tensorRT部署分类网络resnet与性能验证教程(C++)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、pytorch构建分类网络
-
- 基于torchvision构建resnet网络
- 获得wts文件
- 获得onnx文件
- 二、tensorrt部署resnet
-
- 基于wts格式采用C++ API 转tensorrt部署
- 基于onnx格式采用C++ API 转tensorrt部署
-
- onnx-simpiler简化onnx文件
- 部署测试展示
- 三、性能测试实验
- 四、py转engine被C调用验证
-
- py转engine代码
- 推理部署代码(C++)
- infer显示
- 实验结果
- 五、Linux环境下构建CMakeList文件
-
- 基于wts格式构建编译文件
- 基于onnx格式构建编译文件
- 六、测试结果
-
- 基于wts测试结果
- 基于onnx测试结果
- 总结
前言
本文通过分类网络验证基于onnx构建network和基于wts构建network方式,使用tensorrt推理存在的性能区别。为此,本文内容主要分为六个,第一个内容介绍使用python构建网络,获取pt/wts/onnx文件;第二个内容介绍基于C++ API构建engine;第三个内容介绍基于C++使用onnx构建engine;第四个内容介绍windows性能及linux性能;第五个内容介绍验证;第六个内容介绍如何在Linux环境下编译engine且运行。
代码链接-百度网盘(提取码:r63z)
一、pytorch构建分类网络
基于torchvision构建resnet网络
构建resnet分类网络,并保存pth权重,代码如下:
from torchvision.transforms import transforms
import torch
import torchvision.models as models
import struct
transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
transforms_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
def build_model():
model = models.resnet18(pretrained=True)
model = model.eval()
model = model.cuda()
torch.save(model, "./resnet18.pth")
if __name__ == '__main__':
build_model()
获得wts文件
获得wts权重格式文件,代码如下:
from torchvision.transforms import transforms
import torch
import torchvision.models as models
import struct
def get_wts(model_path='./resnet18.pth',save_wts_path="./resnet18.wts"):
net = torch.load(model_path)
net = net.cuda()
net = net.eval()
print('model: ', net)
# print('state dict: ', net.state_dict().keys())
tmp = torch.ones(1, 3, 224, 224).cuda()
print('input: ', tmp)
out = net(tmp)
print('output:', out)
f = open(save_wts_path, 'w')
f.write("{}\n".format(len(net.state_dict().keys())))
for k, v in net.state_dict().items():
print('key: ', k)
print('value: ', v.shape)
vr = v.reshape(-1).cpu().numpy()
f.write("{} {}".format(k, len(vr)))
for vv in vr:
f.write(" ")
f.write(struct.pack(">f", float(vv)).hex())
f.write("\n")
if __name__ == '__main__':
get_wts(model_path='./resnet18.pth',save_wts_path="./resnet18.wts")
获得onnx文件
获得onnx格式文件,代码如下:
from torchvision.transforms import transforms
import torch
import torchvision.models as models
import struct
def get_onnx(model_path='./resnet18.pth',save_onnx_path="./resnet18.onnx"):
# 定义静态onnx,若推理input_data格式不一致,将导致保存
input_data = torch.randn(2, 3, 224, 224).cuda()
model = torch.load(model_path).cuda()
input_names = ["data"] + ["called_%d" % i for i in range(2)]
output_names = ["prob"]
torch.onnx.export(
model,
input_data,
save_onnx_path,
verbose=True,
input_names=input_names,
output_names=output_names
)
if __name__ == '__main__':
get_onnx(model_path='./resnet18.pth', save_onnx_path="./resnet18.onnx")
以上代码可复制粘贴合并到一个py文件使用。
二、tensorrt部署resnet
基于wts格式采用C++ API 转tensorrt部署
以下使用wts方法,实现引擎engine构建与推理部署,代码如下:
#include "NvInfer.h"
#include "cuda_runtime_api.h"
//#include "logging.h"
#include
float cls_float = prob[0];
int cls_id = 0;
for (int i = 0; i < OUTPUT_SIZE; i++) {
if (cls_float < prob[i]) {
cls_float = prob[i];
cls_id = i;
}
}
std::cout << "i=" << i << "\tcls_id=" << cls_id << "\t cls_float=" << cls_float << std::endl;
}
std::cout << "C++2engine" << "mean read img time =" << time_read_img / 1000 << "ms\t" << "mean infer img time =" << time_infer / 1000 << "ms" << std::endl;
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
return 0;
}
int main(int argc, char** argv)
{
//string mode = argv[1];
string mode = "-d"; //适用windows编译,固定指定参数
//if (std::string(argv[1]) == "-s") {
if (mode == "-s") {
get_trtengine();
}
//else if (std::string(argv[1]) == "-d") {
else if (mode == "-d") {
infer();
}
else {
return -1;
}
return 0;
}
基于onnx格式采用C++ API 转tensorrt部署
本代码基于onnx格式,使用visual studio编译器,实现resnet分类网络部署,代码如下:
#include "NvInfer.h"
#include "cuda_runtime_api.h"
//#include "logging.h"
#include
float cls_float = prob[0];
int cls_id = 0;
for (int i = 0; i < OUTPUT_SIZE; i++) {
if (cls_float < prob[i]) {
cls_float = prob[i];
cls_id = i;
}
}
std::cout << "i=" << i << "\tcls_id=" << cls_id << "\t cls_float=" << cls_float << std::endl;
}
std::cout << "C++2engine" << "mean read img time =" << time_read_img / 1000 << "ms\t" << "mean infer img time =" << time_infer / 1000 << "ms" << std::endl;
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
return 0;
}
int main(int argc, char** argv)
{
//string mode = argv[1];
string mode = "-d"; //适用windows编译,固定指定参数
//if (std::string(argv[1]) == "-s") {
if (mode == "-s") {
get_trtengine();
}
//else if (std::string(argv[1]) == "-d") {
else if (mode == "-d") {
infer();
}
else {
return -1;
}
return 0;
}
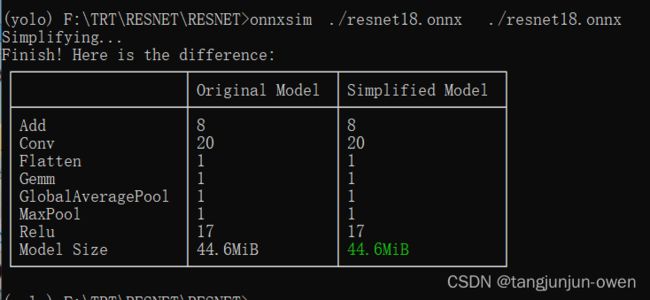
onnx-simpiler简化onnx文件
使用onnx-simpiler 进行优化onnx,但已是最简化,但若能简化,猜想预测会更快一些。
onnxsim ./resnet18.onnx ./resnet18.onnx
部署测试展示
总之测试2张图基本在一个大类中,应该没啥错误。
windows使用visual studio测试结果:

linux服务器测试结果:

三、性能测试实验
性能测试结果(测试平台:windows10 cuda11.4 tensorrt8.4 RTX 2060):

性能测试结果(测试平台:Linux ubuntu18.4 cuda11.3 tensorrt8.2 RTX 2060)(添加:20220914):

注:检测1000张的平均时间
说明 window10与ubuntu是2个独立设备(电脑),读图主要是CPU处理代码,后期可改成CUDA处理提速。
四、py转engine被C调用验证
使用python将onnx转为engine引擎,使用C++调用验证
py转engine代码
python代码将其转为engine库,注:使用同样的tensorrt版本
我将这部分代码丢失,读者可参考网络方法,进行转换。
推理部署代码(C++)
将转换的engine文件通过tensorrt部署推理,代码如下:
#include "NvInfer.h"
#include "cuda_runtime_api.h"
#include
float cls_float = prob[0];
int cls_id = 0;
for (int i = 0; i < OUTPUT_SIZE; i++) {
if (cls_float < prob[i]) {
cls_float = prob[i];
cls_id = i;
}
}
std::cout << "i=" << i << "\tcls_id=" << cls_id << "\t cls_float=" << cls_float << std::endl;
}
std::cout << "C++2engine" << "mean read img time =" << time_read_img / 1000 << "ms\t" << "mean infer img time =" << time_infer / 1000 << "ms" << std::endl;
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
return 0;
}
int main(int argc, char** argv)
{
infer();
return 0;
}
infer显示
以下为python转engine后,通过C++直接使用转换的engine推理效果如下:

实验结果
windows系统 可行! 很令人兴奋,意味着使用python转换为engine,将可以使用C++调用,无需再使用C++创建engine。

注:推理时间变长了快2倍。
五、Linux环境下构建CMakeList文件
本节介绍如何使用编译命令在ubuntu(linux)环境中运行,本节将介绍主要介绍CMakeLists.txt文件的构建:
基于wts格式构建编译文件
CMakeList.txt文件:
cmake_minimum_required(VERSION 2.6)
project(resnet)
add_definitions(-std=c++11)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
include_directories(${PROJECT_SOURCE_DIR}/include)
# include and link dirs of cuda and tensorrt, you need adapt them if yours are different
# cuda
include_directories(/usr/local/cuda/include)
link_directories(/usr/local/cuda/lib64)
# tensorrt
include_directories(/home/ubuntu/soft/TensorRT-8.2.5.1/include/)
link_directories(/home/ubuntu/soft/TensorRT-8.2.5.1/lib/)
#include_directories(/usr/include/x86_64-linux-gnu/)
#link_directories(/usr/lib/x86_64-linux-gnu/)
# opencv
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
add_executable(resnet18 ${PROJECT_SOURCE_DIR}/main.cpp)
target_link_libraries(resnet18 nvinfer)
target_link_libraries(resnet18 cudart)
target_link_libraries(resnet18 ${OpenCV_LIBS})
add_definitions(-O2 -pthread)
基于onnx格式构建编译文件
CMakeList.txt文件:
cmake_minimum_required(VERSION 2.6)
project(resnet)
add_definitions(-std=c++11)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
include_directories(${PROJECT_SOURCE_DIR}/include)
# include and link dirs of cuda and tensorrt, you need adapt them if yours are different
# cuda
include_directories(/usr/local/cuda/include)
link_directories(/usr/local/cuda/lib64)
# tensorrt
include_directories(/home/ubuntu/soft/TensorRT-8.2.5.1/include/)
link_directories(/home/ubuntu/soft/TensorRT-8.2.5.1/lib/)
include_directories(/home/ubuntu/soft/TensorRT-8.2.5.1/samples/common/)
#link_directories(/home/ubuntu/soft/TensorRT-8.2.5.1/lib/stubs/)
# opencv
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
add_executable(resnet18 ${PROJECT_SOURCE_DIR}/main.cpp)
target_link_libraries(resnet18 nvinfer)
target_link_libraries(resnet18 cudart)
target_link_libraries(resnet18 ${OpenCV_LIBS})
target_link_libraries(resnet18 /home/ubuntu/soft/TensorRT-8.2.5.1/lib/stubs/libnvonnxparser.so
)
add_definitions(-O2 -pthread)
以上为ONNX及C++构建engine的cmakelists的语句,主要在于库的链接或头文件之类,相关可看其它博客或网上资料。
附带说明:以上Onnx的CmakeLists.txt语句已经在yolov5、yolov7中验证,可以编译运行。
ResNet代码在上面已有说明,我将不放在本博客中,其中细节代码在我发布的链接中可下载使用。
六、测试结果
本节展示linux服务器上,分别基于wts与onnx方法构建分类网络resnet测试结果比较。
从以下图中,可知onnx转engine速度更快,但我个人觉得可能因为网络不够复杂等,导致与预期不一致现象。为此,此结论仅作为分类网络resnet测试参考。
基于wts测试结果

基于onnx测试结果

总结
本文实现基于wts与onnx部署方法与性能测试。