2021-10-18大数据学习日志——数据埋点+网络爬虫——多任务和网络
课程介绍:
数据埋点本质上就是进行数据采集。相对于爬虫的数据采集形式,数据埋点是对自身业务数据进行采集。要进行数据埋点就要了解我们的业务程序的开发流程,知道整个数据的传递过程,这样能更加明确数据分析的业务需求,有利于数据埋点的准确性。
在这一阶段前半部部分,学习部分前端:HTML、CSS、JS、Jquery知识,后端:多任务、网络编程及Python高级语法。通过对前端和后端开发业务的了解,方便在数据埋点时能更好的确认是前端埋点还是后端埋点。
另外本阶段后半部分将学习爬虫的基础知识,通过爬虫程序去爬出数据并进行数据的提取操作。

本章节学习目标:
- 能够知道多任务的执行方式
- 能够知道进程的作用
- 能够使用多进程完成多任务
- 能够写出进程执行带有参数的任务
- 能够说出进程的注意点
本章节常用单词:
- acquire 英 [ə'kwaɪə] 获得;取得;
- lock 英 [lɒk] 锁,锁上;
- release 英 [rɪ'liːs] 释放;发射
- broadcast 英 ['brɔːdkɑːst] 广播,播送;
- daemon 英 ['diːmən] 守护进程;后台程序
- process 英 [prəˈses;(for n.)ˈprəʊses] 过程,进程;
- arguments 英 ['ɑːgjʊm(ə)nts] 参数
- group 英 [gruːp] 组;团体
- terminate 英 ['tɜːmɪneɪt] 结束,终止;
- multiprocessing 英 [ˌmʌltɪˈprəʊsɛsɪŋ] 多重处理;多道处理
- process 英[ˈprəʊses , prəˈses] 工艺流程; 工序;进程
01_多任务编程——进程
1.1 多任务的介绍
学习目标
- 能够知道多任务的执行方式
1.1.1 提问
利用之前所学知识能够让两个函数或者方法同时执行吗?
不能,因为之前所写的程序都是单任务的,也就是说一个函数或者方法执行完成另外一个函数或者方法才能执行,要想实现这种操作就需要使用多任务。
多任务的最大好处是充分利用CPU资源,提高程序的执行效率。
1.1.2 多任务的概念
多任务是指在同一时间内执行多个任务,例如: 现在电脑安装的操作系统都是多任务操作系统,可以同时运行着多个软件。
多任务效果图:

1.1.3 多任务的执行方式
- 并发
- 并行
并发:
在一段时间内交替去执行任务。
例如:
对于单核cpu处理多任务,操作系统轮流让各个软件交替执行,假如:软件1执行0.01秒,切换到软件2,软件2执行0.01秒,再切换到软件3,执行0.01秒……这样反复执行下去。表面上看,每个软件都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像这些软件都在同时执行一样,这里需要注意单核cpu是并发的执行多任务的。
并行:
对于多核cpu处理多任务,操作系统会给cpu的每个内核安排一个执行的软件,多个内核是真正的一起执行软件。这里需要注意多核cpu是并行的执行多任务,始终有多个软件一起执行。
1.2 进程
学习目标
- 能够知道进程的作用
1.2.1 进程的介绍
在Python程序中,想要实现多任务可以使用进程来完成,进程是实现多任务的一种方式。
1.2.2 进程的概念
一个正在运行的程序或者软件就是一个进程,它是操作系统进行资源分配的基本单位,也就是说每启动一个进程,操作系统都会给其分配一定的运行资源(内存资源)保证进程的运行。
比如:现实生活中的公司可以理解成是一个进程,公司提供办公资源(电脑、办公桌椅等),真正干活的是员工,员工可以理解成线程。
注意:
一个程序运行后至少有一个进程,一个进程默认有一个线程,进程里面可以创建多个线程,线程是依附在进程里面的,没有进程就没有线程。
1.2.3 进程的作用
单进程效果图:

多进程效果图:
 说明:
说明:
多进程可以完成多任务,每个进程就好比一家独立的公司,每个公司都各自在运营,每个进程也各自在运行,执行各自的任务。
1.3 多进程的使用
学习目标
- 能够使用多进程完成多任务
1.3.1 导入进程包
# 导入进程包
import multiprocessing1.3.2 Process进程类的说明
Process(group,target,name,args,kwargs)
- group:指定进程组,目前只能使用None
- target:执行的目标任务名
- name:进程名字
- args:以元组方式给执行任务传参
- kwargs: 以字典方式给执行任务传参
Process创建的实例对象的常用方法:
- start():启动子进程实例(创建子进程)
- join():等待子进程执行结束
- terminate():不管任务是否完成,立即终止子进程
Process创建的实例对象的常用属性:
name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
1.3.3 多进程完成多任务的代码
import multiprocessing
import time
# 跳舞任务
def dance():
for i in range(5):
print("跳舞中...")
time.sleep(1)
# 唱歌任务
def sing():
for i in range(5):
print("唱歌中...")
time.sleep(1)
if __name__ == '__main__':
# 创建子进程
# group: 表示进程组,目前只能使用None
# target: 表示执行的目标任务名(函数名、方法名)
dance_process = multiprocessing.Process(target=dance)
sing_process = multiprocessing.Process(target=sing)
# 启动子进程执行对应的任务
dance_process.start()
sing_process.start()执行结果:
唱歌中...
跳舞中...
唱歌中...
跳舞中...
唱歌中...
跳舞中...
唱歌中...
跳舞中...
唱歌中...
跳舞中...1.4 进程执行带有参数的任务
学习目标
- 能够写出进程执行带有参数的任务
1.4.1 进程执行带有参数的任务的介绍
前面我们使用进程执行的任务是没有参数的,假如我们使用进程执行的任务带有参数,如何给函数传参呢?
Process类执行任务并给任务传参数有两种方式:
- args 表示以元组的方式给执行任务传参
- kwargs 表示以字典方式给执行任务传参
1.4.2 args参数的使用
示例代码:
import multiprocessing
import time
# 带有参数的任务
def task(count):
for i in range(count):
print("任务执行中..")
time.sleep(0.2)
else:
print("任务执行完成")
if __name__ == '__main__':
# 创建子进程
# args: 以元组的方式给任务传递参数
sub_process = multiprocessing.Process(target=task, args=(3,))
sub_process.start()执行结果:
任务执行中..
任务执行中..
任务执行中..
任务执行完成1.4.3 kwargs参数的使用
示例代码:
import multiprocessing
import time
# 带有参数的任务
def task(count):
for i in range(count):
print("任务执行中..")
time.sleep(0.2)
else:
print("任务执行完成")
if __name__ == '__main__':
# 创建子进程
# kwargs: 以字典的方式给任务传递参数
sub_process = multiprocessing.Process(target=task, kwargs={"count": 3})
sub_process.start()执行结果:
任务执行中..
任务执行中..
任务执行中..
任务执行完成1.5 进程的注意点
学习目标
- 能够说出进程的注意点
1.5.1 进程的注意点介绍
(1) 进程之间不共享全局变量
(2) 主进程会等待所有的子进程执行结束再结束
1.5.2 进程之间不共享全局变量
import multiprocessing
import time
# 定义全局变量
g_list = []
# 添加数据的函数
def add_data():
for i in range(5):
g_list.append(i)
print('add:', i)
time.sleep(0.2)
print('add_data:', g_list)
# 读取数据的函数
def read_data():
print('read_data:', g_list)
if __name__ == '__main__':
# 创建添加数据的子进程
add_data_process = multiprocessing.Process(target=add_data)
# 创建读取数据的子进程
read_data_process = multiprocessing.Process(target=read_data)
# 启动添加数据子进程
add_data_process.start()
# 主进程等待 add_data_process 执行完成,再向下继续执行
add_data_process.join()
# 启动读取数据子进程
read_data_process.start()
print('main:', g_list)
# 结论:多进程之间不会共享全局变量执行结果:
add: 0
add: 1
add: 2
add: 3
add: 4
add_data: [0, 1, 2, 3, 4]
main: []
read_data []进程之间不共享全局变量的解释效果图:

1.5.3 进程之间不共享全局变量的小结
- 创建子进程会对主进程资源进行拷贝,也就是说子进程是主进程的一个副本,好比是一对双胞胎,之所以进程之间不共享全局变量,是因为操作的不是同一个进程里面的全局变量,只不过不同进程里面的全局变量名字相同而已。
1.5.4 主进程会等待所有的子进程执行结束再结束
假如我们现在创建一个子进程,这个子进程执行完大概需要2秒钟,现在让主进程执行1秒钟就退出程序,查看一下执行结果,示例代码如下:
import multiprocessing
import time
# 任务函数
def task():
for i in range(10):
print('任务执行中...')
time.sleep(0.2)
if __name__ == '__main__':
# 创建子进程并启动
sub_process = multiprocessing.Process(target=task)
sub_process.start()
# 主进程延时 1s
time.sleep(1)
print('主进程结束!')
# 退出程序
exit()
# 结论:主进程会等待所有的子进程执行完成以后程序再退出执行结果:
任务执行中...
任务执行中...
任务执行中...
主进程结束!
任务执行中...
任务执行中...
任务执行中...
任务执行中...
任务执行中...
任务执行中...
任务执行中...说明:
通过上面代码的执行结果,我们可以得知: 主进程会等待所有的子进程执行结束再结束
假如我们就让主进程执行0.5秒钟,子进程就销毁不再执行,那怎么办呢?
- 我们可以设置守护主进程 或者 在主进程退出之前 终止子进程
守护主进程:
- 守护主进程就是主进程退出子进程销毁不再执行
import multiprocessing
import time
# 任务函数
def task():
for i in range(10):
print('任务执行中...')
time.sleep(0.2)
if __name__ == '__main__':
# 创建子进程并启动
sub_process = multiprocessing.Process(target=task)
# 设置子进程为守护进程
sub_process.daemon = True # 注意:设置守护进程需要在进程启动之前!!!
sub_process.start()
# 主进程延时 1s
time.sleep(1)
print('主进程结束!')
# 退出程序
exit()执行结果:
任务执行中...
任务执行中...
主进程结束!终止子进程:
- 结束子进程执
import multiprocessing
import time
# 任务函数
def task():
for i in range(10):
print('任务执行中...')
time.sleep(0.2)
if __name__ == '__main__':
# 创建子进程并启动
sub_process = multiprocessing.Process(target=task)
sub_process.start()
# 主进程延时 1s
time.sleep(1)
print('主进程结束!')
# 终止子进程
sub_process.terminate()
# 退出程序
exit()执行结果:
任务执行中...
任务执行中...
主进程结束!1.5.5 主进程会等待所有的子进程执行结束再结束的小结
- 为了保证子进程能够正常的运行,主进程会等所有的子进程执行完成以后再销毁,设置守护主进程的目的是主进程退出子进程销毁,不让主进程再等待子进程去执行。
- 设置守护主进程方式: 子进程对象.daemon = True
- 终止子进程方式: 子进程对象.terminate()
02_多任务编程——线程
本章节学习目标:
- 能够知道线程的作用
- 能够使用多线程完成多任务
- 能够写出线程执行带有参数的任务
- 能够说出线程的注意点
- 能够知道进程和线程的关系
本章节常用单词:
- desktop 英 ['desktɒp] 桌面;台式机
- service 英 ['sɜːvɪs] 服务,服侍
- Handshake 英 ['hæn(d)ʃeɪk] 握手
- sequence 英 ['siːkw(ə)ns] 序列;顺序;
- client 英 ['klaɪənt] 客户;顾客;
- wait 英 [weɪt] 等候;推迟;
- number 英 ['nʌmbə] 数字;编号
- maximum 英 ['mæksɪməm] 最大限度;最大量
- process 英 [prəˈses;(for n.)ˈprəʊses] 过程,进程;
- thread 英 [θred] 线;思路;
- sleep 英 [sliːp] 睡,睡觉
- join 英 [dʒɒɪn] 参加;结合;
2.1 线程
学习目标
能够知道线程的作用
2.1.1 线程的介绍
在Python中,想要实现多任务除了使用进程,还可以使用线程来完成,线程是实现多任务的另外一种方式。
2.1.2 线程的概念
线程是进程中执行代码的一个分支,每个执行分支(线程)要想工作执行代码需要cpu进行调度 ,也就是说线程是cpu调度的基本单位,每个进程至少都有一个线程,而这个线程就是我们通常说的主线程。
2.1.3 线程的作用
多线程可以完成多任务
多线程效果图:

2.2 多线程的使用
学习目标
- 能够使用多线程完成多任务
2.2.1 导入线程模块
# 导入线程模块
import threading2.2.2 线程类Thread参数说明
Thread([group [, target [, name [, args [, kwargs]]]]])
- group: 线程组,目前只能使用None
- target: 执行的目标任务名
- args: 以元组的方式给执行任务传参
- kwargs: 以字典方式给执行任务传参
- name: 线程名,一般不用设置
2.2.3 启动线程
启动线程使用start方法
2.2.4 多线程完成多任务的代码
# 导入线程模块
import threading
import time
# 跳舞任务函数
def dance():
for i in range(5):
print('正在跳舞...%d' % i)
time.sleep(1)
# 唱歌任务函数
def sing():
for i in range(5):
print('正在唱歌...%d' % i)
time.sleep(1)
if __name__ == '__main__':
# 创建跳舞的子线程
dance_thread = threading.Thread(target=dance)
# 创建唱歌的子线程
sing_thread = threading.Thread(target=sing)
# 启动两个子线程
dance_thread.start()
sing_thread.start()执行结果:
正在唱歌...0
正在跳舞...0
正在唱歌...1
正在跳舞...1
正在唱歌...2
正在跳舞...2
正在唱歌...3
正在跳舞...3
正在唱歌...4
正在跳舞...42.3 线程执行带有参数的任务
学习目标
- 能够写出线程执行带有参数的任务
2.3.1 线程执行带有参数的任务的介绍
前面我们使用线程执行的任务是没有参数的,假如我们使用线程执行的任务带有参数,如何给函数传参呢?
Thread类执行任务并给任务传参数有两种方式:
- args 表示以元组的方式给执行任务传参
- kwargs 表示以字典方式给执行任务传参
2.3.2 args参数的使用
示例代码:
import threading
import time
# 带有参数的任务(函数)
def task(count):
for i in range(count):
print('任务执行中...')
time.sleep(0.2)
else:
print('任务执行完成')
if __name__ == '__main__':
# 创建子线程,指定执行的任务函数
sub_thread = threading.Thread(target=task, args=(3, ))
# 启动子线程
sub_thread.start()执行结果:
任务执行中..
任务执行中..
任务执行中..
任务执行完成2.3.3 kwargs参数的使用
示例代码:
import threading
import time
# 带有参数的任务(函数)
def task(count):
for i in range(count):
print('任务执行中...')
time.sleep(0.2)
else:
print('任务执行完成')
if __name__ == '__main__':
# 创建子线程,指定执行的任务函数
sub_thread = threading.Thread(target=task, kwargs={'count': 3})
# 启动子线程
sub_thread.start()执行结果:
任务执行中..
任务执行中..
任务执行中..
任务执行完成2.4 线程的注意点
学习目标
- 能够说出线程的注意点
2.4.1 线程的注意点介绍
- 线程之间执行是无序的
- 主线程会等待所有的子线程执行结束再结束
- 线程之间共享全局变量
2.4.2 线程之间执行是无序的
import threading
import time
def task():
time.sleep(1)
print(f'当前线程:{threading.current_thread().name}')
if __name__ == '__main__':
for i in range(5):
sub_thread = threading.Thread(target=task)
sub_thread.start()执行结果:
当前线程: Thread-1
当前线程: Thread-2
当前线程: Thread-4
当前线程: Thread-5
当前线程: Thread-3说明:
- 线程之间执行是无序的,它是由cpu调度决定的 ,cpu调度哪个线程,哪个线程就先执行,没有调度的线程不能执行。
- 进程之间执行也是无序的,它是由操作系统调度决定的,操作系统调度哪个进程,哪个进程就先执行,没有调度的进程不能执行。
2.4.3 主线程会等待所有的子线程执行结束再结束
假如我们现在创建一个子线程,这个子线程执行完大概需要2.5秒钟,现在让主线程执行1秒钟就退出程序,查看一下执行结果,示例代码如下:
import threading
import time
def task():
for i in range(5):
print('任务执行中...')
time.sleep(0.5)
if __name__ == '__main__':
# 创建子线程
sub_thread = threading.Thread(target=task)
sub_thread.start()
# 主进程延时 1s
time.sleep(1)
print('主线程结束!')执行结果:
任务执行中...
任务执行中...
主线程结束!
任务执行中...
任务执行中...
任务执行中...说明:
通过上面代码的执行结果,我们可以得知:主线程会等待所有的子线程执行结束再结束
2.4.4 线程之间共享全局变量
需求:
- 定义一个列表类型的全局变量
- 创建两个子线程分别执行向全局变量添加数据的任务和向全局变量读取数据的任务
- 查看线程之间是否共享全局变量数据
import threading
import time
# 定义全局变量
g_list = []
# 添加数据的函数
def add_data():
for i in range(5):
g_list.append(i)
print('add:', i)
time.sleep(0.2)
print('add_data:', g_list)
# 读取数据的函数
def read_data():
print('read_data:', g_list)
if __name__ == '__main__':
# 创建添加数据的子线程
add_data_thread = threading.Thread(target=add_data)
# 创建读取数据的子线程
read_data_thread = threading.Thread(target=read_data)
# 启动添加数据子线程
add_data_thread.start()
# 主线程等待 add_data_thread 执行完成,再向下继续执行
add_data_thread.join()
# 启动读取数据子线程
read_data_thread.start()
print('main:', g_list)执行结果:
add: 0
add: 1
add: 2
add: 3
add: 4
add_data: [0, 1, 2, 3, 4]
read_data: [0, 1, 2, 3, 4]
main: [0, 1, 2, 3, 4]2.4.5 守护线程设置
假如我们就让主线程执行1秒钟,子线程就销毁不再执行,那怎么办呢?
- 我们可以设置守护主线程
守护主线程:
- 守护主线程就是主线程退出子线程销毁不再执行
设置守护主线程有两种方式:
- threading.Thread(target=show_info, daemon=True)
- 线程对象.setDaemon(True)
设置守护主线程的示例代码:
import threading
import time
# 任务函数
def task():
for i in range(10):
print('任务执行中...')
time.sleep(0.2)
if __name__ == '__main__':
# 创建子线程并启动
sub_thread = threading.Thread(target=task)
# 设置子线程为守护线程
# sub_thread.daemon = True
sub_thread.setDaemon(True) # 注意:设置守护线程要在线程启动之前!!!
sub_thread.start()
# 主线程延时 1s
time.sleep(1)
print('主线程结束!')执行结果:
任务执行中...
任务执行中...
任务执行中...
任务执行中...
任务执行中...
主线程结束!2.4.6 线程之间共享全局变量数据出现错误问题
需求:
- 定义两个函数,实现循环100万次,每循环一次给全局变量加1
- 创建两个子线程执行对应的两个函数,查看计算后的结果
import threading
# 定义全局变量
g_num = 0
def sum_num1():
global g_num
# 循环一次给全局变量加1
for i in range(1000000):
g_num += 1
print('sum1:', g_num)
def sum_num2():
global g_num
# 循环一次给全局变量加1
for i in range(1000000):
g_num += 1
print('sum2:', g_num)
if __name__ == '__main__':
# 创建两个线程
first_thread = threading.Thread(target=sum_num1)
second_thread = threading.Thread(target=sum_num2)
# 启动两个线程
first_thread.start()
second_thread.start()执行结果:
sum1: 1210949
sum2: 1496035注意点:
多线程同时对全局变量操作数据发生了错误
错误分析:
两个线程first_thread和second_thread都要对全局变量g_num(默认是0)进行加1运算,但是由于是多线程同时操作,有可能出现下面情况:
- 在g_num=0时,first_thread取得g_num=0。此时系统把first_thread调度为”seeping”状态,把second_thread转换为”running”状态,t2也获得g_num=0
- 然后second_thread对得到的值进行加1并赋给g_num,使得g_num=1
- 然后系统又把second_thread调度为”sleeping”,把first_thread转为”running”。线程t1又把它之前得到的0加1后赋值给g_num。
- 这样导致虽然first_thread和first_thread都对g_num加1,但结果仍然是g_num=1
全局变量数据错误的解决办法:
线程同步:保证同一时刻只能有一个线程去操作全局变量
同步:就是协同步调,按预定的先后次序进行运行。如:你说完,我再说, 好比现实生活中的对讲机
线程同步的方式:
- 线程等待(join):等待一个线程执行结束之后,代码再继续执行,同一时刻只有一个线程执行
- 互斥锁
线程等待的示例代码:
import threading
# 定义全局变量
g_num = 0
def sum_num1():
global g_num
# 循环一次给全局变量加1
for i in range(1000000):
g_num += 1
print('sum1:', g_num)
def sum_num2():
global g_num
# 循环一次给全局变量加1
for i in range(1000000):
g_num += 1
print('sum2:', g_num)
if __name__ == '__main__':
# 创建两个线程
first_thread = threading.Thread(target=sum_num1)
second_thread = threading.Thread(target=sum_num2)
# 启动两个线程
first_thread.start()
# 线程等待:主线程等待 first_thread 线程执行结束之后,再启动执行 second_thread 线程
first_thread.join()
second_thread.start()执行结果:
sum1: 1000000
sum2: 20000002.5 互斥锁
学习目标
- 能够知道互斥锁的作用
2.5.1 互斥锁的概念
互斥锁: 对共享数据进行锁定,保证同一时刻只能有一个线程去操作。
注意:
- 互斥锁是多个线程一起去抢"锁",抢到锁的线程执行,没有抢到锁的线程需要等待,等互斥锁使用完释放后,其它等待的线程再去抢这个锁。
2.5.2 互斥锁的使用
threading模块中定义了Lock变量,这个变量本质上是一个函数,通过调用这个函数可以获取一把互斥锁。
互斥锁使用步骤:
# 创建锁
mutex = threading.Lock()
# 抢锁(没抢到锁的线程,此句代码会阻塞等待)
mutex.acquire()
...这里编写代码能保证同一时刻只能有一个线程去操作, 对共享数据进行锁定...
# 释放锁
mutex.release()注意点:
- acquire和release方法之间的代码同一时刻只能有一个线程去操作
- 如果在调用acquire方法的时候 其他线程已经使用了这个互斥锁,那么此时acquire方法会堵塞,直到这个互斥锁释放后才能再次上锁。
2.5.3 使用互斥锁完成2个线程对同一个全局变量各加100万次的操作
import threading
# 创建互斥锁
lock = threading.Lock()
# 定义全局变量
g_num = 0
def sum_num1():
# 抢锁
lock.acquire()
global g_num
# 循环一次给全局变量加1
for i in range(1000000):
g_num += 1
# 释放锁
lock.release()
print('sum1:', g_num)
def sum_num2():
# 抢锁
lock.acquire()
global g_num
# 循环一次给全局变量加1
for i in range(1000000):
g_num += 1
# 释放锁
lock.release()
print('sum2:', g_num)
if __name__ == '__main__':
# 创建两个线程
first_thread = threading.Thread(target=sum_num1)
second_thread = threading.Thread(target=sum_num2)
# 启动两个线程
first_thread.start()
second_thread.start()执行结果:
sum1: 1000000
sum2: 2000000说明:
通过执行结果可以地址互斥锁能够保证多个线程访问共享数据不会出现数据错误问题
2.6 进程和线程的对比
学习目标
- 能够知道进程和线程的关系
2.6.1 进程和线程的对比的三个方向
- 关系对比
- 区别对比
- 优缺点对比
2.6.2 关系对比
- 线程是依附在进程里面的,没有进程就没有线程。
- 一个进程默认提供一条线程,进程可以创建多个线程。
2.6.3 区别对比
(1)进程之间不共享全局变量
(2)线程之间共享全局变量,但是要注意资源竞争的问题,解决办法: 互斥锁或者线程同步
(3)创建进程的资源开销要比创建线程的资源开销要大
(4)进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
(5)线程不能够独立执行,必须依存在进程中
(6)多进程开发比单进程多线程开发稳定性要强
2.6.4 优缺点对比
- 进程优缺点:
- 优点:可以用多核
- 缺点:资源开销大
- 线程优缺点:
- 优点:资源开销小
- 缺点:不能使用多核
2.7 扩展阅读: 死锁
学习目标
- 能够知道产生死锁的原因
2.7.1 死锁的概念
死锁: 一直等待对方释放锁的情景就是死锁
说明:
现实社会中,男女双方一直等待对方先道歉的这种行为就好比是死锁。
死锁的结果
- 会造成应用程序的停止响应,不能再处理其它任务了。
2.7.2 死锁示例
需求:
根据下标在列表中取值, 保证同一时刻只能有一个线程去取值
2.7.3 避免死锁
- 在合适的地方释放锁
import threading
import time
# 创建互斥锁
lock = threading.Lock()
# 根据下标去取值, 保证同一时刻只能有一个线程去取值
def get_value(index):
# 上锁
lock.acquire()
print(threading.current_thread())
my_list = [3,6,8,1]
if index >= len(my_list):
print("下标越界:", index)
# 当下标越界需要释放锁,让后面的线程还可以取值
lock.release()
return
value = my_list[index]
print(value)
time.sleep(0.2)
# 释放锁
lock.release()
if __name__ == '__main__':
# 模拟大量线程去执行取值操作
for i in range(30):
sub_thread = threading.Thread(target=get_value, args=(i,))
sub_thread.start()03_网络编程
本章节目标
- 能够说出IP 地址的作用
- 能够说出端口和端口号的作用
- 能够说出TCP 的特点
- 能够说出 socket 的作用
- 能够知道TCP客户端程序的开发流程
- 能够写出 TCP 客户端应用程序发送和接收消息
- 能够写出TCP服务端应用程序接收和发送消息
- 能够说出开发TCP网络应用程序的注意点
- 能够说出多任务版TCP服务端程序的实现过程
本章节常用单词
- bind 英 [baɪnd] 绑;约束;
- content 英 [kən'tent] 内容,目录;
- message 英 ['mesɪdʒ] 消息;通知;
- control 英 [kən'trəʊl] 控制;管理;
- broadcast 英 ['brɔːdkɑːst] 广播,播送;播放
- read 英 [ri:d;red] 阅读;读懂
- write 英 [raɪt] 写,写字;
- refused 英 [rɪ'fjuːzd] 拒绝
- connect 英 [kə'nekt] 连接;联合;关连
- listen 英 ['lɪs(ə)n] 听,倾听;听从
- accept 英 [əkˈsept] 接受;承认;承担;
3.1 IP 地址的介绍
学习目标
- 能够说出IP 地址的作用
3.1.1 IP 地址的概念
IP 地址就是标识网络中设备的一个地址,好比现实生活中的家庭地址。
网络中的设备效果图:

3.1.2 IP 地址的表现形式

说明:
-
IP 地址分为两类: IPv4 和 IPv6
-
IPv4 是目前使用的ip地址
-
IPv6 是未来使用的ip地址
-
IPv4 是由点分十进制组成
-
IPv6 是由冒号十六进制组成
IP 地址的作用:
IP 地址的作用是标识网络中唯一的一台设备的,也就是说通过IP地址能够找到网络中某台设备。
IP地址作用效果图:

3.1.3 查看 IP 地址
- Linux 和 mac OS 使用 ifconfig 这个命令
- Windows 使用 ipconfig 这个命令
说明:
ifconfig 和 ipconfig 都是查看网卡信息的,网卡信息中包括这个设备对应的IP地址

说明:
- 192.168.1.107是设备在网络中的IP地址
- 127.0.0.1表示本机地址,提示:如果和自己的电脑通信就可以使用该地址。
- 127.0.0.1该地址对应的域名是localhost,域名是 ip 地址的别名,通过域名能解析出一个对应的ip地址。
3.1.4 检查网络是否正常
- 检查网络是否正常使用 ping 命令
检查网络是否正常效果图:

说明:
- ping www.baidu.com 检查是否能上公网
- ping 当前局域网的ip地址 检查是否在同一个局域网内
- ping 127.0.0.1 检查本地网卡是否正常
3.2 端口和端口号的介绍
学习目标
- 能够说出端口和端口号的作用
3.2.1 问题思考
不同电脑上的飞秋之间进行数据通信,它是如何保证把数据给飞秋而不是给其它软件呢?
其实,每运行一个网络程序都会有一个端口,想要给对应的程序发送数据,找到对应的端口即可。
端口效果图:
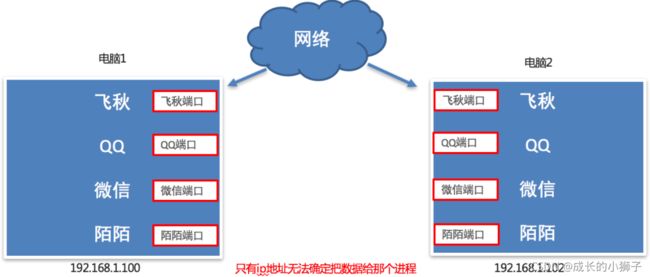
3.2.2 什么是端口
端口是传输数据的通道,好比教室的门,是数据传输必经之路。
那么如何准确的找到对应的端口呢?
其实,每一个端口都会有一个对应的端口号,好比每个教室的门都有一个门牌号,想要找到端口通过端口号即可。
端口号效果图:
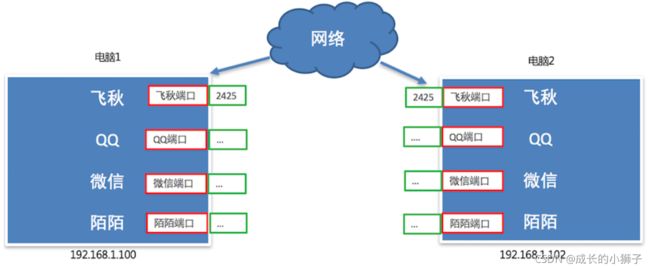
3.2.3 什么端口号
操作系统为了统一管理这么多端口,就对端口进行了编号,这就是端口号,端口号其实就是一个数字,好比我们现实生活中的门牌号。
端口号有65536个。
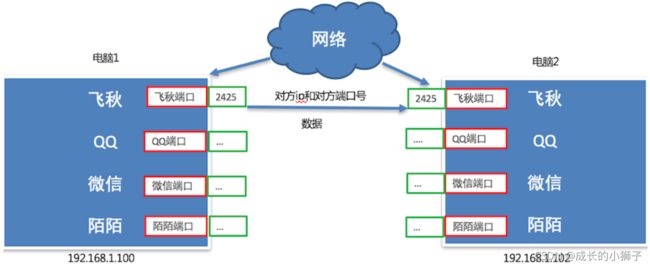
那么最终飞秋之间进行数据通信的流程是这样的,通过ip地址找到对应的设备,通过端口号找到对应的端口,然后通过端口把数据传输给应用程序。
最终通信流程效果图:
3.2.4 端口和端口号的关系
端口号可以标识唯一的一个端口。
3.2.5 端口号的分类
- 知名端口号
- 动态端口号
知名端口号:
知名端口号是指众所周知的端口号,范围从0到1023。
- 这些端口号一般固定分配给一些服务,比如21端口分配给FTP(文件传输协议)服务,25端口分配给SMTP(简单邮件传输协议)服务,80端口分配给HTTP服务。
动态端口号:
一般程序员开发应用程序使用端口号称为动态端口号, 范围是从1024到65535。
- 如果程序员开发的程序没有设置端口号,操作系统会在动态端口号这个范围内随机生成一个给开发的应用程序使用。
- 当运行一个程序默认会有一个端口号,当这个程序退出时,所占用的这个端口号就会被释放。
3.3 TCP 的介绍
学习目标
- 能够说出TCP 的特点
3.3.1 网络应用程序之间的通信流程
前面我们学习了 IP 地址和端口号,通过 IP 地址能够找到对应的设备,然后再通过端口号找到对应的端口,再通过端口把数据传输给应用程序,这里要注意,数据不能随便发送,在发送之前还需要选择一个对应的传输协议,保证程序之间按照指定的传输规则进行数据的通信, 而这个传输协议就是我们今天学习的 TCP。
3.3.2 TCP 的概念
TCP 的英文全拼(Transmission Control Protocol)简称传输控制协议,它是一种面向连接的、可靠的、基于字节流的传输层通信协议。
面向连接的效果图:

TCP 通信步骤:
- 创建连接
- 传输数据
- 关闭连接
说明:
TCP 通信模型相当于生活中的“打电话”,在通信开始之前,一定要先建立好连接,才能发送数据,通信结束要关闭连接。
3.3.3 TCP 的特点
- 面向连接
- 通信双方必须先建立好连接才能进行数据的传输,数据传输完成后,双方必须断开此连接,以释放系统资源。
- 可靠传输
- TCP 采用发送应答机制
- 超时重传
- 错误校验
- 流量控制和阻塞管理
3.4 socket 的介绍
学习目标
- 能够说出 socket 的作用
3.4.1 问题思考
到目前为止我们学习了 ip 地址和端口号还有 tcp 传输协议,为了保证数据的完整性和可靠性我们使用 tcp 传输协议进行数据的传输,为了能够找到对应设备我们需要使用 ip 地址,为了区别某个端口的应用程序接收数据我们需要使用端口号,那么通信数据是如何完成传输的呢?
使用 socket 来完成
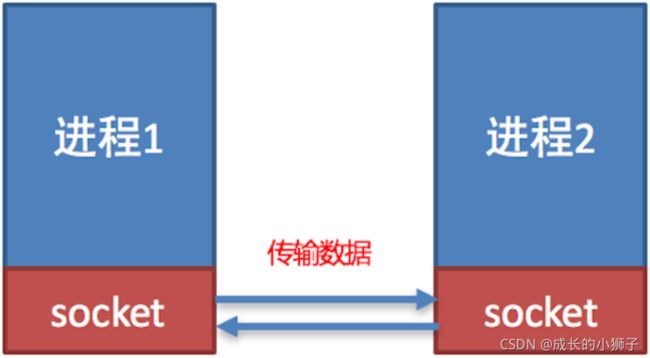
3.4.2 socket 的概念
socket (简称 套接字) 是进程之间通信一个工具,好比现实生活中的插座,所有的家用电器要想工作都是基于插座进行,进程之间想要进行网络通信需要基于这个 socket。
socket 效果图:
3.4.3 socket 的作用
负责进程之间的网络数据传输,好比数据的搬运工。
3.4.4 socket 使用场景
不夸张的说,只要跟网络相关的应用程序或者软件都使用到了 socket
3.5 TCP 网络应用程序开发流程
学习目标
- 能够知道TCP客户端程序的开发流程
3.5.1 TCP 网络应用程序开发流程的介绍
TCP 网络应用程序开发分为:
- TCP 客户端程序开发
- TCP 服务端程序开发
说明:
客户端程序是指运行在用户设备上的程序
服务端程序是指运行在服务器设备上的程序,专门为客户端提供数据服务。
3.5.2 TCP 客户端程序开发流程的介绍

步骤说明:
(1) 创建客户端套接字对象
(2) 和服务端套接字建立连接
(3) 发送数据
(4) 接收数据
(5) 关闭客户端套接字
3.5.3 TCP 服务端程序开发流程的介绍

步骤说明:
(1) 创建服务端监听套接字对象
(2)绑定端口号
(3) 设置监听
(4) 等待接受客户端的连接请求
(5) 接收数据
(6) 发送数据
(7) 关闭套接字
3.6 TCP 客户端程序开发
学习目标
- 能够写出 TCP 客户端应用程序发送和接收消息
3.6.1 开发 TCP 客户端程序开发步骤回顾
- 创建客户端套接字对象
- 和服务端套接字建立连接
- 发送数据
- 接收数据
- 关闭客户端套接字
3.6.2 socket 类的介绍
导入 socket 模块
import socket
创建客户端 socket 对象
socket.socket(AddressFamily, Type)
参数说明:
- AddressFamily 表示IP地址类型, 分为IPv4和IPv6
- Type 表示传输协议类型
方法说明:
- connect((host, port)) 表示和服务端套接字建立连接, host是服务器ip地址,port是应用程序的端口号
- send(data) 表示发送数据,data是二进制数据
- recv(buffersize) 表示接收数据, buffersize是每次接收数据的长度
3.6.3 TCP 客户端程序开发示例代码
import socket
# 创建客户端 socket 套接字对象
# socket.AF_INET:表示 IPV4
# socket.SOCK_STRAM:表示 TCP 传输协议
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 客户端请求和服务端程序建立连接
client.connect(('127.0.0.1', 8080))
print('客户端连接服务器成功!')
# 客户端向服务器发生消息
send_msg = input('请输入发送的消息:')
client.send(send_msg.encode()) # 注意:send 函数参数需要为 bytes 类型
# 客户端接收服务器响应的消息,最多接收 1024 个字节
recv_msg = client.recv(1024) # 接收的消息为 bytes 类型
print('服务器响应的消息为:', recv_msg.decode())
# 关闭客户端套接字
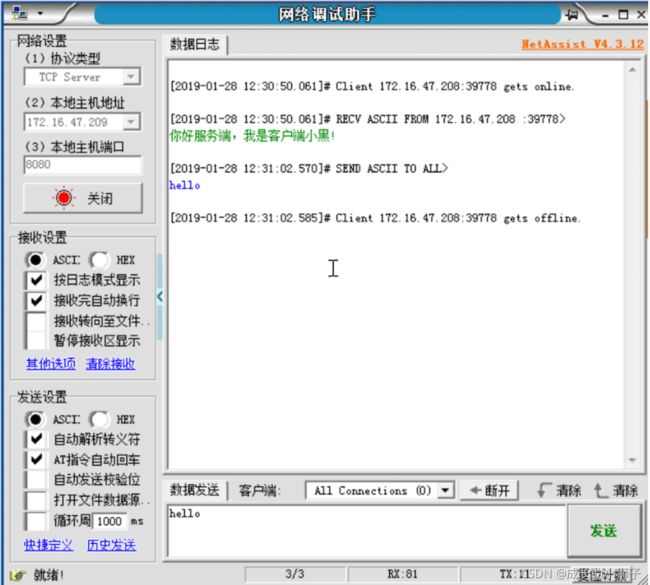
client.close()执行结果:
客户端连接服务器成功!
请输入发送的消息:hello
服务器响应的消息为: hello说明
- str.encode(编码格式) 表示把字符串编码成为二进制
- data.decode(编码格式) 表示把二进制解码成为字符串
网络调试助手充当服务端程序:
3.7 TCP服务端程序开发
学习目标
- 能够写出TCP服务端应用程序接收和发送消息
3.7.1 开发 TCP 服务端程序开发步骤回顾
- 创建服务端监听套接字对象
- 绑定端口号
- 设置监听
- 等待接受客户端的连接请求
- 接收数据
- 发送数据
- 关闭套接字
3.7.2 socket 类的介绍
导入 socket 模块
import socket
创建服务端 socket 对象
socket.socket(AddressFamily, Type)
参数说明:
- AddressFamily 表示IP地址类型, 分为IPv4和IPv6
- Type 表示传输协议类型
方法说明:
- bind((host, port)) 表示绑定端口号, host 是 ip 地址,port 是端口号,ip 地址一般不指定,表示本机的任何一个ip地址都可以。
- listen (backlog) 表示设置监听,backlog参数表示最大等待建立连接的个数。
- accept() 表示等待接受客户端的连接请求
- send(data) 表示发送数据,data 是二进制数据
- recv(buffersize) 表示接收数据, buffersize 是每次接收数据的长度
3.7.3 TCP 服务端程序开发示例代码
import socket
# 创建服务端监听套接字
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 监听套接字绑定地址和端口
server.bind(('127.0.0.1', 8080))
# 监听套接字开始监听,准备接收客户端的连接请求
server.listen(128)
print('服务器开始监听...')
# 接收客户端的连接请求
# service_client:专门和客户端通信的套接字
# ip_port:客户端的 IP 地址和端口号
service_client, ip_port = server.accept()
print(f'服务器接收到来自{ip_port}的请求')
# 接收客户端发送的消息,最多接收 1024 给字节
recv_msg = service_client.recv(1024) # 接收的消息为 bytes 类型
print('客户端发送的消息为:', recv_msg.decode())
# 给客户端发送响应消息
send_msg = input('请输入响应的消息:')
service_client.send(send_msg.encode())
# 关闭和客户端通信的套接字
service_client.close()
# 关闭服务器监听套接字
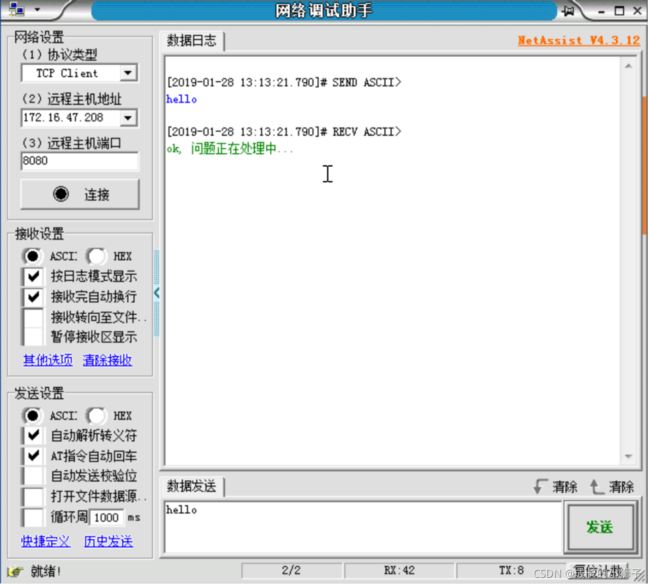
server.close()执行结果:
服务器开始监听...
服务器接收到来自('127.0.0.1', 54424)的请求
客户端发送的消息为: hello
请输入响应的消息:hello说明:
当客户端和服务端建立连接后,服务端程序退出后端口号不会立即释放,需要等待大概1-2分钟。
解决办法有两种:
(1) 更换服务端端口号
(2) 设置端口号复用(推荐大家使用),也就是说让服务端程序退出后端口号立即释放。
设置端口号复用的代码如下:
# 参数1: 表示当前套接字
# 参数2: 设置端口号复用选项
# 参数3: 设置端口号复用选项对应的值
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)网络调试助手充当客户端程序:
3.8 TCP网络应用程序的注意点
学习目标
- 能够说出开发TCP网络应用程序的注意点
TCP网络应用程序的注意点介绍
(1) 当 TCP 客户端程序想要和 TCP 服务端程序进行通信的时候必须要先建立连接
(2) TCP 客户端程序一般不需要绑定端口号,因为客户端是主动发起建立连接的。
(3) TCP 服务端程序必须绑定端口号,否则客户端找不到这个 TCP 服务端程序。
(4) listen 后的套接字是被动套接字,只负责接收新的客户端的连接请求,不能收发消息。
(5) 当 TCP 客户端程序和 TCP 服务端程序连接成功后, TCP 服务器端程序会产生一个新的套接字,收发客户端消息使用该套接字。
(6) 关闭 accept 返回的套接字意味着和这个客户端已经通信完毕。
(7) 关闭 listen 后的套接字意味着服务端的套接字关闭了,会导致新的客户端不能连接服务端,但是之前已经接成功的客户端还能正常通信。
(8) 当客户端的套接字调用 close 后,服务器端的 recv 会解阻塞,返回的数据长度为0,服务端可以通过返回数据的长度来判断客户端是否已经下线,反之服务端关闭套接字,客户端的 recv 也会解阻塞,返回的数据长度也为0。
04 扩展阅读-多任务版TCP服务端程序开发
学习目标
- 能够说出多任务版TCP服务端程序的实现过程
4.1 需求
目前我们开发的TCP服务端程序只能服务于一个客户端,如何开发一个多任务版的TCP服务端程序能够服务于多个客户端呢?
完成多任务,可以使用线程,比进程更加节省内存资源。
4.2 具体实现步骤
- 编写一个TCP服务端程序,循环等待接受客户端的连接请求
- 当客户端和服务端建立连接成功,创建子线程,使用子线程专门处理客户端的请求,防止主线程阻塞
- 把创建的子线程设置成为守护主线程,防止主线程无法退出。
4.3 多任务版TCP服务端程序的示例代码:
import socket
import threading
# 处理客户端的请求操作
def handle_client_request(service_client_socket, ip_port):
# 循环接收客户端发送的数据
while True:
# 接收客户端发送的数据
recv_data = service_client_socket.recv(1024)
# 容器类型判断是否有数据可以直接使用if语句进行判断,如果容器类型里面有数据表示条件成立,否则条件失败
# 容器类型: 列表、字典、元组、字符串、set、range、二进制数据
if recv_data:
print(recv_data.decode("gbk"), ip_port)
# 回复
service_client_socket.send("ok,问题正在处理中...".encode("gbk"))
else:
print("客户端下线了:", ip_port)
break
# 终止和客户端进行通信
service_client_socket.close()
if __name__ == '__main__':
# 创建tcp服务端套接字
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置端口号复用,让程序退出端口号立即释放
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# 绑定端口号
tcp_server_socket.bind(("", 9090))
# 设置监听, listen后的套接字是被动套接字,只负责接收客户端的连接请求
tcp_server_socket.listen(128)
# 循环等待接收客户端的连接请求
while True:
# 等待接收客户端的连接请求
service_client_socket, ip_port = tcp_server_socket.accept()
print("客户端连接成功:", ip_port)
# 当客户端和服务端建立连接成功以后,需要创建一个子线程,不同子线程负责接收不同客户端的消息
sub_thread = threading.Thread(target=handle_client_request, args=(service_client_socket, ip_port))
# 设置守护主线程
sub_thread.setDaemon(True)
# 启动子线程
sub_thread.start()
# tcp服务端套接字可以不需要关闭,因为服务端程序需要一直运行
# tcp_server_socket.close()执行结果:
客户端连接成功: ('172.16.47.209', 51528)
客户端连接成功: ('172.16.47.209', 51714)
hello1 ('172.16.47.209', 51528)
hello2 ('172.16.47.209', 51714)4.4 小结
(1) 编写一个TCP服务端程序,循环等待接受客户端的连接请求
while True:
service_client_socket, ip_port = tcp_server_socket.accept()(2) 当客户端和服务端建立连接成功,创建子线程,使用子线程专门处理客户端的请求,防止主线程阻塞
while True:
service_client_socket, ip_port = tcp_server_socket.accept()
sub_thread = threading.Thread(target=handle_client_request, args=(service_client_socket, ip_port))
sub_thread.start()(3) 把创建的子线程设置成为守护主线程,防止主线程无法退出。
while True:
service_client_socket, ip_port = tcp_server_socket.accept()
sub_thread = threading.Thread(target=handle_client_request, args=(service_client_socket, ip_port))
sub_thread.setDaemon(True)
sub_thread.start()