异常的request
---------
@param request:
@param response:
---------
@result: request / callback / None (返回值必须可迭代)
"""
pass
def failed_request(self, request, response):
"""
@summary: 超过最大重试次数的request
---------
@param request:
---------
@result: request / item / callback / None (返回值必须可迭代)
"""
pass
exception_request:处理请求失败或解析出异常的request,我们可以在这里切换request的cookie等,然后再yield request返回处理后的request
failed_request:处理超过最大重试次数的request。我们可以在这里将任务状态更新为-1
def failed_request(self, request, response):
"""
@summary: 超过最大重试次数的request
---------
@param request:
---------
@result: request / item / callback / None (返回值必须可迭代)
"""
yield request
yield self.update_task_batch(request.task_id, -1) # 更新任务状态为-1
超过最大重试次数的request会保存到redis里,key名以z_failed_requsets结尾。我们可以查看这个表里的失败任务,观察失败原因,以此来调整爬虫
增量采集
每个批次开始时,框架默认会重置状态非-1的任务为0,然后重新抓取。但是有些需求是增量采集的,做过的任务无需再次处理。重置任务是init_task方法实现的,我们可以将init_task方法置空来实现增量采集
def init_task(self):
pass
调试
与Spider调试类似。BatchSpider可以通过to_DebugBatchSpider转为调试爬虫,写法如下:
def test_debug():
spider = test_spider.TestSpider.to_DebugBatchSpider(
task_id=1,
redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置
task_table="batch_spider_task", # mysql中的任务表
task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
batch_record_table="batch_spider_batch_record", # mysql中的批次记录表
batch_name="批次爬虫测试(周全)", # 批次名字
batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24
)
spider.start() # 采集
DebugBatchSpider爬虫支持传递task_id或直接传递task来指定任务。还支持其他参数,全部参数如下:
@param task_id: 任务id
@param task: 任务 task 与 task_id 二者选一即可
@param save_to_db: 数据是否入库 默认否
@param update_stask: 是否更新任务 默认否
运行 BatchSpider
与Spider运行方式类似。但因每个爬虫都有maser和work两个入口,因此框架提供一种更方便的方式,写法如下
from spiders import *
from feapder import ArgumentParser
def crawl_test(args):
spider = test_spider.TestSpider(
redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置
task_table="batch_spider_task", # mysql中的任务表
task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
batch_record_table="batch_spider_batch_record", # mysql中的批次记录表
batch_name="批次爬虫测试(周全)", # 批次名字
batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24
)
if args == 1:
spider.start_monitor_task() # 下发及监控任务
else:
spider.start() # 采集
if __name__ == "__main__":
parser = ArgumentParser(description="批次爬虫测试")
parser.add_argument(
"--crawl_test", type=int, nargs=1, help="BatchSpider demo(1|2)", function=crawl_test
)
parser.start()
运行master:python3 main.py --crawl_test 1
运行worker:python3 main.py --crawl_test 2
crawl_test的args参数会接收1或2两个参数,以此来运行不同的程序
完整的代码示例
:https://github.com/Boris-code/feapder/tree/master/tests/batch-spider
3、爬虫集成
本功能可以将多个爬虫以插件的形式集成为一个爬虫,常用于采集周期一致,需求一致的,但需要采集多个数据源的项目
使用场景举例
如我们需要做舆情数据,需要采集多个新闻网站,如何开发爬虫呢?
常规做法
每个新闻源写一个或多个爬虫,如下:
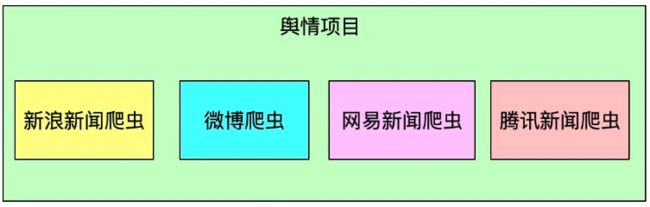
这样每个爬虫之间比较独立,如果有上百个数据源,需要启动上百个爬虫脚本,不便于管理
feapder 框架做法
feapder 框架支持上述的常规做法同时,支持了更友好的管理方式,可将这些爬虫集成为一个爬虫,我们只需维护这一个爬虫即可,当然也支持分布式。
注: Spider爬虫与BatchSpider爬虫支持集成,AirSpider不支持

Spider 集成
支持分布式采集,以采集新浪和腾讯新闻为例
编写 解析器
新浪解析器
import feapder
class SinaNewsParser(feapder.BaseParser):
def start_requests(self):
"""
注意 这里继承的是BaseParser,而不是Spider
"""
yield feapder.Request("https://news.sina.com.cn/")
def parse(self, request, response):
title = response.xpath("//title/text()").extract_first()
print(title)
腾讯解析器
import feapder
class TencentNewsParser(feapder.BaseParser):
"""
注意 这里继承的是BaseParser,而不是Spider
"""
def start_requests(self):
yield feapder.Request("https://news.qq.com/")
def parse(self, request, response):
title = response.xpath("//title/text()").extract_first()
print(title)
注意:之前的爬虫都是继承自
Spider,这里因为要集成,所以要继承BaseParser
BaseParser只是一个解析器,不具备任何调度功能,我们写好每个网站的解析器,然后集成到爬虫中,由这个爬虫调度这些解析器去解析对应的网站
BaseParser所支持的函数与Spider一致,因此集成时爬虫代码无需更改,只需要将继承类改为BaseParser即可
集成 解析器
from feapder import Spider
spider = Spider(redis_key="feapder:test_spider_integration")
# 集成
spider.add_parser(SinaNewsParser)
spider.add_parser(TencentNewsParser)
spider.start()
add_parser方法可以集成解析器,只需要将每个解析器的类名传进来即可
完整代码示例:Spider集成
示例:
添加任务:
import feapder
custom_setting = dict(
REDISDB_IP_PORTS="127.0.0.1:6379",
REDISDB_USER_PASS="",
REDISDB_DB=0
)
redis_key = "feapder:test_spider_integration"
class SinaNewsParser(feapder.Spider):
__custom_setting__ = custom_setting
def start_requests(self):
"""
注意 这里继承的是BaseParser,而不是Spider
"""
yield feapder.Request("https://news.sina.com.cn/")
pass
def parse(self, request, response):
title = response.xpath("//title/text()").extract_first()
print(title)
yield feapder.Request("https://news.sina.com.cn/")
class TencentNewsParser(feapder.Spider):
__custom_setting__ = custom_setting
def start_requests(self):
yield feapder.Request("https://news.qq.com/")
def parse(self, request, response):
title = response.xpath("//title/text()").extract_first()
print(title)
yield feapder.Request("https://news.qq.com/")
def main_1():
obj_test = SinaNewsParser(redis_key=redis_key)
obj_test.start()
def main_2():
obj_test = TencentNewsParser(redis_key=redis_key)
obj_test.start()
if __name__ == '__main__':
# main_1()
main_2(){'url': 'https://news.sina.com.cn/', 'parser_name': 'SinaNewsParser', 'make_absolute_links': True}
{'url': 'https://news.qq.com/', 'parser_name': 'TencentNewsParser', 'make_absolute_links': True}

集成。这里为了演示,新浪、腾讯 两个 类都放到 一个 py 文件里面
import feapder
from feapder import Spider
class TencentNewsParser(feapder.BaseParser):
"""
注意 这里继承的是BaseParser,而不是Spider
"""
def start_requests(self):
yield feapder.Request("https://news.qq.com/")
def parse(self, request, response):
title = response.xpath("//title/text()").extract_first()
print(f'腾讯 ---> {title}')
class SinaNewsParser(feapder.BaseParser):
def start_requests(self):
"""
注意 这里继承的是BaseParser,而不是Spider
"""
yield feapder.Request("https://news.sina.com.cn/")
def parse(self, request, response):
title = response.xpath("//title/text()").extract_first()
print(f'新浪 ---> {title}')
spider = Spider(redis_key="feapder:test_spider_integration")
# 集成
spider.add_parser(SinaNewsParser)
spider.add_parser(TencentNewsParser)
spider.start()setting.py 中配置 redis 连接

运行结果截图:

可以看到,分别调用了两个 类 里面的 parse 函数
BatchSpider 集成
支持批次采集、支持分布式,以采集新浪和腾讯新闻为例
编写 解析器
新浪解析器
import feapder
class SinaNewsParser(feapder.BatchParser):
"""
注意 这里继承的是BatchParser,而不是BatchSpider
"""
def start_requests(self, task):
task_id = task[0]
url = task[1]
yield feapder.Request(url, task_id=task_id)
def parse(self, request, response):
title = response.xpath("//title/text()").extract_first()
print(self.name, title)
yield self.update_task_batch(request.task_id, 1)
腾讯解析器
import feapder
class TencentNewsParser(feapder.BatchParser):
"""
注意 这里继承的是BatchParser,而不是BatchSpider
"""
def start_requests(self, task):
task_id = task[0]
url = task[1]
yield feapder.Request(url, task_id=task_id)
def parse(self, request, response):
title = response.xpath("//title/text()").extract_first()
print(self.name, title)
yield self.update_task_batch(request.task_id, 1)
注意:之前我们爬虫继承的是BatchSpider,这里因为要集成,所以要继承BatchParser
BatchParser只是一个解析器,不具备任何调度功能,我们写好每个网站的解析器,然后集成到爬虫中,由这个爬虫调度这些解析器去解析对应的网站
BatchParser 所支持的常用函数与BatchSpider一致,但BatchParser不支持任务初始化函数init_task。任务初始化为BatchSpider的每个批次开始时的逻辑,所有批次解析器共用一个init_task
集成 解析器
from feapder import BatchSpider
def batch_spider_integration_test(args):
"""
BatchSpider集成测试
"""
spider = BatchSpider(
task_table="batch_spider_integration_task", # mysql中的任务表
batch_record_table="batch_spider_integration_batch_record", # mysql中的批次记录表
batch_name="批次爬虫集成测试", # 批次名字
batch_interval=7, # 批次时间 天为单位 若为小时 可写 1 / 24
task_keys=["id", "url", "parser_name"], # 集成批次爬虫,需要将批次爬虫的名字取出来,任务分发时才知道分发到哪个模板上
redis_key="feapder:test_batch_spider_integration", # redis中存放request等信息的根key
task_state="state", # mysql中任务状态字段
)
# 集成
spider.add_parser(SinaNewsParser)
spider.add_parser(TencentNewsParser)
if args == 1:
spider.start_monitor_task()
elif args == 2:
spider.start()
任务表:

任务表里需要有一个字段存储解析器的类名,与对应的任务关联,在我们取任务时携带这个类名,这样框架才知道这条任务归属于哪个解析器
这里存储解析器名字的字段为parser_name
示例
完整代码示例:批次爬虫集成
4、使用进阶
- 请求-Request
- 响应-Response
- 代理使用说明
- 用户池说明
- 浏览器渲染-Selenium
- 浏览器渲染-Playwright
- 解析器-BaseParser
- 批次解析器-BatchParser
- Spider进阶
- BatchSpider进阶
- 配置文件
- Item
- UpdateItem
- 数据管道-pipeline
- MysqlDB
- MongoDB
- RedisDB
- 工具库-tools
- 日志配置及使用
- 海量数据去重-dedup
- 报警及监控
- 监控打点
请求-Request
响应-Response
代理使用说明
用户池说明
浏览器渲染-Selenium
浏览器渲染-Playwright
解析器-BaseParser
批次解析器-BatchParser
Spider进阶
BatchSpider进阶
配置文件
Item
UpdateItem
数据管道-pipeline
MysqlDB
MongoDB
RedisDB
工具库-tools
日志配置及使用
海量数据去重-dedup
报警及监控
监控打点
5、爬虫管理系统
功能概览
feaplat 命名源于 feapder 与 platform 的缩写。读音: [ˈfiːplæt]

特性
- 支持部署任何程序,包括不限于
feapder、scrapy - 支持集群管理,部署分布式爬虫可一键扩展进程数
- 支持部署服务,且可自动实现服务负载均衡
- 支持程序异常报警、重启、保活
- 支持监控,监控内容可自定义
- 支持4种定时调度模式
- 自动从git仓库拉取最新的代码运行,支持指定分支
- 支持多人协同
- 支持浏览器渲染,支持有头模式。浏览器支持
playwright、selenium - 支持弹性伸缩
- 支持自定义worker镜像,如自定义java的运行环境、node运行环境等,即根据自己的需求自定义(feaplat分为
master-调度端和worker-运行任务端) - docker一键部署,架设在docker swarm集群上
项目管理
添加/编辑项目

- 支持 git和zip两种方式上传项目
- 根据requirements.txt自动安装依赖包
- 可选择多个人参与项目
任务管理


- 支持一键启动多个任务实例(分布式爬虫场景或者需要启动多个进程的场景)
- 支持4种调度模式
- 标签:给任务分类使用
- 强制运行:(上一次任务没结束,本次是否运行,是则会停止上一次任务,然后运行本次调度)
- 异常重启:当部署的程序异常退出,是否自动重启,且会报警

- 支持限制程序运行的CPU、内存等。
任务实例
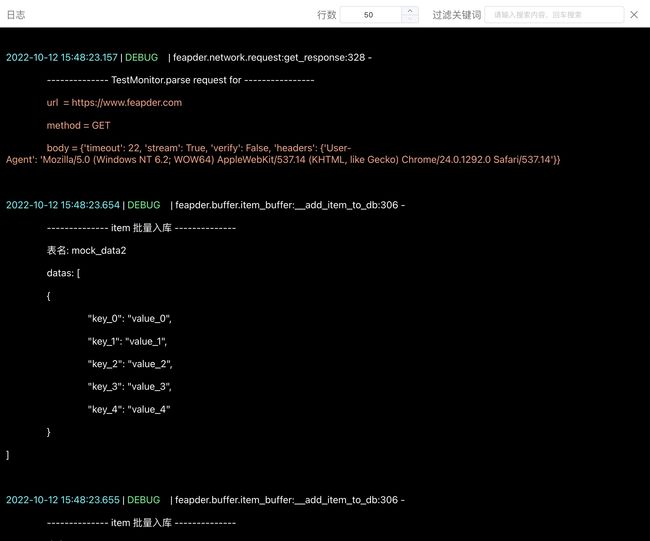
一键部署了20份程序,每个程序独占一个进程,可从列表看每个进程部署到哪台服务器上了,运行状态是什么
实时查看日志
爬虫监控
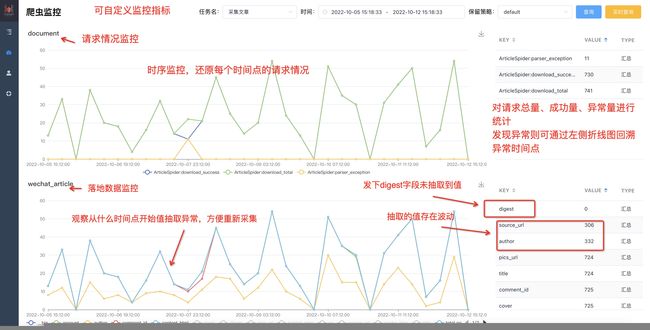
feaplat支持对feapder爬虫的运行情况进行监控,除了数据监控和请求监控外,用户还可自定义监控内容,详情参考自定义监控
若scrapy爬虫或其他python脚本使用监控功能,也可通过自定义监控的功能来支持,详情参考自定义监控
报警
调度异常、程序异常自动报警 支持钉钉、企业微信、飞书、邮箱

部署
:https://feapder.com/#/feapder_platform/feaplat
下面部署以centos为例, 其他平台docker安装方式可参考docker官方文档:Overview | Docker Documentation