YOLO模型背后的直觉
YOLO 采用单阶段检测原理,这意味着它将目标检测管道的所有组件统一到单个神经网络中。 它使用整个图像的特征来预测类概率和边界框坐标。
这种方法有助于对整个图像和图像中的对象进行全局推理建模。 然而,在像 RCNN 这样的先前两级检测器中,我们有一个提案生成器,可以为图像生成粗略的提案,然后将其传递到下一阶段进行分类和回归。
推荐:用 NSDT设计器 快速搭建可编程3D场景。
1、YOLO模型概述
下图显示整个检测过程由三个步骤组成:将输入图像大小调整为 448 × 448,在完整图像上运行单个卷积网络,并根据模型的置信度对结果检测进行阈值处理,从而消除重复检测。

这种端到端的统一检测设计使YOLO架构能够更快地训练并在推理过程中实现实时速度,同时确保较高的平均精度(接近两级检测器)。
传统方法(例如 DPM)使用滑动窗口方法。 然而,分类器在整个图像上均匀分布的位置运行,因此训练和测试时间非常慢,并且优化具有挑战性,尤其是 RCNN 架构,因为每个阶段都需要单独训练。
我们了解到YOLO致力于统一的端到端检测方法,但它是如何实现这一目标的呢? 让我们来看看吧!
YOLO 模型将图像划分为 S × S 网格,如图 5 所示,其中 S = 7。如果某个对象的中心落入 49 个网格之一,则该单元负责检测该对象。

但是一个网格单元可以负责检测多少个物体呢? 那么,每个网格单元可以检测 B 个边界框以及这些边界框的置信度分数,B = 2。
总共,该模型可以检测 49 × 2 = 98 个边界框; 然而,稍后我们会看到,在训练过程中,模型会尝试抑制每个单元格中与地面实况框交并(IOU)较少的两个框之一。
为每个框分配一个置信度分数,该分数表明模型对边界框包含对象的置信度。
置信度得分可以定义为:
![]()
其中,如果对象存在,则 Pr(object) 为 1,否则为 0; 当存在对象时,置信度得分等于真实值与预测边界框之间的 IOU。
这是有道理的,因为当预测框与真实框不完全对齐时,我们不希望置信度得分为 100% (1),这允许我们的网络为每个边界框预测更真实的置信度。
每个边界框输出五个预测:
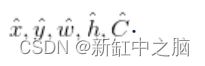
- 目标 (x, y) 坐标表示相对于网格单元边界的边界框中心,这意味着 (x, y) 的值范围在 [0, 1] 之间。 值为 (0.5, 0.5) 的 (x, y) 表示对象的中心是特定网格单元的中心。
- 目标(w,h)是边界框相对于整个图像的宽度和高度。 这意味着预测的 (w_hat, h_hat) 也将相对于整个图像。 边界框的宽度和高度可以大于 1。
- C_hat 是网络预测的置信度得分。
除了边界框坐标和置信度得分之外,每个网格单元还预测 C 个条件类概率 Pr(Classi| Object),其中 PASCAL VOC 类的 C = 20。 Pr 以包含对象的网格单元为条件; 因此,只有当有一个对象时它才存在。
我们了解到每个网格单元负责预测两个盒子。 然而,只考虑与真实值 IOU 最高的一个; 因此,模型预测每个网格单元的一组类概率,忽略框 B 的数量。
为了培养更多的直觉,请参阅下图 ; 我们可以观察 7 × 7 个网格,每个网格单元都有 Box 1 和 Box 2 的输出预测以及类别概率。

每个边界框有五个值 [confidence、X、Y、Width、Height],边界框和 20 个类概率总共有 10 个值。 因此,最终的预测是 7 × 7 × 30 张量。
2、YOLO的网络架构
YOLO的网络架构很简单,相信我! 它类似于你过去训练过的图像分类网络。 但是,令人惊讶的是,该架构的灵感来自于图像分类任务中使用的 GoogLeNet 模型。
它主要由三种类型的层组成:卷积层、最大池层和全连接层。 YOLO 网络有 24 个卷积层,用于提取图像特征,然后是两个全连接层,用于预测边界框坐标和分类分数。
雷德蒙等人 修改原有的GoogLenet架构。 首先,他们使用 1 × 1 卷积层而不是 inception 模块来减少特征空间,然后是 3 × 3 卷积层:

YOLO 的第二种变体称为 Fast-YOLO,具有 9 个卷积层(而不是 24 个),并使用较小的滤波器尺寸。 主要是为了将推理速度进一步提升到人们无法想象的程度。 通过此设置,作者能够达到 155 FPS!
3、YOLO的损失函数设计
现在让我们剖析图 9 中所示的 YOLO 损失函数。乍一看,下面的方程可能看起来有点冗长和棘手,但不用担心; 这很容易理解。
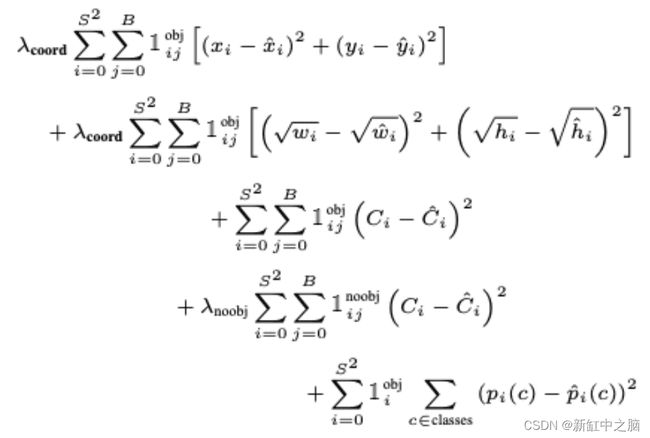
你会注意到,在此损失方程中,我们正在使用平方和误差 (SSE) 和 Redmon 等人优化网络。 相信很容易优化。 然而,使用它有一些警告,他们试图通过添加一个称为 lambda 的权重项来克服这些警告。
让我们分项理解上面的等式:
- 方程的第一部分计算预测边界框中点 (x_hat, y_jat) 和真实边界框中点 (x, y) 之间的损失。
它针对所有 49 个网格单元进行计算,并且损失中仅考虑两个边界框之一。 请记住,它只会惩罚对真实框“负责”的预测器的边界框坐标误差(即,在该网格单元中具有最高 IOU 的预测器)。
简而言之,我们将看到与目标边界框具有最高 IOU 的两个边界框,并且将优先进行损失计算。
最后,我们用常数 lambda_coord=5 来衡量损失,以确保我们的边界框预测尽可能接近目标。 最后,1^obj_ij 表示单元格 i 中的第 j 个边界框预测器负责该预测。 因此,如果目标对象存在,则为 1,否则为 0。
- 第二部分与第一部分非常相似,所以让我们了解一下差异。 在这里,我们计算预测边界框宽度和高度 (w_hat, h_hat) 与目标宽度和高度 (w, h) 之间的损失。
但请注意,我们取宽度和高度的平方根(即,因为平方和损失同等地权衡大型和小型盒子中的误差)。
小盒子中的显着偏差很小,而大盒子中的微小变化将很显着,这会导致小盒子的重要性降低。 因此,作者添加了一个平方根来反映大盒子中的轻微偏差比小盒子中的影响要小。
- 在方程的第三部分中,给定一个对象存在 1^\obj_ij=1,我们计算边界框的预测置信度得分 C_hat 与目标置信度得分 {C} 之间的损失。
这里,目标置信度得分 C 等于预测边界框和目标之间的 IOU。 我们选择与目标 IOU 较高的框的置信度得分。
- 接下来,如果网格单元 i 中不存在任何对象,则 1^noobj_ij=1 和 1^obj_ij=0 将使方程的第三部分为零。 损失是在具有较高 IOU 的框和目标 C 之间计算的,目标 C 为 0,因为我们希望没有对象的单元格的置信度为 0。
我们还用 lambda_noobj=0.5 来衡量这一部分,因为可能有许多没有对象的网格单元,并且我们不希望这项项压倒包含对象的单元格的梯度。 正如本文所强调的,这可能会导致模型不稳定并且更难以优化。
最后,对于每个单元格,如果一个对象出现在单元格 i 中,则 1^obj_i=1 ,我们计算所有 20 个类的损失(条件类概率)。 这里,p_hat© 是预测的条件类概率,p© 是目标条件类概率。
原文链接:YOLO模型的直觉 — BimAnt