Python+Selenium4元素定位_web自动化(3)
目录
0. 上节回顾
1. 八大定位
2. 定位器
3. CSS选择器
4. XPath选择器
4.1. XPath语法
4.2. XPath 函数
5. 相对定位
5.1 XPath 中的相对定位【重点】
5.1.1 相对路径
5.1.2 轴
5.2 selenium4 中的相对定位
总结
0. 上节回顾
- 浏览器的一般操作
- 浏览器的高级操作:窗口切换
- 启动参数:最大化、无头模式、设置代理,通过options参数进行传递
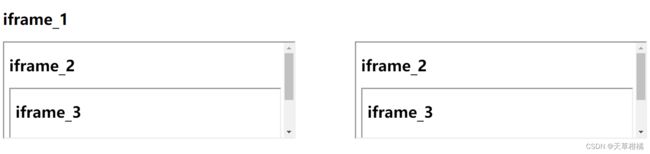
with get_webdriver() as driver:
driver.get("http://118.24.147.95:8086/iframe_1.html")
# 刚打开网页
h2 = driver.find_element(By.TAG_NAME, "h2")
print("a", h2.tag_name, h2.text)
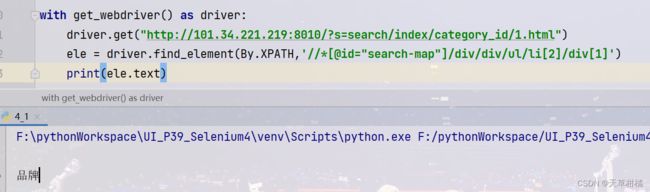
iframe = driver.find_element(By.XPATH, '//*[@id="you_frame"]')
driver.switch_to.frame(iframe) # 完成一次iframe的切换
h2 = driver.find_element(By.TAG_NAME, "h2")
print("右侧b", h2.tag_name, h2.text)
iframe = driver.find_element(By.XPATH, '//*[@id="my_frame"]')
driver.switch_to.frame(iframe) # 又完成一次iframe的切换
h2 = driver.find_element(By.TAG_NAME, "h2")
print("右侧c", h2.tag_name, h2.text)
# driver.switch_to.parent_frame() # 返回上一次层iframe
# driver.switch_to.default_content() # 返回顶层frame
# h2 = driver.find_element(By.TAG_NAME, "h2")
print("d", h2.tag_name, h2.text) 任何元素都是可以被定位到的,没有例外!
操作WEB应用程序上的元素,首先是要定位到元素。
Selenium的WebDriver类提供了find_element和find_elements方法对元素进行定位。
当找到元素后,会返回一个WebElement对象,如果找不到元素,则会报NoSuchElementException异常。
find_element和find_elements的第一个参数是元素定位策略,第二个参数是对应策略需要的值。
# id定位,属性 + 操作 = webELement1. 八大定位
在 WebDriver 中提供 8 中不同的定位策略
- ID : 根据元素的ID属性进行定位
- NAME: 根据元素的NAME属性进行定位
- TAG_NAME: 根据元素的标签名进行定位
- CLASS_NAME:根据元素的class属性进行定位(不可使用复合类名 submit am-btn )
with get_webdriver() as driver:
driver.get("http://101.34.221.219:8010/")
# 根据元素的ID属性进行定位
# ele = driver.find_element(By.ID, "search-input")
# print("定位到的元素", ele.tag_name, ele.text)
# 根据元素的NAME属性进行定位
# ele = driver.find_element(By.NAME, "wd")
# print("定位到的元素", ele.tag_name, ele.text)
# 根据元素的标签名进行定位
# ele = driver.find_element(By.TAG_NAME, "input")
# print("定位到的元素", ele.tag_name, ele.text)
# ele = driver.find_element(By.CLASS_NAME, "submit am-btn") # 定位失败 不可使用复合类名
ele = driver.find_element(By.CLASS_NAME, "submit") # 定位成功
print("定位到的元素", ele.tag_name, ele.text)- LINK TEXT : 根据标签TEXT,定位A标签 (精确匹配)
- PARTIAL_LINK_TEXT : 根据标签 部分 TEXT,定位A标签 (模糊匹配)
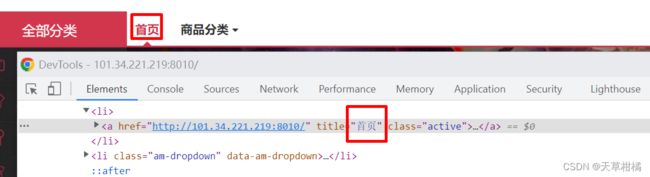
ele = driver.find_element(By.LINK_TEXT, "首页") # 输入完整的TEXT,精确匹配
print("定位到的元素", ele.tag_name, ele.text)
ele = driver.find_element(By.PARTIAL_LINK_TEXT, "首") # 输入部分的TEXT, 模 糊匹配
print("定位到的元素", ele.tag_name, ele.text)- CSS_SELECTOR
ele = driver.find_element(By.CSS_SELECTOR,"#search-input")
print(ele.tag_name)- XPATH
思考:
1. 哪些定位策略不会被转为 CSS 选择器,会被直接使用?
- CSS
- XPATH
- LINK TEXT : 只能定位A标签,局限性很大
- PARTIAL_LINK_TEXT: 只能定位A标签,局限性很大
2. 在浏览器底层, CSS 和 XPATH 有什么区别?
2. 定位器
- find_element 返回单个元素
- find_elements 返回多个元素, 通过列表返回的
3. CSS选择器
CSS 是前端开发工程师,必备的技能,也是浏览器必备的能力
扩展资料:
https://developer.mozilla.org/zh-CN/docs/Web/CSS/CSS_Selectors
https://www.w3school.com.cn/cssref/css_selectors.asp
测试工程师,至少掌握以下几种:
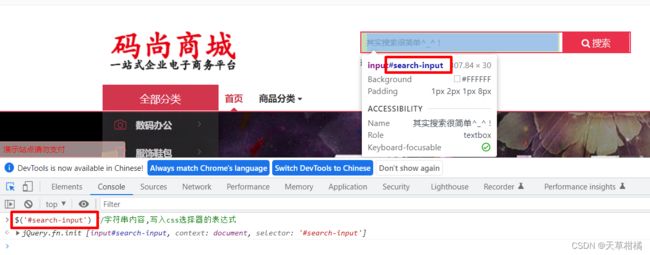
- ID选择器
#ID
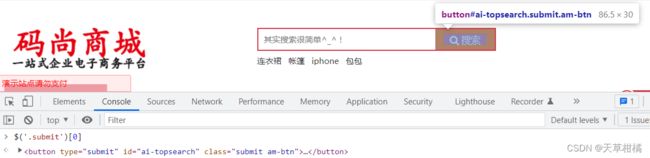
- CLASS选择器
.class
- 元素选择器
input
- 属性选择器
input[id=search-input]
- 通配选择器
- 层次选择器
#goods-category > div > div > div > ul >li

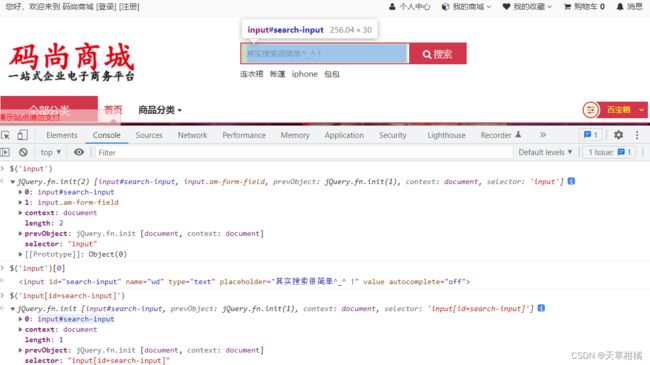
调试工具:Chrome的开发者工具, 通过 $() 执行CSS选择器的表达式
#search-input
对于CSS选择器来说,定位步骤如下:
1. 在开发者工具中,选中元素
2. 右键 - 复制 - 复制 CSS 选择器
3. 在开发者工具 - 控制台,对表达式进行调优 (可选项)

对于长的选择器 可以优化 如下:找其父节点进行选择


ele = driver.find_element(By.CSS_SELECTOR,
#"body > div.nav-search.white.am-hide-sm-only > div > div.search-bar > form"
".search-bar > form")
print(ele.tag_name)4. XPath选择器
XPATH 是 "XML 路径查询语言 " , 是 W3C 标准: https://docs.microsoft.com/en-us/previous-versions/dotnet/netframework-4.0/ms256115(v=vs.100)
XPATH 优势:
- 支持逻辑表达式
- 内置函数
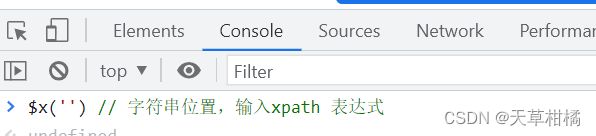
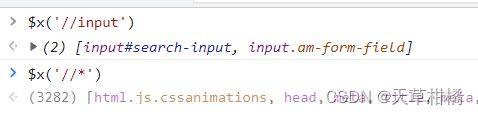
在 Chrome 开发者工具 - 控制台,使用 $x() 执行 XPath 表达式
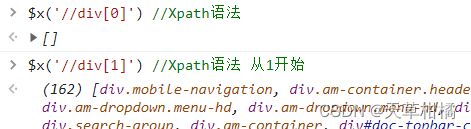
4.1. XPath语法
层级表示
/html/body/div
- / (开头) 根路径
- / (中间)下一级
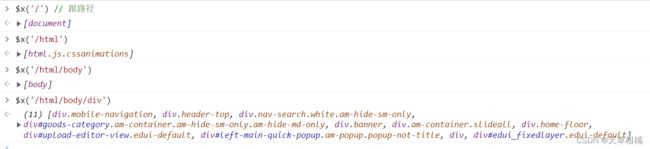
- // 任一级

属性表示
- @ 属性
- id
- name
- class
- 。。。。

位置表示
- 从1开始
- 没有-1
元素表示
- 直接写元素名
- * 代表所有的元素
SQL 不需要手写
CSS 不需要手写
XPATH 不需要手写
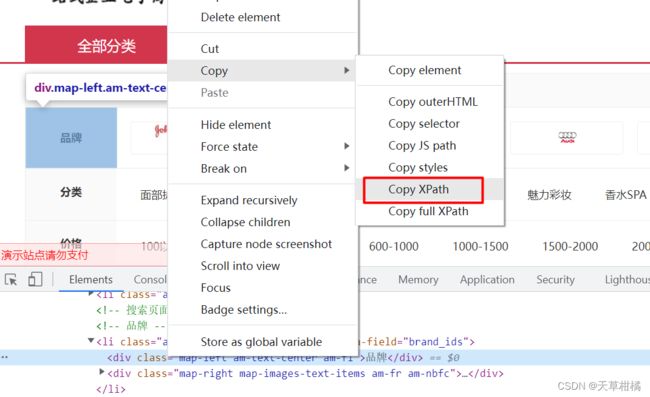
对于 XPATH 选择器来说,定位步骤如下:
1. 在开发者工具中,选中元素
2. 右键 - 复制 - 复制 XPATH
3. 在开发者工具 - 控制台,对表达式进行调优 (可选项)
 4.2. XPath 函数
4.2. XPath 函数
所有的函数 : https://www.w3school.com.cn/xpath/xpath_functions.asp
常用的函数 :
- text $x('//div[text()="iphoneX新品发布了"]')
- contains
- starts-with $x('//img[starts-with(@alt,"Meizu/魅族")]')
- ends-with
- last
with get_webdriver() as driver:
driver.get("http://101.34.221.219:8010/")
ele0 = driver.find_element(By.XPATH, '//img[@alt="Meizu/魅族 MX4 Pro移动版 八核大屏智能手机 黑色 16G"]')
print(ele0.tag_name)
# // 任意曾经进行搜索
# img 搜索img 元素
# contains(@alt,"vivo X5MAX") alt属性中,包含了"Meizu/魅族"的元素
ele = driver.find_element(By.XPATH, '//img[contains(@alt,"Meizu/魅族")]')
print(ele.tag_name)5. 相对定位
5.1 XPath 中的相对定位【重点】
四字口诀:父子兄弟
5.1.1 相对路径
相对路径 代表相对于当前节点的 单个节点
./ 子元素
../ 父元素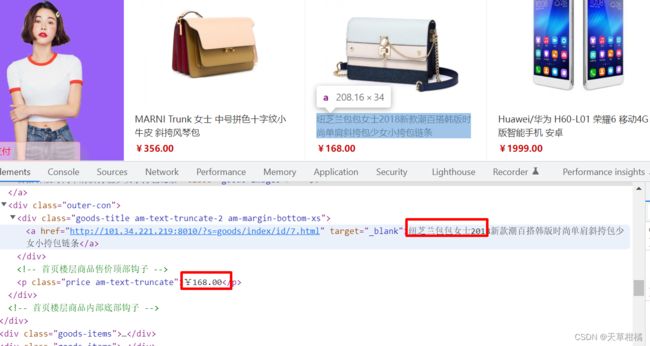
需求: 定位到商品名称 和金额
# 不使用相对定位
name = driver.find_element(
By.XPATH, '//*[@id="floor2"]/div[2]/div[2]/div[6]/div/div/a'
)
price = driver.find_element(
By.XPATH, '//*[@id="floor2"]/div[2]/div[2]/div[6]/div/p'
)
print(name.text, price.text)
# 使用了相对定位
ele = driver.find_element(By.XPATH,'//*[ @ id = "floor2"]/div[2]/div[2]/div[6]/div') # 定位共同父元素
name1 = ele.find_element(By.XPATH, ".//a") # 使用相对定位
price1 = ele.find_element(By.XPATH, ".//p") # 使用相对定位5.1.2 轴
轴定位 代表相对于当前节点的 N个节点
|
轴名称
|
结果
|
|
following
|
自身之前的所有元素
|
|
preceding
|
自身之后的所有元素
|
|
ancestor
|
所有先辈(父、祖父等)
|
|
ancestor-or-self
|
所有先辈(父、祖父等)以及自身
|
|
parent
|
父节点
|
|
preceding-sibling
|
所有兄节点
|
|
self
|
自身
|
|
following -sibling
|
所有弟节点
|
|
child
|
所有子元素
|
|
descendant-or-self
|
所有后代元素(子、孙等)以及当前节点本身
|
|
descendant
|
所有后代元素(子、孙等)
|
![]()
with get_webdriver() as driver:
driver.get("http://101.34.221.219:8010/")
name = driver.find_element( By.XPATH, '//*[@id="floor2"]/div[2]/div[2]/div[6]/div/div/a' )
price = name.find_element(By.XPATH, "ancestor::*[2]/p")
# ancestor,所有的祖先,爸爸最近,爷爷第二。。。。。。
# ::轴的语法
# * 所有类型的祖先
# [2] 距离第二近
# /下一级
# p 定位p元素
print(name.text, price.text)
5.2 selenium4 中的相对定位
四字口诀:上下左右
工作中不要使用
|
相对定位器
|
作用
|
|
above
|
在指定元素上方进行搜索
|
|
below
|
在指定元素下方进行搜索
|
|
to_left_of
|
在指定元素左侧进行搜索
|
|
to_right_of
|
在指定元素右侧进行搜索
|
|
near
|
在指定元素附近( 50px )进行搜索
|
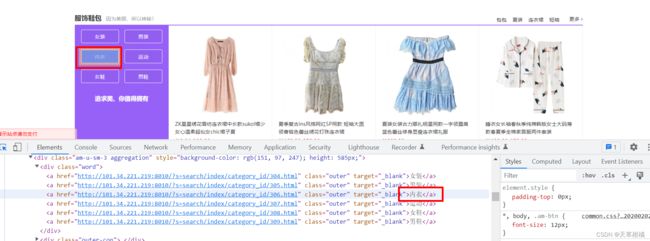
driver = webdriver.Chrome() # 启动浏览器 是空白页
driver.get("http://101.34.221.219:8010/")
# 定位 内衣
ele = driver.find_element(By.XPATH, '//*[@id="floor2"]/div[2]/div[1]/div[1]/a[3]')
# 定位 ele 上方 a 标签
n_ele = driver.find_element(locate_with(By.TAG_NAME, "a").above(ele))
assert n_ele.text == "女装"
# 定位 ele 下方 a 标签
n_ele = driver.find_element(locate_with(By.TAG_NAME, "a").below(ele))
assert n_ele.text == "女鞋"
# 定位 ele 右边 a 标签
n_ele = driver.find_element(locate_with(By.TAG_NAME, "a").to_right_of(ele))
assert n_ele.text == "运动" 原理:通过 JS 代码,遍历附近所有元素的 rect( 坐标和大小 ), 然后进行元素筛选定位
优势: 根据元素实际展示效果进行定位,不关系具体层级
弊端:效率低下,准确的低、通用性差,很多时候无法按照预期进行工作
总结
- 从selenium 的角度,定位有八种策略
- 从浏览器的角度,定位有2种选择器
- CSS选择器, 通用性好,执行效率高,是selenium 推荐的选择器
- XPATH选择器,效率高,有很多的函数,用法灵活
- 底层都是通过JS实现的
- 相对定位:
- XPath 相对定位:能用
- selenium4 相对定位: 不能用
实际项目中,一般统一封装为 XPATH 选择器