ClickHouse(二):ClickHouse特性

目录
1. 完备的DBMS功能
2. 列式存储
3. 数据压缩
4. 向量化执行引擎
5. 关系模型与标准SQL查询
6. 多样化的表引擎
7. 多线程与分布式
8. 多主架构
9. 交互式查询
10. 数据分片与分布式查询
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
个人主页:含各种IT体系技术,IT贫道_Apache Doris,Kerberos安全认证,随笔-CSDN博客
订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
1. 完备的DBMS功能
ClickHouse是一个数据库管理系统,而不仅是一个数据库,作为数据库管理系统具备完备的管理功能:
- DDL(Data Definition Language-数据定义语言):可以动态地创建、修改或删除数据库、表和视图,而无须重启服务。
- DML(Data Manipulation Language):可以动态查询、插入、修改或删除数据。
- 分布式管理:提供集群模式,能够自动管理多个数据库节点。
- 权限控制:可以按照用户粒度设置数据库或者表的操作权限,保障数据的安全性。
- 数据备份与恢复:提供了数据备份导出与导入恢复机制,满足生产环境的要求。
2. 列式存储
目前大数据存储有两种方案可以选择,行式存储(Row-Based)和列式存储(Column-Based)。
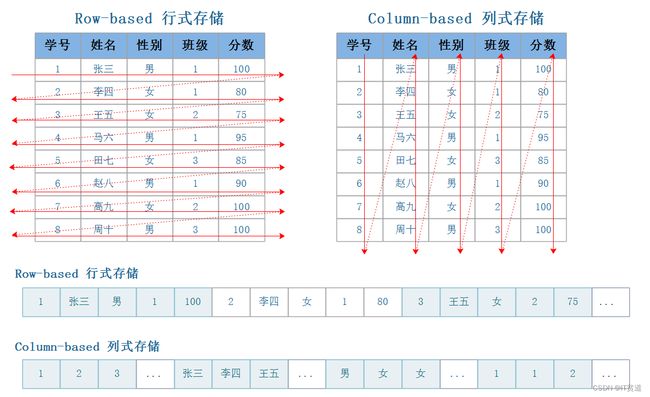
- 行式存储在数据写入和修改上具有优势。
行存储的写入是一次完成的,如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,可以保证数据的完整性。列式存储需要把一行记录拆分成单列保存,写入次数明显比行存储多(因为磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms),再加上磁头需要在盘片上移动和定位花费的时间,实际消耗更大。
数据修改实际上也是一次写入过程,不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。
所以,行式存储在数据写入和修改上具有很大优势。
- 列式存储在数据读取和解析、分析数据上具有优势。
数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。列存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
列式存储中的每一列数据类型是相同的,不存在二义性问题,例如,某列类型为整型int,那么它的数据集合一定是整型数据,这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。
所以,列式存储在数据读取和解析数据做数据分析上更具优势。
综上所述,行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略,数量大可能会影响到数据的处理效率。列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域比较重要。一般来说一个OLAP类型的查询可能需要访问几百万或者几十亿行的数据,但是OLAP分析时只是获取少数的列,对于这种场景列式数据库只需要读取对应的列即可,行式数据库需要读取所有的数据列,因此这种场景更适合列式数据库,可以大大提高OLAP数据分析的效率。ClickHouse就是一款使用列式存储的数据库,数据按列进行组织,属于同一列的数据会被保存在一起,列与列之间也会由不同的文件分别保存,在对OLAP场景分析时,效率很高。
3. 数据压缩
为了使数据在传输上更小,处理起来更快,可以对数据进行压缩,ClickHouse默认使用LZ4算法压缩,数据总体压缩比可达8:1。
ClickHouse采用列式存储,列式存储相对于行式存储另一个优势就是对数据压缩的友好性。例如:有两个字符串“ABCDE”,“BCD”,现在对它们进行压缩:
压缩前:ABCDE_BCD
压缩后:ABCDE_(5,3)通过以上案例可以看到,压缩的本质是按照一定步长对数据进行匹配扫描,当发现重复部分的时候就进行编码转换。例如:(5,3)代表从下划线往前数5个字节,会匹配上3个字节长度的重复项,即:“BCD”。当然,真实的压缩算法比以上举例更复杂,但压缩的本质就是如此,数据中重复性项越多,则压缩率越高,压缩率越高,则数据体量越小,而数据体量越小,则数据在网络中的传输越快,对网络带宽和磁盘IO的压力也就越小。
列式存储中同一个列的数据由于它们拥有相同的数据类型和现实语义,可能具备重复项的可能性更高,更利于数据的压缩。所以ClickHouse在数据压缩上比例很大。
4. 向量化执行引擎
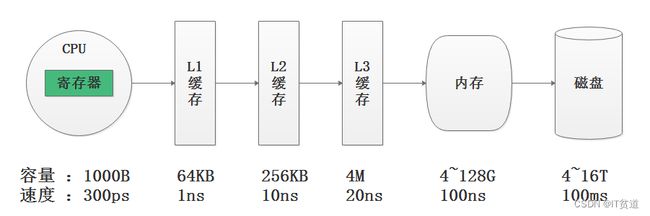
在计算机系统的体系结构中,存储系统是一种层次结构,典型服务器计算机的存储层次结构如上图,上图表述了CPU、CPU三级缓存、内存、磁盘数据容量与数据读取速度对比,我们可以看出存储媒介距离CPU越近,则访问数据的速度越快。
注意:缓存就是数据交换的缓冲区,缓存往往都是RAM(断电即掉的非永久储存),它们的作用就是帮助硬件更快地响应。CPU缓存的定义为CPU与内存之间的临时数据交换器,它的出现是为了解决CPU运行处理速度与内存读写速度不匹配的矛盾,CPU缓存一般直接跟CPU芯片集成或位于主板总线互连的独立芯片上,现阶段的CPU缓存一般直接集成在CPU上。CPU往往需要重复处理相同的数据、重复执行相同的指令,如果这部分数据、指令,CPU能在CPU缓存中找到,CPU就不需要从内存或硬盘中再读取数据、指令,从而减少了整机的响应时间。
由上图可知,从内存读取数据速度比磁盘读取数据速度要快1000倍,从CPU缓存中读取数据的速度比从内存中读取数据的速度最快要快100倍,从CPU寄存器中读取数据的速度为300ps(1000ps 皮秒 = 1ns),比CPU缓存要快3倍还多。从寄存器中访问数据的速度,是从内存访问数据速度的300倍,是从磁盘中访问数据速度的30万倍。
如果能从CPU寄存器中访问数据对程序的性能提升意义非凡,向量化执行就是在寄存器层面操作数据,为上层应用程序的性能带来了指数级的提升。
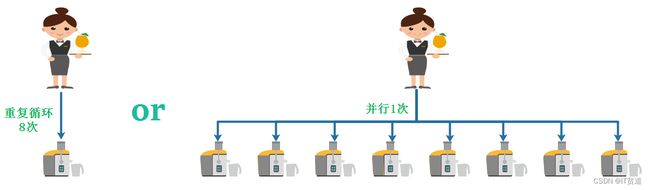
何为向量化执行?向量化执行,可以简单地看作一项消除程序中循环的优化。这里用一个形象的例子比喻。小胡经营了一家果汁店,虽然店里的鲜榨苹果汁深受大家喜爱,但客户总是抱怨制作果汁的速度太慢。小胡的店里只有一台榨汁机,每次他都会从篮子里拿出一个苹果,放到榨汁机内等待出汁。如果有8个客户,每个客户都点了一杯苹果汁,那么小胡需要重复循环8次上述的榨汁流程,才能榨出8杯苹果汁。如果制作一杯果汁需要5分钟,那么全部制作完毕则需要40分钟。为了提升果汁的制作速度,小胡想出了一个办法。他将榨汁机的数量从1台增加到了8台,这么一来,他就可以从篮子里一次性拿出8个苹果,分别放入8台榨汁机同时榨汁。此时,小胡只需要5分钟就能够制作出8杯苹果汁。为了制作n杯果汁,非向量化执行的方式是用1台榨汁机重复循环制作n次,而向量化执行的方式是用n台榨汁机只执行1次。
为了实现向量化执行,需要利用CPU的SIMD指令,SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据。现代计算机系统概念中,它是通过数据并行以提高性能的一种实现方式(其他的还有指令级并行和线程级并行),它的原理是在CPU寄存器层面实现数据的并行操作。
ClickHouse列式存储除了降低IO和存储的压力之外,还为向量化执行做好了铺垫,除了读取磁盘速度快之外,ClickHouse还利用SSE4.2指令集实现向量化执行,为处理数据提升很大效率。
5. 关系模型与标准SQL查询
相比HBase和Redis这类NoSQL数据库,ClickHouse使用关系模型描述数据并提供了传统数据库的概念(数据库、表、视图和函数等)。ClickHouse完全使用SQL作为查询语言(支持GROUP BY、ORDER BY、JOIN、IN等大部分标准SQL),ClickHouse提供了标准协议的SQL查询接口,可以与第三方分析可视化系统无缝集成对接。在SQL解析方面,ClickHouse是大小写敏感,SELECT a 和 SELECT A所代表的语义不同。
6. 多样化的表引擎
与MySQL类似,ClickHouse也将存储部分进行了抽象,把存储引擎作为一层独立的接口。ClickHouse拥有各种表引擎,每种表引擎决定不同的数据存储方式。其中每一种表引擎都有着各自的特点,用户可以根据实际业务场景的要求,选择合适的表引擎使用。将表引擎独立设计的好处是通过特定的表引擎支撑特定的场景,十分灵活,对于简单的场景,可直接使用简单的引擎降低成本,而复杂的场景也有合适的选择。
7. 多线程与分布式
向量化执行是通过数据级并行的方式提升了性能,多线程处理是通过线程级并行的方式实现了性能的提升。相比基于底层硬件实现的向量化执行SIMD,线程级并行通常由更高层次的软件层面控制,目前市面上的服务器都支持多核心多线程处理能力。由于SIMD不适合用于带有较多分支判断的场景,ClickHouse也大量使用了多线程技术以实现提速,以此和向量化执行形成互补。ClickHouse在数据存取方面,既支持分区(纵向扩展,利用多线程原理 ),也支持分片(横向扩展,利用分布式原理),可以说是将多线程和分布式的技术应用到了极致。
8. 多主架构
HDFS、Spark、HBase和Elasticsearch这类分布式系统,都采用了Master-Slave主从架构,由一个管控节点作为Leader统筹全局。而ClickHouse则采用Multi-Master多主架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。这种多主的架构有许多优势,例如对等的角色使系统架构变得更加简单,不用再区分主控节点、数据节点和计算节点,集群中的所有节点功能相同。所以它天然规避了单点故障的问题,非常适合用于多数据中心、异地多活的场景。
9. 交互式查询
Hive,SparkSQL,HBase等都支持海量数据的查询场景,都拥有分布式架构,都支持列存、数据分片、计算下推等特性。ClickHouse在设计上吸取了以上技术的优势,例如:Hive、SparkSQL无法保证90%以上的查询在秒级内响应,在大数据量复杂查询下需要至少分钟级的响应时间,而HBase可以对海量数据做到交互式查询,由于不支持标准SQL在对数据做OLAP聚合分析时显得捉襟见肘。ClickHouse吸取以上各个技术的优势,在复杂查询的场景下,它也能够做到极快响应,且无须对数据进行任何预处理加工。
10. 数据分片与分布式查询
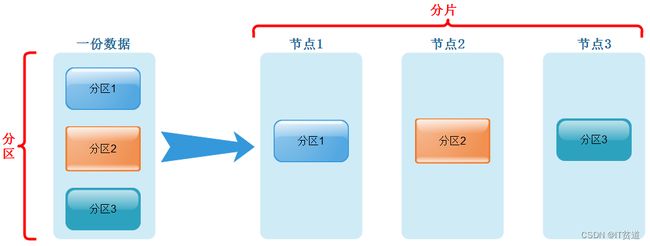
数据分片是将数据进行横向切分,这是一种在面对海量数据的场景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现。ClickHouse支持分片,而分片则依赖集群。每个集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节点。分片的数量上限取决于节点数量(1个分片只能对应1个服务节点)。
ClickHouse拥有高度自动化的分片功能。ClickHouse提供了本地表 (Local Table)与分布式表(Distributed Table)的概念。一张本地表等同于一份数据的分片。而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。
这种设计类似数据库的分库和分表,十分灵活。例如在业务系统上线的初期,数据体量并不高,此时数据表并不需要多个分片。所以使用单个节点的本地表(单个数据分片)即可满足业务需求,待到业务增长、数据量增大的时候,再通过新增数据分片的方式分流数据,并通过分布式表实现分布式查询。