论文笔记--Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classific
论文笔记--Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
-
- 3.1 Prompt Tuning(KPT)
- 3.2 Knowledgeable Prompt Tuning(KPT)
- 3.3 Verbalizer Refinement
-
- 3.3.1 Frequency Refinement
- 3.3.2 Relevance Refinement
- 3.3.3 Contextualized Calibration
- 3.3.4 Learnable Refinement
- 4. 文章亮点
- 5. 原文传送门
Incorporating Knowledge into Prompt Verbalizer for Text Classification)
1. 文章简介
- 标题:Knowledgeable Prompt-tuning:
Incorporating Knowledge into Prompt Verbalizer for Text Classification - 作者:Shengding Hu, Ning Ding, Huadong Wang, Zhiyuan Liu, Jingang Wang, Juanzi Li, Wei Wu, Maosong Sun
- 日期:arxiv preprint
- 期刊:2021
2. 文章概括
文章提出了Knowledgeable Prompt Tuning(KPT)方法,将外部知识融入Verbalizer,并设计了4种处理方法可以从外部知识中筛选出合适的label words。
3 文章重点技术
3.1 Prompt Tuning(KPT)
首先定义 M \mathcal{M} M为语言模型。文章以文本分类任务出发,探讨了如何通过KPT提高prompt tuning的表现。给定输入 x = ( x 0 , … , x n ) x = (x_0, \dots, x_n) x=(x0,…,xn),我们要将它分类到标签集合 y ∈ Y y\in \mathcal{Y} y∈Y。Prompt Tuning(PT)的任务是通过一个template(一段自然文本)将原输入封装。比如任务是将文本"What’s the relation between speed and acceleration?“分类为"SCIENCE"或"SPORTS”,分别对应label 0和1,PT会将它包装为 x p = [ C L S ] A [ M A S K ] q u e s t i o n : x x_p = [CLS]\ A\ [MASK]\ question: x xp=[CLS] A [MASK] question:x,然后模型 M \mathcal{M} M会预测 [ M A S K ] [MASK] [MASK]被填充为词表单词 v v v的概率 P M ( [ M A S K ] = v ∣ x p ) P_{\mathcal{M}}([MASK]=v|x_p) PM([MASK]=v∣xp)。为了把该概率映射到标签集合 Y \mathcal{Y} Y,我们定义verbalizer为函数 f : V → Y f: \mathcal{V} \to \mathcal{Y} f:V→Y,其中 V \mathcal{V} V表示标签单词集合,我们用 V y \mathcal{V}_y Vy表示标签 y ∈ Y y\in\mathcal{Y} y∈Y对应的单词集合,则有 V = ∪ y ∈ Y V y \mathcal{V}=\cup_{y\in\mathcal{Y}} \mathcal{V}_y V=∪y∈YVy。则可以预测标签 y y y的概率为 P ( y ∣ x p ) = g ( P M ( [ M A S K ] = v ∣ x p ) ∣ v ∈ V y ) P(y|x_p) = g(P_{\mathcal{M}} ([MASK]=v|x_p)|v\in\mathcal{V}_y) P(y∣xp)=g(PM([MASK]=v∣xp)∣v∈Vy),其中 g g g表示标签单词到标签的概率转化函数。上例中,我们可以设计 V 1 = { "science" } \mathcal{V}_1 = \{\text{"science"}\} V1={"science"}, V 2 = { "sports" } \mathcal{V}_2 = \{\text{"sports"}\} V2={"sports"},从而预测标签为0的概率等于[MASK]位置填充为"science"的概率。
3.2 Knowledgeable Prompt Tuning(KPT)
文章提出KPT,将外部知识融入从而提高verbalizer。文章以主题分类和情感分类为例说明KPT的运作方式。
针对主题分类(topic classification),文章选择Related Words知识图谱作为我们的外部知识数据(KB)。图谱中每个节点表示一个单词,边表示单词之间是相关的,边的score表示单词之间的相关度。假设每个标签的名称 v 0 v_0 v0(比如上述标签0对应的名称为"science")可以代表该类别的正确label word,则考虑该名称在图谱中的所有相邻且scores大于给定阈值 η \eta η(文章取 η = 0 \eta=0 η=0的节点 N G ( v 0 ) N_{\mathcal{G}}(v_0) NG(v0)为该标签的label words集合。
针对情感分类,文章采用开源的情感辞典用于形成标签的label words集合。
3.3 Verbalizer Refinement
由于上述开源DB可能存在噪音,文章设计了4个refinement方法来对DB进行精炼。
3.3.1 Frequency Refinement
首先由于PLM对稀有词的预测往往不准确,为此,文章设计了contextualized prior来从label words中移除这些单词。具体来说,给定文本分类任务,记句子 x x x在语料库中的分布为 D \mathcal{D} D,考虑所有句子的整体期望,我们得到label words的先验分布为 P D ( v ) = E x ∈ D P M ( [ M A S K ] = v ∣ x p ) P_{\mathcal{D}}(v) = \mathbb{E}_{x\in\mathcal{D}} P_{\mathcal{M}} ([MASK]=v|x_p) PD(v)=Ex∈DPM([MASK]=v∣xp)。为例得到上式的经验估计,我们从训练集中采样一小部分无标注的支持集 C ~ \tilde{C} C~,假设抽样的样本是样本集的均匀分布,则上式的估计式为 P D ( v ) ≈ 1 ∣ C ~ ∣ ∑ x ∈ C ~ P M ( [ M A S K ] = v ∣ x p ) P_{\mathcal{D}}(v) \approx \frac 1{|\tilde{C}|} \sum_{x\in\tilde{C}} P_{\mathcal{M}} ([MASK]=v|x_p) PD(v)≈∣C~∣1x∈C~∑PM([MASK]=v∣xp)。
有了每个label word的先验分布估计式,我们移除所有先验概率小于给定阈值的label word,即移除稀有词。文章采用了基于排名的阈值,即将label words按照 P D ( v ) P_{\mathcal{D}}(v) PD(v)进行排序,移除概率较低的一半label words。
3.3.2 Relevance Refinement
为了度量每个label word和它们所属标签的相关性,文章对每个 C ~ \tilde{C} C~中的句子 x i x_i xi(其实就相当于上一节中的 x x x,只是为了增加索引这一节有多了个下标。读者注意这里不是表示 x x x的元素!),计算label word v v v的向量表示 q i v = P M ( [ M A S K ] = v ∣ x i p ) q_i^v = P_{\mathcal{M}} ([MASK]=v|x_{ip}) qiv=PM([MASK]=v∣xip),从而得到 v v v的向量表示 q v = ( q 0 v , … , q ∣ C ~ ∣ v ) T q^v = (q_0^v, \dots, q_{|\tilde{C}|}^v)^T qv=(q0v,…,q∣C~∣v)T,即 v v v在支持集 C ~ \tilde{C} C~上的预测概率。
记下来计算所有label words的表示,且用同样方式计算每个标签 y y y对应名称 v 0 v_0 v0的向量表示 q v 0 : = q y q^{v_0}:=q^y qv0:=qy用来估计该类别的分布,然后计算label word v v v和类别 y y y之间的余弦相似度 r ( v , y ) = c o s ( q v , q y ) = c o s ( q v , q v 0 ) r(v, y) = cos(q^v, q^y) = cos(q^v, q^{v_0}) r(v,y)=cos(qv,qy)=cos(qv,qv0)。由于有部分 v v v同时属于多个类别,比如phisiology属于SCIENCE和SPORTS,从而文章对上式进行了修正: R ( v ) = r ( v , y ) ∣ Y ∣ − 1 ∑ y ∈ Y , y ≠ f ( v ) r ( v , y ) R(v) = r(v, y) \frac {|\mathcal{Y}| - 1}{\sum_{y\in\mathcal{Y}, y\neq f(v)}r(v, y)} R(v)=r(v,y)∑y∈Y,y=f(v)r(v,y)∣Y∣−1,其中 f ( v ) f(v) f(v)表示 v v v所属的类别。这里笔者简单注释下:首先 r ( v , y ) ∈ [ 0 , 1 ] r(v,y) \in[0, 1] r(v,y)∈[0,1],这是因为每个 q q q表示的是概率,从而 q q q的每个元素只能是 ( 0 , 1 ) (0,1) (0,1)之间,故任意两个 q v , q y q^v, q^y qv,qy点积一定是正数;其次,由于 r ( v , y ) ∈ [ 0 , 1 ] r(v,y)\in[0,1] r(v,y)∈[0,1],我们有上式的分母小于等于 ∣ Y ∣ − 1 |\mathcal{Y}| - 1 ∣Y∣−1,故 R ( v ) ≥ r ( v , y ) R(v) \ge r(v, y) R(v)≥r(v,y),且当当前 v v v对每个类别 y ≠ f ( v ) y\neq f(v) y=f(v)都有 r ( v , y ) = 1 r(v, y) = 1 r(v,y)=1时达到最小值 r ( v , y ) r(v,y) r(v,y)。
一个好的label word应该可以代表它所属的类别 f ( v ) f(v) f(v),即对它不属于的类别 r ( v , y ) r(v, y) r(v,y)应该小一点,所以 R ( v ) R(v) R(v)越大说明 v v v越好。文章选择移除所有 R ( v ) < 1 R(v)<1 R(v)<1的 v v v,因为当 R ( v ) < 1 R(v) < 1 R(v)<1时,我们有 r ( v , y ) < 1 ∣ Y ∣ − 1 ∑ y ∈ Y , y ≠ f ( v ) r ( v , y ) r(v, y) < \frac 1{|\mathcal{Y}| - 1}{\sum_{y\in\mathcal{Y}, y\neq f(v)}} r(v,y) r(v,y)<∣Y∣−11∑y∈Y,y=f(v)r(v,y),即 v v v与其所属类别的相似度小于与其余类别相似度的均值。
3.3.3 Contextualized Calibration
研究表明,一些label words相比于其它label words更难被预测,从而造成预测结果是有偏大。文章采用Contextualized Calibration(CC)来对预测的分布进行校准: P ~ M ( [ M A S K ] = v ∣ x p ) ∝ P M ( [ M A S K ] = v ∣ x p ) P D ( v ) \tilde{P}_{\mathcal{M}} ([MASK]=v|x_p) \propto \frac {P_{\mathcal{M}} ([MASK]=v|x_p)}{P_{\mathcal{D}(v)}} P~M([MASK]=v∣xp)∝PD(v)PM([MASK]=v∣xp),其中 P D ( v ) P_{\mathcal{D}}(v) PD(v)为 v v v的先验概率,最后将上述 P ~ M \tilde{P}_M P~M标准化为1: ∑ v ∈ V P ~ M ( v ) = 1 \sum_{v\in\mathcal{V}} \tilde{P}_M(v) = 1 ∑v∈VP~M(v)=1。
3.3.4 Learnable Refinement
针对few-shot学习中,文章通过学习过程来对label words进行精炼。具体来说,文章为每个label word v v v分配一个可学习的参数权重 w v ∈ R ∣ V ∣ w_v\in \mathbb{R}^{|\mathcal{V}|} wv∈R∣V∣,初始化为零向量,然后对每个类别的权重进行标准化,得到标准化权重 α v = exp w v ∑ u ∈ V y exp w u \alpha_v = \frac {\exp w_v}{\sum_{u\in\mathcal{V}_y} \exp w_u} αv=∑u∈Vyexpwuexpwv。此过程旨在让模型自动为噪音单词学习到一个小的权重,从而降低噪音的影响。
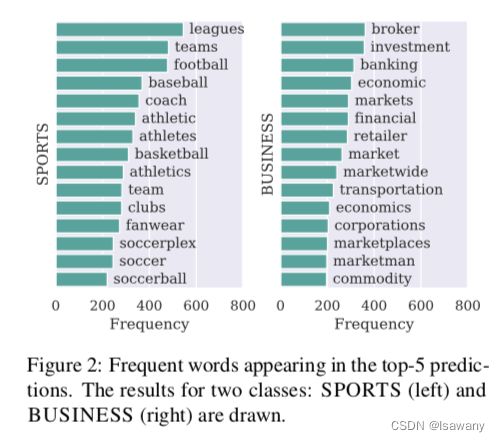
通过上述方法,我们可以检测出一些比较有代表性的label words,且不局限于同义词层面。下图为文章给出的top-15l abel words示例。
4. 文章亮点
文章提出了KPT方法,将外部知识有效地融入到verbalizer中,从而提高zero-shot/few-shot的表现能力。文章提出的4种精炼方法也是KPT成功的必要元素。实验证明,KPT在zero-shot文本分类任务中持平或超越了PT/PT+CC方法,在few-shot文本分类任务中超过了FT方法。且文章证明当KB中存在比较多的噪音时,文章提出的精炼方法可以有效地从中筛选出有益的label words以支撑文本分类任务,提高模型的鲁棒性。
5. 原文传送门
Knowledgeable Prompt-tuning:
Incorporating Knowledge into Prompt Verbalizer for Text Classification