基于ESP32-S3-BOX-Lite的语音合成与播报系统(esp-idf+WiFi+HTTPS+TTS)
目录
- 项目介绍
- 硬件介绍
- 项目设计
-
- 开发环境及工程目录
- 总体流程图
- 硬件初始化
- WiFi
- HTTPS请求
- TTS语音合成与播报
-
- cJSON解析
- TTS初始化
- 语音合成与播报
- 附加功能
-
- 按键回调
- LVGL数据可视化显示
- 功能展示
- 项目总结
【Funpack2-5】基于ESP32-S3-BOX-Lite的语音合成与播报系统
Github: EmbeddedCamerata/esp-box-lite-bfans-tts
项目介绍
本项目基于ESP32-S3-BOX-Lite,使用esp-idf开发,连接WiFi并发出HTTPS请求,返回B站用户数据信息,再使用cJSON完成json数据解析,得到用户粉丝数,最后通过TTS实现语音合成与播报。
Github: espressif/esp-box
Github: espressif/esp-idf
硬件介绍
ESP32-S3-BOX-Lite 是目前对应的 AIoT 应用开发板,搭载支持 AI 加速的 ESP32-S3 Wi-Fi + Bluetooth 5 (LE) SoC。该开发板配备一块2.4寸LCD显示屏、双麦克风、一个扬声器、两个用于硬件拓展的Pmod™兼容接口、结合三个独立按键,可构建多样的HMI人机交互应用。
ESP32-S3 是一款集成 2.4 GHz Wi-Fi 和 Bluetooth 5 (LE) 的 MCU 芯片,支持远距离模式 (Long Range)。ESP32-S3 搭载 Xtensa® 32 位 LX7 双核处理器,主频高达 240 MHz,内置 512 KB SRAM (TCM),具有 45 个可编程 GPIO 管脚和丰富的通信接口。ESP32-S3 支持更大容量的高速 Octal SPI flash 和片外 RAM,支持用户配置数据缓存与指令缓存。
- Xtensa® 32 位 LX7 双核处理器,主频高达 240 MHz
- 内置 512 KB SRAM、384 KB ROM 存储空间,并支持多个外部 SPI、Dual SPI、 Quad SPI、Octal SPI、QPI、OPI flash 和片外 RAM
- 额外增加用于加速神经网络计算和信号处理等工作的向量指令 (vector instructions)
- 45 个可编程 GPIO,支持常用外设接口如 SPI、I2S、I2C、PWM、RMT、ADC、UART、SD/MMC 主机控制器和 TWAITM 控制器等
- 基于 AES-XTS 算法的 Flash 加密和基于 RSA 算法的安全启动,数字签名和 HMAC 模块,“世界控制器 (World Controller)”模块
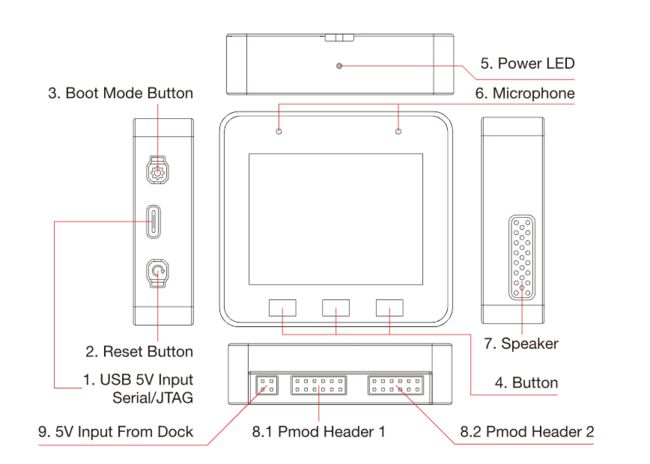
项目设计
开发环境及工程目录
强烈建议采用esp-box仓库中所述的稳定版本:esp-idf v4.4.4 以及 esp-box v0.3.0。二者环境的安装及基本例程上手参见各说明文档,在此不作赘述。
工程目录上,可仿照乐鑫提供的 模板 构建自己的工程目录。例如:
├ build(编译时所产生的构建文件)
├ main
│ ├ include
│ │ ├ wifi_connect.h
│ │ └ ...(其余头文件)
│ └ src
│ │ ├ wifi_connect.c
│ │ └ ...(其余源代码)
│ ├ main.c
│ ├ CMakeLists.txt
│ └ component.mk
├ resources
│ └ server_root_cert.pem(HTTPS请求所用到的网站CA root cert)
├ CMakeLists.txt
├ Makefile
├ partitions.csv
└ ...
⚠️ 注意:工程根目录下 CMakeLists.txt 中,EXTRA_COMPONENT_DIRS 需要指定本地esp-box仓库所在路径,例如:
cmake_minimum_required(VERSION 3.5)
include($ENV{IDF_PATH}/tools/cmake/project.cmake)
set(EXTRA_COMPONENT_DIRS ../esp-box/components)
project(esp-box-lite-bfans-tts)
总体流程图

硬件初始化
参考esp-box中的示例,需要注意的是由于会用到TTS,调用 bsp_board_power_ctrl() 打开AUDIO电源是必要的。
ESP_ERROR_CHECK(bsp_board_init());
ESP_ERROR_CHECK(bsp_board_power_ctrl(POWER_MODULE_AUDIO, true));
WiFi
参考esp-idf所提供的有关wifi的示例:station_example_main,为wifi功能单独设置 .c/.h 文件实现。将示例中的宏定义修改为实际值:
#define EXAMPLE_ESP_WIFI_SSID YOUR_WIFI_SSID
#define EXAMPLE_ESP_WIFI_PASS YOUR_WIFI_PASSWORD
#define EXAMPLE_ESP_MAXIMUM_RETRY 3
在工程的主程序 main.c 中,直接使用示例的主程序即可:
/* Initialize NVS */
esp_err_t ret = nvs_flash_init();
if (ret == ESP_ERR_NVS_NO_FREE_PAGES || ret == ESP_ERR_NVS_NEW_VERSION_FOUND) {
ESP_ERROR_CHECK(nvs_flash_erase());
ret = nvs_flash_init();
}
ESP_ERROR_CHECK(ret);
wifi_init_sta();
⚠️ 注意:在初始化wifi协议栈之前,需初始化NVS(非易失性存储单元)。由于乐鑫会将SSID与密码存储在NVS中,因此需要对开发板做分区配置 partitions.csv,根据esp-box中的例程,增加一个nvs分区与voice_data分区(TTS会用到):
| # Name | Type | SubType | Offset | Size |
|---|---|---|---|---|
| nvs | data | nvs | 0x9000 | 0x4000 |
| factory | app | factory | 0x010000 | 6M |
| voice_data | data | fat | 0x610000 | 3890K |
参考 esp-idf文档:分区表
HTTPS请求
该部分完成对 api.bilibili.com 发出HTTPS请求,URL为:https://api.bilibili.com/x/relation/stat?vmid= + user_uid。
参考esp-idf所提供的有关HTTPS请求的示例:https_request_example_main,为该功能单独设置 .c/.h 文件实现。将示例中的宏定义修改为实际值:
#define WEB_SERVER "api.bilibili.com"
#define WEB_PORT "443"
#define WEB_URL "https://api.bilibili.com/x/relation/stat?vmid=user_uid" // 用户B站UID
在主程序中,由于WiFi功能的初始化已经为我们完成了NVS、netif、event_loop_create等初始化操作,因此只需要示例主程序中创建线程的操作即可:
xTaskCreate(&https_request_task, "https_get_task", 8192, NULL, 5, NULL);
⚠️ 注意:HTTPS请求,需要网站的CA根证书文件 .pem。在示例中有注释指导如何生成网站的 .pem 文件:
/* Root cert for howsmyssl.com, taken from server_root_cert.pem
The PEM file was extracted from the output of this command:
openssl s_client -showcerts -connect www.howsmyssl.com:443
生成 .pem 文件后,修改工程目录下的 component.mk ,将 .pem 文件以二进制形式储存(笔者将其单独放在工程根目录下 .resources 目录下):
COMPONENT_EMBED_TXTFILES := ../resources/server_root_cert.pem
所返回的请求数据(字符串)形如:
HTTP/1.1 200 OK
Date: Sun, 16 Jul 2023 15:33:55 GMT
Content-Type: application/json; charset=utf-8
Content-Length: 108
Connection: keep-alive
Bili-Status-Code: 0
Bili-Trace-Id: 550bd14e7a64b40d
X-Bili-Trace-Id: 26617a088e651658550bd14e7a64b40d
Expires: Sun, 16 Jul 2023 15:33:54 GMT
Cache-Control: no-cache
X-Cache-Webcdn: BYPASS from blzone04
{"code":0,"message":"0","ttl":1,"data":{"mid":42602419,"following":243,"whisper":0,"black":0,"follower":69}}
其中json字段的 data 中 follower 是想解析得到的数据。由于TTS将会用到返回的数据,因此在每次获取到返回数据后,用 memcpy 将其保存至全局变量 https_req_buf。
#define MAX_REQUEST_BUF_LEN 512
char https_req_buf[MAX_REQUEST_BUF_LEN];
static void https_get_request(esp_tls_cfg_t cfg, const char *WEB_SERVER_URL, const char *REQUEST)
{
...
/* Print response directly to stdout as it is read */
for (int i = 0; i < len; i++)
{
putchar(buf[i]);
}
putchar('\n'); // JSON output doesn't have a newline at end
memcpy(https_req_buf, buf, MAX_REQUEST_BUF_LEN); // 保存至全局变量内
} while (1);
...
}
TTS语音合成与播报
cJSON解析
esp-idf/components下,已经包含 cJSON 库,用于做json数据的解析或合成。在上一节已经知道了API返回的数据,因此先简单做个字符串截断 strchr(buf, '{'),待获取到json数据后,再提取json中 follower 字段的内容。
esp_err_t json_parse_followers(char **parsed)
{
char *json_buf;
cJSON *cjson_root = NULL;
json_buf = strchr(https_req_buf, '{');
cjson_root = cJSON_Parse(json_buf);
cJSON *cjson_data = cJSON_GetObjectItem(cjson_root, "data");
cJSON *cjson_follower = cJSON_GetObjectItem(cjson_data, "follower");
*parsed = (char*)malloc(32*sizeof(char));
*parsed = cJSON_Print(cjson_follower);
cJSON_Delete(cjson_root);
return ESP_OK;
}
// 外部调用方式
char *followers;
esp_err_t err = json_parse_followers(&followers);
⚠️ 在此输入参数类型为 char **;使用cJSON的最后,调用 cJSON_Delete() 释放指针。
TTS初始化
经过json解析后得到的粉丝数数据,交由TTS模块完成语音合成。首先需要为板子进行TTS功能的初始化。
参考esp-skainet所提供的有关TTS的示例:chinese_tts
- 存放voice_data数据,esp-box仓库提供了现成的 voice_data(
esp_tts_voice_data_xiaole.dat),参考chinese_tts/README,工程源码目录下./main/CMakeLists.txt需要添加如下内容:
set(voice_data_image ${PROJECT_DIR}/../esp-box/components/esp-sr/esp-tts/esp_tts_chinese/esp_tts_voice_data_xiaole.dat)
add_custom_target(voice_data ALL DEPENDS ${voice_data_image})
add_dependencies(flash voice_data)
partition_table_get_partition_info(size "--partition-name voice_data" "size")
partition_table_get_partition_info(offset "--partition-name voice_data" "offset")
if("${size}" AND "${offset}")
esptool_py_flash_to_partition(flash "voice_data" "${voice_data_image}")
else()
set(message "Failed to find model in partition table file"
"Please add a line(Name=voice_data, Type=data, Size=3890K) to the partition file.")
endif()
⚠️ 注意:修改 voice_data_image 为实际对应 esp_tts_voice_data_xiaole.dat 路径,其余可照抄。
- 将示例程序中的部分代码借鉴下来:
static const char *TAG = "TTS report";
static esp_tts_handle_t *tts_handle;
esp_err_t tts_init()
{
/* 1. create esp tts handle */
// initial voice set from separate voice data partition
const esp_partition_t *part = esp_partition_find_first(ESP_PARTITION_TYPE_DATA, ESP_PARTITION_SUBTYPE_ANY, "voice_data");
if (part == NULL)
{
ESP_LOGE(TAG, "Couldn't find voice data partition!\n");
return ESP_FAIL;
}
else
{
ESP_LOGI(TAG, "voice_data paration size:%d\n", part->size);
}
void *voicedata;
#if ESP_IDF_VERSION >= ESP_IDF_VERSION_VAL(5, 0, 0)
esp_partition_mmap_handle_t mmap;
esp_err_t err = esp_partition_mmap(part, 0, part->size, ESP_PARTITION_MMAP_DATA, &voicedata, &mmap);
#else
spi_flash_mmap_handle_t mmap;
esp_err_t err = esp_partition_mmap(part, 0, part->size, SPI_FLASH_MMAP_DATA, &voicedata, &mmap);
#endif
if (err != ESP_OK)
{
ESP_LOGE(TAG, "Couldn't map voice data partition!\n");
return ESP_FAIL;
}
esp_tts_voice_t *voice = esp_tts_voice_set_init(&esp_tts_voice_xiaole, (int16_t *)voicedata);
tts_handle = esp_tts_create(voice);
if (!tts_handle)
{
ESP_LOGE(TAG, "Created tts_handle failed!\n");
return ESP_FAIL;
}
return ESP_OK;
}
⚠️ 注意:使用的是xiaole语音数据而非template,esp_tts_voice_t *voice = esp_tts_voice_set_init(&esp_tts_voice_xiaole, (int16_t *)voicedata)
语音合成与播报
参考esp-sr/speech_command_recognition所提供的简单的语音合成示例:
esp_err_t tts_report(char *prompt, unsigned int speed)
{
if (esp_tts_parse_chinese(tts_handle, prompt))
{
int len[1] = {0};
size_t bytes_write = 0;
do
{
short *pcm_data = esp_tts_stream_play(tts_handle, len, speed);
i2s_write(I2S_NUM_0, pcm_data, len[0] * 2, &bytes_write, portMAX_DELAY);
} while (len[0] > 0);
}
else
{
ESP_LOGE(TAG, "Parse %s failed!\n", prompt);
return ESP_FAIL;
}
esp_tts_stream_reset(tts_handle);
return ESP_OK;
}
⚠️ 注意:调用 i2s_write() 而非 esp_audio_play() 完成数据写入外设。
其次,还需要调节语音播报语速。即便 esp_tts_stream_play() 函数输入 speed=0,其语音播报速度依旧太快,需要在开发板BSP相关代码做修改。具体修改 components/bsp/src/boards/esp32_s3_box_lite.c 中139~140行,将I2S与语音编解码时钟频率降低。尝试取11K时语速合适。
// ESP_ERROR_CHECK(bsp_i2s_init(I2S_NUM_0, 16000));
// ESP_ERROR_CHECK(bsp_codec_init(AUDIO_HAL_16K_SAMPLES));
ESP_ERROR_CHECK(bsp_i2s_init(I2S_NUM_0, 11000));
ESP_ERROR_CHECK(bsp_codec_init(AUDIO_HAL_11K_SAMPLES));
附加功能
按键回调
将TTS语音合成与播报的功能绑定在按键回调上。ESP32-S3-BOX-Lite正面三个按钮从左至右分别为 BOARD_BTN_ID_PREV、BOARD_BTN_ID_ENTER、BOARD_BTN_ID_NEXT。参考esp-box出厂程序中按键的实现,基本的按键回调函数绑定为:
bsp_btn_register_callback(BOARD_BTN_ID_PREV, BUTTON_PRESS_DOWN, tts_report_cb, NULL);
含义为按下正面左侧按钮时,触发 tts_report_cb 函数。该函数完成对HTTPS请求返回数据的json格式解析、将得到的粉丝数(字符串)显示在屏幕上、将粉丝数字符串转换为字符串,例如,“粉丝数一百一十四”、“粉丝数一千九百一十九”、最后调用 tts_report() 完成语音播报。
void tts_report_cb(void *arg)
{
char *followers;
char prompt[64];
/* Parse the followers number(string) */
esp_err_t err = json_parse_followers(&followers);
/* Update the followers number on the screen */
lvgl_display_update(atoi(followers));
/* Convert the string to Chinese prompt */
err = followers_to_prompt(followers, prompt);
/* Play the prompt at speed=1 */
err = tts_report(prompt, 1);
}
LVGL数据可视化显示
esp-box内已经实现LVGL的移植,可参考出厂程序示例学习LVGL用法。首先,需要在主程序中初始化LVGL:
ESP_ERROR_CHECK(lv_port_init());
bsp_lcd_set_backlight(true);
之后简单地在屏幕中央打印出“Followers: 102”即可,先初始化显示“Followers: 0”:
void lvgl_display_init()
{
/* Change the active screen's background color */
lv_obj_set_style_bg_color(lv_scr_act(), lv_color_hex(0x003a57), LV_PART_MAIN);
/* Create a white label, set its text and align it to the center */
label = lv_label_create(lv_scr_act());
lv_obj_set_style_text_font(label, &lv_font_montserrat_24, 0); // Font size 24
lv_label_set_text(label, "Followers: 0");
lv_obj_set_style_text_color(lv_scr_act(), lv_palette_main(LV_PALETTE_ORANGE), LV_PART_MAIN);
lv_obj_align(label, LV_ALIGN_CENTER, 0, 0);
}
后在按键回调中, lvgl_display_update() 函数内刷新显示的粉丝数:
void lvgl_display_update(int num)
{
lv_label_set_text_fmt(label, "Followers: %d", num);
}
并且,在工程主程序的最后:
do
{
lv_task_handler();
} while (vTaskDelay(1), true);
功能展示
通过 idf.py flash monitor 完成程序下载与监控。初始屏幕显示:

之后,开发板将连接上wifi,发出HTTPS请求并返回如下图所示数据:

之后,按下正面左键,开发板将合成语音并播报,如下图所示,“粉丝数六十九”:

同时,屏幕将更新显示:

详细展示参见:B站:基于ESP32-S3-BOX-Lite的语音合成与播报系统
项目总结
本次工程基于 esp-idf 开发,实现了 WiFi 连接、HTTPS请求,实现B站用户粉丝数的读取,并通过 cJSON 完成 json 数据的解析,最后通过 TTS 实现语音合成与播报。
esp-idf 开发框架旨在基础地、详尽地操控整个芯片与板级的外设与配置。基于 esp-idf 的工程构建,使用 CMake 配置工程与资源的方式非常优雅,在 Linux 上编译速度快(因为Windows 上编译的速度更慢)。esp-idf 提供的各种外设示例也都能参考。TTS 这边,一开始是想参考 esp-skainet 那边基于 esp32-s3-box 的示例,但好像有关音频 codec 的移植似乎有些混乱。期望 esp-skainet 那边能官方支持 esp32-s3-box-lite。