一个AI玩遍多个游戏
文章目录
- 1.Decision Transformers模型结构
- 2.不同模型规模下的表现
- 3.模型预训练与关注点
前面我曾经介绍过很多在游戏圈比较出名的AI智能体。这些AI智能体往往能在MOBA类游戏和即时战略游戏中超越专业选手,例如腾讯在王者荣耀训练出来的“绝悟AI”:

DeepMind在星际争霸中训练出来的“AlphaStar”:

还有我曾经写过的一篇《我的世界》的AI智能体:
https://blog.csdn.net/qq_30232405/article/details/125570578?spm=1001.2014.3001.5501
这其中,OpenAI利用玩家视频来学习,训练出超大的预训练模型VPT,这个AI智能体能够在开放自由世界中进行探索:
但是上面所介绍的AI智能体,往往仅能使用在在某个单独的游戏。因此为了让一个AI智能体能够学会游玩多个游戏,谷歌提出了一个新的**决策Transformer模型。**该模型在46个雅达利游戏上,达到了人类的水平。

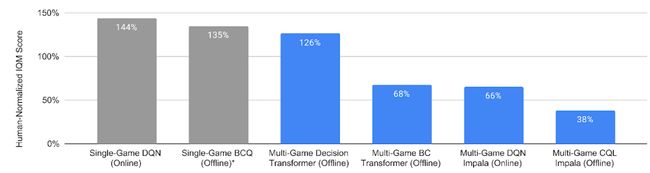
可以看到,在46个雅达利游戏上利用专家和非专家数据集进行训练,决策Transformers模型能够达到126%的人类分数,已经能够媲美单独训练一个DQN模型:
1.Decision Transformers模型结构
与视觉和自然语言领域相比,强化学习提倡使用小模型,而且一般来说只用于解决单个任务,或在同一环境中解决多个任务。但不同的是,在多个游戏环境的训练中,具有不同的动态、奖励、视觉效果和智能体,因此对这种AI智能体的研究目前较少。
在以往的强化学习方法中,包括**在线RL(online RL), 离线时分差分方法(offline temporal difference methods), 对比学习(contrastive representations )和行为克隆(behavior cloning)**等方法,不能够很好的应用在多个游戏环境中,且训练时间较为漫长。
因此该AI智能体的出发点在于:模型能不能在不同游戏环境下学习?
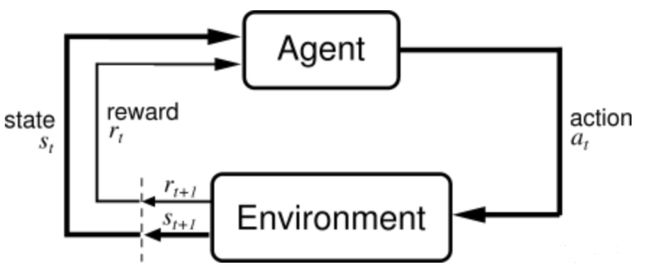
我们知道,在强化学习中要定义几个关键要素,包括当前状态State,奖励Reward,动作Action。训练过程简单来说就是:在当前状态State下,执行动作Action,当前环境进行反馈后,会给智能体相应的奖励,训练的目标就是要把累积收益最大化。
这个模型的贡献在于:
- 证明了可以训练出一个高通用性的AI智能体,它能够从离线数据中进行学习,并适应多个不同的游戏环境
- 证明了模型的大小对AI智能体的提升是有作用的
整体的决策Transformer模型如下:
- 在输入中把图片拆分成多个块进行输入
- 根据当前观察到的环境、回报、行动,来预测下一个回报、行动、奖励离散标记序列。

同时在输入的时候,把剩下的回报奖励作为输入 R t R^t Rt,这样可以当作序列模型进行预测。
2.不同模型规模下的表现
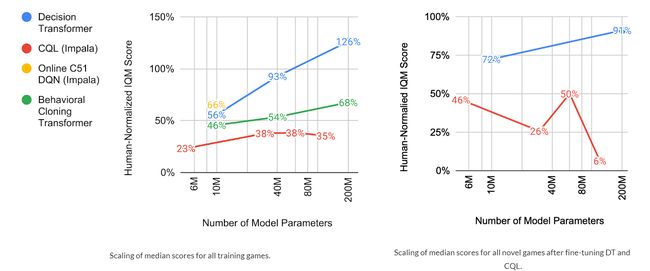
在通常的NLP和视觉任务下,模型越大,通常得到的效果越好。因此谷歌研究者研究了是否在互动游戏中,模型也有类似的表现。从下图中可以知道,决策Transformer参数越大,达到的效果越好:
3.模型预训练与关注点
目前的强化学习模型,训练完成后一般只能应用在训练的游戏环境中,因此把当前模型迁移到新游戏中的研究尚没有得到广泛的探索。决策Transformer中,采用了预训练方法,发现在5个新游戏中能够快速适应,效果比从头开始训练要好得多。
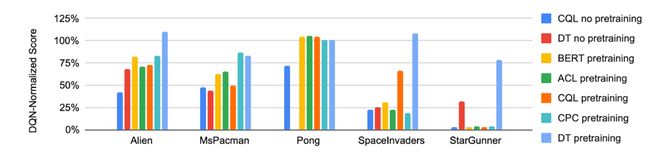
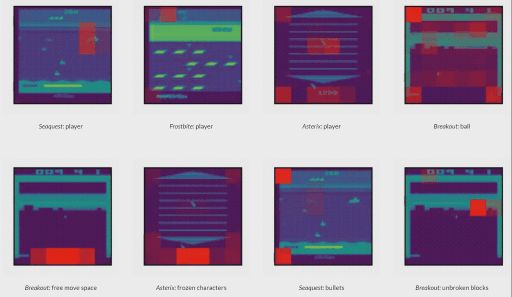
从不同游戏中,研究者发现:模型会关注有意义的图像块,如玩家角色、玩家的自由移动空间、非玩家对象和其他环境特征:
当然决策Transformer模型已经不是第一次提出来的,其开山之作可以看这篇文章:
《Decision Transformer: Reinforcement Learning via Sequence Modeling》

还有类似的在RL领域上提出的Trajectory Transformers,希望这些Transformers能够像在NLP和视觉任务上,在RL领域也能够大放异彩。
我是leo,欢迎关注我的公众号“算法一只狗”,我们下期再见~