Hadoop、Hive On k8s
参考文章:在Kubernetes上部署Hadoop_迷途的攻城狮(798570156)的博客-CSDN博客_apache hadoop k8s
1、环境介绍:
机器:
| IP | 主机名 | 角色 |
|---|---|---|
| 192.168.119.129 | master | k8s-master01 |
| 192.168.119.130 | node1 | k8s-master02 |

Hadoop版本:hadoop-2.7.2
Hive版本:hive-2.1.1
目前在K8S里面调试Yarn环境,无法正常提交任务至Yarn运行,ResourceManager和NodeManager不部署
注意:在开启端口映射时,比如,将容器内的端口:8020 映射到宿主机:8020 ,会报错:
:::info
The Service “xxx-service” is invalid: spec.ports[1].nodePort: Invalid value: 8020: provided port is not in the valid range. The range of valid ports is 30000-32767
:::
K8s 默认端口映射的范围:30000 – 32767,需要手动调整范围:
修改 kube-apiserver 开启Node的pod端口范围
2、DockerFile
vim docker-hadoop
FROM openjdk:8-jdk
ENV HADOOP_VERSION 2.7.2
ENV HIVE_VERSION 2.1.1
ENV HADOOP_HOME=/opt/hadoop
ENV HIVE_HOME /opt/hive
ENV HADOOP_COMMON_HOME=${HADOOP_HOME} \
HADOOP_HDFS_HOME=${HADOOP_HOME} \
HADOOP_MAPRED_HOME=${HADOOP_HOME} \
HADOOP_YARN_HOME=${HADOOP_HOME} \
HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop \
PATH=${PATH}:${HADOOP_HOME}/bin
ENV PATH=${PATH}:${HIVE_HOME}/bin
#RUN curl --silent --output /tmp/hadoop.tgz https://ftp-stud.hs-esslingen.de/pub/Mirrors/ftp.apache.org/dist/hadoop/common/hadoop-${HADOOP_VERSION}/hadoop-${HADOOP_VERSION}.tar.gz && tar --directory /opt -xzf /tmp/hadoop.tgz && rm /tmp/hadoop.tgz
#RUN curl --silent --output /tmp/hive.tgz http://archive.apache.org/dist/hive/hive-${HIVE_VERSION}/apache-hive-${HIVE_VERSION}-bin.tar.gz && tar --directory /opt -xzf /tmp/hive.tgz && rm /tmp/hadoop.tgz
COPY apache-hive-${HIVE_VERSION}-bin.tar.gz /tmp/hive.tgz
COPY hadoop-${HADOOP_VERSION}.tar.gz /tmp/hadoop.tgz
RUN tar --directory /opt -xzf /tmp/hive.tgz && rm /tmp/hive.tgz
RUN tar --directory /opt -xzf /tmp/hadoop.tgz && rm /tmp/hadoop.tgz
RUN mv /opt/apache-hive-${HIVE_VERSION}-bin /opt/hive-${HIVE_VERSION}
RUN ln -s /opt/hive-${HIVE_VERSION} ${HIVE_HOME}
COPY mysql-connector-java-5.1.47-bin.jar ${HIVE_HOME}/lib/
RUN ln -s /opt/hadoop-${HADOOP_VERSION} ${HADOOP_HOME}
WORKDIR $HADOOP_HOME
# Hdfs ports
EXPOSE 50010 50020 50070 50075 50090 8020 9000
# Mapred ports
EXPOSE 19888
#Yarn ports
EXPOSE 8030 8031 8032 8033 8040 8042 8088 8090
#Other ports
EXPOSE 49707 2122
# Hive port
EXPOSE 10000 10002 9083
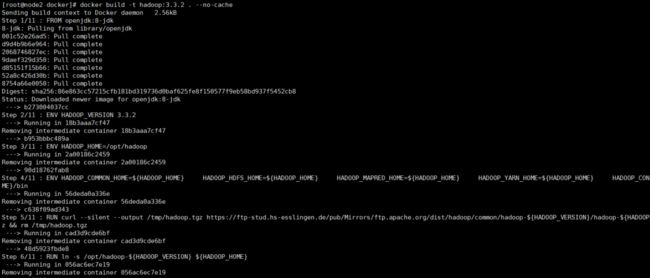
- 构建镜像
docker build -f docker-hadoop -t hadoop:2.7.2 . --no-cache
- 将镜像上传到阿里云镜像仓库
[root@node2 docker]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hadoop 3.3.2 3c5e7afd9959 About an hour ago 1.84GB
openjdk 8-jdk b273004037cc 6 months ago 526MB
redis latest 3edbb69f9a49 7 months ago 117MB
big-data/pig v3.1.2204 2e48ce06d2fa 10 months ago 1.26GB
big-data/mysql-redis v3.0.2111 6a0542caf04c 14 months ago 453MB
guohao/kibanatest 0.1 23367f808e5a 15 months ago 2GB
abell_test 0.1 ba6acccedd29 16 months ago 72.8MB
ubuntu latest ba6acccedd29 16 months ago 72.8MB
centos 8 5d0da3dc9764 17 months ago 231MB
centos latest 5d0da3dc9764 17 months ago 231MB
big-data/mysql-redis v2 b42d43966aa9 19 months ago 453MB
portainer/portainer latest 62771b0b9b09 2 years ago 79.1MB
kibana 7.6.0 b36db011e72c 3 years ago 1.01GB
elasticsearch 7.6.0 5d2812e0e41c 3 years ago 790MB
[root@node2 docker]# docker tag 3c5e7afd9959 registry.cn-hangzhou.aliyuncs.com/dockerxiahu/hadoop:3.3.2
[root@node2 docker]# docker push registry.cn-hangzhou.aliyuncs.com/dockerxiahu/hadoop:3.3.2
The push refers to repository [registry.cn-hangzhou.aliyuncs.com/dockerxiahu/hadoop]
07c796120429: Pushed
52ed9ff2fb8e: Pushed
6b5aaff44254: Pushed
53a0b163e995: Pushed
b626401ef603: Pushed
9b55156abf26: Pushed
293d5db30c9f: Pushed
03127cdb479b: Pushed
9c742cd6c7a5: Pushed
3.3.2: digest: sha256:bef0b6581a47585e2dd5010002c1895abb9d7793048071c56a50c52974d4bad5 size: 2215
3、搭建NFS
服务端配置
## 创建同步目录
sudo mkdir /home/nfs
## 安装同步服务
sudo yum install -y rpcbind nfs-utils
## 设置同步目录
sudo vim /etc/exports
/home/nfs *(insecure,rw,sync,no_root_squash)
## 服务开机自启动
sudo systemctl enable rpcbind
sudo systemctl start rpcbind
sudo systemctl enable nfs-server
sudo systemctl start nfs-server
sudo exportfs -r
sudo exportfs
## 防火墙设置
sudo firewall-cmd --zone=public --permanent --add-service=rpc-bind
sudo firewall-cmd --zone=public --permanent --add-service=mountd
sudo firewall-cmd --zone=public --permanent --add-service=nfs
sudo firewall-cmd --reload
客户端配置
## 检查服务端共享目录
sudo showmount -e 192.168.119.129
## 挂在共享目录
sudo mkdir /home/nfs
sudo mount -t nfs 192.168.119.129:/home/nfs /home/nfs
## 同步服务 自动挂载
sudo vim /etc/fstab
192.168.119.129:/home/nfs /home/nfs nfs defaults 0 0
sudo systemctl daemon-reload
4、构建Yaml文件
pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: hadoop-config-nfs-pv
namespace: hadoop
labels:
release: hadoop-config
spec:
capacity:
storage: 16Mi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
path: /home/nfs/data/hadoop-config
server: 192.168.119.129
创建/home/nfs/data/hadoop-config共享路径,用于存储hadoop的配置文件
pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: hadoop-config-nfs-pvc
namespace: hadoop
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 16Mi
selector:
matchLabels:
release: hadoop-config
pv与pvc进行绑定
hadoop-namenode
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: hadoop-nn
namespace: hadoop
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: hadoop-nn
serviceName: hadoop-nn-service
template:
metadata:
labels:
app: hadoop-nn
spec:
containers:
- name: hadoop-nn
image: registry.cn-hangzhou.aliyuncs.com/dockerxiahu/hadoop:2.7.2
command:
- "/bin/bash"
- "/root/bootstrap/bootstrap.sh"
- "-d"
env:
- name: HADOOP_CONF_DIR
value: /etc/hadoop
- name: NODE_TYPE
value: NN
volumeMounts:
- name: hadoop-config-volume
mountPath: /etc/hadoop
- name: hadoop-custom-config-volume
mountPath: /root/bootstrap
- name: dfs-name-dir-volume
mountPath: /dfs/nn
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-master01
volumes:
- name: hadoop-config-volume
persistentVolumeClaim:
claimName: hadoop-config-nfs-pvc
- name: hadoop-custom-config-volume
configMap:
name: hadoop-custom-config-cm
- name: dfs-name-dir-volume
hostPath:
path: /opt/dfs/nn
type: DirectoryOrCreate
- 创建Pod,名称为:hadoop-nn
- 从
registry.cn-hangzhou.aliyuncs.com/dockerxiahu/hadoop:2.7.2拉取镜像 - 设置环境变量:
$HADOOP_CONF_DIR,$NODE_TYPE - 添加挂载卷,与宿主机进行交互,持久化存储数据
- 容器:
/etc/hadoop—> 宿主机:/home/nfs/data/hadoop-config - 容器:
/root/bootstrap—> 配置文件内的bootstrap.sh移动到/root/bootstrap - 容器:
/dfs/nn—> 宿主机:/opt/dfs/nn
- 容器:
- 最后会执行shell:
/bin/bash /root/bootstrap/bootstrap.sh -d
hadoop-namenode-service
apiVersion: v1
kind: Service
metadata:
name: hadoop-nn-service
namespace: hadoop
labels:
app: hadoop-nn
spec:
ports:
- nodePort: 50070
port: 50070
targetPort: 50070
name: datanode
- nodePort: 8020
port: 8020
targetPort: 8020
name: namenode
selector:
app: hadoop-nn
type: NodePort
管理hadoop-nnpod
hadoop-datanode
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: hadoop-dn-node1
namespace: hadoop
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: hadoop-dn-node1
serviceName: hadoop-dn-node1-service
template:
metadata:
labels:
app: hadoop-dn-node1
spec:
containers:
- name: hadoop-dn-node1
image: registry.cn-hangzhou.aliyuncs.com/dockerxiahu/hadoop:2.7.2
command:
- "/bin/bash"
- "/root/bootstrap/bootstrap.sh"
- "-d"
env:
- name: HADOOP_CONF_DIR
value: /etc/hadoop
- name: NODE_TYPE
value: DN
volumeMounts:
- name: hadoop-config-volume
mountPath: /etc/hadoop
- name: hadoop-custom-config-volume
mountPath: /root/bootstrap
- name: dfs-data-dir-volume
mountPath: /dfs/dn/data
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- nfs-server
volumes:
- name: hadoop-config-volume
persistentVolumeClaim:
claimName: hadoop-config-nfs-pvc
- name: hadoop-custom-config-volume
configMap:
name: hadoop-custom-config-cm
- name: dfs-data-dir-volume
hostPath:
path: /opt/dfs/dn
type: DirectoryOrCreate
- 创建Pod,名称为:hadoop-dn-node1
- 从
registry.cn-hangzhou.aliyuncs.com/dockerxiahu/hadoop:2.7.2拉取镜像 - 设置环境变量:
$HADOOP_CONF_DIR,$NODE_TYPE - 添加挂载卷,与宿主机进行交互,持久化存储数据
- 容器:
/etc/hadoop—> 宿主机:/home/nfs/data/hadoop-config - 容器:
/root/bootstrap—> 配置文件内的bootstrap.sh移动到/root/bootstrap - 容器:
/dfs/dn/data—> 宿主机:/opt/dfs/dn
- 容器:
- 最后会执行shell:
/bin/bash /root/bootstrap/bootstrap.sh -d
configMap
apiVersion: v1
kind: ConfigMap
metadata:
name: hadoop-custom-config-cm
namespace: hadoop
labels:
app: hadoop
data:
bootstrap.sh: |-
#!/bin/bash
NAME_NODE_MEMORY=900m
DATA_NODE_MEMORY=1000m
RESOURCE_MANAGER_MEMORY=900m
NODE_MANAGER_MEMORY=900m
cd /root/bootstrap
# Don't override slaves、core-site.xml and yarn-site.xml
if [[ ! -e $HADOOP_CONF_DIR/NameNode ]];then
rm -f $HADOOP_HOME/etc/hadoop/slaves $HADOOP_HOME/etc/hadoop/core-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml
# Copy original hadoop file to $HADOOP_CONF_DIR
cp -a $HADOOP_HOME/etc/hadoop/* $HADOOP_CONF_DIR
fi
# Get this node's FQDN
#FQDN=`ping $HOSTNAME -c 1 | grep PING | awk '{print $2}'`
FQDN=$HOSTNAME
# NAME_NODE_FQDN=$FQDN".hadoop-nn-service"
# sed -i 's/${NAME_NODE_SERVICE_NAME}/'$NAME_NODE_FQDN'/g' `grep '${NAME_NODE_SERVICE_NAME}' -rl $HADOOP_CONF_DIR`
# sed -i 's/${NAME_NODE_SERVICE_NAME}/'$NAME_NODE_FQDN'/g' `grep '${NAME_NODE_SERVICE_NAME}' -rl $HADOOP_HOME/etc/hadoop`
# If this node is nameNode, set it's FQDN to core-site.xml file and yarn-site.xml file
if [[ "$NODE_TYPE" =~ "NN" ]]; then
for cfg in ./*; do
if [[ ! "$cfg" =~ bootstrap.sh ]]; then
cat $cfg > $HADOOP_CONF_DIR/${cfg##*/}
fi
done
for f in slaves core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml; do
if [[ -e ${HADOOP_CONF_DIR}/$f ]]; then
cp -a ${HADOOP_CONF_DIR}/$f $HADOOP_HOME/etc/hadoop/$f
else
echo "ERROR: Could not find $f in $CONFIG_DIR"
exit 1
fi
done
NAME_NODE_FQDN=$FQDN".hadoop-nn-service"
sed -i 's/${NAME_NODE_SERVICE_NAME}/'$NAME_NODE_FQDN'/g' `grep '${NAME_NODE_SERVICE_NAME}' -rl $HADOOP_CONF_DIR`
sed -i 's/${NAME_NODE_SERVICE_NAME}/'$NAME_NODE_FQDN'/g' `grep '${NAME_NODE_SERVICE_NAME}' -rl $HADOOP_HOME/etc/hadoop`
if [[ ! -e $HADOOP_CONF_DIR/namenode_memory_set ]];then
# 修改NameNode启动时JVM参数
echo "export HADOOP_NAMENODE_OPTS=\"-Xms${NAME_NODE_MEMORY} -Xmx${NAME_NODE_MEMORY}\"" >> $HADOOP_CONF_DIR/hadoop-env.sh
echo "export HADOOP_NAMENODE_OPTS=\"-Xms${NAME_NODE_MEMORY} -Xmx${NAME_NODE_MEMORY}\"" >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh
echo 1 >> $HADOOP_CONF_DIR/namenode_memory_set
fi
if [[ ! -e $HADOOP_CONF_DIR/resourcemanager_memory_set ]];then
# 修改ResouceManager启动时JVM参数
echo "export YARN_RESOURCEMANAGER_OPTS=\"-Xms${RESOURCE_MANAGER_MEMORY} -Xmx${RESOURCE_MANAGER_MEMORY}\"" >> $HADOOP_CONF_DIR/yarn-env.sh
echo "export YARN_RESOURCEMANAGER_OPTS=\"-Xms${RESOURCE_MANAGER_MEMORY} -Xmx${RESOURCE_MANAGER_MEMORY}\"" >> $HADOOP_HOME/etc/hadoop/yarn-env.sh
echo 1 >> $HADOOP_CONF_DIR/resourcemanager_memory_set
fi
#mkdir -p /var/hadoop/dfs/name
# Apply custom config file context
#for cfg in ./*; do
# if [[ ! "$cfg" =~ bootstrap.sh ]]; then
# cat $cfg > $HADOOP_CONF_DIR/${cfg##*/}
# fi
#done
# Set nameNode's FQDN to file
echo $FQDN > $HADOOP_CONF_DIR/NameNode
# Format HDFS if not formatted yet
if [[ ! -e $HADOOP_CONF_DIR/hdfs-namenode-format.out ]]; then
$HADOOP_HOME/bin/hdfs namenode -format -force -nonInteractive &> $HADOOP_CONF_DIR/hdfs-namenode-format.out
$HADOOP_HOME/bin/hdfs namenode -format -force -nonInteractive &> $HADOOP_CONF_DIR/hdfs-namenode-format.out
fi
if [ ! -f $HADOOP_CONF_DIR/namenode_formated ]; then
# Only format if necessary
$HADOOP_HOME/bin/hdfs namenode -format -force -nonInteractive && echo 1 > $HADOOP_CONF_DIR/namenode_formated
fi
# Start hadoop nameNode daemon
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode
fi
# If this node is ResourceManager
if [[ "$NODE_TYPE" =~ "RM" ]]; then
$HADOOP_HOME/sbin/yarn-daemon.sh start resourcemanager
$HADOOP_HOMEsbin/mr-jobhistory-daemon.sh start historyserver
fi
# If this node is nodeManager, add it to slave
if [[ "$NODE_TYPE" =~ "NM" ]]; then
#sed -i '/'$FQDN'/d' $HADOOP_CONF_DIR/workers
#echo $FQDN >> $HADOOP_CONF_DIR/workers
# Waiting nameNode set NAME_NODE_FQDN
while [[ ! -e $HADOOP_CONF_DIR/NameNode || -z $NAME_NODE_FQDN ]]; do
echo "Waiting for nameNode set NAME_NODE_FQDN" && sleep 2 && NAME_NODE_FQDN=`cat $HADOOP_CONF_DIR/NameNode`
done
sed -i '/localhost/d' $HADOOP_CONF_DIR/slaves
sed -i '/'$FQDN'/d' $HADOOP_CONF_DIR/slaves
echo $FQDN >> $HADOOP_CONF_DIR/slaves
NAME_NODE_HOSTNAME=`cat $HADOOP_CONF_DIR/NameNode`
NAME_NODE_FQDN=$NAME_NODE_HOSTNAME".hadoop-nn-service"
sed -i 's/${NAME_NODE_SERVICE_NAME}/'${NAME_NODE_FQDN}'/g' $HADOOP_CONF_DIR/yarn-site.xml
if [[ ! -e $HADOOP_CONF_DIR/nodemanager_memory_set ]];then
#修改DataNode启动时JVM参数
echo "export YARN_NODEMANAGER_OPTS=\"-Xms${NODE_MANAGER_MEMORY} -Xmx${NODE_MANAGER_MEMORY}\"" >> $HADOOP_CONF_DIR/yarn-env.sh
echo "export YARN_NODEMANAGER_OPTS=\"-Xms${NODE_MANAGER_MEMORY} -Xmx${NODE_MANAGER_MEMORY}\"" >> $HADOOP_HOME/etc/hadoop/yarn-env.sh
echo 1 >> $HADOOP_CONF_DIR/nodemanager_memory_set
fi
# Start hadoop nodeManager daemon
while [[ -z `curl -sf http://$NAME_NODE_FQDN:8088/ws/v1/cluster/info` ]]; do
echo "Waiting for $FQDN" && sleep 2
done
$HADOOP_HOME/sbin/yarn-daemon.sh start nodemanager
fi
# If this node is dataNode, add it to slave
if [[ "$NODE_TYPE" =~ "DN" ]]; then
#sed -i '/localhost/d' $HADOOP_CONF_DIR/workers
#sed -i '/'$FQDN'/d' $HADOOP_CONF_DIR/workers
#echo $FQDN >> $HADOOP_CONF_DIR/workers
# Waiting nameNode set NAME_NODE_FQDN
while [[ ! -e $HADOOP_CONF_DIR/NameNode || -z $NAME_NODE_FQDN ]]; do
echo "Waiting for nameNode set NAME_NODE_FQDN" && sleep 2 && NAME_NODE_FQDN=`cat $HADOOP_CONF_DIR/NameNode`
done
sed -i '/localhost/d' $HADOOP_CONF_DIR/slaves
sed -i '/'$FQDN'/d' $HADOOP_CONF_DIR/slaves
echo $FQDN >> $HADOOP_CONF_DIR/slaves
NAME_NODE_HOSTNAME=`cat $HADOOP_CONF_DIR/NameNode`
NAME_NODE_FQDN=$NAME_NODE_HOSTNAME".hadoop-nn-service"
sed -i 's/${NAME_NODE_SERVICE_NAME}/'${NAME_NODE_FQDN}'/g' $HADOOP_CONF_DIR/core-site.xml
sed -i 's/${HOST_NAME}/'${FQDN}'/g' $HADOOP_CONF_DIR/hdfs-site.xml
if [[ ! -e $HADOOP_CONF_DIR/datanode_memory_set ]];then
# 修改DataNode启动时JVM参数
echo "export HADOOP_DATANODE_OPTS=\"-Xms${DATA_NODE_MEMORY} -Xmx${DATA_NODE_MEMORY}\"" >> $HADOOP_CONF_DIR/hadoop-env.sh
echo "export HADOOP_DATANODE_OPTS=\"-Xms${DATA_NODE_MEMORY} -Xmx${DATA_NODE_MEMORY}\"" >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh
echo 1 >> $HADOOP_CONF_DIR/datanode_memory_set
fi
# Start hadoop dataNode daemon
while [[ -z `curl http://$NAME_NODE_FQDN:8020` ]]; do
echo "Waiting for $NAME_NODE_FQDN" && sleep 2
done
$HADOOP_HOME/sbin/hadoop-daemon.sh start datanode
fi
if [[ "$NODE_TYPE" =~ "HIVE" ]]; then
while [[ ! -e $HADOOP_CONF_DIR/NameNode || -z $NAME_NODE_FQDN ]]; do
echo "Waiting for nameNode set NAME_NODE_FQDN" && sleep 2 && NAME_NODE_FQDN=`cat $HADOOP_CONF_DIR/NameNode`
done
for cfg in ./*; do
if [[ "$cfg" =~ hive-site.xml ]]; then
cat $cfg > $HADOOP_CONF_DIR/${cfg##*/}
fi
done
cp -a $HADOOP_CONF_DIR/hive-site.xml $HIVE_HOME/conf/
# hive
if [ ! -f $HADOOP_CONF_DIR/hive_init_schema ]; then
#hive init schema
$HIVE_HOME/bin/schematool -dbType mysql -initSchema && echo 1 > $HADOOP_CONF_DIR/hive_init_schema
fi
cd $HIVE_HOME/bin
nohup hive --service hiveserver2 >> /etc/hadoop/hive-hiveserver2.log 2>&1 &
nohup hive --service metastore >> /etc/hadoop/hive-metastore.log 2>&1 &
fi
# keep running
sleep infinity
hdfs-site.xml: |-
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
>
>
>dfs.name.dir >
>/dfs/nn >
>
>
>dfs.data.dir >
>/dfs/dn/data/ >
>
>
>dfs.replication >
>3 >
>
>
>dfs.namenode.datanode.registration.ip-hostname-check >
>false >
>
>
>dfs.datanode.use.datanode.hostname >
>true >
>
>
core-site.xml: |-
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
>
>
>fs.defaultFS >
>hdfs://${NAME_NODE_SERVICE_NAME}:8020 >
>
>
>hadoop.tmp.dir >
>/var/hadoop >
>
>
>hadoop.proxyuser.root.hosts >
>*
>
>
>hadoop.proxyuser.root.groups >
>*
>
>
mapred-site.xml: |-
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
>
>
>mapreduce.framework.name >
>yarn >
>
>
yarn-site.xml: |-
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
yarn.acl.enable
true
yarn.admin.acl
*
yarn.resourcemanager.address
${NAME_NODE_SERVICE_NAME}:8032
yarn.resourcemanager.admin.address
${NAME_NODE_SERVICE_NAME}:8033
yarn.resourcemanager.scheduler.address
${NAME_NODE_SERVICE_NAME}:8030
yarn.resourcemanager.resource-tracker.address
${NAME_NODE_SERVICE_NAME}:8031
yarn.resourcemanager.webapp.address
${NAME_NODE_SERVICE_NAME}:8088
yarn.resourcemanager.webapp.https.address
${NAME_NODE_SERVICE_NAME}:8090
yarn.resourcemanager.client.thread-count
50
yarn.resourcemanager.scheduler.client.thread-count
50
yarn.resourcemanager.admin.client.thread-count
1
yarn.scheduler.minimum-allocation-mb
1024
yarn.scheduler.increment-allocation-mb
512
yarn.scheduler.maximum-allocation-mb
49192
yarn.scheduler.minimum-allocation-vcores
1
yarn.scheduler.increment-allocation-vcores
1
yarn.scheduler.maximum-allocation-vcores
32
yarn.resourcemanager.amliveliness-monitor.interval-ms
1000
yarn.am.liveness-monitor.expiry-interval-ms
600000
yarn.resourcemanager.am.max-attempts
2
yarn.resourcemanager.container.liveness-monitor.interval-ms
600000
yarn.resourcemanager.nm.liveness-monitor.interval-ms
1000
yarn.nm.liveness-monitor.expiry-interval-ms
600000
yarn.resourcemanager.resource-tracker.client.thread-count
50
yarn.application.classpath
$HADOOP_CLIENT_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
yarn.scheduler.capacity.resource-calculator
org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
yarn.resourcemanager.max-completed-applications
10000
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
Whether to enable log aggregation
yarn.log-aggregation-enable
true
yarn.log.server.url
${NAME_NODE_SERVICE_NAME}:19888/jobhistory/logs
slaves: |-
localhost
hive-site.xml: |-
>
>
>javax.jdo.option.ConnectionURL >
>jdbc:mysql://192.168.0.220:3306/hive?createDatabaseIfNotExist=true >
>
>
>javax.jdo.option.ConnectionDriverName >
>com.mysql.jdbc.Driver >
>
>
>javax.jdo.option.ConnectionUserName >
>hive >
>
>
>javax.jdo.option.ConnectionPassword >
>hive >
>
>
>hive.metastore.warehouse.dir >
>/hive/warehouse >
>
>
>hive.metastore.schema.verification >
>false >
>
>
简洁版
apiVersion: v1
kind: ConfigMap
metadata:
name: hadoop-custom-config-cm
namespace: hadoop
labels:
app: hadoop
data:
bootstrap.sh: |-
#!/bin/bash
NAME_NODE_MEMORY=900m
DATA_NODE_MEMORY=1000m
RESOURCE_MANAGER_MEMORY=900m
NODE_MANAGER_MEMORY=900m
cd /root/bootstrap
# Don't override slaves、core-site.xml and yarn-site.xml
if [[ ! -e $HADOOP_CONF_DIR/NameNode ]];then
rm -f $HADOOP_HOME/etc/hadoop/slaves $HADOOP_HOME/etc/hadoop/core-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml
# Copy original hadoop file to $HADOOP_CONF_DIR
cp -a $HADOOP_HOME/etc/hadoop/* $HADOOP_CONF_DIR
fi
# Get this node's FQDN
#FQDN=`ping $HOSTNAME -c 1 | grep PING | awk '{print $2}'`
FQDN=$HOSTNAME
$HADOOP_HOME/etc/hadoop`
# If this node is nameNode, set it's FQDN to core-site.xml file and yarn-site.xml file
if [[ "$NODE_TYPE" =~ "NN" ]]; then
for cfg in ./*; do
if [[ ! "$cfg" =~ bootstrap.sh ]]; then
cat $cfg > $HADOOP_CONF_DIR/${cfg##*/}
fi
done
for f in slaves core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml; do
if [[ -e ${HADOOP_CONF_DIR}/$f ]]; then
cp -a ${HADOOP_CONF_DIR}/$f $HADOOP_HOME/etc/hadoop/$f
else
echo "ERROR: Could not find $f in $CONFIG_DIR"
exit 1
fi
done
NAME_NODE_FQDN=$FQDN".hadoop-nn-service"
sed -i 's/${NAME_NODE_SERVICE_NAME}/'$NAME_NODE_FQDN'/g' `grep '${NAME_NODE_SERVICE_NAME}' -rl $HADOOP_CONF_DIR`
sed -i 's/${NAME_NODE_SERVICE_NAME}/'$NAME_NODE_FQDN'/g' `grep '${NAME_NODE_SERVICE_NAME}' -rl $HADOOP_HOME/etc/hadoop`
if [[ ! -e $HADOOP_CONF_DIR/namenode_memory_set ]];then
# 修改NameNode启动时JVM参数
echo "export HADOOP_NAMENODE_OPTS=\"-Xms${NAME_NODE_MEMORY} -Xmx${NAME_NODE_MEMORY}\"" >> $HADOOP_CONF_DIR/hadoop-env.sh
echo "export HADOOP_NAMENODE_OPTS=\"-Xms${NAME_NODE_MEMORY} -Xmx${NAME_NODE_MEMORY}\"" >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh
echo 1 >> $HADOOP_CONF_DIR/namenode_memory_set
fi
# Set nameNode's FQDN to file
echo $FQDN > $HADOOP_CONF_DIR/NameNode
# Format HDFS if not formatted yet
if [[ ! -e $HADOOP_CONF_DIR/hdfs-namenode-format.out ]]; then
$HADOOP_HOME/bin/hdfs namenode -format -force -nonInteractive &> $HADOOP_CONF_DIR/hdfs-namenode-format.out
$HADOOP_HOME/bin/hdfs namenode -format -force -nonInteractive &> $HADOOP_CONF_DIR/hdfs-namenode-format.out
fi
if [ ! -f $HADOOP_CONF_DIR/namenode_formated ]; then
# Only format if necessary
$HADOOP_HOME/bin/hdfs namenode -format -force -nonInteractive && echo 1 > $HADOOP_CONF_DIR/namenode_formated
fi
# Start hadoop nameNode daemon
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode
fi
# If this node is dataNode, add it to slave
if [[ "$NODE_TYPE" =~ "DN" ]]; then
#sed -i '/localhost/d' $HADOOP_CONF_DIR/workers
#sed -i '/'$FQDN'/d' $HADOOP_CONF_DIR/workers
#echo $FQDN >> $HADOOP_CONF_DIR/workers
# Waiting nameNode set NAME_NODE_FQDN
while [[ ! -e $HADOOP_CONF_DIR/NameNode || -z $NAME_NODE_FQDN ]]; do
echo "Waiting for nameNode set NAME_NODE_FQDN" && sleep 2 && NAME_NODE_FQDN=`cat $HADOOP_CONF_DIR/NameNode`
done
sed -i '/localhost/d' $HADOOP_CONF_DIR/slaves
sed -i '/'$FQDN'/d' $HADOOP_CONF_DIR/slaves
echo $FQDN >> $HADOOP_CONF_DIR/slaves
NAME_NODE_HOSTNAME=`cat $HADOOP_CONF_DIR/NameNode`
NAME_NODE_FQDN=$NAME_NODE_HOSTNAME".hadoop-nn-service"
sed -i 's/${NAME_NODE_SERVICE_NAME}/'${NAME_NODE_FQDN}'/g' $HADOOP_CONF_DIR/core-site.xml
sed -i 's/${HOST_NAME}/'${FQDN}'/g' $HADOOP_CONF_DIR/hdfs-site.xml
if [[ ! -e $HADOOP_CONF_DIR/datanode_memory_set ]];then
# 修改DataNode启动时JVM参数
echo "export HADOOP_DATANODE_OPTS=\"-Xms${DATA_NODE_MEMORY} -Xmx${DATA_NODE_MEMORY}\"" >> $HADOOP_CONF_DIR/hadoop-env.sh
echo "export HADOOP_DATANODE_OPTS=\"-Xms${DATA_NODE_MEMORY} -Xmx${DATA_NODE_MEMORY}\"" >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh
echo 1 >> $HADOOP_CONF_DIR/datanode_memory_set
fi
# Start hadoop dataNode daemon
while [[ -z `curl http://$NAME_NODE_FQDN:8020` ]]; do
echo "Waiting for $NAME_NODE_FQDN" && sleep 2
done
$HADOOP_HOME/sbin/hadoop-daemon.sh start datanode
fi
if [[ "$NODE_TYPE" =~ "HIVE" ]]; then
while [[ ! -e $HADOOP_CONF_DIR/NameNode || -z $NAME_NODE_FQDN ]]; do
echo "Waiting for nameNode set NAME_NODE_FQDN" && sleep 2 && NAME_NODE_FQDN=`cat $HADOOP_CONF_DIR/NameNode`
done
for cfg in ./*; do
if [[ "$cfg" =~ hive-site.xml ]]; then
cat $cfg > $HADOOP_CONF_DIR/${cfg##*/}
fi
done
cp -a $HADOOP_CONF_DIR/hive-site.xml $HIVE_HOME/conf/
# hive
if [ ! -f $HADOOP_CONF_DIR/hive_init_schema ]; then
#hive init schema
$HIVE_HOME/bin/schematool -dbType mysql -initSchema && echo 1 > $HADOOP_CONF_DIR/hive_init_schema
fi
cd $HIVE_HOME/bin
nohup hive --service hiveserver2 >> /etc/hadoop/hive-hiveserver2.log 2>&1 &
nohup hive --service metastore >> /etc/hadoop/hive-metastore.log 2>&1 &
fi
# keep running
sleep infinity
hdfs-site.xml: |-
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
>
>
>dfs.name.dir >
>/dfs/nn >
>
>
>dfs.data.dir >
>/dfs/dn/data/ >
>
>
>dfs.replication >
>3 >
>
>
>dfs.namenode.datanode.registration.ip-hostname-check >
>false >
>
>
>dfs.datanode.use.datanode.hostname >
>true >
>
>
core-site.xml: |-
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
>
>
>fs.defaultFS >
>hdfs://${NAME_NODE_SERVICE_NAME}:8020 >
>
>
>hadoop.tmp.dir >
>/var/hadoop >
>
>
>hadoop.proxyuser.root.hosts >
>*
>
>
>hadoop.proxyuser.root.groups >
>*
>
>
slaves: |-
localhost
hive-site.xml: |-
>
>
>javax.jdo.option.ConnectionURL >
>jdbc:mysql://192.168.0.220:3306/hive?createDatabaseIfNotExist=true >
>
>
>javax.jdo.option.ConnectionDriverName >
>com.mysql.jdbc.Driver >
>
>
>javax.jdo.option.ConnectionUserName >
>hive >
>
>
>javax.jdo.option.ConnectionPassword >
>hive >
>
>
>hive.metastore.warehouse.dir >
>/hive/warehouse >
>
>
>hive.metastore.schema.verification >
>false >
>
>
hive
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: hive
namespace: hadoop
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: hive
serviceName: hive-service
template:
metadata:
labels:
app: hive
spec:
containers:
- name: hive
image: registry.cn-hangzhou.aliyuncs.com/dockerxiahu/hadoop:2.7.2
command:
- "/bin/bash"
- "/root/bootstrap/bootstrap.sh"
- "-d"
env:
- name: HADOOP_CONF_DIR
value: /etc/hadoop
- name: NODE_TYPE
value: HIVE
volumeMounts:
- name: hadoop-config-volume
mountPath: /etc/hadoop
- name: hadoop-custom-config-volume
mountPath: /root/bootstrap
volumes:
- name: hadoop-config-volume
persistentVolumeClaim:
claimName: hadoop-config-nfs-pvc
- name: hadoop-custom-config-volume
configMap:
name: hadoop-custom-config-cm
---
apiVersion: v1
kind: Service
metadata:
name: hive-service
namespace: hadoop
labels:
app: hive
spec:
ports:
- nodePort: 10000
port: 10000
targetPort: 10000
name: hiveserver2
- nodePort: 9083
port: 9083
targetPort: 9083
name: metastore
- nodePort: 10002
port: 10002
targetPort: 10002
name: hiveweb
selector:
app: hive
type: NodePort
5、启动
将上面的7个文件合成一个文件:start.yaml
# 创建命名空间
[root@master hadoop-config]# kubectl create namespace hadoop
[root@master hadoop-config]# kubectl apply -f start.yaml
[root@master hadoop-config]# kubectl get -n hadoop pod,svc,deployment,configmap,pv
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/hadoop-dn-node1-0 1/1 Running 0 49m 100.96.251.229 nfs-server <none> <none>
pod/hadoop-nn-0 1/1 Running 0 49m 100.124.32.186 k8s-master01 <none> <none>
pod/hive-0 1/1 Running 0 45m 100.84.122.170 k8s-master02 <none> <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/hadoop-nn-service NodePort 10.96.2.17 <none> 50070:50070/TCP,8020:8020/TCP 49m app=hadoop-nn
service/hive-service NodePort 10.96.1.64 <none> 10000:10000/TCP,9083:9083/TCP,10002:10002/TCP 45m app=hive

6、验证
datanode
http://192.168.119.129:50070/

hive
http://192.168.119.130:10002