二叉树的三序遍历
今天不看算法了,刷刷题换换脑子。
参考教程: 代码随想录
文章目录
- 二叉树的遍历方式
- 二叉树的递归遍历
-
- 前序遍历
- 中序遍历
- 后序遍历
- 二叉树的迭代遍历
-
- 前序遍历
- 中序遍历
- 后序遍历
- 按遍历顺序构造二叉树
-
- 从中序与后序构造二叉树。
- 从前序与中序构造二叉树。
二叉树的遍历方式
二叉树的遍历方式,粗略来分,可以直接分为深度优先遍历和广度优先遍历。
- 深度优先遍历:从根节点出发一直往深处走,遇到叶子节点再回头探索下一个方向。
- 广度优先遍历: 从第一层开始,一层一层地遍历二叉树。
广度优先遍历二叉树又可以称为层次遍历,它是通过迭代来实现的。
深度优先遍历又可以按照遍历的顺序进行细分,分为三种类型:
- 前序遍历:先遍历根节点,再遍历左子树和右子树。
- 中序遍历:先遍历左子树,再遍历根节点,再遍历右子树。
- 后序遍历:先遍历左子树和右子树,再遍历根节点。

以上图为例子。三种顺序的遍历结果分别是:
- 前序遍历:1->2->4->5->3->6->7
- 中序遍历:4->2->5->1->6->3->7
- 后序遍历:4->5->2->6->7->3->1
先列出本章会涉及到的leetcode题目链接:
- 144. 二叉树前序遍历
- 94. 二叉树中序遍历
- 145. 二叉树后序遍历
- 105. 从前序和中序遍历构造二叉树
- 106. 从中序和后序遍历构造二叉树
在开始之前我们先进行一个二叉树的定义。
这是一个链式存储的二叉树的类定义,它包含一个节点值val,并且有left和right分别指向它的左子树和右子树。
class TreeNode(object):
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
我们在进行二叉树的遍历时,有两种写法,一种是递归的遍历方法,一种是迭代的遍历方法。
二叉树的递归遍历
递归算法是一种直接的或简洁的调用自身的算法。在它的方法的定义里,会出现对自身的调用。递归必须有一个终止条件,不然就会递归次数太多导致内存栈的溢出。
递归算法有三个要素:
- 确定递归函数的参数与返回值。
- 确定终止条件。
- 确定单层递归的逻辑。
接下来我们就用递归的方式来完成三种顺序的遍历。在三种遍历顺序中,其实我们的第一个要素和第二个要素应该是一致的,不一样的是单层递归的逻辑。我们先看一下前两个要素。
我们按照递归三要素的顺序来确定遍历的写法。
- 确定递归函数的参数与返回值。
如果是按顺序直接打印节点的数值,那么就不需要返回值。
你也可以选择将数值存放在一个全局的list变量中去,那么也不需要返回值。
假如你希望写出一个比较明确的返回值,那么我们的返回值应该是以输入的node为根节点的子树的遍历结果。我们可以写成如下形式。def dfs(node): xxxxxxxxxx return result - 确定终止条件。
在二叉树的遍历中,终止条件很好理解。当前节点为空时,即可以停止遍历,当前层的递归就结束。
假如你不需要返回值,那么你可以写成。
假如你使用的是带返回值的写法,那么当前层为空时,遍历结果也是一个空list,可以写成。if not node: returnif not node: return []
我们在这个的基础上完成三种遍历顺序的递归代码。
前序遍历
我们来确定一下前序遍历在单层递归中的逻辑顺序。
在前序遍历中,我们优先遍历根节点,然后再看左子树和右子树。所以在单层递归的逻辑中,要先取根节点的数值。
- 假设我们使用的是不带返回值,但是使用一个全局的list存储节点数值的方法,这个全局list名为res。那我们的单层递归顺序可以写成:
res.append(node.val) dfs(node.left) dfs(node.right) - 假设我们使用的是带返回值的方法,那么我们要在这里返回存储在
result中的遍历结果。cur = node.val left = dfs(node.left) right = dfs(node.right) result = [cur] + left + right
在leetcode解答中,两个完整的代码分别为:
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
res = []
def dfs(root):
if not root:
return
res.append(root.val)
dfs(root.left)
dfs(root.right)
dfs(root)
return res
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
def dfs(node):
if not node:
return []
cur = node.val
left = dfs(node.left)
right = dfs(node.right)
return [cur]+ left + right
return dfs(root)
中序遍历
我们来确定一下中序遍历在单层递归中的逻辑顺序。
在中序遍历中,我们优先遍历左子树,然后再看根节点,然后再看右子树。所以在单层递归的逻辑中,要先取左子树的数值。
- 假设我们使用的是不带返回值,但是使用一个全局的list存储节点数值的方法,这个全局list名为res。那我们的单层递归顺序可以写成:
dfs(node.left) res.append(node.val) dfs(node.right) - 假设我们使用的是带返回值的方法,那么我们要在这里返回存储在
result中的遍历结果。cur = node.val left = dfs(node.left) right = dfs(node.right) result = left + [cur] + right
可以看到带返回值的中序遍历和带返回值的前序遍历的区别主要体现在result的赋值上,它的left分支和right分支的递归顺序是不影响结果的。
后序遍历
我们来确定一下后序遍历在单层递归中的逻辑顺序。
在后序遍历中,我们优先遍历左子树,然后再遍历右子树,然后再看根节点。所以在单层递归的逻辑中,要最后取节点的值。
- 假设我们使用的是不带返回值,但是使用一个全局的list存储节点数值的方法,这个全局list名为res。那我们的单层递归顺序可以写成:
dfs(node.left) dfs(node.right) res.append(node.val) - 假设我们使用的是带返回值的方法,那么我们要在这里返回存储在
result中的遍历结果。cur = node.val left = dfs(node.left) right = dfs(node.right) result = left + right + [cur]
二叉树的迭代遍历
迭代就是不断地按照逻辑用旧的值递推新的值的过程,直到没有新的值产生,那么这个过程就可以终止。
我们以层序遍历为例子讲解一下迭代遍历的过程。
假如你的root是非空的。我们把它存到一个list里。
q = []
if root:
q.append(root)
然后我们开始遍历这个list里的元素,每次取出一个元素,然后用它生成新的元素,再放进list里。这个新元素,在二叉树这个环境里,就是取出的元素的left和right。
while q:
for i in range(len(q)): # 这样就是一层一层的取元素
cur = q.pop(0) # 取出第一个元素
if cur.left:
q.append(cur.left)
if cur.right:
q.append(cur.right)
q取完且没有新元素产生之后就变成了空,迭代的过程也就停止了。
在这个过程中,这个list实际上是当成队列来用的,因为它总是pop(0),也就是取出最先放进去的元素,遵循先进先出。
但是你要用迭代法完成非层序的遍历时,就不能使用队列了,而应该使用栈。
因为你不再是按照从左到右的层次顺序进行,具体来说,使用队列时,你先拿出第一个元素,然后把它的衍生结果放到最右边,你再拿出新的第一个元素,再把它的衍生结果放到最右边,在这个过程中,每一层从左到右的顺序是不变的。
假如你现在要做的是前序遍历。你按照左,右的顺序放入元素后,你发现你拿出的第一个元素,得到的衍生结果,还需要放回左边。而不是放到右边。所以不如直接使用栈,从右边拿,从右边放。要注意在这个时候,我们应该先放进去右边,再放左边。这样才能每次都优先拿出左边的元素。
但是这个做法很难应用到中序和后序遍历中。因为中序和后序中,都需要先遍历左子树,我们使用迭代的方法很难分辨出该在什么位置取元素的值,所以中序和后序遍历都需要对代码进行比较多的修改。此外,一个通用的优化方法是增加一个标志符,帮我们进行定位。
前序遍历
我们首先按上面的先放右边再放左边的栈的思路给出一个解法。
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
q = []
res = []
if root:
q.append(root)
while q:
cur = q.pop() # 每次取出最新的元素
res.append(cur.val)
if cur.right:
q.append(cur.right)
if cur.left:
q.append(cur.left)
return res
然后我们采用增加一个标识符的方法,帮我们进行定位。比如说在栈中存入中间节点后,在后面跟上一个'#',这样在迭代过程中如果我们遍历到这个节点,我们就知道下一个要取出的是中间节点。
首先还是熟悉的开局。
result = []
q = []
if root:
q.append(root)
迭代的过程会发生一些变化。我们要以中,左,右的顺序进行二叉树的遍历。所有要用右、左、中的顺序将二叉树存放到栈中。假如遇到了’#',说明我们的下一个值就是中间节点的值,就把它拿出来存到result中。
while q:
cur = q.pop() # 取出最新的值
if cur != '#': # 如果没有遇到#,说明下一个不是中间节点
if cur.right: # 还是先右再左再中,这样每次都先取出中间的的
q.append(cur.right)
if cur.left:
q.append(cur.left)
q.append(cur)
q.append('#')
else: # 遇到了#,说明下一个就是中间节点了。
cur = q.pop()
result.append(cur.val)
中序遍历
中序遍历的要求是先遍历左子树,再遍历根节点,再遍历右子树。因此我们可以先只看左子树,一直到左边为空,然后回退到上一个节点,看该节点的右子树。
这个过程写成代码是:
q = []
cur = root
result = []
while cur or q:
if cur: # 当前不为空的话就一直往左边走
q.append(cur) # 当前不为空就放进去。
cur = cur.left # 优先遍历左边。
else: # 当前为空,说明左边走到头了。
cur = q.pop() # 回退一下,拿上一个非空的节点
result.append(cur.val) # 存值
cur = cur.right # 然后看右边
如果是使用带标志的方法,我们仍然选择在中间节点上打上标记。因为现在是中序遍历,遍历顺序是左,中,右,所以往栈里存放的顺序应该变成右,中,左。
我们只写中间过程:
while q:
cur = q.pop() # 取出最新的值
if cur != '#': # 如果没有遇到#,说明下一个不是中间节点
if cur.right: # 还是先右再中再左,这样每次都先取出左边的
q.append(cur.right)
q.append(cur)
q.append('#')
if cur.left:
q.append(cur.left)
else: # 遇到了#,说明下一个就是中间节点了。
cur = q.pop()
result.append(cur.val)
后序遍历
后续遍历的顺序是左,右,中,因此我们可以先保存中,右,左的结果,然后将结果前后翻转,就变成了左,右,中。而中,右,左在用栈进行存放时,为了保证先拿出右再拿出左,要先放左再放右。
这个过程写成代码是:
def solution(root):
q = []
res = []
if root:
q.append(root)
while q:
cur = q.pop() # 每次取出最新的元素
res.append(cur.val)
if cur.left:
q.append(cur.left)
if cur.right:
q.append(cur.right)
return res[::-1]
如果是使用带标志的方法,我们仍然选择在中间节点上打上标记。因为现在是后序遍历,遍历顺序是左,右,中,所以往栈里存放的顺序应该变成中,右,左。
我们只写中间过程:
while q:
cur = q.pop() # 取出最新的值
if cur != '#': # 如果没有遇到#,说明下一个不是中间节点
q.append(cur)
q.append('#')
if cur.right: # 还是先右再中再左,这样每次都先取出左边的
q.append(cur.right)
if cur.left:
q.append(cur.left)
else: # 遇到了#,说明下一个就是中间节点了。
cur = q.pop()
result.append(cur.val)
按遍历顺序构造二叉树
已知前序遍历序列和中序遍历序列,可以唯一确定一棵二叉树。
已知后序遍历序列和中序遍历序列,可以唯一确定一棵二叉树。
已知前序遍历序列和后序遍历序列,不可以唯一确定一棵二叉树。
现在在给定二叉树遍历顺序的情况下,我们怎么将它恢复成一颗二叉树呢。
从中序与后序构造二叉树。
从代码随想录中偷一张图过来:
图片来源:代码随想录
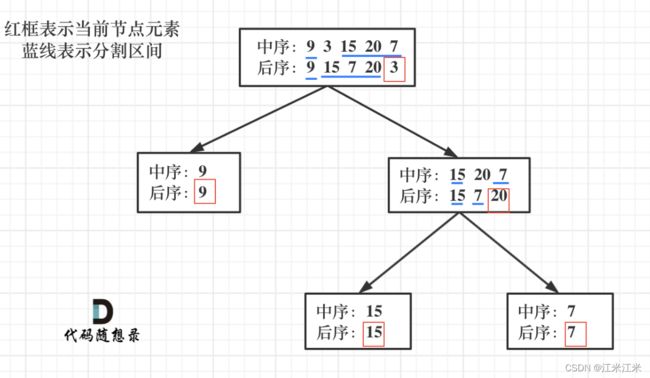
中序遍历的顺序是左中右。
后序遍历的顺序是左右中。
因此我们可以发现,通过后序遍历结果的最后一个值,可以帮助我们在中序遍历结果中进行左右子树的切分。通过层层切分和查找,我们就能一层一层的构建出我们的最终结果。
很明显这是要通过递归的方法来做的。我们先来定义一下我们的递归三要素:
-
确定递归函数的参数与返回值。
在这个题目中,我们递归函数的参数就是当前子树对应的中序遍历结果和后序遍历结果,返回值就是重构的子树。def dfs(inorder, postorder): xxxxxxxxxxxxxxxxxx return root -
确定终止条件。
当前传入的遍历结果为空时,说明已经走到了子树的最后一层,不需要再递归了。if not inorder: return -
确定单层递归的逻辑。
我们的逻辑就是,根据后序遍历结果的最后一个元素,从中序遍历中拆分出左右子树,加上当前的节点,构建出一个完整的子树。rootval = postorder[-1] root_index = inorder.index(rootval) # 切分左子树右子树 xxxxxxxxxxx # 递归 root = TreeNode(rootval) root.left = dfs(xxxxxx) root.right = dfs(xxxxxx)
写出完整的代码如下:
def dfs(inorder, postorder):
if not inorder:
return
rootval = postorder[-1]
rootindex = inorder.index(rootval)
left_in = inorder[:rootindex] # 注意这里不包括root
right_in = inorder[rootindex+1:] # 注意这里不包括root
left_post = postorder[:len(left_in)] # 注意这里的长度
right_post = postorder[len(left_in):-1] # 注意这里不包括root
root = TreeNode(rootval)
root.left = dfs(left_in, left_post)
root.right = dfs(right_in, right_post)
return root
从前序与中序构造二叉树。
中序遍历的顺序是左中右。
前序遍历的顺序是中左右。
因此我们可以发现,通过前序遍历结果的第一个值,可以帮助我们在中序遍历结果中进行左右子树的切分。通过层层切分和查找,我们就能一层一层的构建出我们的最终结果。
整体过程和上一题是一样的。所以在这里直接给出代码。
def dfs(preorder, inorder):
if not preorder:
return
rootval = preorder[0] # 取前序遍历的第一个值
rootindex = inorder.index(rootval) # 确定root的位置
left_in = inorder[:rootindex] # 取左子树
right_in = inorder[rootindex+1:] # 取右子树
left_pre = preorder[1:len(left_in)+1] # 取左子树
right_pre = preorder[len(left_in)+1:] # 取右子树
root = TreeNode(rootval)
root.left = dfs(left_pre, left_in)
root.right = dfs(right_pre, right_in)
return root