Transformer 模型实用介绍:BERT
动动发财的小手,点个赞吧!
在 NLP 中,Transformer 模型架构是一场革命,极大地增强了理解和生成文本信息的能力。
在本教程[1]中,我们将深入研究 BERT(一种著名的基于 Transformer 的模型),并提供一个实践示例来微调基本 BERT 模型以进行情感分析。
BERT简介
BERT 由 Google 研究人员于 2018 年推出,是一种使用 Transformer 架构的强大语言模型。 BERT 突破了早期模型架构(例如 LSTM 和 GRU)单向或顺序双向的界限,同时考虑了过去和未来的上下文。这是由于创新的“注意力机制”,它允许模型在生成表示时权衡句子中单词的重要性。
BERT 模型针对以下两个 NLP 任务进行了预训练:
-
掩码语言模型 (MLM)
-
下一句话预测 (NSP)
通常用作各种下游 NLP 任务的基础模型,例如我们将在本教程中介绍的情感分析。
预训练和微调
BERT 的强大之处在于它的两步过程:
- 预训练是 BERT 在大量数据上进行训练的阶段。因此,它学习预测句子中的屏蔽词(MLM 任务)并预测一个句子是否在另一个句子后面(NSP 任务)。此阶段的输出是一个预训练的 NLP 模型,具有对该语言的通用“理解”
- 微调是针对特定任务进一步训练预训练的 BERT 模型。该模型使用预先训练的参数进行初始化,并且整个模型在下游任务上进行训练,从而使 BERT 能够根据当前任务的具体情况微调其对语言的理解。
实践:使用 BERT 进行情感分析
完整的代码可作为 GitHub 上的 Jupyter Notebook 获取
在本次实践练习中,我们将在 IMDB 电影评论数据集(许可证:Apache 2.0)上训练情感分析模型,该数据集
会标记评论是正面还是负面。我们还将使用 Hugging Face 的转换器库加载模型。
让我们加载所有库
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, roc_curve, auc
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
# Variables to set the number of epochs and samples
num_epochs = 10
num_samples = 100 # set this to -1 to use all data
首先,我们需要加载数据集和模型标记器。
# Step 1: Load dataset and model tokenizer
dataset = load_dataset('imdb')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
接下来,我们将创建一个绘图来查看正类和负类的分布。
# Data Exploration
train_df = pd.DataFrame(dataset["train"])
sns.countplot(x='label', data=train_df)
plt.title('Class distribution')
plt.show()
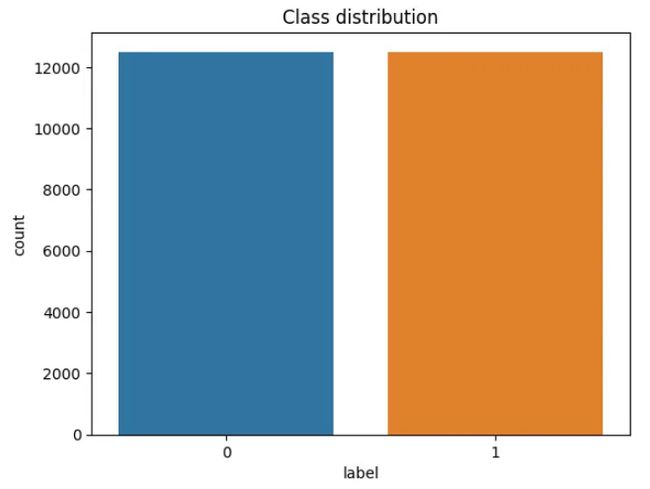
接下来,我们通过标记文本来预处理数据集。我们使用 BERT 的标记器,它将文本转换为与 BERT 词汇相对应的标记。
# Step 2: Preprocess the dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)

之后,我们准备训练和评估数据集。请记住,如果您想使用所有数据,可以将 num_samples 变量设置为 -1。
if num_samples == -1:
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42)
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42)
else:
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(num_samples))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(num_samples))
然后,我们加载预训练的 BERT 模型。我们将使用 AutoModelForSequenceClassification 类,这是一个专为分类任务设计的 BERT 模型。
# Step 3: Load pre-trained model
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
现在,我们准备定义训练参数并创建一个 Trainer 实例来训练我们的模型。
# Step 4: Define training arguments
training_args = TrainingArguments("test_trainer", evaluation_strategy="epoch", no_cuda=True, num_train_epochs=num_epochs)
# Step 5: Create Trainer instance and train
trainer = Trainer(
model=model, args=training_args, train_dataset=small_train_dataset, eval_dataset=small_eval_dataset
)
trainer.train()
结果解释
训练完我们的模型后,让我们对其进行评估。我们将计算混淆矩阵和 ROC 曲线,以了解我们的模型的表现如何。
# Step 6: Evaluation
predictions = trainer.predict(small_eval_dataset)
# Confusion matrix
cm = confusion_matrix(small_eval_dataset['label'], predictions.predictions.argmax(-1))
sns.heatmap(cm, annot=True, fmt='d')
plt.title('Confusion Matrix')
plt.show()
# ROC Curve
fpr, tpr, _ = roc_curve(small_eval_dataset['label'], predictions.predictions[:, 1])
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(1.618 * 5, 5))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.show()
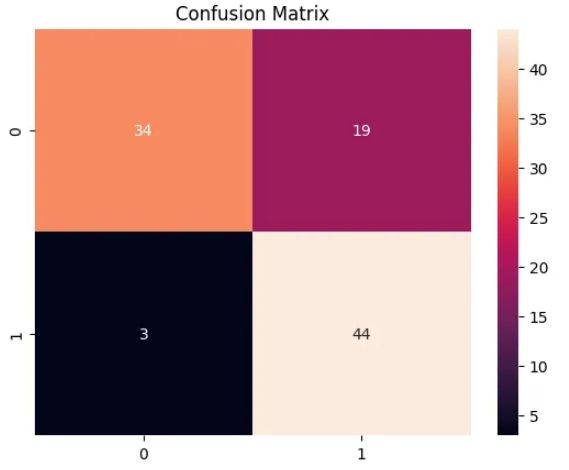
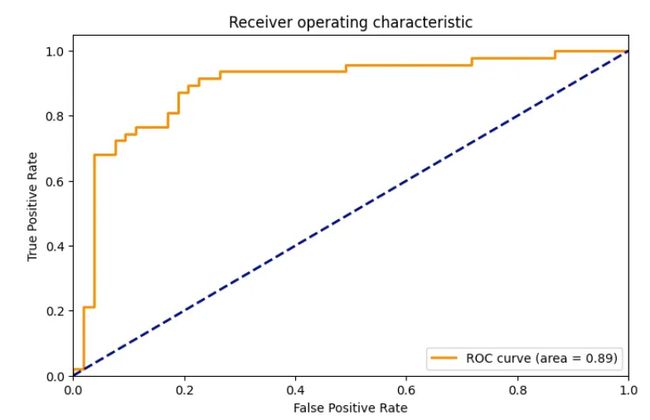
混淆矩阵详细说明了我们的预测如何与实际标签相匹配,而 ROC 曲线则向我们展示了各种阈值设置下真阳性率(灵敏度)和假阳性率(1 - 特异性)之间的权衡。
最后,为了查看我们的模型的实际效果,让我们用它来推断示例文本的情绪。
# Step 7: Inference on a new sample
sample_text = "This is a fantastic movie. I really enjoyed it."
sample_inputs = tokenizer(sample_text, padding="max_length", truncation=True, max_length=512, return_tensors="pt")
# Move inputs to device (if GPU available)
sample_inputs.to(training_args.device)
# Make prediction
predictions = model(**sample_inputs)
predicted_class = predictions.logits.argmax(-1).item()
if predicted_class == 1:
print("Positive sentiment")
else:
print("Negative sentiment")
总结
通过浏览 IMDb 电影评论的情感分析示例,我希望您能够清楚地了解如何将 BERT 应用于现实世界的 NLP 问题。我在此处包含的 Python 代码可以进行调整和扩展,以处理不同的任务和数据集,为更复杂和更准确的语言模型铺平道路。
Reference
[1]Source: https://towardsdatascience.com/practical-introduction-to-transformer-models-bert-4715ed0deede
本文由 mdnice 多平台发布