内存一致性模型指南
Memory Consistency Models: A Tutorial(内存一致性模型指南)
The cause of, and solution to, all your multicore performance problems.
计算机科学里有几个比较困难的问题:缓存失效、命名、off-by-one errors。除此之外还有事件排序问题,以一定的顺序观察事件是一件很具有挑战性的事情。
内存一致性模型用来描述事件排序,定义多个并行线程之间如何以一定的顺序观察共享内存的状态变化。有很多讨论内存一致性的资料,但是大多数要么是幻灯片要么出自《A Primer on Memory Consistency and Cache Coherence》这本书。我的目标就是就是尽量阐述为什么对于多处理器系统而言内存一致性为什么会如此重要。更详细的问题可以查看其他更优秀的资料。
Making threads agree
一致性模型用来表示多个线程如何看待这个世界。考虑如下程序片段:
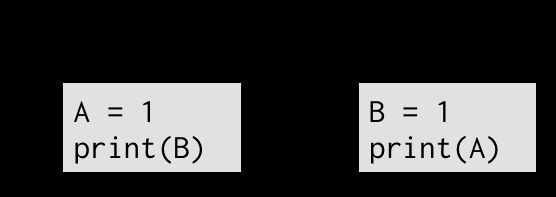
为了搞清楚这个程序的输出,我们必须考虑事件的执行顺序。凭感觉来说这个程序有两种执行路径:
- (1) → (2) → (3) → (4): 输出01.
- (3) → (4) → (1) → (2): 输出01.
还有两种交叉执行的可能: - (1) → (3) → (2) → (4): 输出11.
- (1) → (3) → (4) → (2): 输出11.
- 其他执行顺序也是相同的输出。
Things that shouldn’t happen(不应该发生的事情)
直觉上来讲,这个程序不会输出00。为了让(2)输出0,(2)必须在(3)之前执行,我们可以画一条箭头从(2)指向(3)。
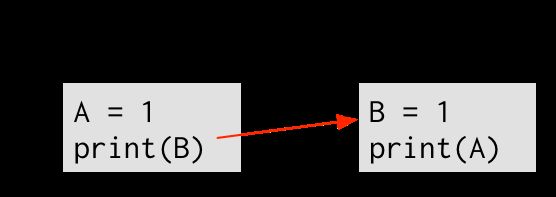
一条从x指向y的箭头表明,x先于y执行。同样地,为了(4)输出0,(4)必须先于(1)执行。如下图:
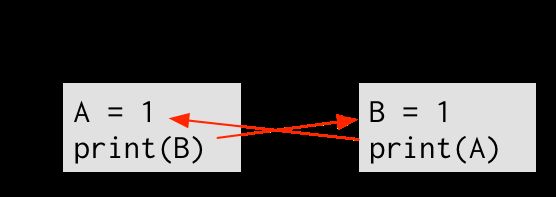
最后,每个线程的执行路径按照程序指定的顺序执行——(1) 先于 (2),(3) 先于 (4)。最后得到下图:
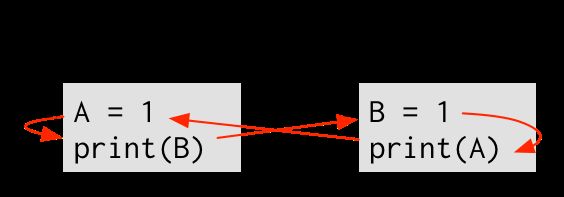
如果我们从(1)开始执行,然后顺着箭头的方向执行的话,到 (2), 然后 (3), 再然后 (4), 最后又到了 (1)!这个图表示(1)先于(1)执行。除非物理学有重大研究突破,否则,这是不可能的!
因为这个执行路径需要时间扭曲,所以我们可以得出结论,这个程序不可能输出00.我们使用反证法来进行论证:假设这个程序可以输出00,那么我们刚才列出的排列规则一定会遵守,但是通过这个规则我们得出(1)先于(1)执行。所以,假设是错误的。
Sequential consistency: an intuitive model of parallelism(顺序一致性:一个直观的并行模型)
架构师和语言设计者希望我们上面列举的规则对于软件开发人员来说是通俗易懂的。核心思想就是在单个主内存的计算机系统中并行执行多个线程,这些线程的执行事件一定是有序进行的。如果两个事件同时访问主存的话,那么这两个事件不可能同时执行。
这个规则没有规定全局的事件到底以什么样的顺序执行,但是规定了在一个线程内,事件肯定是按照程序指定的顺序(program order)执行,这肯定是程序员期望的,因为不可能在不检查钥匙之前就直接发送导弹。
所以,一个共享内存和程序顺序(program order)共同定义了顺序一致性。定义顺序一致性是Leslie Lamport在2013.1年获得图灵奖的众多成就之一(尽管Lamport刚开始是研究多核系统,但是之后他的工作方向变成了分布式系统,在当前的分布式系统场景中的sequential consistency与架构师所期望的sequential consistency模型不太一样,甚至可能还要弱一点。架构师期望的sequential consistency可能是分布式系统中现在使用的“linearizability”模型)。
顺序一致性是内存模型的第一个例子。内存一致性模型(通常叫做内存模型)定义了多线程在多核心处理器上执行时,事件被允许执行的顺序。比如上面的程序,顺序一致性模型禁止输出00结果,但是允许出现01和11两个结果。
内存模型是硬件和软件之间的契约。硬件只会按照内存模型允许的顺序重新排列事件,相应地,软件也会考虑所有事件可以执行的可能性。
The problem with sequential consistency(顺序一致性的一些问题)
理解顺序一致性的一个更好的方法就是转换器(switch)。每一个时钟周期,转换器选择一个线程执行,然后执行线程的下一个事件。这个实例保持了顺序一致性的两个原则:事件只访问了一个主内存,并且都是按照程序规定的顺序访问。
这个模型非常的低效。我们在同一个时刻只能执行一条指令,所以我们不能发挥多线程带来的并行优势。更糟糕的是,我们只能等待一条指令执行完成并且修改的数据对其他线程都可见之后才可以执行下一条指令。
Coherence(缓存一致性)
有些时候,等待是非常有必要的。考虑如下场景,两个线程想要往A变量写入数据,并且第三个线程打算读取这个变量:

如果我们不规定只有一个主存并且允许(1) 和 (2) 并行执行,我们无法确定(3)能读取到什么数据。一个主存可以保证两个写事件只能有一个成功。如果没有这个前提的话,(1) 和 (2)同时发生,我们能同时看到1和2。
Coherence保证对一个内存位置的所有写操作,在所有线程看来顺序都是一样的。但是不能规定哪个事件先执行((1)先执行或者(2)先执行),但是可以保证同一时刻所有的线程看到的写事件都是一个。
Relaxed memory models
不考虑一致性(Coherence)的话,完全不用限制只有一个内存。考虑如下程序:
事件(2)没必要等待事件(1)完成。这两个事件没有任何交集,所以他俩可以并行执行。事件(1)比较慢,因为是一个写操作。在一个主存的情况下,我们只能在(1)写完后并且其他线程都可以看到后,才能执行(2)。在现代CPU系统中,由于缓存的存在导致这是一个非常耗时的操作。
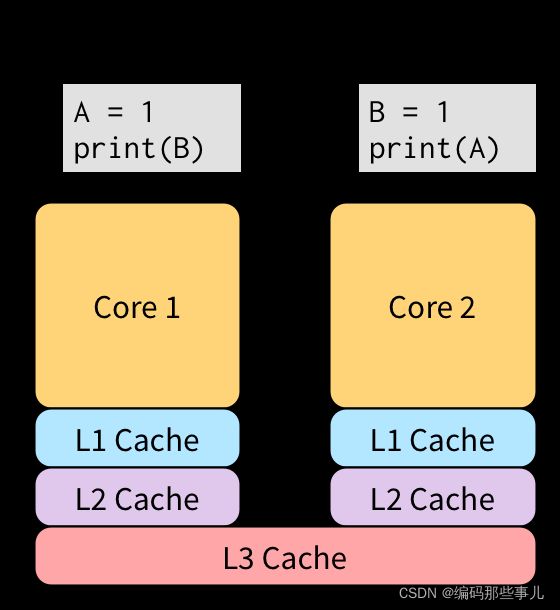
两个CPU唯一共享的内存就是L3级缓存,这一级缓存的操作大概需要90个时钟周期。
Total store ordering (TSO)
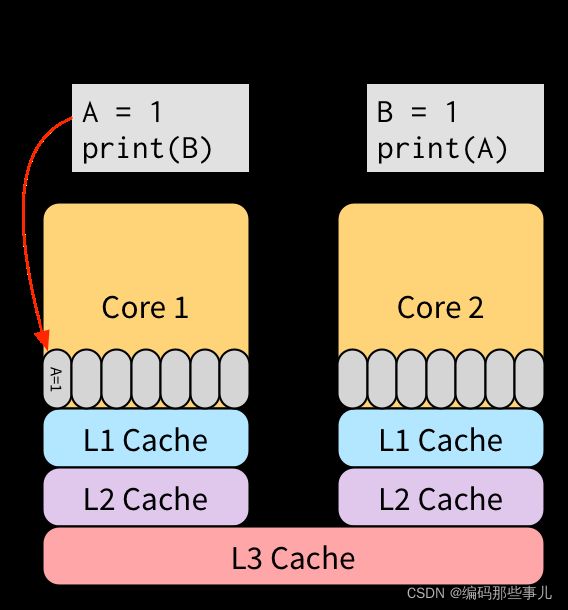
我们可以把事件(1)放入一个store buffer中,从而不必等待(1)的操作对所有线程都可见再去执行后面的事件。事件(2)在(1)被放入store buffer之后可以立即执行,不用等待事件(1)把数据写入L3。因为store buffer是在CPU核心里,所以访问速度非常快。之后的某个时间段,缓存系统会把事件(1)的操作结果反映到缓存上,之后其他线程就可以看到这个数据。
Store buffering非常nice,因为他保留了单个线程的一些特点。考虑如下程序:
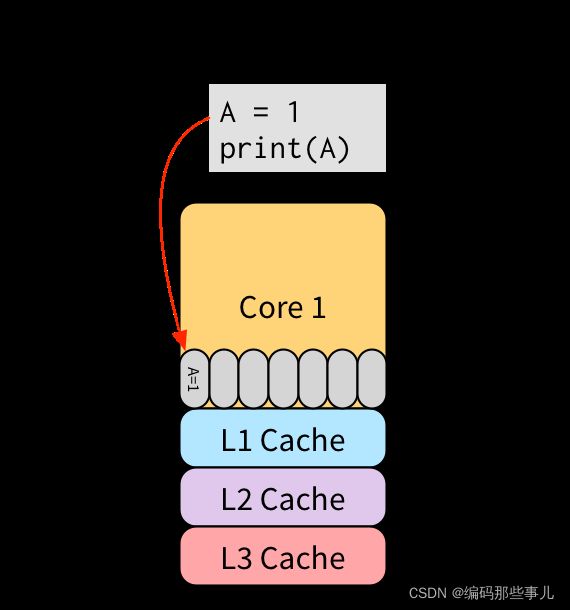
为了保证单个线程执行这个程序时的特性,(2)必须能读取到(1)写入的值。(1)还没有把数据写入内存,只是放在了CPU1的store buffer里,所以如果(2)直接去内存读取的话,可能会读到之前的数据。但是因为(1)和(2)都在一个CPU上运行,所以(2)可以直接去store buffer检索,如果找到有更新相同内存的事件的话,直接读取就可以。所以,即使使用了store buffer,这个程序的输出也是1。
允许store buffering存在的内存模型叫做total store ordering (TSO)。TSO与顺序一致性模型一样,唯一的区别就是,TSO使用了store buffer来减少写的时延从而提高程序的运行速度。
The catch(缺点)
Store buffer听起来像是一个很棒的性能优化,但这里有一个问题:TSO允许顺序一致性不允许的行为。换句话说,运行在TSO上的程序会表现出让开发者感觉很诧异的行为。
让我们回顾上面的一个程序,但是这次这个程序运行在一个有store buffer的计算机上。首先我们执行(1)然后执行(3),这两个都会把数据放入store buffer而不是写入主存:
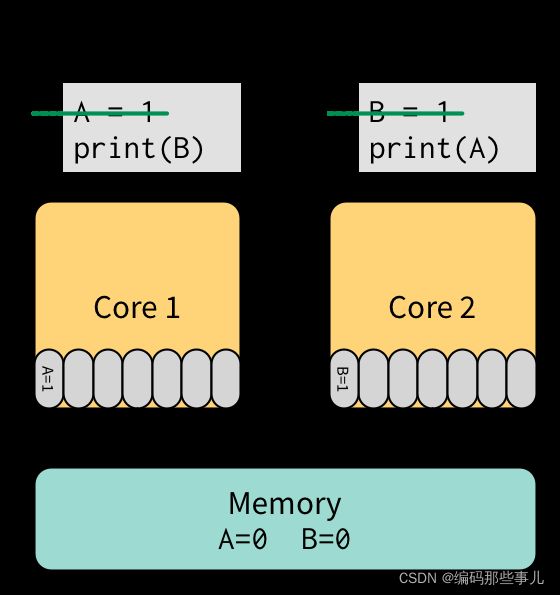
接下来我们在CPU1上执行(2),事件(2)先去CPU1的store buffer中查找是否有变量B的值,因为store buffer中没有B的值,所以事件(2)去内存里读取到了B=0这个值。最后我们在CPU2上执行(4),同样在CPU2的store buffer中没有找到A的值,然后去主存获取到了A=0这个值。在未来某个时刻,缓存系统会把store buffer中的值同步到内存里。
在TSO模型里,程序会打印00.这个值在SC(Sequential consistency)模型中是不会出现的。所以store buffer会造成一些开发者不希望看到的行为。
一些计算机体系结构会为了提升性能而采取一些让开发者感觉很奇怪的优化方法吗?当然!事实证明现代的体系架构都会有个一个store buffer,并且也会有一个和TSO一样弱的内存模型。
X86架构使用了和TSO非常接近的内存模型。Intel(x86的设计者)和AMD(x86-64的设计者)都使用了类似上面的简单程序代码对内存模型进行了描述。但是对于比较复杂的系统,很难用测试用例来描述系统的表现行为。Cambridge大学的研究人员花费了大量精力来形式化x86-TSO模型,该模型规定了x86’s TSO的实现所具有的某些特性(还描述了与store buffering不一样的地方)。
Getting weaker
尽管x86放弃了顺序一致性,但是就这个架构能允许的疯狂表现而言,x86是一个表现非常好的架构。其他的架构实现了更弱的内存模型,这就意味着会出现更多意想不到的行为。SPARC架构允许开发人员在系统运行过程中选择不同的内存模型。
现在智能手机中普遍使用的ARM架构就采用了比TSO还弱的内存模型。ARM内存模型本质上是一种弱排序(weak ordering),它所能提供的保证更少。弱排序(weak ordering)几乎可以对任何操作进行重排序以便进行硬件优化,但是,这对于软件开发者来说是一个噩梦。
Escaping through barriers(内存屏障解决一切)
幸运的是,现代架构都有同步操作,在需要的时候可以通过同步操作控制这些弱化的内存模型。最常用的同步操作就是内存屏障(barrier 或者 fence)。内存屏障指令之前的所有内存操作完成之后才可以执行后续的操作。也就是说,内存屏障指令使得程序运行的某个时刻让系统的内存模型变成了顺序一致性模型。
当然我们会通过使用store buffer或者其他优化方式尽量减少内存屏障的使用。内存屏障是一个非常耗时的操作,一次操作大概需要几百个时钟周期,必须谨慎使用,并且与一些定义不清楚的内存模型结合使用的时候,很容易出错。有一些比较有用的基础指令,比如CAS(atomic compare-and-swap),但是我们建议尽量少使用这种比较底层的同步指令。使用一些专用的同步库可能会比较方便。
Languages need memory models too
硬件可能会重排序内存操作指令,编译器也经常对指令进行重排序。考虑如下程序代码:
X = 0
for i in range(100):
X = 1
print X
这个程序会打印长度为100的字符串(1111…)。在循环里为X赋值显得比较冗余,因为没有其他地方对X进行修改。编译器在进行代码编译的时候会把代码优化成下面这样:
X = 1
for i in range(100):
print X
这两段代码完全一样, 因为他们的输出是一样的。
考虑有另个线程也在运行我们的程序,并且为X进行了赋值:
X = 0
当这两个线程同时执行的时候,第一个程序的输出就会变成11101111…,因为第二次循环会把X设置成1。第二个程序的输出也会变成11100000…,因为循环里的赋值代码被优化到循环外面。
对于这两个程序片段来说,第一个程序片段不会输出11100000…,第二个程序片段也不会输出11101111…。这就意味着,在并行场景中,编译器优化不能再得到两个一样的代码。
这个示例说明在语言层面也需要内存模型。编译器把一些内存访问指令进行了重排序。为了保持明确的代码执行结果,编程语言需要内存模型来控制编译器如何对代码指令进行重排序。在语言设计领域,内存模型变得越来越普遍,比如最新版本的C++和Java都有明确的内存模型定义。
Computers are broken!
这些重排序看着比较凌乱,我们是没有办法完全搞明白这些重排序。另一方面,如果我们回顾一下自己的编程经验,那么内存一致性可能并不常见(除非是一个底层内核黑客)。
我这里提到的每个例子都涉及到数据竞争。数据竞争是指对同一个内存位置的两次访问,其中至少一次是写操作,并且没有使用同步操作保证执行顺序。如果没有数据竞争(race-free)的话,那么指令重排序就没有太大问题,因为所有的不确定的重排序操作都会被同步指令禁止。但是这并不意味着没有数据竞争的程序就是确定性的,因为每次多线程执行的时候,都会只有一个线程赢得这次竞争。
实际上,编程语言比如C++或者Java都为data-race-free的程序提供了称为sequential consistency(顺序一致性)的一致性模型。这个模型保证如果程序没有数据竞争的话,编译器会在必要的地方插入内存屏障来保障顺序一致性。如果程序有数据竞争的话,编程语言便不会提供这些保障,编译器可以按照它们的意愿进行重排序。所以,带有数据竞争的程序非常的容易有bug,并且编程语言也不会为这种程序提供太强的一致性保证。如果程序有数据竞争的话,开发者应该了解如果处理这些数据竞争,并且有义务去处理这些内存重排序问题。
Use a synchronization library
我们应该使用同步工具,同步工具会帮我们解决这些讨厌的重排序问题。操作系统也进行了大量优化,会在特定平台上进行必要的同步。经过简单的讨论,现在我们已经了解了当这些库和内核处理同步问题时,底层到底发生了什么。
如果想更多的了解更多的内存模型,Morgan & Claypool有关于一致性模型和缓存一致性更好的资料。