基于弱监督深度学习的医学图像分割方法综述
基于弱监督深度学习的医学图像分割方法综述
摘要:基于深度学习的医学影像分割尽管精度在不断的提升,但是离不开大规模的高质量标注数据的训练,被称为弱监督学习的深度学习的一个分支正在帮助医生通过减少对完整和准确的数据标签的需求,以更少的努力获得更多的洞察力。本文阐述了深度学习中三种不同类型的学习方式,并着重介绍了弱监督学习方式的三种类型,然后进一步总结了医学图像分割中的弱监督学习方法,最后详细列举了不同级别的弱监督在医学图像分割的应用实例。
关键词:深度学习;弱监督学习;医学图像分割
A Review of Medical Image Segmentation Methods Based on Weak Supervised Deep Learning
Abstract: Although the accuracy of medical image segmentation based on deep learning is constantly improving, it can not be separated from large-scale high-quality annotation data training. A branch of deep learning called weak supervised learning is helping doctors gain more insight with less effort by reducing the demand for complete and accurate data labels. This paper expounds three different types of learning methods in deep learning, and emphatically introduces three types of weak supervised learning methods, then further summarizes the weak supervised learning methods in medical image segmentation, and finally lists the application examples of different levels of weak supervision in medical image segmentation.
Key words: Deep Learning; Weak Supervised Learning; Medical Image Segmentation
1.引言
近年来,机器学习、深度学习在很多任务中大获成功,尤其是在有监督学习中,深度学习、机器学习取得了突破性的进展。例如在分类和回归的有监督任务中,预测模型从大量有标注的训练样本中学习,这些模型依赖强监督信息,因此学习前样本需要人工进行大量的数据标注。而在实际生产中,数据的标注成本很高,获取大量的有标注样本难度大,这一点在医疗行业中尤其具有挑战性。今天,被称为弱监督学习的深度学习的一个分支正在帮助医生通过减少对完整和准确的数据标签的需求,以更少的努力获得更多的洞察力。弱监督学习通过利用更容易获得的粗略标签(例如Image-Level Tag,图像级别标签)来工作,并允许使用预先训练的模型和常见的可解释性方法,能够有效的利用数据,提升模型的性能。
2.深度学习的学习方式
模型学习的本质是学习一种函数的映射关系。数据是模型学习的原料,通常训练一个模型需要大量的数据。现实生活中存在大量没有标注的数据,标注数据是人工添加的标签,因此标注数据通常需要花费大量的人力和物力。标注的数据分为有标签的数据和无标签的数据,输入数据有无标签对应着不同的学习方式。不同的学习方式可分为有监督学习、弱监督学习、无监督学习等。
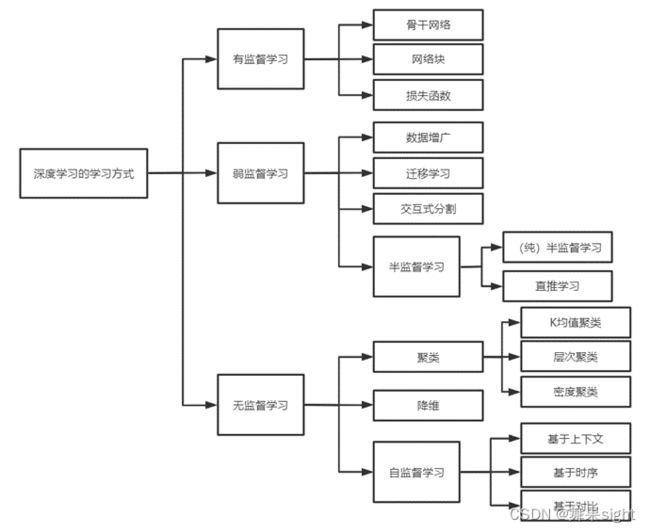
图2.1 深度学习的学习方式综述
2.1有监督学习
通过让机器学习大量带有标签的样本数据,训练出一个模型,并使该模型可以根据输入得到相应输出的过程。通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如分类和回归。可以说有监督学习,学习的是数据到标签的一种映射关系。
2.2无监督学习
无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,因此其训练数据不要求有标签,聚类和降维是比较典型的无监督算法。而自监督学习可以说是无监督学习的一个分支,自监督学习利用辅助任务(pretask)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
2.3弱监督学习
弱监督学习是相对于有监督学习而言的。同有监督学习不同,弱监督学习中的数据标签允许是不完全的,即训练集中只有一部分数据是有标签的,其余甚至绝大部分数据是没有标签的;或者说数据的监督学习是间接的,也就是机器学习的信号并不是直接指定给模型,而是通过一些引导信息间接传递给机器学习模型。总之,弱监督学习涵盖的范围很广泛,可以说只要标注信息是不完全、不确切或者不精确的标记学习都可以看作是弱监督学习。
3弱监督学习的三种类型
3.1不完全监督(Incomplete Supervision)
如果仅仅采用有标注的信息训练模型,往往不能得到一个泛化能力强,非常鲁棒的模型,不完全监督主要应对只有训练集的一个很小的子集含有标签,而大量的样本为无标注的样本。这是最常见的由于标注成本过高而导致无法获得完全的强监督信号的情况,例如,在为医学图像研究构建大型数据集时,放射科医生不会因为个人利益就轻易帮忙标记数据。而且由于医生对于数据科学的了解往往不够深入,有许多数据的标注结果(例如为分割任务框定的病灶轮廓)是无法使用的,从而产生了很多实际上缺少有效标记的训练样本。
在诸多针对不完全监督环境开发的机器学习范式中,主动学习和半监督学习是两种比较流行的学习范式。
3.1.1主动学习(Active Learning)
主动学习假设未标注数据的真值标签可以向人类专家查询,让专家为训练模型最有价值的数据点打上标签(更详细的介绍请参阅:Settles 等人于 2012 年发表的综述文章[1] )。简单起见,在我们只考虑用查询次数衡量标注成本的情况下,主动学习的目标是在提高查询效率,且查询次数尽可能小的情况下,使得训练出的模型性能最好。因此,主动学习需要选择出最有价值的未标注数据来询问人类专家。
而在衡量被查询样本的价值时,有两种广泛使用的选择标准:信息量和代表性。信息量衡量的是一个未标注数据能够在多大程度上降低统计模型的不确定性,而代表性则衡量一个样本在多大程度上能代表模型的输入分布。这两种方法都有其明显的缺点。基于信息量的衡量方法包括不确定性抽样和投票查询,其主要的缺点是在建立选择查询样本所需的初始模型时,严重依赖于对数据的标注,而当表述样本量较小时,学习性能通常不稳定。基于代表性的方法,主要缺点在于其性能严重依赖于未标注数据控制的聚类结果。
目前,研究者正尝试将这两种方法结合起来,互为补充。举例来说,我们可以选择处于当前模型决策边界附近的乳房 X 线照片,并要求放射科医生仅给这些照片进行标记。但是,我们也可以要求仅仅对这些数据点进行较弱的监督,在这种情况下,主动学习是对于弱监督学习的完美补充(更详细的例子可以参考Druck, settle, 和 McCallum 于2009 发表的论文[2] )。
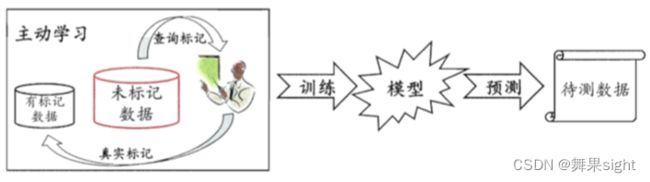
图3.1 主动学习的模型训练过程
3.1.2半监督学习(Semi-Supervised Learning)
与主动学习不同,半监督学习是一种在没有人类专家参与的情况下对未标注数据加以分析、利用的学习范式,它无需人工的参与,自动开发无标注的数据,来提升模型的性能。通常,尽管未标注的样本没有明确的标签信息,但是其数据的分布特征与已标注样本的分布往往是相关的,这样的统计特性对于预测模型是十分有用的。
存在一种特殊的半监督学习,称为直推式学习(Transductive Learning)。直推式学习和(纯)半监督学习的主要区别在于,它们对测试数据,即训练过的模型需要进行预测的数据,假设有所不同。直推式学习持有“封闭世界”假设,即,测试数据是事先给出的、目标是优化测试数据的性能;换言之,未标注数据正是测试数据。纯半监督式学习则持有“开放世界”假设,即,测试数据是未知的,未标注数据不一定是测试数据。

图3.2 直推学习和(纯)半监督学习模型训练过程的对比
半监督学习对于数据的分布有两种假设:聚类假设和流形假设。前者假设数据具有内在的聚类结构,因此,落入同一个聚类的样本类别相同。后者假设数据分布在一个流形上,在流形上相近的样本具有相似的预测结果。可见,两个假设的本质都是相似的数据输入应该有相似的输出。因此,如何更好地衡量样本点之间的相似性,如何利用这种相似性帮助模型进行预测,是半监督学习的关键。
一般来讲,半监督学习的方法主要包括:生成式方法、基于图的方法、低密度分割法、基于分歧的方法。
3.2不确切监督(Inexact Supervision)
针对一幅图片,只拥有对整张图片的类别标注,而对于图片中的各个实体则没有标注的监督信息,这就是不确切监督。不确切监督关注的问题是给定了监督信息,但是监督信息不够准确的情况,即训练样本只有粗粒度的标签。
例如:当我们对一张肺部 X 光图片进行分类时,我们只知道某张图片是肺炎患者的肺部图片,但是并不知道具体图片中哪个部位的响应说明了该图片的主人患有肺炎。
该问题可以被形式化表示为:该任务是从训练数据集中学习,其中每张肺部X光图片被称为一个包。每张肺部X光图片的各个部位的响应,是一个示例。如果存在肺部X光图片的某一个部位响应是正样本时,那么对应的包就是一个正包,同时这个包应该是未知的。模型的目标就是预测未知包的标签。该方法被称为多示例学习。
已经有许多有效的算法被开发出来并应用于多示例学习。实际上,几乎所有的有监督学习算法都有对等的多示例算法。大多数算法试图调整单示例监督学习算法,使其适配多示例表示,主要是将其关注点从对示例的识别转移到对包的识别;一些其他算法试图通过表示变换,调整多示例表示使其适配单示例算法。
早期的理论结果表明多示例学习对于包中每个示例都由不同的规则分类的异质性(heterogeneous)案例来说,是很难的;对于以相同的规则分类所有示例的同质性(homogeneous)案例就是可学习的,幸运的是,几乎所有的实际多示例任务都属于同质性案例。这些分析假定包中的示例是独立的,但不假定示例的独立性的分析更具挑战性,这类研究也出现得较晚,其揭示了在同质性类中,至少存在某些可以用包间的任意分布来学习的案例。
多示例学习已成功应用于各种任务,如图像分类/检索/注释,文本分类,垃圾邮件检测,医学诊断,面部/对象检测,对象类别发现,对象跟踪等。尽管如此,与其在算法和应用上的繁荣发展相反,多示例学习的理论研究成果非常少,因为分析的难度太大。
3.3 不精确监督(Inaccurate Supervision)
不精确监督关注的问题是对于给定的监督信息,有一些是错误的,也就是监督信息不总是真实值的情况。一个相对典型的场景就是在有标签噪声的情况下进行学习,出现这种情况的原因有很多,例如:标注人员自身水平有限、标注过程粗心、标注难度较大。目前很多理论研究相关问题,其中大多数均假设存在随机的分类噪声,即标签受随机噪声的影响,基本的思想就是识别潜在的误分类样本,然后尝试对其进行修正。
目前比较流行的众包模式(crowdsourcing)是不准确监督学习的一个重要的应用场景,对于机器学习来说,用众包模式为训练数据收集标签是一种经济的方式。具体来说,未标记的数据被外包给大量的工人来标记,使用众包返回的不准确监督信息来保证学习性能是非常困难的。很多研究尝试用众包标签推断真值标签,多数人投票策略得到了集成方法的理论支持,在实践中得到了广泛使用并有很好的表现,因此通常作为基线标准。如果预期可以对工人质量和任务难度建模,那么通过为不同的工人在不同的任务上设置权重,则可以获得更好的效果。为此,一些方法尝试构建概率模型然后使用 EM 算法进行评估[3] [4] ,人们也使用了极小极大熵方法。概率模型可以用于移除垃圾制造者。近期人们给出了移除低质量工人的一般理论条件。
目前已有很多关于用众包标签学习的研究,这和用带噪声标签学习是很接近的。但其中的区别在于,对于众包设定而言,人们可以方便地、重复地对某个示例提取众包标签。因此,在众包数据学习中,考虑经济性和最小化众包标签的充分数量是很重要的,即有效众包学习的最小代价。
4医学图像分割中的弱监督学习方法
对于医学图像分割中的弱监督学习方法,我们分别从数据增广,迁移学习和交互式分割三个角度来进行分析。

图4.1 医学图像分割中的弱监督学习方法综述
4.1 数据增广
数据增广的本质实际上是在现有的有限数据的基础上,在不实际收集更多数据的前提下,而让数据产生等价于更大数据量的价值,即根据现有数据样本按照规则生成增量数据的过程。
传统的医学图像数据增广方法,通常使用图像处理技术来完成医学图像数据集的扩充,包括改善图像质量(如噪声抑制)、改变图像强度(如亮度、饱和度和对比度)、改变图像布局(如旋转、失真和缩放)、参数变换(旋转、平移、剪切、移位、翻转)等。但它们都有一个特点,与原始图像太相似了。通过基于生成对抗网络的生成建模方式进行数据增广,克服了对原始数据的依赖,是现阶段医学图像分割中较为常用的手段。
现有的工作表明,DCGAN可用于合成逼真的前列腺病变斑块(Kitchen和Seah,2017年)[5] ,视网膜图像(Schlegl,2019)[6] 或肺癌结节(Chuquicusma,2018)[7] 。合成的肺癌结节和真实的相比,甚至对放射科医生而言,都难以区分。
Frid-Adar(2018)[8] 也使用DCGAN合成肝脏CT不同类别的病变斑块:对于每个类别,即囊肿,转移灶和血管瘤,训练独立的生成模型。出于训练数据集太小,他们使用大量增强的数据来训练GAN。作者证明了除了数据增强外,GAN的合成样本还能改善CNN分类器。
Bermudez(2018)[9] 也显示DCGAN也能够生成相当高分辨率的MRI数据,甚至只需要少量样品即可。在训练了1500个epoch之后,作者的实验获得了很棒的生成效果(人眼无法判断真假图像)。
Baur(2018)[10] 比较了DCGAN,LAPGAN对皮肤病变图像合成的影响。由于训练数据方差很大,因此样本数量很少不足以训练出可靠的DCGAN。但是,级联式的LAPGAN和它的变体变现很好,合成样品有也成功地用于训练皮肤病变分类器。Baur采用渐进式PGAN(Karras 2017)[11] 合成皮肤病变的高分辨率图像,效果极佳,连专业的皮肤科医生都无法地分辨是不是合成的。
Nie(2018)[12] 利用级联的3D全卷积网络从相应的MRI图像合成CT图像。为提高合成CT图像的真实性,除对抗性训练外,他们还通过逐像素重建损失和图像梯度损失训练模型。Nie要求使用CT和MRI图像一一对应的数据集进行训练。
Zhao(2018)[13] 的Deep-supGAN将头部的3D MRI数据映射到其CT图像,以促进颅颌面骨结构的分割。为获得更好的转换结果,他们提出了“deep-supervision discriminator(深度监督鉴别器)”,类似于“perceptual loss”,利用预训练的VGG16模型提取的特征表示来区分真实和合成的CT图像和提供梯度更新给生成器。
Guibas (2017)[14] 提出了一种两阶段方法,包括经过训练可从噪声中合成vessel tree图像的GAN和Pix2Pix网络,以生成现实的高分辨率血管分割图像和相应的eye fundus图。作者发现使用实际图像训练的U-Net进行分割,和仅用合成样本相比,后者稍差而已。
生成Blood Vessels血管图像对于检测冠状动脉CT血管造影术(CCTA)中的动脉粥样硬化斑块或狭窄,机器学习驱动的方法通常需要大量数据。为解决缺少标记数据的问题,Wolterink(2018)[15] 基于WGAN生成合理的3D血管形状图像。Olut(2018)[16] 提出steerable GAN合成MRIA(磁共振血管成像)图像。
4.2迁移学习(Transfer Learning)
迁移学习的目标是将已经在不同数据集上训练过的一个或多个模型应用到目标数据集和任务中 (Pan and Yang 2010)[17] 。例如,我们可能有一个大型肿瘤数据集,它是与身体某一器官相关的,并且我们在这组数据集上已经训练好了分类器,并希望将其迁移应用到我们的乳房摄影任务。
具体而言,迁移学习的定义为:有源域Ds 和任务Ts ;目标域Dt 和任务Tt ,迁移学习的目标是利用源域中的知识解决目标域中的预测函数 f ,条件是源域和目标域不相同或者源域中的任务和目标域中的任务不相同。
目前迁移学习有两种主流的方法,一种方法是针对目标医学图像分析任务微调ImageNet上的预训练模型,另一种方法是领域适应。
4.2.1预训练模型(Pre-trained Model)
当今深度学习社区中的常见迁移学习方法是把神经网络的训练分为两个阶段:(1)预训练。通常在代表大量多种标签/类别的大规模基准数据集(例如ImageNet)上训练神经网络。(2)微调。对预训练的网络在感兴趣的特定目标任务上进一步训练,可能需要比预训练数据集更少的标签样本。预训练步骤可帮助网络学习可在目标任务上重用的通用特征(General Features)。
Kalinin等人(2020)[18] 使用在ImageNet上预先训练的VGG-11、VGG-16和ResNet-34网络作为U形网络(U-shaped Network)的编码器,对血管增生性病变和外科手术的无线胶囊内镜视频中的机械仪器进行语义分割。同样,Conze等人(2020)[19] 使用在ImageNet上预先训练的VGG-11作为分割网络的编码器,进行肩胛肌MRI分割。
在迁移学习的背景下,针对ImageNet设计的具有相应预训练权重的标准体系结构在医疗任务上进行微调,从解释胸部X射线到识别眼部疾病到早期阿尔茨海默氏病发现,尽管已广泛使用,但是目前科学界对迁移学习的确切效果还没有很好的了解。
4.2.2领域适应(Domain Adaptation)
如果训练目标域的标签不可用,只能访问其他域的标签,那么常见的方法是将源域(Source Domain)上训练好的分类器转移到没有标注数据的目标域。
图16展示了CycleGAN的循环结构,主要由两个生成器和两个判别器组成。首先,一个在X域的图像通过生成器G转移到Y域,然后生成器G的输出通过生成器F在X域中重构回原始图像。相反,一个在Y域的图像通过生成器F转移到X域,然后生成器F的输出通过生成器G在Y域中重构回原始图像。判别器G和F都起着判别作用,保证了图像样式的传递。
Huo等人(2018)[20] 利用CycleGAN对CT图像中的脾脏分割任务提出了一种联合优化的图像合成和分割框架。该框架实现了从标注的源域到合成图像目标域的图像转换。在训练过程中,使用合成的目标图像来训练分割网络。在测试过程中,直接将目标域的真实图像(不带标签)输入到训练好的分割网络中,以获得理想的分割结果。
Chen等人(2019)[21] 也采用了类似的方法,利用MRI图像的分割标签来完成心脏CT的分割任务。Chartsias等人(2017)[22] 利用CycleGAN从CT切片和心肌分割标签中生成相应的MRI图像和标签,然后利用合成MRI图像和真实MRI图像训练心肌分割模型,比在真实MRI图像上训练的心肌分割模型效果提高了16%。同样,也有一些研究通过CycleGAN实现了不同域之间的图像转换,提高了医学图像分割的性能(Zhao et al. 2018,Valindria et al. 2018)[13] [23] 。
4.3 交互式分割
人工绘制医学图像分割标签通常繁琐而耗时,尤其是对于三维数据。交互分割则允许临床医生对模型生成的初始分割图像进行交互式校正,以获得更准确的分割结果。有效交互式分割的关键在于临床医生可以使用诸如鼠标点击和轮廓框(Outline Boxes)等交互方法来改进模型的初始分割结果,随后更新模型参数以生成新的分割图像,再获取临床医生最新的反馈。
传统的交互式分割主要代表有:GraphCuts,RandomWalks和ITK-Snap。
Wang等人(2018) 提出了利用两个CNN级联的DeepIGeoS[24],对二维和三维医学图像进行交互分割。第一个CNN叫做P-Net,用于输出一个粗分割结果。在此基础上,用户提供交互点或短线标注出错误的分割区域,然后将其作为第二个CNN(R-Net)的输入,获取修正后的结果。对二维胎儿MRI图像和三维脑瘤图像分析的研究结果表明,与GraphCuts、RandomWalks、ITK-Snap等传统的交互分割方法相比,DeepIGeoS大大降低了用户交互需求,并减少了所需时间。
DeepIGeoS 虽结合了 CNN 与用户交互操作,但无法泛化到未见类别的物体上,无法举一反三,为提升 CNN 对未见类别物体的泛化性能,Wang等人提出了类似于GrabCut原理的BIFSeg[25] 。GrabCut的原理是先让用户绘制一个边界框(Bounding Box),将边界框内的区域作为CNN的输入,得到一个初始结果,再通过微调获取更好的分割结果。GrabCut通过从图像中拟合高斯混合模型(Gaussian Mixture Model,GMM)来实现图像分割,而BIFSeg则从图像中拟合CNN。通常基于CNN的分割方法只能处理已经出现在训练集中的对象,从而限制了这些方法的灵活性,但BIFSeg尝试使用CNN来分割训练过程中未出现的对象。这个过程相当于让BIFSeg学会从一个边界框中提取对象的前景部分。在测试过程中,CNN可以通过自适应微调(Adaptive Fine-Tuning)更好地利用特定图像中的信息。
Rupprecht等人(2018)提出了一种新的交互式分割方法GM interactive[26] 。该方法根据用户输入的文本更新图像分割结果,通过交互式地修改编码器和解码器之间的特征映射来改变网络的输出。首先根据用户响应来设置区域类别,随后通过反向传播更新一些指导参数(包括乘法和偏移系数),最后改变特征映射,得到更新的分割结果。
5不同级别的弱监督在医学图像分割的应用实例
根据图像分割的具体任务,可以将其分为语义分割(Semantic Segmentation)、实例分割(Instance Segmentation)与全景分割(Panoptic Segmentation)三个方向,医学图像上,很少有实例分割,一般默认就是语义分割。
具有粗监督的分割在文献中通常也称为弱监督分割。根据粗略标注的类型,粗监督可以是Image-Level(每张训练图像只提供类别标签)、Box-Level(除了类别标签外,还包括Object Bounding Box) 为每个训练图像注释)或Scribble-Level(涂鸦,即每个训练图像中的像素子集被注释)。
5.1图像级别
Xu等人(2020)[27] 提出了CAMEL,一种仅使用图像级标签(Image-Level Label)的弱监督学习框架,用于组织病理学图像分割。其使用基于多实例学习(MIL)的标签富集(Label Enrichment),CAMEL将图像分割成网格实例,并自动生成实例级标签(Instance-Level Label)。在标签富集(Label Enrichment)之后,实例级标签被进一步分配给相应的像素,产生近似的像素级标签,并使得分割模型的完全监督训练成为可能。

图5.1 CAMEL的系统架构
5.2目标框级别
Rajchl 等人(2017)[28] 提出了一种给定弱标注的实例分割方法。其将微软研究院提出的GrabCut进行扩展,可以实现给定Bounding Boxes的神经网络分类器训练。该论文将分类问题视为在稠密连接的条件随机场下的能量最小化问题,并通过不断迭代实现实例分割。
论文中还提出了一些DeepCut方法的变体,并将它们与其它算法在弱监督条件下进行了比较。值得注意的是,该算法在解决大脑和肺的两个问题上已经得到了实验,精度还不错(使用的数据库是Fetal Magnetric Resonance Dataset)。下图是基本的DeepCut网络结构。

图5.2 DeepCut的网络结构
下图是DeepCut在胎儿磁共振数据集中解决脑和肺分割问题的实验结果,
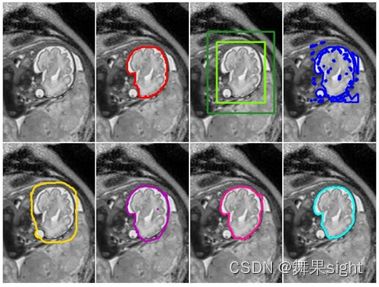
图5.3 DeepCut在胎儿磁共振数据集中的脑和肺分割结果
5.3涂鸦级别
收集稀疏注释(点、涂鸦、边界框)比密集注释更容易,而弱监督学习使用涂鸦来训练模型要比边界框和点对复杂对象具有更好的泛化性。涂鸦即仅提供一小部分像素的标注,也可以当做是一种种子区域。解决涂鸦监督的关键是如何将语义信息从稀疏的涂鸦传播到所有其他未标记的像素上,当前的方法通过利用图像的内部先验来实现这一点,即跨像素相似度。
Luo等人(2022)[29] 提出了一种简单而有效的涂鸦监督图像分割方法,并将其应用于心脏MRI分割。具体来说,作者采用了一个双分支网络,带有一个编码器和两个略有不同的解码器进行图像分割,并动态混合两个解码器的预测,以生成用于辅助监控的伪标签。通过将涂鸦监控和辅助伪标签监控相结合,双分支网络可以有效地从涂鸦注释中进行端到端的学习。在公共ACDC数据集上的实验表明,该方法比现有的Scribble监督分割方法具有更好的性能,也优于几种半监督分割方法。

图5.4 基于双分支网络和动态混合伪标签监督的涂鸦监督医学图像分割
6总结
本文阐述了深度学习中三种不同类型的学习方式,并着重介绍了弱监督学习方式的三种类型,然后进一步总结了医学图像分割中的弱监督学习方法,最后详细列举了不同级别的弱监督在医学图像分割的应用实例。直到最近,基于深度学习的医学影像分割尽管精度在不断的提升,但是离不开大规模的高质量标注数据的训练,弱监督学习等技术减少了对完整、准确和准确的数据标签的需求,并解锁了因在时间和专业知识方面成本太高而无法获得的洞察力,所以在稀疏标注下的弱监督学习和小数据集下的数据增广仍然是医学图像领域未来研究的重要课题。
参考文献
- Active Learning[J]. Synthesis Lectures on Artificial Intelligence & Machine Learning, 2012.
- Druck G , Settles B , Mccallum A . Active Learning by Labeling Features[C], EMNLP 2009, 6-7 August 2009, Singapore, A meeting of SIGDAT, a Special Interest Group of the ACL. 2009.
- Raykar V C , Yu S , Zhao L H , et al. Learning From Crowds[J]. Journal of Machine Learning Research, 2010, 11(2):1297-1322.
- Whitehill J , Ruvolo P , Wu T , et al. Whose Vote Should Count More: Optimal Integration of Labels from Labelers of Unknown Expertise[C], Proceedings of a meeting held 7-10 December 2009, Vancouver, British Columbia, Canada. Curran Associates Inc. 2009.
- Kitchen A , Seah J . Deep Generative Adversarial Neural Networks for Realistic Prostate Lesion MRI Synthesis[J]. 2017.
- Schlegl T , Seebck P , Waldstein S M , et al. f-AnoGAN: Fast Unsupervised Anomaly Detection with Generative Adversarial Networks[J]. Medical Image Analysis, 2019, 54.
- Chuquicusma M , Hussein S , Burt J , et al. How to fool radiologists with generative adversarial networks? A visual turing test for lung cancer diagnosis[C]// 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018). IEEE, 2018.
- Frid-Adar M , Klang E , Amitai M , et al. Synthetic data augmentation using GAN for improved liver lesion classification[C]// 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018). IEEE, 2018.
- Plassard A J , Davis L T , Newton A T , et al. Learning Implicit Brain MRI Manifolds with Deep Learning[J]. 2018.
- Baur C , Albarqouni S , Navab N . Generating Highly Realistic Images of Skin Lesions with GANs:, 10.48550/arXiv.1809.01410[P]. 2018.
- Karras T , Aila T , Laine S , et al. Progressive Growing of GANs for Improved Quality, Stability, and Variation[J]. 2017.
- Dong, Nie, Roger, et al. Medical Image Synthesis with Deep Convolutional Adversarial Networks[J]. IEEE Transactions on Biomedical Engineering, 2018, 65(12):2720-2730.
- Zhao M , Wang L , Chen J , et al. Craniomaxillofacial Bony Structures Segmentation from MRI with Deep-Supervision Adversarial Learning[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2018.
- Virdi T S , Guibas J T , Li P S . Synthetic Medical Images from Dual Generative Adversarial Networks[J]. 2017.
- Wolterink J M , Leiner T , Isgum I . Blood Vessel Geometry Synthesis using Generative Adversarial Networks[J]. 2018.
- Olut S , Sahin Y H , Demir U , et al. Generative Adversarial Training for MRIA Image Synthesis Using Multi-Contrast MRI[J]. 2018.
- AS Bais. IMPROVE A LEARNER: A SURVEY OF TRANSFER LEARNING. 2018.
- Lei T , Wang R , Wan Y , et al. Medical Image Segmentation Using Deep Learning: A Survey[J]. 2020.
- Conze P H , Kavur A E , Gall C L , et al. Abdominal multi-organ segmentation with cascaded convolutional and adversarial deep networks[J]. 2020.
- Huo Y , Xu Z , Bao S , et al. Adversarial synthesis learning enables segmentation without target modality ground truth[C]// 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018). IEEE, 2018.
- Chen C , Dou Q , Chen H , et al. Synergistic Image and Feature Adaptation: Towards Cross-Modality Domain Adaptation for Medical Image Segmentation[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33:865-872.
- Chartsias A , Joyce T , Dharmakumar R , et al. Adversarial Image Synthesis for Unpaired Multi-modal Cardiac Data[C]// International conference on medical imaging computing and computer-assisted intervention;International workshop on simulation and synthesis in medical imaging. Springer, Cham, 2017.
- Valindria V V , Pawlowski N , Rajchl M , et al. Multi-modal Learning from Unpaired Images: Application to Multi-organ Segmentation in CT and MRI[C]// 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2018.
- Guotai W , Zuluaga M A , Wenqi L , et al. DeepIGeoS: A Deep Interactive Geodesic Framework for Medical Image Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(7):1559-1572.
- Wang G , Li W , Zuluaga M A , et al. Interactive Medical Image Segmentation Using Deep Learning With Image-Specific Fine Tuning[J]. Institute of Electrical and Electronics Engineers, 2018(7).
- Rupprecht C , Laina I , Navab N , et al. Guide Me: Interacting with Deep Networks[J]. IEEE, 2018.
- Xu G , Song Z , Sun Z , et al. CAMEL: A Weakly Supervised Learning Framework for Histopathology Image Segmentation[C]// 2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2020.
- Rajchl M , Lee M , Oktay O , et al. DeepCut: Object Segmentation From Bounding Box Annotations Using Convolutional Neural Networks[J]. Institute of Electrical and Electronics Engineers (IEEE), 2017(2).
- Luo X , Hu M , Liao W , et al. Scribble-Supervised Medical Image Segmentation via Dual-Branch Network and Dynamically Mixed Pseudo Labels Supervision[J]. arXiv e-prints, 2022.