10、32位 x86处理器编程架构
10.1、IA-32架构的基本执行环境
10.1.1、寄存器的扩展
8个通用寄存器的扩展:
(AX、BX、CX、DX) 16位 -> 32位 (EAX、EBX、ECX、EDX)
(SI、DI、BP、SP) 16位 -> 32位 (ESI、EDI、EBP、ESP)
AH、AL..DH、DL仍然可以用
IP扩展:
IP 扩展到了 32 位,即 "EIP"
标志寄存器FLAGE扩展:
FLAGE 扩展到了 32 位,即 "EFLAGS",低 16 位和原先保持一致
指令的源操作数和目的操作数必须具有相同的长度;(错:mov eax,cx)
低16位保持同16位处理器的兼容性,但高16位是不可独立使用;
本书中,32 位模式特指 32 位保护模式;
处理器可以使用它全部的 32 根地址线,即能够访问 4GB 内存(2^32=4G)
32 根地址线,可以自由访问4G内存的任何一个位置,IA-32 架构的处理器仍是基于分段模型
可以只分一个段,段的基地址是 0x00000000,段的长度是 4GB,可以视为不分段,即平坦模型(Flat Mode)。
⭐️ 保护模式
在 32 位模式(保护模式)下,处理器在加载程序时,要求先定义该程序所拥有的段,然后才允许使用这些段。
定义段时,除了"基地址"(起始地址)外,还附加"段界限"、"特权级别"、"类型"等属性。
访问段时,处理器将用固件实施各种检查工作,以防止对内存的违规访问。
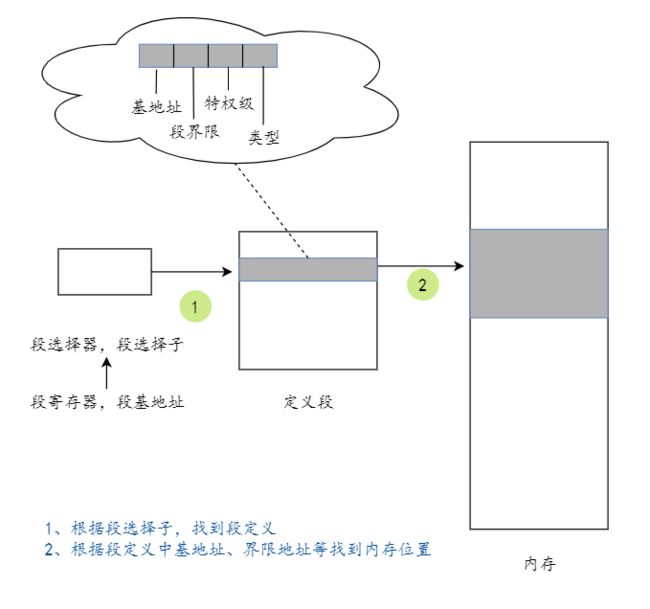
问题
1、访问某个段时,处理器使用固件实施各种检查的过程是什么?
访问的内存是否超过段描述符定义的界限;
是否有权限访问该段;
10.1.2、基本的工作模式
80286
|-第一次提出保护模式
|-段地址:真正的段地址位于寄存器的描述符高速缓存(24位)中,可访问16MB
|-段内偏移地址:通用寄存器仍然是16位的,所以段的最长为64KB
80386
|-段地址:32位
|-段内偏移地址:32位
不存在32位实模式,实模式的概念实质是8086模式
10.1.3、线性地址
逻辑地址:段地址 + 偏移地址(也称有效地址)
段管理由处理器的"段部件"负责;
"段部件"将段地址和偏移地址相加,得到访问内存的物理地址;
IA-32处理器支持多任务、支持分页功能;
分页功能:将物理内存划分成逻辑上的页,页大小固定;
页功能开启后,段部件产生的地址就不是内存物理地址了,而是线性地址,线性地址还需要经页部件转换变成物理地址
线性地址空间:
IA-32处理器上的"每个任务"都拥有4G的虚拟空间,这段长4GB的平坦空间,就像一段平直的线段,因此叫做线性地址空间

10.2、 现代处理器的结构和特点
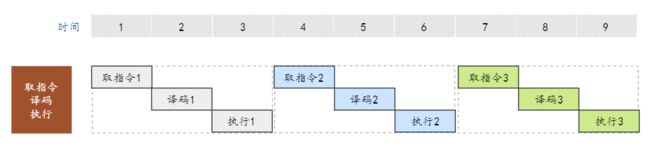
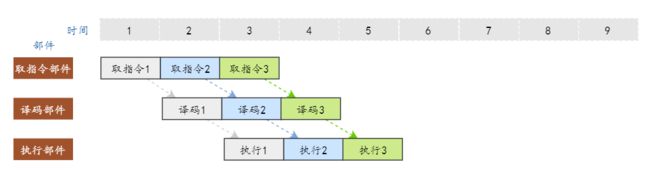
10.2.1 流水线
流水线(Pipe-Line)技术,执行指令的方法
|-把一条指令的执行过程分解成若干个细小的步骤;
|-并把各步骤分配给相应的单元来完成,各个单元的执行是独立的、并行的;
|-各个步骤的执行在时间上就会重叠起来;
10.2.2 高速缓存
高速缓存(SRAM)位于处理器与内存(DRAM)之间,速度可以与CPU匹配;
各个存储的速度
|-数据位于寄存器,1个时钟周期内就可以访问到(超音速飞机1200km/h)
|-数据位于高速缓存,4~75个时钟周期可以访问到(高铁300km/h)
|-数据位于内存,上百个周期可以访问到(步行6km/h)
|-数据位于磁盘,大约几千万个周期(0.6毫秒/h)
作为一个程序员,你需要理解存储器层次结构,因为它对应用程序的性能有着巨大的影响。
如果你的程序需要的数据是存储在 CPU 寄存器中的,那么在指令的执行期间个周期内就能访问到它们。
如果存储在高速缓存中,需要 4~75 个周期。
如果存储在主存中,需要上百个周期。而如果存储在磁盘上,需要大约几千万个周期!
参考: 深入理解计算机系统 -第6章
处理器要访问内存过程
|-1、首先检索高速缓存;
|-2、Hit命中:如果要访问的内容已经在高速缓存中,那么直接从高速缓存中取得
|-3、Miss不中:要访问的内容不在Cache中,处理器在取得需要的内容之前必须重新装载Cache
"Cache装载单位":
高速缓存的装载是以块为单位的,包括那个所需数据的邻近内容。
"不中惩罚":
花费额外的时间来等待块从内存载入高速缓存的时间称为不中惩罚(Miss Penalty)
10.2.3 乱序执行
将指令拆分成微操作,处理器就可以在必要的时候乱序执行程序以提升性能;
例:
add eax,[mem],拆分成2个微操作
|-1、从内存读取数据放入临时寄存器
|-2、EAX和临时寄存器数值相加
add [mem],eax, 拆分成3个微操作
|-1、内存中读数据
|-2、执行相加的动作
|-3、相加的结果写回到内存
举例说明,下面两条指令
push eax
call func
call指令需要压栈下条指令地址,所以他必须等待push指令执行完,如下图

将push指令拆分成微指令
push eax
|-sub esp,4
|-mov [esp],eax
call func
执行过程如下图
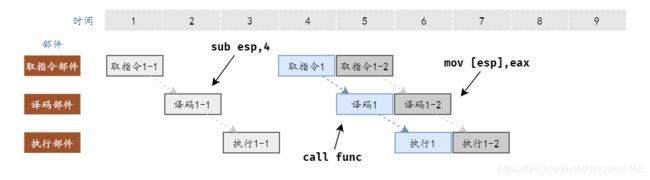
从上图可以看出,拆分成微指令后,可以乱序执行(也可以不乱序);
本质上提升了流水线并行度;
乱序执行的前提是不改变运行结果;
10.2.4 寄存器重命名
IA-32 架构的处理器内部还有大量的临时寄存器,处理器可以重命名这些寄存器以代表一个逻辑寄存器。
寄存器重命名
重命名处理器中的临时寄存器,代替指令中使用的寄存器,达到"乱序执行"的目的,从而提升性能;
寄存器重命名是处理器自动完成的;
比如先后执行两个不相干的功能(功能1、功能2),这两个功能使用了相同的寄存器,此时就可以重命名功能2中的寄存器,
从而让功能1和功能2并行执行
所有通用寄存器,堆栈指针、标志、浮点寄存器,甚至段寄存器都有可能被重命名;
10.2.5 分支预测
"分支预测"就是记录本次进入的目标分支,下次执行相同分支时,进入一样的目标分支;
流水线最大的问题是代码中经常存在分支,已经进入流水线的指令可能就无效了;
1996年Intel Pentiem Pro 引入分支预测技术来解决流水线中的分支问题;
"处理器内部,有一个小容量的高速缓存器,叫分支目标缓存器(Branch Target Buffer,BTB)。
BTB用来记录当前指令的地址、分支目标的地址,以及本次分支预测的结果。
预测失败则清空流水线,同时刷新BTB;
10.3、 32位模式的指令系统
10.3.1、 32 位处理器的寻址方式
32 位处理器兼容 16 位处理器的工作模式
32 位处理器有独立的 32 位运行模式
32位处理器寻址
|-内存地址操作数默认是32位
|-立即数默认是32位(mov ecx,0x55 ;ECX←0x00000055 )
错误:mov ax,[sp]
正确:mov eax,[esp]
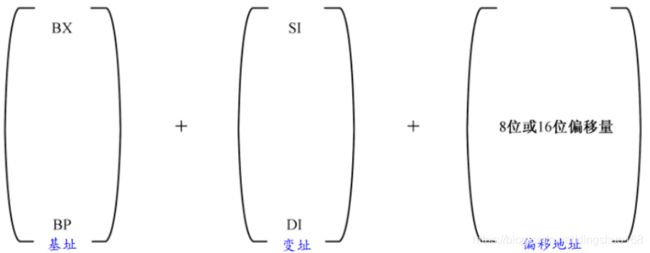
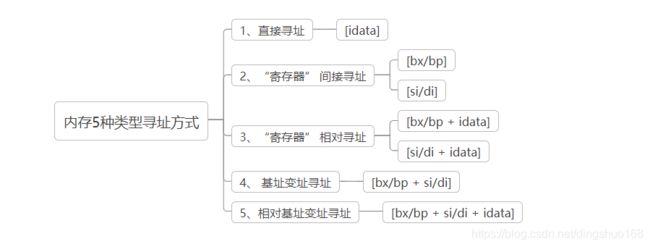
(1)32位处理器寻址

(2)16位处理器寻址
10.3.2、 操作数大小的指令前缀-0x66
Intel指令系统比较复杂,原因:
|-指令多
|-寻址方式多
前缀指令
|-重复前缀(例 rep)
|-段超越前缀(例 es:)
|-总线封锁前缀(例 lock)
前缀指令长度1个字节;
每条指令都可以拥有0-4条前缀指令
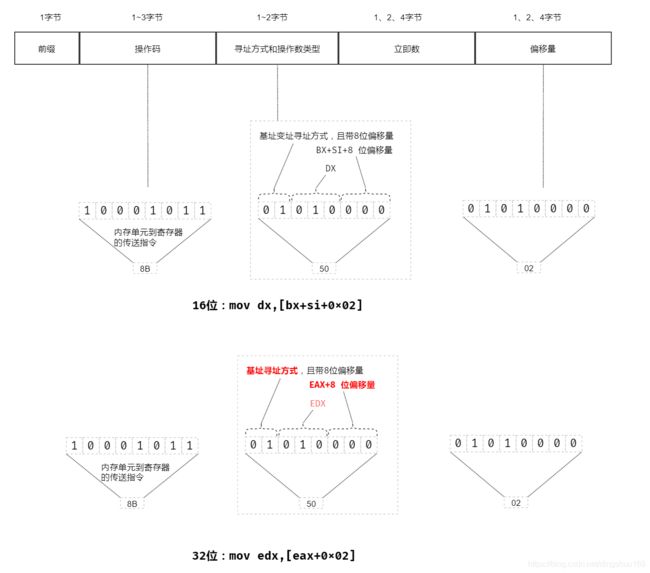
从下图可知,相同的指令,在32位模式下和16位模式下对指令的解析和执行效果是不同的;
可以使用伪指令bits来提示编译器按照16模式还是32位模式来编译
前缀指令0x66 用来在16位/32位模式间进行切换,例:
// ----------------------------------------
bits 16
mov cx,dx ;89 D1
mov eax,ebx ;66 89 D8 ,16位下使用前缀0x66来使用32位寄存器
// ----------------------------------------
bits 32
mov cx,dx ;66 89 D1 ,32位下使用前缀0x66来使用16位寄存器
mov eax,ebx ;89 D8
10.3.3、 一般指令的扩展
add指令
add al,bl
add ax,bx
;// 32位
add eax,ebx
add dword [ecx],0x0000005f
逻辑移动指令(shl、shr等)
|-源操作数如果是寄存器,则必须使用CL(32位和16位一样,因为cl足够表达移动的位数)
shl eax,1
shl eax,9
shl dword [eax*2+0x08], cl
loop
|-16位模式下,循环次数在cx中
|-32位模式下,循环次数在ecx中;// 32位
mul
|- mul r/m8 ; AX ← AL×r/m8
|- mul r/m16 ; DX:AX ← AX×r/m16
|- mul r/m32 ; EDX:EAX ← EAX×r/m32;// 32位
multiply
|- 两个数相乘的位数相同(32/16/8位)
|- 被乘数,放在eax/ax/al中(不必指定)
|- 乘数,放在寄存器或内存单元;
|- 结果,放在"EDX:EAX"或"dx:ax"或"ax"
div/idiv
|-除数是32位;// 32位
|-被除数则为64位,高32位在EDX寄存器;低32位在EAX寄存器
|-除数位于32位的寄存器 或 存放有32位实际操作数的内存地址
push/pop
|-
|-
push
[处理器都不会真的压入一字节,要么压入字,要么压入双字]
|-push byte 0x55 ;// 16/32位下的机器码都是 6A 55
|- 16位模式下
|-sp = sp-2
|-压入字0x0055
|- 32位模式下
|-esp = esp-4
|-压入双字0x00000055
|-push dword 0x55
|- 16、32位模式下
|-sp/esp = sp/esp-4
|-压入双字0x00000055
|-push r/m
|-word指定的内存/16位寄存器
|-sp = sp-2
|-压入字
|-dword指定的内存/32位寄存器
|-esp = esp-4
|-压入双字
|-push 段寄存器
|-16位模式下
|-sp = sp-2
|-压入段寄存器内容
|-32位模式下
|-esp = esp-4
|-段寄存器的内容用零扩展到32位,即高16位为全零
|-压入扩展后的32位内容