CentOS7系统下Docker容器基于TensorFlow测试GPU
前言
TensorFlow 在新款 NVIDIA Pascal GPU 上的运行速度可提升高达 50%,并且能够顺利跨 GPU 进行扩展。 如今,您训练模型的时间可以从几天缩短到几小时。
TensorFlow 使用优化的 C++ 和 NVIDIA® CUDA® 工具包编写,使模型能够在训练和推理时在 GPU 上运行,从而大幅提速。
TensorFlow GPU 支持需要多个驱动和库。为简化安装并避免库冲突,建议利用 GPU 支持的 TensorFlow Docker 镜像。此设置仅需要 NVIDIA GPU 驱动并且安装 NVIDIA Docker。用户可以从预配置了预训练模型和 TensorFlow 库支持的 NGC (NVIDIA GPU Cloud) 中提取容器。
当基于nvidia gpu开发的docker镜像在实际部署时,需要先安装nvidia docker。安装nvidia docker前需要先安装原生docker compose
1. CentOS7安装docker详细教程
安装docker
1. Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的CentOS 版本是否支持 Docker 。
通过 uname -r 命令查看你当前的内核版本
uname -r
2. 使用 root 权限登录 Centos 确保 yum 包更新到最新
sudo yum update
3. 卸载旧版本(如果安装过旧版本的话)
yum remove docker
docker-client
docker-client-latest
docker-common
docker-latest
docker-latest-logrotate
docker-logrotate
docker-selinux
docker-engine-selinux
docker-engine
4. 安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的
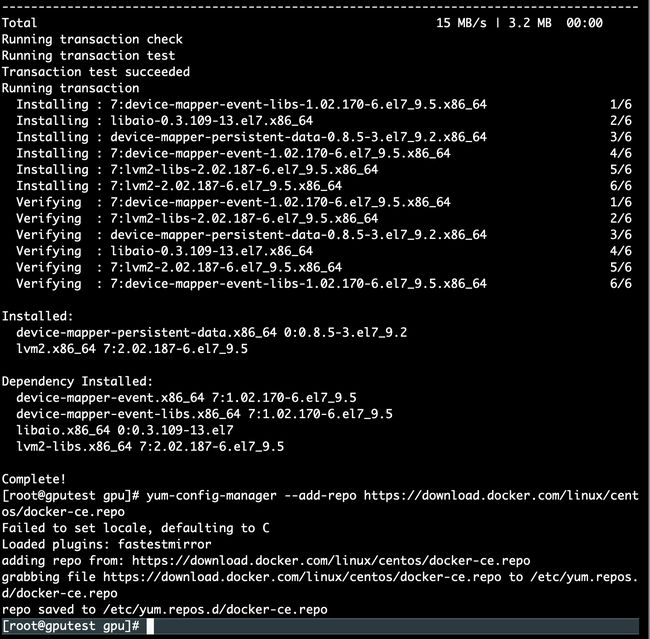
yum install -y yum-utils device-mapper-persistent-data lvm2
5. 设置yum源
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
6. 可以查看所有仓库中所有docker版本,并选择特定版本安装
yum list docker-ce --showduplicates | sort -r
7. 安装docker,版本号自选
yum install docker-ce-17.12.0.ce
8. 启动并加入开机启动
systemctl start docker
systemctl status docker
systemctl enable docker
9. 验证安装是否成功(有client和service两部分表示docker安装启动都成功了)
docker version

2. CentOS7安装Docker Compose
1. 卸载旧版本Docker Compose
如果之前安装过Docker Compose的旧版本,可以先卸载它们:
sudo rm /usr/local/bin/docker-compose
2. 下载Docker Compose最新版
从Docker官方网站下载Docker Compose最新版本的二进制文件:
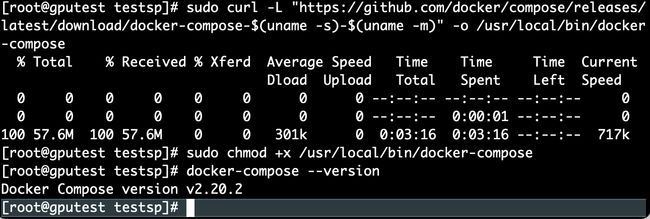
sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
3. 授权Docker Compose二进制文
授予Docker Compose二进制文件执行权限
sudo chmod +x /usr/local/bin/docker-compose
4. 检查Docker Compose版本
docker-compose --version
安装版本为
Docker Compose version v2.20.2
3. CentOS7安装NVIDIA-Docker

依赖条件
如果使用的 Tensorflow 版本大于 1.4.0,要求 CUDA 9.0 以上版本
1. 下载nvidia-docker安装包
$ wget https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.1/nvidia-docker-1.0.1-1.x86_64.rpm
2. 安装nvidia-docker
$ rpm -ivh nvidia-docker-1.0.1-1.x86_64.rpm
3. 启动 nvidia-docker 服务
$ sudo systemctl restart nvidia-docker
4. 执行以下命令,若结果显示 active(running) 则说明启动成功
$ systemctl status nvidia-docker.service
Active: active (running) since Fri 2023-07-21 11:15:45 CST; 1min ago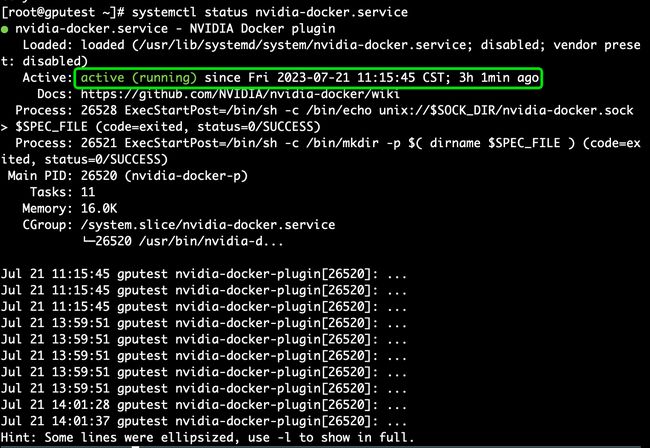 5. 使用 nvidia-docker查看 GPU 信息
5. 使用 nvidia-docker查看 GPU 信息
$ nvidia-docker run --rm nvidia/cuda nvidia-smi
4. 启动NVIDIA-Docker的Tensorflow
4.1 查看下载的镜像
[root@gputest gpu]# docker image ls
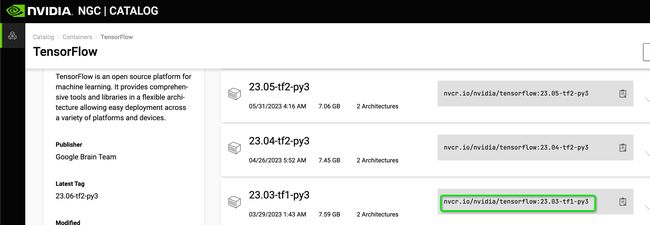
4.2 下载tensorflow v1.15.5版本的镜像
官网地址:TensorFlow | NVIDIA NGC
[root@gputest gpu]# docker pull nvcr.io/nvidia/tensorflow:23.03-tf1-py3
安装testflow1.0版本(向下兼容)
4.3 再次查看下载的镜像
[root@gputest gpu]# docker image ls
第一个为刚刚安装的tensorflow

4.4 进入tensorflow容器
nvidia-docker run --rm -it nvcr.io/nvidia/tensorflow:18.03-py3 (清除镜像)
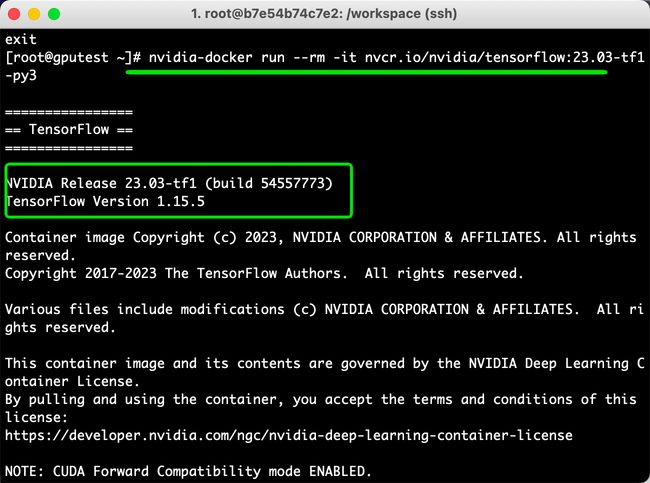
[root@gputest ~]# nvidia-docker run -it nvcr.io/nvidia/tensorflow:23.03-tf1-py3
格式:nvidia-docker run -it {REPOSITORY容器名称:TAG号}
测试脚本:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
hello = tf.constant('--------Hello, TensorFlow!----------')
sess = tf.Session()
sess.run(hello)输出日志太多,可以看到上面的图有I W 分别代表info warning
设置TF_CPP_MIN_LOG_LEVEL的日志级别
机器学习,每次运行代码都会出一堆Successfully opened dynamic library,还有显示各种提示,还有显卡计算信息,于是上网查了很多方法,都不行,最后发现是犯了个错。。如下,要写在import tensorflow前面
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
只要写在前面就行了。。。顺序不能错 不能在 import tensorflow as tf 后面
5. 配置git
1. 在本机生成公私钥ssh-keygen -t rsa -b 4096 -C "[email protected]" 默认生成的公私钥 ~/.ssh/
id_rsa.pub
id_rsa
去查了下4096是啥意思 参考博客ssh-keygen -t rsa -b 4096 -C "邮箱"_weixin_33775582的博客-CSDN博客
-b 4096:b是bit的缩写
-b 指定密钥长度。对于RSA密钥,最小要求768位,默认是2048位。命令中的4096指的是RSA密钥长度为4096位。
DSA密钥必须恰好是1024位(FIPS 186-2 标准的要求)
Generating public/private rsa key pair.
Enter file in which to save the key (/Users/qa/.ssh/id_rsa): yes
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in yes.
Your public key has been saved in yes.pub.
The key fingerprint is:
SHA256:MGbV/xx/xx [email protected]
The key's randomart image is:
+---[RSA 4096]----+
| ...OBB=Eo|
| . .O+oO=o=|
| = .o*+B *o.|
| o o o+B =.. |
| S.+o . |
| . o |
| . . |
| . . |
| . |
+----[SHA256]-----+
2. 配置登录git的username email。为公司给你分配的用户名 密码
第一步:
git config --global user.name 'username'
git config --global user.email '[email protected]'
第二步:设置永久保存
git config --global credential.helper store 复制代码
第三步:手动输入一次用户名和密码,GIT会自动保存密码,下次无须再次输入
git pull
3. 初始化仓库 git init
4. 拉取代码 git clone [email protected]:xx/xx.git
Cloning into 'xx-xx'...
[email protected]'s password:
Permission denied, please try again.
[email protected]'s password:
遇到的问题:没有出username 和 password成对的输入项 ,而是出了password输入项
都不知道密码是啥,跟登录git库的密码不一样。
然后使用http的方式,报一个错误:
use:~/ecox # git clone https://vcs.in.ww-it.cn/ecox/ecox.git
正克隆到 'ecox'...
fatal: unable to access 'https://vcs.in.ww-it.cn/ecox/ecox.git/': SSL certificate problem: unable to get local issuer certificate
提示SSL证书错误。发现说这个错误并不重要是系统证书的问题,系统判断到这个行为会造成不良影响,所以进行了阻止,只要设置跳过SSL证书验证就可以了,那么用命令 :
git config --global http.sslVerify false
6. git同步远程分支到本地,拉取tensorflow对应版本的分支
git fetch origin 远程分支名xxx:本地分支名xxx
使用这种方式会在本地仓库新建分支xxx,但是并不会自动切换到新建的分支xxx,需要手动checkout,当然了远程分支xxx的代码也拉取到了本地分支xxx中。采用这种方法建立的本地分支不会和远程分支建立映射关系
root@818d19092cdc:/gpu/benchmarks# git checkout -b tf1.15 origin/cnn_tf_v1.15_compatible
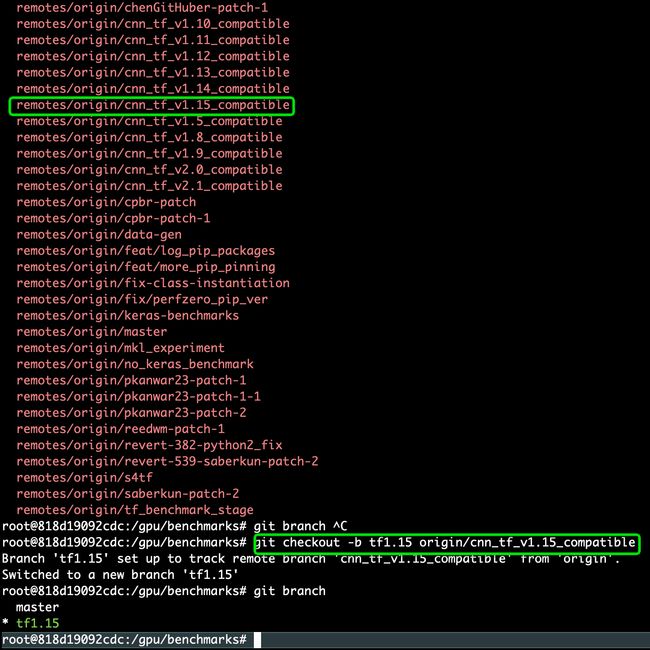
7. tensorflow v1.15脚本运行不同模型
root@818d19092cdc:/gpu/benchmarks/scripts/tf_cnn_benchmarks# pwd
/gpu/benchmarks/scripts/tf_cnn_benchmarks
root@818d19092cdc:/gpu/benchmarks/scripts/tf_cnn_benchmarks# python3 tf_cnn_benchmarks.py
真实操作:
场景一:
batch_size=2
python3 tf_cnn_benchmarks.py --num_gpus=1 --batch_size=2 --model=resnet50 --variable_update=parameter_server
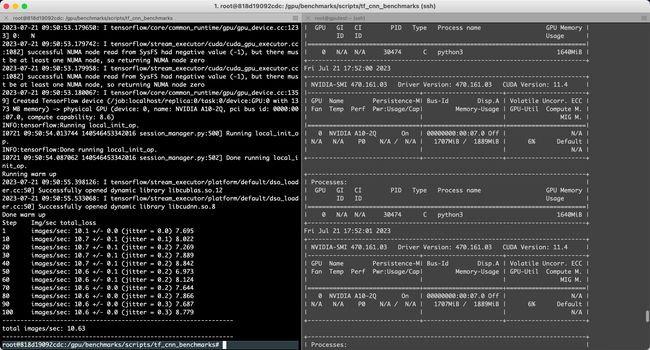
Running warm up
2023-07-21 09:50:55.398126: I tensorflow/stream_executor/platform/default/dso_loader.cc:50] Successfully opened dynamic library libcublas.so.12
2023-07-21 09:50:55.533068: I tensorflow/stream_executor/platform/default/dso_loader.cc:50] Successfully opened dynamic library libcudnn.so.8
Done warm up
Step Img/sec total_loss
1 images/sec: 10.1 +/- 0.0 (jitter = 0.0) 7.695
10 images/sec: 10.7 +/- 0.1 (jitter = 0.1) 8.022
20 images/sec: 10.7 +/- 0.1 (jitter = 0.2) 7.269
30 images/sec: 10.7 +/- 0.1 (jitter = 0.2) 7.889
40 images/sec: 10.7 +/- 0.1 (jitter = 0.2) 8.842
50 images/sec: 10.6 +/- 0.1 (jitter = 0.2) 6.973
60 images/sec: 10.6 +/- 0.1 (jitter = 0.2) 8.124
70 images/sec: 10.6 +/- 0.0 (jitter = 0.2) 7.644
80 images/sec: 10.6 +/- 0.0 (jitter = 0.2) 7.866
90 images/sec: 10.6 +/- 0.0 (jitter = 0.3) 7.687
100 images/sec: 10.6 +/- 0.0 (jitter = 0.3) 8.779
----------------------------------------------------------------
total images/sec: 10.63
场景二:
batch_size=4
python3 tf_cnn_benchmarks.py --num_gpus=1 --batch_size=4 --model=resnet50 --variable_update=parameter_server
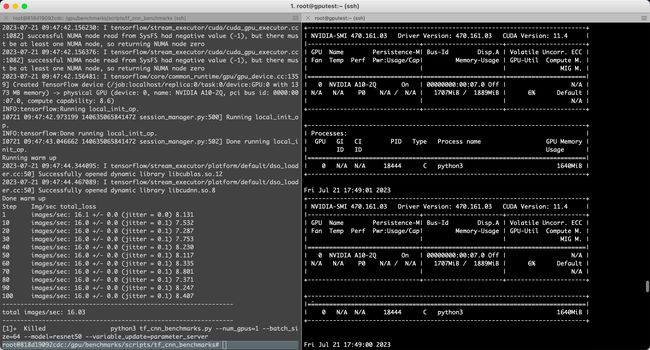
Running warm up
2023-07-21 09:57:12.491542: I tensorflow/stream_executor/platform/default/dso_loader.cc:50] Successfully opened dynamic library libcublas.so.12
2023-07-21 09:57:12.628008: I tensorflow/stream_executor/platform/default/dso_loader.cc:50] Successfully opened dynamic library libcudnn.so.8
Done warm up
Step Img/sec total_loss
1 images/sec: 16.0 +/- 0.0 (jitter = 0.0) 8.122
10 images/sec: 16.0 +/- 0.0 (jitter = 0.1) 7.534
20 images/sec: 16.0 +/- 0.0 (jitter = 0.1) 7.281
30 images/sec: 16.1 +/- 0.0 (jitter = 0.1) 7.757
40 images/sec: 16.1 +/- 0.0 (jitter = 0.1) 8.225
50 images/sec: 16.1 +/- 0.0 (jitter = 0.1) 8.124
60 images/sec: 16.1 +/- 0.0 (jitter = 0.1) 8.332
70 images/sec: 16.0 +/- 0.0 (jitter = 0.1) 8.802
80 images/sec: 16.0 +/- 0.0 (jitter = 0.1) 7.374
90 images/sec: 16.0 +/- 0.0 (jitter = 0.1) 8.243
100 images/sec: 16.0 +/- 0.0 (jitter = 0.1) 8.416
----------------------------------------------------------------
total images/sec: 16.04
结论:由于阿里云服务器申请的是2个G显存,所以只能跑size=2 和 4 ,超出会吐核
已放弃(吐核)--linux 已放弃(吐核) (core dumped) 问题分析
出现这种问题一般是下面这几种情况:
1.内存越界
2.使用了非线程安全的函数
3.全局数据未加锁保护
4.非法指针
5.堆栈溢出
也就是需要检查访问的内存、资源。
可以使用 strace 命令来进行分析
在程序的运行命令前加上 strace,在程序出现:已放弃(吐核),终止运行后,就可以通过 strace 打印在控制台的跟踪信息进行分析和定位问题
方法2:docker启动普通镜像的Tensorflow
$ docker pull tensorflow/tensorflow:1.8.0-gpu-py3
$ docker tag tensorflow/tensorflow:1.8.0-gpu-py3 tensorflow:1.8.0-gpu
# nvidia-docker run -it -p 8888:8888 tensorflow:1.8.0-gpu
$ nvidia-docker run -it -p 8033:8033 tensorflow:1.8.0-gpu
浏览器进入指定 URL(见启动终端回显) 就可以利用 IPython Notebook 使用 tensorflow
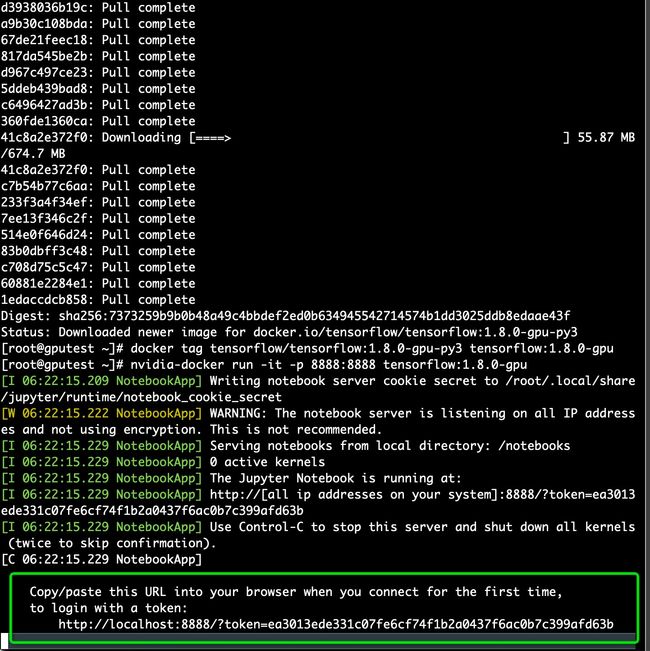
8. 保存镜像的修改
执行以下命令,保存TensorFlow镜像的修改
docker commit -m "commit docker" CONTAINER_ID nvcr.io/nvidia/tensorflow:18.03-py3
# CONTAINER_ID可通过docker ps命令查看。[root@gputest ~]# docker commit -m "commit docker" 818d19092cdc nvcr.io/nvidia/tensorflow:23.03-tf1-py3
sha256:fc14c7fdf361308817161d5d0cc018832575e7f2def99fe49876d2a41391c52c
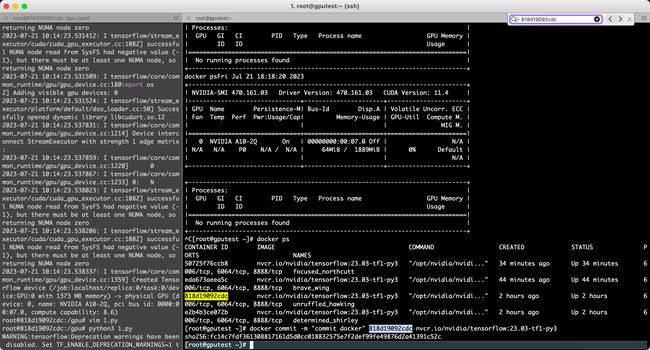
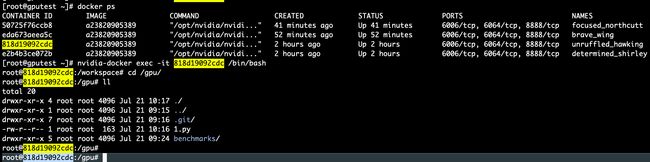
查看docker进程
[root@gputest ~]# docker ps
进入CONTAINER ID containerid
[root@gputest ~]# nvidia-docker exec -it 818d19092cdc /bin/bash
100. 参考资料
如何在GPU实例上部署NGC环境?_GPU云服务器-阿里云帮助中心
TensorFlow | NVIDIA NGC
搭建深度学习docker容器(2)- CentOS7安装NVIDIA-Docker | Luck_zy
Docker安装Docker-Compose - 哔哩哔哩
CentOS7安装nvidia-docker - CodeAntenna
os.environ['TF_CPP_MIN_LOG_LEVEL']无效_os.environ['tf_cpp_min_log_level'] = '2'无效_yulanf的博客-CSDN博客