HDP安装教程笔记
HDP安装教程,ambari安装教程,大数据平台安装教程
1.环境准备
1.安装centos7系统
1.使用vmware安装centos系统,略
HDP 环境安装配置
HDP : Hortonworks Data Platform
CDH : Cloudera Distribution Hadoop
部署安装主要分为3大部分
- 准备环境、配置机器、准备离线包、本地仓库、数据库等
- 安装Ambari Server 阶段
- 基于Ambari Server UI 来安装相关服务组件阶段
HDP集群的安装,95%的工作是对Ambari Server的安装配置。
所有对集群的安装、配置、管理等都是通过Ambari Server UI来完成
也就是说,Ambari Server UI 是整个集群的管理员,我们多数操作都是通过它来进行的,而不需要像部署开源Hadoop那样去一台台机器手动去部署。
Ambari Server UI 是我们对集群进行管理的入口。如同Linux Shell是操作系统的操作界面一样,Ambari Server UI 就是整个集群的操作界面
1. 环境检查
1.1 产品互用性
首先, 需要确定使用的Ambari版本,可以参考: https://supportmatrix.hortonworks.com , 这里列出了Ambari和HDP等组件的版本依赖关系
我们这里使用Ambari 2.7.0, HDP 3.0.0 来安装部署集群
Ambari 和 HDP 有版本依赖关系
然后HDP的版本 和其内部可使用的大数据组件也有版本参照关系
HDP版本对应的各个大数据组件版本参见:
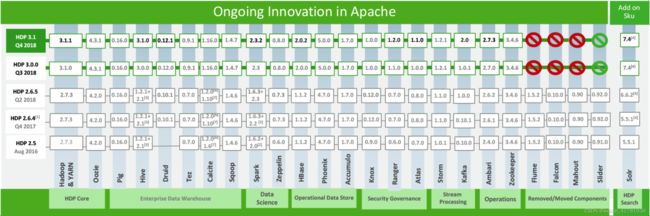
1.2 课程使用的版本信息
根据 > https://supportmatrix.hortonworks.com 的选择后,课程使用
- Centos 7.4 x64 操作系统
- JDK8
- HDP 3.0.0
- Ambari 2.7
- mysql-5.7.27-1.el7.x86_64.rpm-bundle
- Centos 7.9
同学们如果想要尝试其他版本,请按照网站的搭配来确定版本
2.挂载系统盘并安装ifconfig软件
1.挂载系统安装盘到机器上,配置本地yum仓库用来安装软件,安装ifconfig等软件
- 如果下载了Everything版本的centos7.iso则挂载Everything版本,软件包多一点

D:\原电脑E盘\软件安装包\CentOS-7-x86_64-Everything-1810_2.iso
mkdir /mnt/centos #创建要挂载到的目录
cd /dev
ls | grep sr #查看cdrom指向哪里
mount -t iso9660 -o loop /dev/sr1 /mnt/centos #
mount -t iso9660 -o loop /dev/cdrom /mnt/centos #// 虚拟机环境下,可以用光驱加载ISO文件,不需要上传
2.确定要挂载的sr,cdrom指向的是sr0,但是我们的系统镜像是sr1,所以使用了mount -t iso9660 -o loop /dev/sr1 /mnt/centos

3.配置本地源,用于安装软件是从本地仓库下载
配置本地yum源:
1.将iso光盘挂载到目录下
# 非虚拟机环境
mkdir /data #创建目录(存放iso镜像文件)
#将iso镜像文件上传到/data下
mkdir /mnt/centos #创建要挂载到的目录
mount /xxx/xxx/xxx.iso /mnt/centos
# 虚拟机环境
#必须让虚拟机加载了安装盘
mkdir /mnt/centos
mount -t iso9660 -o loop /dev/cdrom /mnt/centos // 虚拟机环境下,可以用光驱加载ISO文件,不需要上传,mount -t iso9660 -o loop /dev/sr1 /mnt/centos
#查看挂载点
df -h /dev/loop0 11G 11G 0 100% /mnt/centos
2.配置基于本地文件的yum源
cd /etc/yum.repos.d/
ll ./ #查看yum源文件配置
CentOS-Base.repo #网络yum源
CentOS-Debuginfo.repo
CentOS-fasttrack.repo
CentOS-Media.repo #本地yum源
CentOS-Vault.repo
3.先禁用本地的yum配置文件(必须以.repo结尾的yum配置文件才生效)
rename .repo .repo.bak ./*
yum repolist (检查,查不到东西说明,yum源已禁用)
4.复制一份CentOS-Media.repo
cp CentOS-Media.repo.bak local.repo
5.配置local.repo
vi local.repo
[centos7-local]
name=CentOS-$releasever - Local
baseurl=file:///mnt/centos/
gpgcheck=1
enabled=1 #设置这个配置文件为可用
gpgkey=file:///mnt/centos/RPM-GPG-KEY-CentOS-7
6.yum clean all清缓存
7.yum repolist 查看仓库信息
#配置成功会显示
------------------------------------------------------------
repo id repo name status
Local CentOS-6 - Local 6,575
repolist: 6,575
------------------------------------------------------------
4.安装ifconfig软件
# 查找ifconfig是哪个包
yum search ifconfig
#拿到安装包名称后直接下载
yum install -y net-tools # -y 代表yes 直接安装
#安装成功后输入
ifconfig # 输出ip相关信息
5.卸载设备
-
卸载挂载的光盘,重新挂载新的
-
umount -v /mnt/centos
umount 用来卸载设备
-a:卸除/etc/mtab中记录的所有文件系统;
-h:显示帮助;
-n:卸除时不要将信息存入/etc/mtab文件中;
-r:若无法成功卸除,则尝试以只读的方式重新挂入文件系统;
-t<文件系统类型>:仅卸除选项中所指定的文件系统;
-v:执行时显示详细的信息; -V:显示版本信息。
umount -v /dev/sda1 通过设备名卸载
umount -v /mnt/mymount/ 通过挂载点卸载
umount -vl /mnt/mymount/ 延迟卸载
如果报device is busy ,说明你在这个目录下卸载自己 这样肯定不行 退出目录卸载可行 或者 执行延迟卸载
6.挂载光盘
- 挂载Everything版本的centos7.iso,上面挂载的没有vim,软件包比较少,所以umount了以后挂载新的光盘
mount -t iso9660 /dev/cdrom /mnt/centos/
# 挂载光盘 Everything版本的centos7.iso
# mount -t iso9660 /dev/cdrom /mnt/cdrom
1.yum clean all清缓存
2.yum repolist 查看仓库信息
-
换了新的iso后软件变多了447——》10019
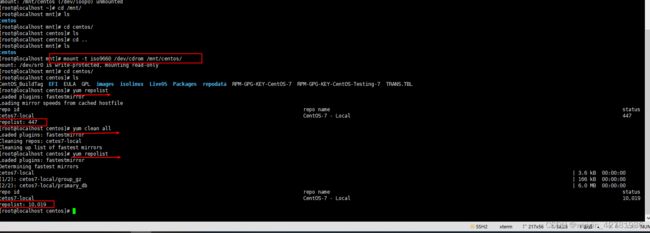
-
可以安装vim了
- vim 用于编辑文档
yum install -y vim
3.配置静态ip
-
修改部分内容
vim /etc/sysconfig/network-scripts/ifcfg-ens33
# cat /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="static" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" UUID="26809e1e-4bee-4a4e-aef6-8f3fe6e216b4" DEVICE="ens33" ONBOOT="yes" IPADDR="192.168.152.100" #定义的本机ip NETMASK="255.255.255.0" #子网掩码 GATEWAY="192.168.152.2" #网关 如下图查询 DNS1="192.168.152.1" DNS2="8.8.8.8"

4.配置主机名
-
修改主机名 修改/etc/hostname文件。重启生效。3台服务器都需要做如上修改,先修改一台一会克隆后在适当修改部分内容
vim /etc/hostname 修改为hdp100- 或者使用echo hdp100 > /etc/hostname
-
配置/etc/hosts文件,/etc/hosts存放的是域名与ip的对应关系,域名与主机名没有任何关系,你可以为任何一个IP指定任意一个名字
- 要在hosts文件中配置
FQDN形式的主机名映射,比如
vim /etc/hosts 192.168.152.100 hdp0.itcast.cn hdp100 192.168.152.101 hdp1.itcast.cn hdp101 192.168.152.102 hdp2.itcast.cn hdp102 192.168.152.103 hdp3.itcast.cn hdp103 # hdp0.itcast.cn 就是 fully.qualified.domain.name FQDN-
不要移除hosts中自带的这些
127.0.0.1 localhost.localdomain localhost ::1 localhost6.localdomain6 localhost6 -
3台服务器的hosts都需要做如上修改,先修改一台一会克隆后在适当修改部分内容
-
#生效命令 service network restart 或者 /etc/init.d/network restart
- 要在hosts文件中配置
-
使用
hostname -f检查是否能够映射FQDN主机名,确认hostname(所有服务器均验证)- 获取FQDN形式的主机名
5.关闭防火墙及selinux
-
3台服务器上分别执行以下操作,关闭防火墙并配置开机不自动启动
-
防火墙指定端口开放,不要禁用防火墙,这里学习则关闭了防火墙
systemctl status firewalld.service #查询防火墙状态 systemctl stop firewalld.service #关闭防火墙 systemctl disable firewalld.service #开机不自动启动 systemctl status firewalld.service #查询防火墙状态-
关闭3台服务器selinux
-
临时关闭,不用重启服务器
setenforce 0 -
为了重启后依然关闭,配置如下文件
vim /etc/sysconfig/selinux #修改 SELINUX=disabled -
重启后验证是否禁用成功
sestatus -v SELinux status: disabled设置umask为0022
UMASK Examples:
为当前登录session设置umask:
umask 0022检查设置:
umask为每个用户设置:
echo umask 0022 >> /etc/profileUMASK(用户掩码或用户文件创建MASK)设置在Linux计算机上创建新文件或文件夹时授予的默认权限或基本权限。
大多数Linux发行版(发行版)都将022设置为默认的umask值。
umask值为022,为新文件或文件夹授予755的读取,写入和执行权限。
umask值027为新文件或文件夹授予750读取,写入和执行权限。
Ambari,HDP和HDF支持umask值022(0022在功能上等效),027(0027在功能上等效)。
必须在所有主机上设置这些值。 -
6.克隆系统并修改ip以及hosts、hostname等参数
- 克隆的三台都要修改
-
修改ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33 #修改ip为 192.168.152.101 ,102,103等ip systemctl restart network #重启生效 ifconfig对比 -
修改主机名称
echo hdp100 > /etc/hostname- 重启生效
-
设置SSH免密登陆(所有服务器均设置)
要让Ambari Server在所有群集主机上自动安装Ambari Agent,必须在Ambari Server主机与群集中的所有其他主机之间设置无密码SSH连接。
-
Ambari Server主机使用SSH公钥身份验证来远程访问和安装Ambari代理.
Steps
- 生成ssh 秘钥
ssh-keygen -t rsa - 执行
ssh-copy-id 目标主机 - 执行上述命令后,当前机器可以免密登陆到目标主机 ,所有主机都要设置
3.验证免密是否配置成功
- ssh hdp100
7.安装pssh工具(高效,同时查询或修改其他主机的文件的工具)
- pssh基于Python编写的并发在多台服务器上批量执行命令的工具,它支持文件并行复制、远程并行执行命令、杀掉远程主机上的进程等,这里介绍安装及常用命令
-
我将安装包放到/opt/bao目录下
cd /opt/bao wget http://peak.telecommunity.com/dist/ez_setup.py wget http://files.opstool.com/files/pssh-2.3.tar.gz #上面的网址可能下载不下来,用另一个 wget https://pypi.python.org/packages/60/9a/8035af3a7d3d1617ae2c7c174efa4f154e5bf9c24b36b623413b38be8e4a/pssh-2.3.1.tar.gz -
发解压到/opt/src目录下
tar -zxvf pssh-2.3.1.tar.gz -C /opt/src -
更改包名,并cd到包里
cd /opt/src mv pssh-2.3.1 pssh cd pssh -
build &install
python setup.py build python setup.py install -
查看安装
pssh --version
2.3.1
- 创建nodes文档,添加需要批处理的服务器节点
为了以后使用方便,在根目录下创建,文件名可随意,方便使用原则
vim /node.list
[email protected]:22
[email protected]:22
[email protected]:22
[email protected]:22
cat /node.list
-
使用实例
pssh -h /node.list -i -P 'date' [root@hdp100 pssh]# pssh -h /node.list -i -P 'date' 192.168.152.101: Thu Feb 23 00:34:11 PST 2023 [1] 00:34:11 [SUCCESS] [email protected]:22 Thu Feb 23 00:34:11 PST 2023 192.168.152.100: Thu Feb 23 00:34:11 PST 2023 [2] 00:34:11 [SUCCESS] [email protected]:22 Thu Feb 23 00:34:11 PST 2023 192.168.152.102: Thu Feb 23 00:34:11 PST 2023 [3] 00:34:11 [SUCCESS] [email protected]:22 Thu Feb 23 00:34:11 PST 2023 192.168.152.103: Thu Feb 23 00:34:11 PST 2023 [4] 00:34:11 [SUCCESS] [email protected]:22 pssh -h /node.list -i 'date'pssh是一个用于在多台主机上并行执行ssh的命令,方便多台Linux的管理。 -i 每台主机执行完后显示标准输出和标准错误 -H 指定远程地址,该地址可以同时给出多个,格式为[user@]host[:port],也可以和-f选项配合使用。 -h 指定主机列表文件,也就是说可以从文件中读取主机列表。 -t 指定超时时间,单位是秒,参数为0表示永不超时。 -o 将输出结果保存到指定的文件 -A 提示输入密码,这样做的目的是密码不会保存在命令历史记录里。 -l 指定ssh连接用户名-x 传递额外的ssh命令参数 -p 指定pssh命令的最大并发连接数
8.安装http服务
-
将这个机器配置的本地仓库托管为http服务,让其他server可以访问,安装两个软件 createrepo和httpd
sysctl net.ipv6.conf.all.disable_ipv6=1 # 关闭IP6 yum install yum-utils createrepo #安装失败请检查本地仓库,光盘是否挂载 没有挂载则运行mount -t iso9660 -o loop /dev/cdrom /mnt/centos 也不行 yum install httpd systemctl enable httpd #设置为开机自启动 systemctl enable httpd.service mkdir -p /var/www/html/ #httpd 默认工作目录 cd /var/www/html/ ln -s /mnt/centos centos7-local-repo systemctl start httpd #启动httpd服务,在hdp1就可以通过局域网访问hdp0的仓库了 #备注在/var/www/html下建立centos7-local-repo的软连接,链接到 /mnt/centos /var/www/html是httpd的默认工作目录,所以输入http://192.168.152.100/centos7-local-repo/或者http://hdp0/centos7-local-repo/就可以访问到本地仓库 #修改电脑hosts文件C:\Windows\System32\drivers\etc\hosts #配置本地的ambari集群 自己的 192.168.152.100 hdp100 192.168.152.101 hdp101 192.168.152.102 hdp102 192.168.152.103 hdp103 #在自己电脑浏览器上可以查看,本地仓库托管成网络服务 ,局域网源配置成功 http://192.168.152.100/centos7-local-repo/ 9. 在其他机器上 http://hdp0/centos7-local-repo/ cd /etc/yum.repos.d/ rename .repo .repo.bak ./* cp CentOS-Base.repo.bak my.repo 修改my.repo内容为 ``` [hdp0] # 自己定义 name=CentOS-$releasever - HDP0-local # 自己定义一个名字 # 下面的url 是配置好提供本地仓库的服务器,如我的就是如下 (baseurl) baseurl=http://hdp0/centos7-local-repo/ gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7 ``` yum repolist 同步到其他节点 pscp -h /node.list /etc/yum.repos.d/my.repo /etc/yum.repos.d/my.repo 查看yum源是否配置成功,如下可见redhat7.6.repo配置成功 pssh -h /node.list -i 'yum clean all' pssh -h /node.list -i 'yum repolist' #报错的话则将除了主机外的其他三台主机的my.repo屏蔽,克隆的时候一起克隆过来了 mv local.repo local.repo.bak 查看hdp0是否开机启动 systemctl status httpdyum install yum-utils createrepo #安装失败请检查本地仓库,光盘是否挂载 没有挂载则运行mount -t iso9660 -o loop /dev/cdrom /mnt/centos **失败**
9.配置ntp时钟同步(所有服务器均设置)
-
群集中所有节点的时钟以及运行浏览器的计算机必须能够彼此同步才能访问Ambari Web界面。
-
要安装NTP服务并确保它在启动时启动,请在每台主机上运行以下命令:
-
卸载系统原装的chrony
pssh -h /node.list -i 'yum -y remove chrony' -
所有节点安装NTP服务
pssh -h /node.list -i 'yum -y install ntp'-
选择一台服务器作为NTP Server,将如下配置
vim /etc/ntp.confserver 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst修改为
#server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst #允许这些网段的主机访问进行同步时间 restrict 192.168.152.0 mask 255.255.255.0 nomodify notrap #允许本机访问 restrict 127.0.0.1 #server指定ntp服务器的地址 将当前主机作为时间服务器 #fudge设置时间服务器的层级 stratum 0~15 ,0:表示顶级 , 10:通常用于给局域网主机提供时间服务 #注意:fudge必须和server一块用, 而且是在server的下一行 # local clock 授权中心,自己和自己对,别人以他为准 和自己对时间 server 127.127.1.0 fudge 127.127.1.0 stratum 10 -
其它节点做如下配置
#server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst #(your local server) server 192.168.152.100 -
在每台服务器上启动ntpd服务,并配置服务开机自启动
pssh -h /node.list -i 'systemctl restart ntpd' pssh -h /node.list -i 'systemctl enable ntpd.service' -
验证所有节点NTP是否同步成功
pssh -h /node.list -i 'ntpq -p' [1] 03:45:30 [SUCCESS] [email protected]:22 remote refid st t when poll reach delay offset jitter ============================================================================== hdp0.itcast.cn LOCAL(0) 11 u 7 64 3 0.186 -3851.3 0.008 [2] 03:45:30 [SUCCESS] [email protected]:22 remote refid st t when poll reach delay offset jitter ============================================================================== *LOCAL(0) .LOCL. 10 l 13 64 7 0.000 0.000 0.000 [3] 03:45:30 [SUCCESS] [email protected]:22 remote refid st t when poll reach delay offset jitter ============================================================================== hdp0.itcast.cn LOCAL(0) 11 u 12 64 7 0.613 62273.4 0.032 [4] 03:45:30 [SUCCESS] [email protected]:22 remote refid st t when poll reach delay offset jitter ============================================================================== hdp0.itcast.cn LOCAL(0) 11 u 10 64 7 0.153 -5428.2 0.041 -
同步时间,来手动对时 ,clientnode.list没有本机的ip,只有client节点的ip
pssh -h /clientnode.list -i 'ntpdate -u hdp100' #重启ntpd pssh -h /node.list -i 'systemctl restart ntpd' -
检查 提供ntp server机器的时间
如果时区不对,使用tzselect 命令选择中国时区 tzselect 输入 5 9 1 1 使用date -s "设置时间" 如: date -s "2019-09-02 11:41:00"-
重新使用以上命令同步一下时间
pssh -h /node.list -i 'date' pssh -h /clientnode.list -i 'ntpdate -u hdp100' pssh -h /node.list -i 'date'
-
-
d
-
将安装包提供的
libtirpc-0.2.4-0.15.el7.x86_64.rpm和libtirpc-devel-0.2.4-0.15.el7.x86_64.rpm上传到服务器进行安装rpm -ivh libtirpc-0.2.4-0.15.el7.x86_64.rpm 所有的节点都要安装可以使用
rz命令快速上传,如果rz提示无这个命令使用:yum install lrzsz来安装即可yum install nmap所有的节点都要安装 -
d
-
d
-
10.下载并设置数据库连接器(Ambari Server服务器设置即可)
-
需要元数据存储仓库,默认是postgre,也可以使用其他mysql,oracer,如hive也需要元数据存储仓库,ambari也需要
-
安装一个数据库提供元数据存储
-
安装Mysql:
一、首先清除CentOS7系统中默认的数据库mariadb,否则不能安装mysql rpm -qa |grep mariadb |xargs yum remove -y 二、安装MySql 1、下载MySql的相关rpm包 上传安装包中提供的mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar 2、将下载的mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar放到/usr/local/mysql目录,解压缩安装包 tar -xvf mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar #视频是建立mysql-rpms文件夹,并解压到此文件夹下 #tar -xvf mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar -C mysql-rpms/ 3、切换到下载包目录下(cd 你的下载目录),然后对每个包进行一次安装; rpm -ivh mysql-community-common-8.0.15-1.el7.x86_64.rpm rpm -ivh mysql-community-libs-8.0.15-1.el7.x86_64.rpm rpm -ivh mysql-community-libs-compat-8.0.15-1.el7.x86_64.rpm rpm -ivh mysql-community-embedded-compat-8.0.15-1.el7.x86_64.rpm rpm -ivh mysql-community-devel-8.0.15-1.el7.x86_64.rpm rpm -ivh mysql-community-client-8.0.15-1.el7.x86_64.rpm rpm -ivh mysql-community-server-8.0.15-1.el7.x86_64.rpm 或者一行搞定 >>> rpm -ivh mysql-community-common-5.7.27-1.el7.x86_64.rpm mysql-community-libs-5.7.27-1.el7.x86_64.rpm mysql-community-libs-compat-5.7.27-1.el7.x86_64.rpm mysql-community-embedded-compat-5.7.27-1.el7.x86_64.rpm mysql-community-embedded-devel-5.7.27-1.el7.x86_64.rpm mysql-community-embedded-5.7.27-1.el7.x86_64.rpm mysql-community-devel-5.7.27-1.el7.x86_64.rpm mysql-community-client-5.7.27-1.el7.x86_64.rpm mysql-community-server-5.7.27-1.el7.x86_64.rpm 如果缺少libaio 可以安装提供的两个libaio包 rpm -ip libaio-devel-0.3.109-13.el7.x86_64.rpm 或者执行如下命令,安装所需依赖即可: yum install -y libaio 4、修改MySql基础配置 vi /etc/my.cnf 修改配置如下 #datadir=/var/lib/mysql 存放数据的目录 datadir=/data/mysql socket=/var/lib/mysql/mysql.sock log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid 修改/etc/my.cnf配置文件,在[mysqld]下添加编码配置,如下所示: [mysqld] character_set_server=utf8 init_connect='SET NAMES utf8' 5、通过以下命令,完成对 mysql 数据库的初始化和相关配置 mysqld --initialize // chown mysql:mysql /data/mysql -R cd /var/lib/mysql chown -R mysql:mysql * #将修改权限 systemctl enable mysqld // 设置开机启动 #drwxr-xr-x 2 root root 6 Feb 24 10:54 mysql 三、启动MySql服务 1、启动MySql systemctl start mysqld.service #停止MySql systemctl stop mysqld.service #重启MySql systemctl restart mysqld.service 2、设置MySql开机自启 systemctl enable mysqld 1 3、通过 cat /var/log/mysqld.log | grep password 命令查看数据库的密码 2019-02-16T09:46:38.945518Z 5 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: ,#t#dlkOG0j0 1 以上密码为,#t#dlkOG0j0 AHIZUGI!j8hi 4、测试MySql安装是否成功 4.1、以root用户登录MySql,执行命令 mysql -u root -p 输入以上命令回车进入,出现输入密码提示 4.2、输入刚刚查到的密码,进行数据库的登陆,复制粘贴就行,MySQL 的登陆密码也是不显示的 4.3、通过 ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'root'; 命令来修改密码 4.4、通过 exit; 命令退出 MySQL,然后通过新密码再次登陆 至此,mysql数据库就安装完成了。 2023年2月20号下班到这里了 四、MySql远程访问授权配置 1、以root用户登录MySql mysql -u root -p grant all privileges on *.* to root@"%" identified by '密码' with grant option; flush privileges; #以下为说明解释 #查看添加的账号密码权限 use mysql SELECT Host,user,authentication_string FROM user; 图片如下 #比如你的host主机IP是192.168.170.128,用如下命令在Linux主机上验证是否可以远程登录,注意把如下密码换成你的MySQL数据库的实际root密码,IP换成你的实际主机地址。 mysql -uroot -proot -h hdp100 附: 创建新用户: CREATE USER ‘用户名’@‘host名称’ IDENTIFIED WITH mysql_native_password BY ‘密码’; 给新用户授权:GRANT ALL PRIVILEGES ON . TO ‘用户名’@‘host名称’; 刷新权限: FLUSH PRIVILEGES; 备注: #grant all privileges on *.* #授予所有权限 对于所有的库所有的表*.* #%代表任何地方 不只是本主机才可以登录 %代表所有的访问地址 #WITH GRANT OPTION表示允许级联授权 #其中"*.*"代表所有资源所有权限, “'root'@%”其中root代表账户名,%代表所有的访问地址。IDENTIFIED BY '密码',这里换成数据库root用户的密码,WITH GRANT OPTION表示允许级联授权 #SELECT Host,user,authentication_string FROM user;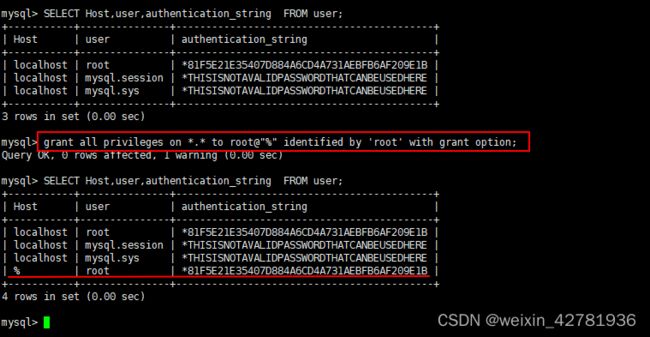
报错解决办法:
1、 运行上边的代码报错,需要加入 --force --nodeps rpm -ivh mysql-community-common-5.7.27-1.el7.x86_64.rpm --force --nodeps mysql-community-libs-5.7.27-1.el7.x86_64.rpm mysql-community-libs-compat-5.7.27-1.el7.x86_64.rpm mysql-community-embedded-compat-5.7.27-1.el7.x86_64.rpm mysql-community-embedded-devel-5.7.27-1.el7.x86_64.rpm mysql-community-embedded-5.7.27-1.el7.x86_64.rpm mysql-community-devel-5.7.27-1.el7.x86_64.rpm mysql-community-client-5.7.27-1.el7.x86_64.rpm mysql-community-server-5.7.27-1.el7.x86_64.rpm Linux下rpm方式安装MySQL遇到warning: mysql-community-server-5.7.25-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY这个错误,这是因为yum安装了旧版本的GPG keys造成的 解决办法:后面加上 --force --nodeps 如: rpm -ivh MySQL-server-5.5.46-1.linux2.6.x86_64.rpm --force --nodeps 即可 2、mysqld --initialize 报错 [root@hdp0 etc]# mysqld --initialize mysqld: error while loading shared libraries: libaio.so.1: cannot open shared object file: No such file or directory 解决办法:原因是因为:新的服务器没有安装所需依赖导致的。 解决办法,执行如下命令,安装所需依赖即可: yum install -y libaio -
创建相关账号和数据库以及表
-
使用MySQL时,用于Ranger管理策略存储表的存储引擎必须支持事务。
-
InnoDB是支持事务的引擎示例。
-
不支持事务的存储引擎不适合作为策略存储。
-
nnoDB,是MySQL的数据库引擎之一,现为MySQL的默认存储引擎,为MySQL AB发布binary的标准之一
-
推荐使用InnoDB引擎
-
应使用MySQL数据库管理员创建Ranger数据库
-
以下一系列命令可用于创建密码为
rangerdba的rangerdba用户。-
以root用户身份登录,然后使用以下命令创建
rangerdba用户并授予其足够的权限。CREATE USER 'rangerdba'@'localhost' IDENTIFIED BY 'rangerdba'; #创建一个用户rangerdba, 可以在localhost登录,密码是rangerdba GRANT ALL PRIVILEGES ON *.* TO 'rangerdba'@'localhost'; #授予所有权限 对于所有的库所有的表*.* 授权给rangerdba用户,必须在localhost登录才可以 CREATE USER 'rangerdba'@'%' IDENTIFIED BY 'rangerdba'; #%代表任何地方 进入mysql后可以查看是否添加 #SELECT Host,user,authentication_string,Grant_priv FROM mysql.user; GRANT ALL PRIVILEGES ON *.* TO 'rangerdba'@'%'; GRANT ALL PRIVILEGES ON *.* TO 'rangerdba'@'localhost' WITH GRANT OPTION; #grant用于给增加用户和创建权限 grant用于给增加用户和创建权限 GRANT ALL PRIVILEGES ON *.* TO 'rangerdba'@'%' WITH GRANT OPTION; FLUSH PRIVILEGES;#说明: #连接:https://baijiahao.baidu.com/s?id=1704529867014054059&wfr=spider&for=pc #也就是说数据库的all priveleges包含下面的权限: INSERT, SELECT, UPDATE, DELETE, CREATE, DROP,REFERENCES, INDEX, ALTER, CREATE TEMPORARY TABLES,LOCK TABLES, EXECUTE,CREATE VIEW, SHOW VIEW,CREATE ROUTINE,ALTER ROUTINE,EVENT, TRIGGER -
Use the
exitcommand to exit MySQL. -
mysql -u rangerdba -prangerdba
- 使用以上命令重新尝试登陆,如果可以登陆说明配置正常
-
-
使用以下命令确认
mysql-connector-java.jar文件位于Java共享目录中。jdbc的驱动包
必须在安装Ambari服务器的服务器上运行此命令ls /usr/share/java/mysql-connector-java.jar如果该文件不在Java共享目录中,请使用以下命令安装MySQL连接器.jar文件。
RHEL/CentOS/Oracle/Aamazon Linux
yum install mysql-connector-java* -
使用安装包提供的
06-Ambari-DDL-MySQL-CREATE.sql在mysql中执行这个sql文件用来创建ambari相关的内容,先上传,然后登录到mysql数据后运行以下代码 使用root账号登录mysqlsource /usr/local/mysql/06-Ambari-DDL-MySQL-CREATE.sql show databases; use ambari; show tables; 111张表 创建好,表示已经为ambari service创建好了基本的表结构 运行完代码多了一个库 (ambari) -
再执行
GRANT ALL PRIVILEGES ON *.* TO 'ambari'@'%' WITH GRANT OPTION;- ambari可以远程访问 #grant用于给增加用户和创建权限 grant用于给增加用户和创建权限
- sql 里面创建了ambari账户,所以在这里需要设置账号ambari的权限
-
FLUSH PRIVILEGES;
#略 上面已经建立了这里不用运行了 只做参考hdp100 # CREATE DATABASE ambari; # use ambari; # CREATE USER 'ambari'@'%' IDENTIFIED BY 'ambari123'; # GRANT ALL PRIVILEGES ON *.* TO 'ambari'@'%'; # CREATE USER 'ambari'@'localhost' IDENTIFIED BY 'ambari123'; # GRANT ALL PRIVILEGES ON *.* TO 'ambari'@'localhost'; # CREATE USER 'ambari'@'hdp100' IDENTIFIED BY 'ambari123'; # GRANT ALL PRIVILEGES ON *.* TO 'ambari'@'hdp100'; #source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql #show tables; #use mysql; #select host,user from user where user='ambari'; #安装组件的时候用到,这里先进行设置建表和账号 CREATE DATABASE hive; use hive; CREATE USER 'hive'@'%' IDENTIFIED BY 'hive'; GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%'; CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hive'; GRANT ALL PRIVILEGES ON *.* TO 'hive'@'localhost'; CREATE USER 'hive'@'hdp100' IDENTIFIED BY 'hive'; GRANT ALL PRIVILEGES ON *.* TO 'hive'@'hdp100'; CREATE DATABASE oozie; use oozie; CREATE USER 'oozie'@'%' IDENTIFIED BY 'oozie'; GRANT ALL PRIVILEGES ON *.* TO 'oozie'@'%'; CREATE USER 'oozie'@'localhost' IDENTIFIED BY 'oozie'; GRANT ALL PRIVILEGES ON *.* TO 'oozie'@'localhost'; CREATE USER 'oozie'@'hdp100' IDENTIFIED BY 'oozie'; GRANT ALL PRIVILEGES ON *.* TO 'oozie'@'hdp100'; FLUSH PRIVILEGES; SELECT Host,user,authentication_string,Grant_priv FROM mysql.user; -
-
11.安装JDK配置JAVA_HOME(所有服务器均设置)
-
下载地址:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
-
D:\6、python全栈-人工智能-数据分析-爬虫\06-Linux环境编程基础\章节1:Linux\软件\软件\03 JDK压缩包\jdk-8u221-linux-x64.tar.gz
-
1、rz上传tar包 --jdk-8u221-linux-x64.tar.gz rz 2、tar -xzvf jdk-8u221-linux-x64.tar.gz -C /usr/local/ 解压的文件在usr/local/jdk1.8.0_221下 3、同步到其他机器,也需要jdk, pscp -h /clientnode.list -r /usr/local/jdk1.8.0_221 /usr/local/jdk1.8.0_221 没有安装pssh使用下面的语句 scp -r jdk1.8.0_221 hdp1:/usr/local/ 4、pwd 配置JDK和JAVA_HOME环境变量 vim /etc/profile 添加如下环境变量 export JAVA_HOME=/usr/local/jdk1.8.0_221 export PATH=$JAVA_HOME/bin:$PATH #自己的电脑配置如下: export JAVA_HOME=/usr/local/jdk1.8.0_221 export PATH=$JAVA_HOME/bin:$PATH 同步到其他节点 pscp -h /clientnode.list /etc/profile /etc/profile 5、source /etc/profile 两台机器都要配置 每台机器单独运行source /etc/profile pssh -h /node.list -i -P 'source /etc/profile' #这个不管用
2.部署HDP相关软件包的yum仓库
2.1部署仓库源,解压安装包
-
上传HDP的tar包
-
yum install yum-utils createrepo yum install httpd # 已经安装了 上面 systemctl enable httpd mkdir -p /var/www/html/ 这几步如果在前面做了 就不用做了 ``` cd /var/www/html/ 解压准备的 ambari hdp hdp-gpl hdp-utils 包到这个目录下/var/www/html/ tar -xzvf ambari-2.7.0.0-centos7.tar.gz #ambari service 和ambari agent相关的内容 tar -xzvf HDP-3.0.0.0-centos7-rpm.tar.gz # hive pig phoenix sqoop oozie hadoop flume 都在这个歌tar包里面 tar -xzvf HDP-GPL-3.0.0.0-centos7-gpl.tar.gz tar -xzvf HDP-UTILS-1.1.0.22-centos7.tar.gz yum install yum-plugin-priorities vim /etc/yum/pluginconf.d/priorities.conf 修改 [main] enabled=1 gpgcheck=0 systemctl start/stop/restart httpd # 使用start 来启动httpd服务 解压好后重启httpd服务 然后通过浏览器核验是否有可以看见 1.使用df -h查看磁盘空间占用情况 2.使用sudo du -s -h /* | sort -nr命令查看那个目录占用空间大 3.然后那个目录占用多 再通过sudo du -s -h /var/* | sort -nr 一层层排查,找到占用文件多的地方。 4.如果通过以上方法没有找到问题所在,那么可以使用 lsof | grep deleted 命令,看看是否删除掉的文件仍然被进程占用而没有进行实际删除。 5. 找到占用文件很大的进程,停止进程。 之后重新启动,就OK了。
设置用户组和授权
[root@hdp100 html]# chown -R root:root HDP
[root@hdp100 html]# chown -R root:root HDP-GPL
[root@hdp100 html]# chown -R root:root HDP-UTILS
[root@hdp100 html]# chmod -R 755 HDP
[root@hdp100 html]# chmod -R 755 HDP-GPL
[root@hdp100 html]# chmod -R 755 HDP-UTILS
2.2配置yum仓库的配置文件
制作本地源
-
配置ambari.repo
-
自己配的只修改了gpgkey和baseurl
-
vim /etc/yum.repos.d/ambari.repo #VERSION_NUMBER=2.7.0.0-897 [ambari-2.7.0.0] #json.url = http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json name=ambari Version - ambari-2.7.0.0 baseurl=http://hdp100/ambari/centos7/2.7.0.0-897/ gpgcheck=1 gpgkey=http://hdp100/ambari/centos7/2.7.0.0-897/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins enabled=1 priority=1 -
配置HDP和HDP-TILS
-
vim /etc/yum.repos.d/HDP.repo [HDP-3.1.5.0] name=HDP Version - HDP-3.0.0.0 baseurl=http://hdp100/HDP/centos7/3.0.0.0-1634/ gpgcheck=1 gpgkey=http://hdp100/HDP/centos7/3.0.0.0-1634/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins enabled=1 priority=1 [HDP-UTILS-1.1.0.22] name=HDP-UTILS Version - HDP-UTILS-1.1.0.22 baseurl=http://hdp100/HDP-UTILS/centos7/1.1.0.22/ gpgcheck=1 gpgkey=http://hdp100/HDP-UTILS/centos7/1.1.0.22/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins enabled=1 priority=1 [HDP-GPL-3.1.5.0] name=HDP-GPL Version - HDP-GPL-3.0.0.0 baseurl=http://hdp100/HDP-GPL/centos7/3.0.0.0-1634/ gpgcheck=1 gpgkey=http://hdp100/HDP-GPL/centos7/3.0.0.0-1634/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins enabled=1 priority=1
-
-
配置libtirpc.repo
vim /etc/yum.repos.d/libtirpc.repo [libtirpc_repo] name=libtirpc-0.2.4-0.15 baseurl=http://hdp100/libtirpc/ gpgcheck=0 enabled=1 priority=1 -
拷贝到其他节点并查看源
pscp -h /clientnode.list /etc/yum.repos.d/ambari.repo /etc/yum.repos.d/ambari.repo pscp -h /clientnode.list /etc/yum.repos.d/libtirpc.repo /etc/yum.repos.d/libtirpc.repo pscp -h /clientnode.list /etc/yum.repos.d/HDP.repo /etc/yum.repos.d/HDP.repo pssh -h /node.list -i 'yum clean all' pssh -h /node.list -i 'yum repolist'libtirpc.repo的本地源失败,可能是没有运行以下命令,像屏蔽此源,手动安装相关软件,相关包 createrepo 手动安装 1. 将安装包提供的`libtirpc-0.2.4-0.15.el7.x86_64.rpm` 和 `libtirpc-devel-0.2.4-0.15.el7.x86_64.rpm`上传到服务器进行安装 pscp -h /clientnode.list /var/www/html/libtirpc/libtirpc-* /opt/ pssh -h /clientnode.list -i -P 'ls /opt/' pssh -h /clientnode.list -i -P 'rpm -ivh /opt/libtirpc-0.2.4-0.15.el7.x86_64.rpm' pssh -h /clientnode.list -i -P 'rpm -ivh /opt/libtirpc-devel-0.2.4-0.15.el7.x86_64.rpm' 主机上直接安装 rpm -ivh libtirpc-0.2.4-0.15.el7.x86_64.rpm 所有的节点都要安装 可以使用`rz`命令快速上传,如果`rz`提示无这个命令使用:`yum install lrzsz`来安装即可 2. `yum install nmap ` 所有的节点都要安装 #不管用pssh -h /clientnode.list -i -P 'rename libtirpc.repo libtirpc.repo.bak /etc/yum.repo.d/* ' 手动一台一台主机改 mv libtirpc.repo libtirpc.repo.bak 拷贝到其他节点并查看源 pssh -h /node.list -i 'yum clean all' pssh -h /node.list -i 'yum repolist'克隆了主机和一台从机 用于后续重新安装ambari20230224 到这里 以下出错了
3. 安装AmbariServer
3.1 安装
Steps
-
安装ambari-server
yum install ambari-server -
输入y表示继续安装,正常输出应该如下:
默认的是postgre数据库,我们需要使用mysql替换,不用postgre
Installing : postgresql-libs-9.2.18-1.el7.x86_64 1/4 Installing : postgresql-9.2.18-1.el7.x86_64 2/4 Installing : postgresql-server-9.2.18-1.el7.x86_64 3/4 Installing : ambari-server-2.7.0.0-896.x86_64 4/4 Verifying : ambari-server-2.7.0.0-896.x86_64 1/4 Verifying : postgresql-9.2.18-1.el7.x86_64 2/4 Verifying : postgresql-server-9.2.18-1.el7.x86_64 3/4 Verifying : postgresql-libs-9.2.18-1.el7.x86_64 4/4 Installed: ambari-server.x86_64 0:2.7.0.0-896 Dependency Installed: postgresql.x86_64 0:9.2.18-1.el7 postgresql-libs.x86_64 0:9.2.18-1.el7 postgresql-server.x86_64 0:9.2.18-1.el7 Complete!
3.2 setup Ambari Server
执行: ambari-server setup
进行设置
按照提示内容选择
-
是否让ambari来控制各个服务组件的账户,默认即可 y,n
-
选择JDk 2自定义
-
输入jdk路径:Path to JAVA_HOME: /usr/local/jdk1.8.0_221
-
Enable Ambari Server to download and install GPL Licensed LZO packages [y/n] (n)?
输入 y
-
Enter advanced database configuration [y/n] (n)?
输入y 要配置数据库,之前配置了mysql,不配置的话就是用默认的postgre
-
输入3选择为mysql
-
回车,因为mysql就是安装在这台机子上 localhost
-
端口也回车 没有改变默认就是3306
-
之前使用了sql语句已经建立了ambari数据库,上传的sql语句
-
Enter choice (1): 3
Hostname (localhost):Port (3306):
Database name (ambari):
Username (ambari):
Enter Database Password (bigdata): -
Should ambari use existing default jdbc /usr/share/java/mysql-connector-java.jar [y/n] (y)?
是否使用已经存在的jdbc 连接器 我们刚刚已经安装了所以选择y就行
-
是否配置远程数据库连接
Proceed with configuring remote database connection properties [y/n] (y)? y
-
配置数据库,选择Mysql提供host port username password等信息
-
等
然后执行:设置jdbc的连接jar包,确保没有问题所以重新设置一下
ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar
More Information
Setup Options
Configuring Ambari for Non-Root
Changing your JDK
Configuring LZO compression
Using an existing database with Ambari
[Setting up Ambari to use an Internet proxy server
3. 在Ambari Server UI中进行基础安装配置
3.1 进入Ambari Server UI
先启动 ambari-server start
输入http://ip-or-host:8080
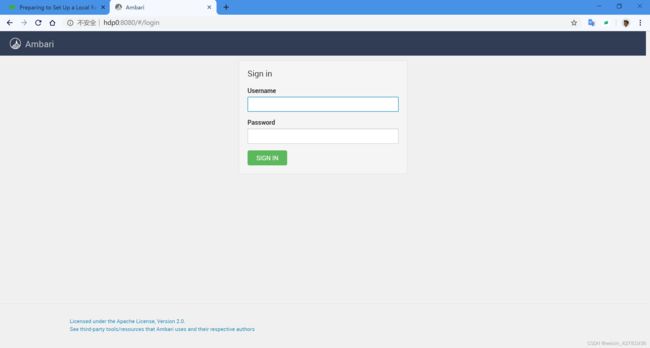
默认账户密码: admin / admin
3.2 启动安装
输入账号密码登陆

点击 LAUNCH INSTALL WIZARD
启动安装流程
3.3 安装过程
- 给定集群一个名称,这里使用
itcast_test
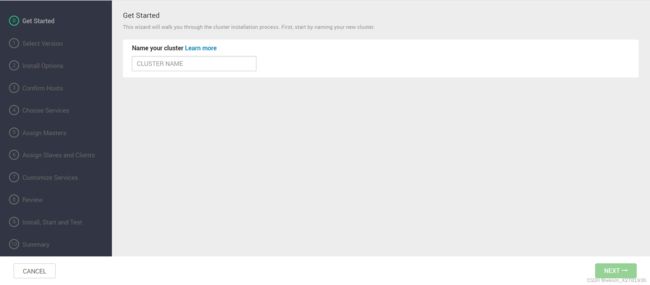
- 选择版本,由于没有网络,默认只能使用HDP 3.0
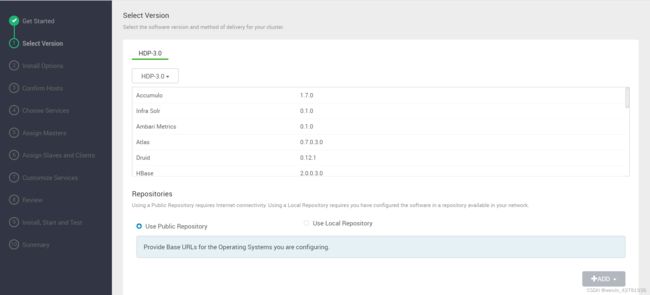
-
选择本地仓库, 输入配置本地仓库时定义的url,其他的os删除,centos就是redhat
http://hdp100/HDP/centos7/3.0.0.0-1634
http://hdp100/HDP-GPL/centos7/3.0.0.0-1634
http://hdp100/HDP-UTILS/centos7/1.1.0.22

-
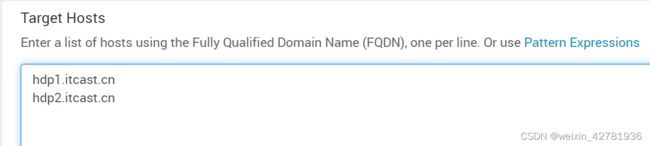
安装选项
-
输入目标主机列表,回车分隔(这个图片少了一个 hdp0.itcast.cn的主机, 因为老师是虚拟机资源有限,所以尽量将Ambari Server这个机器也复用上了,资源丰富的同学,可以不加这个机器也可以的. Ambari Server 和 集群可以相互独立,只要在在一个网络内互通即可)
输入FQDN形式的主机名 目标主机就是用于安装ambari agent的,安装ambari agent后才可以安装hadoop,hive等这些组件 hdp0.itdragon.com hdp1.itdragon.com
-
-
上传Ambari Server 所在机器root账户的 私钥,方便Ambari Server 以root身份ssh到其他节点
/root/.ssh
cat id_rsa
-----BEGIN RSA PRIVATE KEY----- MIIEpQIBAAKCAQEA4BSgg33iNLwujlg9NlL1uOYflsIRlgxZVrXgci7EKOFdG9JW daHMBh5FWSK2UaCL1Sk9WSZkdfX9rkQrNdHGYo6ysU+zzPyzCdzfHVF8SuqSTMvl zgSbzwdZ1V48u91+Ufex4b/eA5zXvj5Uy6/Ds3nlUaFY8LTpHCfvG/1Au+2e3ODO Nuk0JFmUR+V9Uouo2BMXvwA5ms6hvFAczMY2zG0KokzE0buGrP6YybLKnqmBnUKy rD5L5G9e8byd9XbGRqZNqiV9sybUNEyHHySgXM2cQf3SMDEoDLQPIUyx4D8FV0JJ AnH90Y93aq07WI6oEoB0yLbZOkqA6Kz3PrGq6QIDAQABAoIBAHTQrAEAfg1J0Odp /rc0Nl8msG8SSsKzO1ulwxUjZiV9nuFjHKmEKG1EGJjoLK2PCXadYhr4lcSc8ZuI dBJBgq9cfrFKwIvrbJaGq1WIZkhT0uLwJKPq6SLbTSybTQQO6sxmWTg7osy1Vg8a RXBN97K3qCGPAGOznBaOhutLchTFSGHkAfOoeKiotJ1EEzBEgItfJ6NHgbleCPly gEus9BcWj8lomHtHakspAFD3krrCZqzm3gZgy4dnEL7JuOeMv0MB2T7y9Rb/Hr3U xIw5q+ZiakGAAdMAc2ywXmQ+niLhmJRkJHOQnAbC3wt5dIzDBGJR4iGf6ZEuEKUH DIxnRoECgYEA+ra50PEpImLXo0UF/DTGi31X+fWJQeK48+QRsnZfFbrCAMWTeStL PT/Kl16hfRh1WsI80XgG4M/cqP2B6qai3ZHw7J6BWBtf3GqQkmIaVHgMdQALf78D VGrLS/K2+N3Kc075B3zsxO1yBUEYMkwgQZFtca/C3nL5vQFW/QpweHECgYEA5M4k vhvLJEcZMa8Wj1P6HUm1fxp6fUavyyV6hOBmhDlmHGSKOZmvrHkOEI3u/pMyGG3e H0Rdh1PiiHjppoH8RJo8GD6ZkujIci4KMhGwAwQJHolNB8vZrx4nK+KeyVNh3UUp aWMDs1E1A1ZwdisO/3E5dooAFkFAq+cZLpO/VfkCgYEA6NNaGkRq28kI0lGeLkng e9eKJNG1hp8C/VM2cBHnWWmXElppCqR++cFM5Wd29pIJIaCyFCCv2oSOOc06oevf 4X3PTB4ipey+CBZabeZ25yyY/Opuw1JiyDlo0/3xl4l4ob6cGy0TQAn10hVSYBs7 9UgVZ/c+M5B4heJBoznXmrECgYEAlYMjPVsaFn2jN/Uqr8P3V3YX9JOP4Rb0vrGh 6vxb4SFE2V7VeCg2RGTiTO0CdDYpcQ8yK4pX95tYF0eznouoFggXJtyZLAeTHBF7 thYaxw23C846mNKbT7RLcoDms7YZ6CZOlkAOZfm1w5WTbZRbe444N36b6e7/3JTp vqbrS7kCgYEAoCtbLrPTXtc6dnQzqV6g7sdkqyWVsVhW37MEODDMTX64Fa7w1zeJ mAslwsqizcjCuWqWdrOnEP9+CqJO0TkhUIomzpXXk3Lkmi7Ef2h/kXYbMB0Z3Oj3 A5HFxdYdBzFFrnEPJleUNF0t9vJccyAsm1rY7pBAkT118ZF3DnXghic= -----END RSA PRIVATE KEY-----

- 确认主机,正常如下,如果有警告请检查,然后运行重新检查来通过所有的主机检查

- 选择服务组件,这里先安装一个最基本的zookeeper + Ambari Metrics

- 分配服务组件到各个主机上(自行分配即可)

- 分配客户端,将两个客户端机器勾选
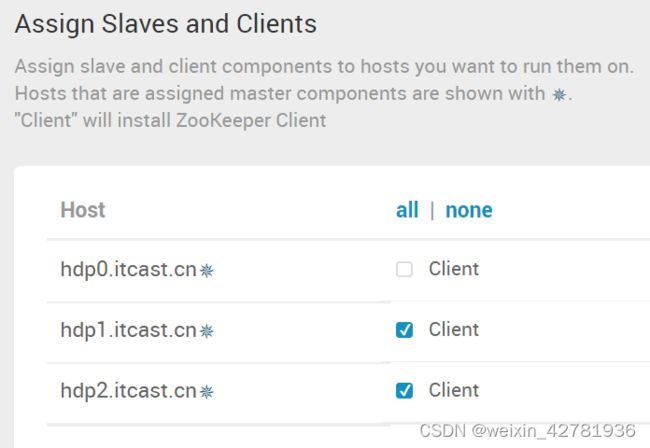
-
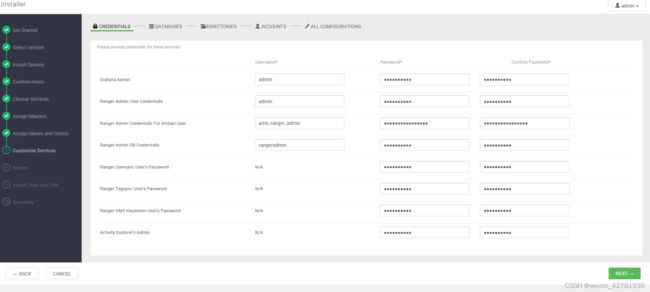
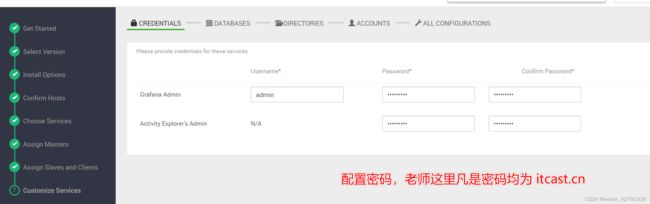
自定义服务
密码都设置为bigdata123
ranger介绍:
https://blog.csdn.net/sinat_28007043/article/details/103320824
包含的内部组件如下:
Ranger Admin 用户管理策略,提供WebUI和RestFul接口
Ranger UserSync 用于将Unix系统或LDAP用户/组同步到RangerAdmin
Ranger TagSync 同步Atlas中的Tag信息,基于标签的权限管理,当一个用户的请求涉及到多个应用系统中的多个资源的权限时,可以通过只配置这些资源的tag方便快速的授权
Ranger KMS 对hadoop KMS的策略管理和密钥管理
注:Apache atlas 是Hadoop社区为解决Hadoop生态系统的元数据治理问题而产生的开源项目,它为Hadoop集群提供了包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心能力。
报错:
rpm -ivh libdb-devel-5.3.21-24.el7.x86_64.rpm --nodeps --force 上次rpm包并安装 每台都上次并安装 在https://vault.centos.org/7.5.1804/os/x86_64/Packages/下载
https://vault.centos.org/7.6.1810/os/x86_64/Packages/
下载glibc-common-2.17-260.el7.x86_64.rpm 上传到所有主机并安装


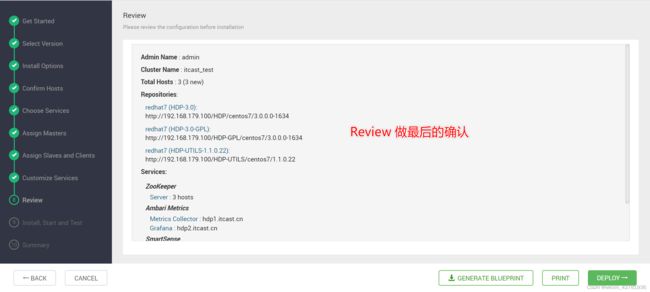
- 点击Deploy进行部署
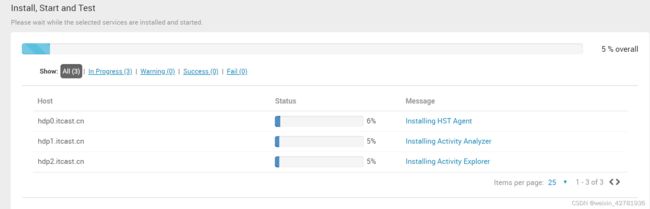
等待部署完成。。。
部署完成后,点击下一步
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nAOAej4V-1677642246527)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567405180883.png)]
-
总结
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TyUojk2y-1677642246528)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567405197314.png)]
点击Complete,进入集群控制页面
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xpzi2jlc-1677642246528)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567405467884.png)]
这两个警告可以忽略
- 是说磁盘空间不足,演示机器虚拟机磁盘没有配置太大
- 说SmartSense 服务无法连接网络,离线安装正常,如果可以联网让Ambari Server主机接入网络即可
4. 测试以及安装其他服务
4.1 安装、测试HDFS
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FvwooVm6-1677642246528)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567409167506.png)]
如图,点击添加service
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WQuuUpWk-1677642246528)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567409229971.png)]
选择HDFS
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-471DQduU-1677642246529)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567409252017.png)]
分配Master节点
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yAqZTsqw-1677642246529)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567409300667.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9W3Kock6-1677642246529)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567409338015.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rW79nDs7-1677642246529)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567409391546.png)]
点击Deploy进行部署,等待其完成
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wtfAE15B-1677642246530)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567409429245.png)]
安装完毕后可以在主页这里看到HDFS相关服务
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uo4rpe4R-1677642246530)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567411134186.png)]
执行测试
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M4LE5Znn-1677642246530)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567411160977.png)]
4.2 部署、测试HBase
同HDFS一样
- 在Service那里点击三个小引号
- 点击Add service
- 选择HBase
- 配置主机和相关配置
- Deploy开始部署
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YoPnUsjl-1677642246530)(D:\原电脑E盘\学习资料\java大数据1\第2阶段大数据环境搭建和云平台\1全程实操从零学习掌握HDP集群\HDP-环境配置资料\01-课件.assets\1567411235913.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HNnsyzQF-1677642246531)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567411259762.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AE9zZGnp-1677642246531)(D:\原电脑E盘\学习资料\java大数据1\第2阶段大数据环境搭建和云平台\1全程实操从零学习掌握HDP集群\HDP-环境配置资料\01-课件.assets\1567411277333.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FwsW6wmH-1677642246531)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567411659389.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vG9oKGCi-1677642246531)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567411697605.png)]
安装完成后进行测试:
su - hbase
hbase shell
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rAgy4TX0-1677642246532)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567411782350.png)]
4.3 部署、测试Yarn、MapReduce
同上
- 点击Add Service
- 添加 YARN + MapReduce2
- 配置节点和相关配置
- 点击Deploy
- 完成后即可使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8CUqjeLF-1677642246532)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567411862921.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2t7t7yJZ-1677642246532)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567411914209.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kSglYwKy-1677642246532)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567414259307.png)]
安装完成后即能看到这两个服务。
运行测试
[hdfs@hdp1 ~]$ hadoop jar /usr/hdp/3.0.0.0-1634/hadoop-mapreduce/hadoop-mapreduce-examples-3.1.0.3.0.0.0-1634.jar wordcount /test.txt /wd-output
19/09/02 17:29:42 INFO client.RMProxy: Connecting to ResourceManager at hdp2.itcast.cn/192.168.179.102:8050
19/09/02 17:29:42 INFO client.AHSProxy: Connecting to Application History server at hdp1.itcast.cn/192.168.179.101:10200
19/09/02 17:29:43 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /user/hdfs/.staging/job_1567416408889_0001
19/09/02 17:29:44 INFO input.FileInputFormat: Total input files to process : 1
19/09/02 17:29:44 INFO mapreduce.JobSubmitter: number of splits:1
19/09/02 17:29:45 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1567416408889_0001
19/09/02 17:29:45 INFO mapreduce.JobSubmitter: Executing with tokens: []
19/09/02 17:29:45 INFO conf.Configuration: found resource resource-types.xml at file:/etc/hadoop/3.0.0.0-1634/0/resource-types.xml
19/09/02 17:29:45 INFO impl.YarnClientImpl: Submitted application application_1567416408889_0001
19/09/02 17:29:45 INFO mapreduce.Job: The url to track the job: http://hdp2.itcast.cn:8088/proxy/application_1567416408889_0001/
19/09/02 17:29:45 INFO mapreduce.Job: Running job: job_1567416408889_0001
19/09/02 17:30:03 INFO mapreduce.Job: Job job_1567416408889_0001 running in uber mode : false
19/09/02 17:30:03 INFO mapreduce.Job: map 0% reduce 0%
19/09/02 17:30:15 INFO mapreduce.Job: map 100% reduce 0%
19/09/02 17:30:21 INFO mapreduce.Job: map 100% reduce 100%
19/09/02 17:30:21 INFO mapreduce.Job: Job job_1567416408889_0001 completed successfully
19/09/02 17:30:21 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=28
FILE: Number of bytes written=457715
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=111
HDFS: Number of bytes written=14
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=6720
Total time spent by all reduces in occupied slots (ms)=7544
Total time spent by all map tasks (ms)=6720
Total time spent by all reduce tasks (ms)=3772
Total vcore-milliseconds taken by all map tasks=6720
Total vcore-milliseconds taken by all reduce tasks=3772
Total megabyte-milliseconds taken by all map tasks=1720320
Total megabyte-milliseconds taken by all reduce tasks=1931264
Map-Reduce Framework
Map input records=2
Map output records=2
Map output bytes=18
Map output materialized bytes=28
Input split bytes=100
Combine input records=2
Combine output records=2
Reduce input groups=2
Reduce shuffle bytes=28
Reduce input records=2
Reduce output records=2
Spilled Records=4
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=153
CPU time spent (ms)=1300
Physical memory (bytes) snapshot=364044288
Virtual memory (bytes) snapshot=4220051456
Total committed heap usage (bytes)=225247232
Peak Map Physical memory (bytes)=222789632
Peak Map Virtual memory (bytes)=2021199872
Peak Reduce Physical memory (bytes)=141254656
Peak Reduce Virtual memory (bytes)=2198851584
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=11
File Output Format Counters
Bytes Written=14
[hdfs@hdp1 ~]$ hadoop fs -cat /wd-output/*
HDP 1
Hello 1
4.4 部署、测试Kafka
- 点击Add Service
- 选择Kafka
- 配置主机以及配置文件(没有特殊需求可以默认)
- 点击Deploy进行部署
- 等待完成
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PDW7vfrd-1677642246533)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567416851545.png)]
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test1
Created topic "test1".
[root@hdp0 bin]# ./kafka-console-producer.sh --broker-list hdp0.itcast.cn:6667 --topic test
>aaa
>ddd
>ddd
>Hello Kafka From HDP
[root@hdp0 bin]# ./kafka-console-consumer.sh --bootstrap-server hdp0.itcast.cn:6667 --topic test --from-beginning
aaa
ddd
ddd
Hello Kafka From HDP
4.5 部署、测试 Spark2
部署Spark2要求按照Tez、Hive,在安装的时候同时装上即可
同上面步骤
- 点击Add Service
- 选择Spark2
- 在弹出是否安装Tez以及Hive的框框内选择ok即可
- 配置主机以及配置文件
- 等待安装完成
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-msv57iy1-1677642246533)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567420668014.png)]
测试Spark
[spark@hdp1 spark2]$ ./bin/run-example SparkPi
19/09/02 22:56:37 INFO SparkContext: Running Spark version 2.3.1.3.0.0.0-1634
19/09/02 22:56:37 INFO SparkContext: Submitted application: Spark Pi
19/09/02 22:56:37 INFO SecurityManager: Changing view acls to: spark
19/09/02 22:56:37 INFO SecurityManager: Changing modify acls to: spark
19/09/02 22:56:37 INFO SecurityManager: Changing view acls groups to:
19/09/02 22:56:37 INFO SecurityManager: Changing modify acls groups to:
19/09/02 22:56:37 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); groups with view permissions: Set(); users with modify permissions: Set(spark); groups with modify permissions: Set()
19/09/02 22:56:37 INFO Utils: Successfully started service 'sparkDriver' on port 37188.
19/09/02 22:56:37 INFO SparkEnv: Registering MapOutputTracker
19/09/02 22:56:37 INFO SparkEnv: Registering BlockManagerMaster
19/09/02 22:56:37 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
19/09/02 22:56:37 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
19/09/02 22:56:37 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-7a9c2f0e-23f1-4117-825c-fcd1b0ddc2fb
19/09/02 22:56:37 INFO MemoryStore: MemoryStore started with capacity 366.3 MB
19/09/02 22:56:37 INFO SparkEnv: Registering OutputCommitCoordinator
19/09/02 22:56:37 INFO log: Logging initialized @1581ms
19/09/02 22:56:37 INFO Server: jetty-9.3.z-SNAPSHOT
19/09/02 22:56:37 INFO Server: Started @1726ms
19/09/02 22:56:37 INFO AbstractConnector: Started ServerConnector@6e4deef2{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
19/09/02 22:56:37 INFO Utils: Successfully started service 'SparkUI' on port 4040.
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@d02f8d{/jobs,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@710d7aff{/jobs/json,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@2d7e1102{/jobs/job,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@301d8120{/jobs/job/json,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@6d367020{/stages,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@72458efc{/stages/json,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@36bc415e{/stages/stage,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@6a714237{/stages/stage/json,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@3e134896{/stages/pool,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@72ba28ee{/stages/pool/json,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@2e3a5237{/storage,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@4ebadd3d{/storage/json,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@6ac97b84{/storage/rdd,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@4917d36b{/storage/rdd/json,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@35c09b94{/environment,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@2d0bfb24{/environment/json,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@c3fa05a{/executors,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@7b44b63d{/executors/json,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@4a699efa{/executors/threadDump,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@38499e48{/executors/threadDump/json,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@4905c46b{/static,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@511d5d04{/,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@682c1e93{/api,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@5b78fdb1{/jobs/job/kill,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@48bfb884{/stages/stage/kill,null,AVAILABLE,@Spark}
19/09/02 22:56:37 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://hdp1.itcast.cn:4040
19/09/02 22:56:38 INFO RMProxy: Connecting to ResourceManager at hdp0.itcast.cn/192.168.179.100:8050
19/09/02 22:56:38 INFO Client: Requesting a new application from cluster with 1 NodeManagers
19/09/02 22:56:38 INFO Configuration: found resource resource-types.xml at file:/etc/hadoop/3.0.0.0-1634/0/resource-types.xml
19/09/02 22:56:38 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (3072 MB per container)
19/09/02 22:56:38 INFO Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
19/09/02 22:56:38 INFO Client: Setting up container launch context for our AM
19/09/02 22:56:38 INFO Client: Setting up the launch environment for our AM container
19/09/02 22:56:38 INFO Client: Preparing resources for our AM container
19/09/02 22:56:39 INFO Client: Use hdfs cache file as spark.yarn.archive for HDP, hdfsCacheFile:hdfs://hdp0.itcast.cn:8020/hdp/apps/3.0.0.0-1634/spark2/spark2-hdp-yarn-archive.tar.gz
19/09/02 22:56:39 INFO Client: Source and destination file systems are the same. Not copying hdfs://hdp0.itcast.cn:8020/hdp/apps/3.0.0.0-1634/spark2/spark2-hdp-yarn-archive.tar.gz
19/09/02 22:56:39 INFO Client: Distribute hdfs cache file as spark.sql.hive.metastore.jars for HDP, hdfsCacheFile:hdfs://hdp0.itcast.cn:8020/hdp/apps/3.0.0.0-1634/spark2/spark2-hdp-hive-archive.tar.gz
19/09/02 22:56:39 INFO Client: Source and destination file systems are the same. Not copying hdfs://hdp0.itcast.cn:8020/hdp/apps/3.0.0.0-1634/spark2/spark2-hdp-hive-archive.tar.gz
19/09/02 22:56:39 INFO Client: Uploading resource file:/usr/hdp/3.0.0.0-1634/spark2/examples/jars/scopt_2.11-3.7.0.jar -> hdfs://hdp0.itcast.cn:8020/user/spark/.sparkStaging/application_1567435113751_0003/scopt_2.11-3.7.0.jar
19/09/02 22:56:40 INFO Client: Uploading resource file:/usr/hdp/3.0.0.0-1634/spark2/examples/jars/spark-examples_2.11-2.3.1.3.0.0.0-1634.jar -> hdfs://hdp0.itcast.cn:8020/user/spark/.sparkStaging/application_1567435113751_0003/spark-examples_2.11-2.3.1.3.0.0.0-1634.jar
19/09/02 22:56:40 INFO Client: Uploading resource file:/tmp/spark-71285c61-5876-49e5-aff0-e2f5221c5fac/__spark_conf__6021223147298639101.zip -> hdfs://hdp0.itcast.cn:8020/user/spark/.sparkStaging/application_1567435113751_0003/__spark_conf__.zip
19/09/02 22:56:41 INFO SecurityManager: Changing view acls to: spark
19/09/02 22:56:41 INFO SecurityManager: Changing modify acls to: spark
19/09/02 22:56:41 INFO SecurityManager: Changing view acls groups to:
19/09/02 22:56:41 INFO SecurityManager: Changing modify acls groups to:
19/09/02 22:56:41 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); groups with view permissions: Set(); users with modify permissions: Set(spark); groups with modify permissions: Set()
19/09/02 22:56:41 INFO Client: Submitting application application_1567435113751_0003 to ResourceManager
19/09/02 22:56:41 INFO YarnClientImpl: Submitted application application_1567435113751_0003
19/09/02 22:56:41 INFO SchedulerExtensionServices: Starting Yarn extension services with app application_1567435113751_0003 and attemptId None
19/09/02 22:56:42 INFO Client: Application report for application_1567435113751_0003 (state: ACCEPTED)
19/09/02 22:56:42 INFO Client:
client token: N/A
diagnostics: [Mon Sep 02 22:56:41 +0800 2019] Application is added to the scheduler and is not yet activated. Queue's AM resource limit exceeded. Details : AM Partition = ; AM Resource Request = ; Queue Resource Limit for AM = ; User AM Resource Limit of the queue = ; Queue AM Resource Usage = ;
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1567436201045
final status: UNDEFINED
tracking URL: http://hdp0.itcast.cn:8088/proxy/application_1567435113751_0003/
user: spark
19/09/02 22:56:43 INFO Client: Application report for application_1567435113751_0003 (state: ACCEPTED)
19/09/02 22:58:24 INFO YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> hdp0.itcast.cn, PROXY_URI_BASES -> http://hdp0.itcast.cn:8088/proxy/application_1567435113751_0003), /proxy/application_1567435113751_0003
19/09/02 22:58:24 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /jobs, /jobs/json, /jobs/job, /jobs/job/json, /stages, /stages/json, /stages/stage, /stages/stage/json, /stages/pool, /stages/pool/json, /storage, /storage/json, /storage/rdd, /storage/rdd/json, /environment, /environment/json, /executors, /executors/json, /executors/threadDump, /executors/threadDump/json, /static, /, /api, /jobs/job/kill, /stages/stage/kill.
19/09/02 22:58:24 INFO YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)
19/09/02 22:58:24 INFO Client: Application report for application_1567435113751_0003 (state: RUNNING)
19/09/02 22:58:24 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.179.101
ApplicationMaster RPC port: 0
queue: default
start time: 1567436201045
final status: UNDEFINED
tracking URL: http://hdp0.itcast.cn:8088/proxy/application_1567435113751_0003/
user: spark
19/09/02 22:58:24 INFO YarnClientSchedulerBackend: Application application_1567435113751_0003 has started running.
19/09/02 22:58:24 INFO Utils: Successfully started service ' org.apache.spark.network.netty.NettyBlockTransferService' on port 46513.
19/09/02 22:58:24 INFO NettyBlockTransferService: Server created on hdp1.itcast.cn:46513
19/09/02 22:58:24 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
19/09/02 22:58:24 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, hdp1.itcast.cn, 46513, None)
19/09/02 22:58:24 INFO BlockManagerMasterEndpoint: Registering block manager hdp1.itcast.cn:46513 with 366.3 MB RAM, BlockManagerId(driver, hdp1.itcast.cn, 46513, None)
19/09/02 22:58:24 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, hdp1.itcast.cn, 46513, None)
19/09/02 22:58:24 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, hdp1.itcast.cn, 46513, None)
19/09/02 22:58:24 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /metrics/json.
19/09/02 22:58:24 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@1cd2ff5b{/metrics/json,null,AVAILABLE,@Spark}
19/09/02 22:58:25 INFO EventLoggingListener: Logging events to hdfs:/spark2-history/application_1567435113751_0003
19/09/02 22:58:25 INFO YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after waiting maxRegisteredResourcesWaitingTime: 30000(ms)
19/09/02 22:58:25 INFO SparkContext: Starting job: reduce at SparkPi.scala:38
19/09/02 22:58:25 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 2 output partitions
19/09/02 22:58:25 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
19/09/02 22:58:25 INFO DAGScheduler: Parents of final stage: List()
19/09/02 22:58:25 INFO DAGScheduler: Missing parents: List()
19/09/02 22:58:25 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
19/09/02 22:58:26 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1832.0 B, free 366.3 MB)
19/09/02 22:58:26 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1181.0 B, free 366.3 MB)
19/09/02 22:58:26 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on hdp1.itcast.cn:46513 (size: 1181.0 B, free: 366.3 MB)
19/09/02 22:58:26 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1039
19/09/02 22:58:26 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1))
19/09/02 22:58:26 INFO YarnScheduler: Adding task set 0.0 with 2 tasks
19/09/02 22:58:27 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.179.101:49994) with ID 1
19/09/02 22:58:28 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, hdp1.itcast.cn, executor 1, partition 0, PROCESS_LOCAL, 7864 bytes)
19/09/02 22:58:28 INFO BlockManagerMasterEndpoint: Registering block manager hdp1.itcast.cn:37982 with 366.3 MB RAM, BlockManagerId(1, hdp1.itcast.cn, 37982, None)
19/09/02 22:58:28 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on hdp1.itcast.cn:37982 (size: 1181.0 B, free: 366.3 MB)
19/09/02 22:58:28 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, hdp1.itcast.cn, executor 1, partition 1, PROCESS_LOCAL, 7864 bytes)
19/09/02 22:58:28 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 887 ms on hdp1.itcast.cn (executor 1) (1/2)
19/09/02 22:58:28 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 63 ms on hdp1.itcast.cn (executor 1) (2/2)
19/09/02 22:58:28 INFO YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
19/09/02 22:58:28 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 3.021 s
19/09/02 22:58:28 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 3.118064 s
Pi is roughly 3.139395696978485
19/09/02 22:58:28 INFO AbstractConnector: Stopped Spark@6e4deef2{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
19/09/02 22:58:28 INFO SparkUI: Stopped Spark web UI at http://hdp1.itcast.cn:4040
19/09/02 22:58:29 INFO YarnClientSchedulerBackend: Interrupting monitor thread
19/09/02 22:58:29 INFO YarnClientSchedulerBackend: Shutting down all executors
19/09/02 22:58:29 INFO YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
19/09/02 22:58:29 INFO SchedulerExtensionServices: Stopping SchedulerExtensionServices
(serviceOption=None,
services=List(),
started=false)
19/09/02 22:58:29 INFO YarnClientSchedulerBackend: Stopped
19/09/02 22:58:29 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
19/09/02 22:58:29 INFO MemoryStore: MemoryStore cleared
19/09/02 22:58:29 INFO BlockManager: BlockManager stopped
19/09/02 22:58:29 INFO BlockManagerMaster: BlockManagerMaster stopped
19/09/02 22:58:29 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
19/09/02 22:58:29 INFO SparkContext: Successfully stopped SparkContext
19/09/02 22:58:29 INFO ShutdownHookManager: Shutdown hook called
19/09/02 22:58:29 INFO ShutdownHookManager: Deleting directory /tmp/spark-71285c61-5876-49e5-aff0-e2f5221c5fac
19/09/02 22:58:29 INFO ShutdownHookManager: Deleting directory /tmp/spark-c664407b-f0e3-435e-b49b-7d4b9d2c0ef2
密码 :bigdata123!
最后来一张Ambari Server UI的全景图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aeHv8wMn-1677642246533)(E:\23年笔记\hdp安装教程笔记\笔记的图片\1567436474126.png)]
TaskSet 0.0, whose tasks have all completed, from pool
19/09/02 22:58:28 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 3.021 s
19/09/02 22:58:28 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 3.118064 s
Pi is roughly 3.139395696978485
19/09/02 22:58:28 INFO AbstractConnector: Stopped Spark@6e4deef2{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
19/09/02 22:58:28 INFO SparkUI: Stopped Spark web UI at http://hdp1.itcast.cn:4040
19/09/02 22:58:29 INFO YarnClientSchedulerBackend: Interrupting monitor thread
19/09/02 22:58:29 INFO YarnClientSchedulerBackend: Shutting down all executors
19/09/02 22:58:29 INFO YarnSchedulerBackend Y a r n D r i v e r E n d p o i n t : A s k i n g e a c h e x e c u t o r t o s h u t d o w n 19 / 09 / 0222 : 58 : 29 I N F O S c h e d u l e r E x t e n s i o n S e r v i c e s : S t o p p i n g S c h e d u l e r E x t e n s i o n S e r v i c e s ( s e r v i c e O p t i o n = N o n e , s e r v i c e s = L i s t ( ) , s t a r t e d = f a l s e ) 19 / 09 / 0222 : 58 : 29 I N F O Y a r n C l i e n t S c h e d u l e r B a c k e n d : S t o p p e d 19 / 09 / 0222 : 58 : 29 I N F O M a p O u t p u t T r a c k e r M a s t e r E n d p o i n t : M a p O u t p u t T r a c k e r M a s t e r E n d p o i n t s t o p p e d ! 19 / 09 / 0222 : 58 : 29 I N F O M e m o r y S t o r e : M e m o r y S t o r e c l e a r e d 19 / 09 / 0222 : 58 : 29 I N F O B l o c k M a n a g e r : B l o c k M a n a g e r s t o p p e d 19 / 09 / 0222 : 58 : 29 I N F O B l o c k M a n a g e r M a s t e r : B l o c k M a n a g e r M a s t e r s t o p p e d 19 / 09 / 0222 : 58 : 29 I N F O O u t p u t C o m m i t C o o r d i n a t o r YarnDriverEndpoint: Asking each executor to shut down 19/09/02 22:58:29 INFO SchedulerExtensionServices: Stopping SchedulerExtensionServices (serviceOption=None, services=List(), started=false) 19/09/02 22:58:29 INFO YarnClientSchedulerBackend: Stopped 19/09/02 22:58:29 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 19/09/02 22:58:29 INFO MemoryStore: MemoryStore cleared 19/09/02 22:58:29 INFO BlockManager: BlockManager stopped 19/09/02 22:58:29 INFO BlockManagerMaster: BlockManagerMaster stopped 19/09/02 22:58:29 INFO OutputCommitCoordinator YarnDriverEndpoint:Askingeachexecutortoshutdown19/09/0222:58:29INFOSchedulerExtensionServices:StoppingSchedulerExtensionServices(serviceOption=None,services=List(),started=false)19/09/0222:58:29INFOYarnClientSchedulerBackend:Stopped19/09/0222:58:29INFOMapOutputTrackerMasterEndpoint:MapOutputTrackerMasterEndpointstopped!19/09/0222:58:29INFOMemoryStore:MemoryStorecleared19/09/0222:58:29INFOBlockManager:BlockManagerstopped19/09/0222:58:29INFOBlockManagerMaster:BlockManagerMasterstopped19/09/0222:58:29INFOOutputCommitCoordinatorOutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
19/09/02 22:58:29 INFO SparkContext: Successfully stopped SparkContext
19/09/02 22:58:29 INFO ShutdownHookManager: Shutdown hook called
19/09/02 22:58:29 INFO ShutdownHookManager: Deleting directory /tmp/spark-71285c61-5876-49e5-aff0-e2f5221c5fac
19/09/02 22:58:29 INFO ShutdownHookManager: Deleting directory /tmp/spark-c664407b-f0e3-435e-b49b-7d4b9d2c0ef2
密码 :bigdata123!
**最后来一张Ambari Server UI的全景图**
[外链图片转存中...(img-aeHv8wMn-1677642246533)]