socket套接字
Linux socket套接字编程
- 理解源IP地址和和目的IP地址
- 认识端口号
- 简单认识TCP协议
- 简单认识UDP协议
- 网络字节序
- socket编程接口
- sockaddr结构
- 基于UDP设计的网络聊天室
- TCP简易小程序
- 地址转换函数
-
- 关于inet_ntoa
理解源IP地址和和目的IP地址
在IP数据包头部中, 有两个IP地址, 分别叫做源IP地址, 和目的IP地址.
源IP地址:源IP地址指的是数据通信的发起方的IP地址。在数据包中,源IP地址用于标识数据的源头,即发送数据的设备或主机。
目的IP地址:目的IP地址指的是数据通信的接收方的IP地址。在数据包中,目的IP地址用于标识数据的目标,即接收数据的设备或主机。
想要理解这两个概念,我们就得弄懂IP地址和Mac地址的区别;
在网络中发送的数据包头中实际上包含着:源Max地址、源IP地址,目的Max地址和、目的IP地址;
那么为什么要包含两个地址呢?目的IP地址和Mac地址的作用分别是什么呢?
首先在网络传输中,我们给对方发送了消息,对方在接收到消息过后可能也想给我们发送消息,因此在向对方发送消息的时候,我们会将自己的IP地址和Max地址也发过去这无可厚非!而目的IP和目的Mac地址呢?当然是让数据包能够被正确的送达到目标主机,接下来我们具体谈谈目的ip和目的max地址是如何保证数据包准确的送到目标主机的:
举个例子:
在西游记里面,每一次唐僧到达一个国家过后,那里的国王都会问一句:“和尚,你从哪里来到哪里去”,唐僧都会回答:“贫僧从东土大唐而来,到西天取经去”,这句话里面就包含了唐僧的两个重要信息:1、唐僧从东土来;2、唐僧要到西天去;接着这个国王就会根据自己判断给出唐僧下一站到哪里去,于是唐僧就立马赶往了下一站:比如:车迟国国王说:“你要到西天去的话,就要从女儿国经过”,这句话也就告诉了唐僧,你的下一站要到女儿国去!
这其中唐僧就相当于我们的数据包,他自带两套地址:东土大唐、西天,这也就好比网络中数据包的源ip地址和目标ip地址;而当和尚到达车迟国,国王听说了它的目的地,便告诉了他下一站要到达的地址,这就相当于目标Mac地址,因为唐僧达到女儿国之后,还会问女儿国国王同样的问题,此时唐僧的下一站地址也就改变了,所以目的Mac地址是变化的
因此,从上面的例子我们可以总结出来:
目的IP的作用:目的IP是不变的,该IP地址用来进行路径选择!确定下一次数据包要达到的主机的Mac地址;
目的Mac地址:是变化的,用来决定下一次数据包要到达的主机!
认识端口号
在具体介绍端口号之前,我们先来谈谈网络通信的本质!
首先我们用户肯定是站在应用层进行网络通信的,可是我们是直接将我们的消息发送到网络中的吗?
换句话说,我们用户是直接与OS打交道的吗?显然不是,我们利用进程作为媒介来与OS进行交流的!显然网络通信也是这样!我们在应用层创建了一个进程,然后我们将自己想要发送的信息交给我们创建的发送进程,发送进程在通过OS的各种网络接口将消息发送到网络中去!然后作为接收方用户,也不可能直接去网线哪里取数据吧!接收方的用户也是通过一个接收进程来作为媒介来接收信息的,用户向接收进程要信息,接收进程通过调用OS的各种接口来获取信息!最终呈现给上层用户!
其实说白了,这不就是两个进程直接的收消息、发消息吗!这不就是两个进程之间的通信吗!两个独立的进程通过网络这个共享资源来进行通信,这与之前的管道、消息队列、共享内存等通信方式有什么区别?只不过现在通信的媒介变成了网络!因此我们可以得出结论:网络通信的本质就是进程间通信!
理解了这一层,接下来就自然很多了,既然都说了网络通信本质就是进程间通信,可是一个主机中有那么多个进程,OS在从网络中拿到了数据过后应该交给那个进程呢?OS是不是要标识一下当前获取到的网络数据应该交给那个进程?不可能明明是发给王者荣耀的信息,你交给我QQ吧!为此端口号这个概念就出来了,端口号的出现就是为了弥补OS不知道该将网络数据交给那个进程的问题!
在发送过来的数据包中不仅包含目的IP地址还有对应目标主机上的端口号!OS通过解析这个数据包中的端口号,来决定将该数据交给那个进程!
接着我们再来理解端口号,就好理解了!
端口号是传输层的协议的内容:
- 端口号是一个2字节的整数;
- 端口号用来标识一个进程,告诉OS当前网络数据应该交给那个进程;
- 因此,IP地址+端口能够唯一确定网络中某一台主机上的某一个进程;
- 一个端口号只能绑定一个进程,一个进程可以绑定多个端口号(分别站在端口号、进程的角度理解);
端口号和进程PID
既然需要OS标识一个进程,那么为什么不用PID呢?省时又省力;
确实,PID确实可以标识一个进程,可是PID是由OS自主分配的,也就是说同一个进程的PID是有可能变化的!比如:qq第一次启动是一个PID,第二次启动可能又是另一个PID了;完全不可靠!当我想要给另一个进程发数据的时候,我还得提前打电话问好它的PID这不麻烦!而端口号不会,只要你给这个进程绑定了端口号,那么无论这个进程什么时候启动,他对应的端口号依旧是绑定的那样不会改变!同时,如果使用PID的话,那么网络模块和进程模块的耦合度就会增加,要是那一天委员会想要更新一下PID,那么网络模块是不是也要受到影响!而采用独立于PID之外的端口号的概念,就大大的降低了进程模块和网络模块的耦合度!
简单认识TCP协议
本篇文章先对TCP协议有一个直观的认识;后面我们详谈:
- 传输层协议;
- 面向连接;
- 可靠传输;(当数据包丢失过后,会自动重新发送)
- 面向字节流;
简单认识UDP协议
此处我们也是对UDP(User Datagram Protocol 用户数据报协议)有一个直观的认识; 后面再详细讨论
- 传输层协议;
- 无连接;
- 不可靠传输;
- 面向数据报;
简单总结:
- TCP/UDP协议都是传输层协议;
- 使用TCP协议进行通信时,需要先建立连接,然后再进行通信,而udp不用;
- TCP协议实际就像铲沙一样,我们想从沙堆铲多少就铲多少,对应TCP协议就是TCP协议想从发送缓冲区拿多少数据进行发送就发送,这也就可能会导致对方接收缓冲区会有一些不完整的数据!而UDP协议就更像搬砖一样,你只能从砖场整块整块的搬砖,不可能搬半截砖,对应UDP协议从发送缓冲区拿数据时,只能将数据当作一块一块的来拿并进行发送,如果不足一块,那么它是不会进行拿取的;这也就是TCP说的面向字节流,UDP面向数据报!
网络字节序
我们知道当今世界上是没有同一机器的大小端问题的!也就是说世界上有大端机器也有小端机器;
那么在使用网络传输是数据应该按照大端传送还是小端传送呢?
要是没有明确规定的话,那么我小段机传到网络上的就是小端存储的数据,要是被小端接收到了还好,可是要是对方是个大端机呢?大端机就会用大端序列来解释小端存储的数据,这部完全反了吗!同理大端机器发送也是一样!
为此:TCP/IP协议规定网络传送数据时,统一采用大端发送!
这也就是说,小端机器发送数据时,需要将其转化为大端数据在进行发送;
同理小端机器在接收到数据时也需要先转换为小端数据才能进行处理!
为了使网络程序具有可移植性,使同一份代码既能在大端机器上运行,也能在小端机器上运行!可以调用以下库函数进行网络序和主机序之间的转换:
#includeh:host主机
n:net网络
s:16位短整数
l:32位长整数
htonls:将32位长整数从主机序列转换为网络序;后面依次类推
- 如果主机本来就是大端序列,那么这些函数将什么也不会做;如果是小端机器,那么会转换为大端序列;
socket编程接口
// 创建 socket 文件描述符 (TCP/UDP, 客户端 + 服务器)
//创建UDP/TCP套接字,服务端和客服端都需要使用这个函数
int socket(int domain, int type, int protocol);
// 绑定端口号 (TCP/UDP, 服务器)
int bind(int socket, const struct sockaddr *address,
socklen_t address_len);
// 开始监听socket (TCP, 服务器)
int listen(int socket, int backlog);
// 接收请求 (TCP, 服务器)
int accept(int socket, struct sockaddr* address,
socklen_t* address_len);
// 建立连接 (TCP, 客户端)
int connect(int sockfd, const struct sockaddr *addr,
socklen_t addrlen);
//发送数据(UDP,, 客户端 + 服务器)
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr,socklen_t addrlen);
//接收数据(UDP,, 客户端 + 服务器)
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);
//接收数据(TCP,, 客户端 + 服务器)
ssize_t read(int fd, void *buf, size_t count);
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
//发送数据(UDP,, 客户端 + 服务器)
ssize_t write(int fd, const void *buf, size_t count);
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
sockaddr结构
socket套接字既可以进行网络通信,也可以进行本地进程间的通信;
如果我们要使用网络通信的话,那么我们就需要使用struct sockaddr_in结构体,如果我们向进行本地通信的话,那么我们就需要使用struct sockaddr_un,那么这也就意味着针对这两个不同的结构体需要编写两套不同的接口,对于使用者使用起来不仅是一种成本,对于编写sock套接字编程的开发人员来说也是一种成本,为此大佬们采用了一种比较抽象的作法,大佬们在编写sock套接字接口时重新提出里一种新的struct sockaddr结构,然后针对这个新结构编写一套既能进行网络通信的接口,又能进行本地通信的接口,大佬们是如和实现的呢?
大佬们是这样想的,如果我们要使用网络通信,那么需要将sockaddr_in结构体指针转换为sockaddr结构体指针,同理当我们要使用本地通信时,我们上层给套接字接口传的也必须是sockaddr类型的指针,也就是说sockadd_un结构体指针也要转换成sockadd结构体指针,那么在套接字接口的内部它是如何区别sockaddr指针到底是指向sockadd_in结构体的还是sockadd_un结构体的呢?这就依赖于sockadd、sockadd_in、sockadd_un结构体的实现了,这三个结构体在头部都有一个公共字段,然后的话,sockadd指针通过判断这个头部字段的属性来判断自己实际指向的到底是sockadd_in还是sockadd_un结构体,这样自己就能在针对性的将sockadd_in结构体指针强转为原类型指针了,这样就能针对不同通信类型进行编码了!这样也就做到了网络通信和本地通信共用同一个套接字接口了:

上面的作法不就是C++中的多态吗?
- IPv4和IPv6的地址格式定义在netinet/in.h中,IPv4地址用sockaddr_in结构体表示,包括16位地址类型, 16位端口号和32位IP地址.
- IPv4、IPv6地址类型分别定义为常数AF_INET、AF_INET6. 这样,只要取得某种sockaddr结构体的首地址,不需要知道具体是哪种类型的sockaddr结构体,就可以根据地址类型字段确定结构体中的内容.
- socket API可以都用struct sockaddr *类型表示, 在使用的时候需要强制转化成sockaddr_in; 这样的好处是程序的通用性, 可以接收IPv4, IPv6, 以及UNIX Domain Socket各种类型的sockaddr结构体指针做为参数;
//sockadd结构体
struct sockaddr
{
__SOCKADDR_COMMON (sa_); /* Common data: address family and length. */
char sa_data[14]; /* Address data. */
};
//sockaddr_in结构体
struct sockaddr_in
{
__SOCKADDR_COMMON(sin_);
in_port_t sin_port; /* Port number. */
struct in_addr sin_addr; /* Internet address. */
/* Pad to size of `struct sockaddr'. */
unsigned char sin_zero[sizeof(struct sockaddr) -
__SOCKADDR_COMMON_SIZE -
sizeof(in_port_t) -
sizeof(struct in_addr)];
};
//sockaddr_un结构体
struct sockaddr_un
{
__SOCKADDR_COMMON (sun_);
char sun_path[108]; /* Path name. */
};
其中__SOCKADDR_COMMN就是这三个结构体的公共头部字段,本质就是一个宏替换类型为unsigned short int;
但是我们真正进行网络编程的时候是基于IPV4进行的,使用的数据结构自然是sockaddr_in结构体,其中sockaddr_in结构体中包含:网络类型、端口号、ip地址等字段
//这也是sockadd_in结构体里面的ip地址的类型,本质上就是一个32为的整数
struct in_addr
{
in_addr_t s_addr;
};
基于UDP设计的网络聊天室
UDP套接字编写流程:
服务端:
1、创建套接字
2、给套接字绑定端口号和IP地址(云服务器一般不能由开发人员来绑定指定IP地址,该字段必须设为INADDR_ANY)
3、通过套接字使用recvfrom接收数据,sendto发送数据
客户端:
1、创建套接字
2、给套接字绑定ip地址和端口号(一般情况下,客户端的ip地址和端口号不需要由我们开发人员来绑定,因为有可能我们绑定的端口号和该主机下的其它客户端的端口号发生冲突了,要是其它客户端先运行起来,那么我们的客户端就无法启动,一启动就挂掉,对于用户来说体验非常不好,因此客户但的ip地址和端口号的bind工作一般都是交给OS来自主分配和绑定!OS会在第一次sendto数据的时候进行绑定!)
3、recvfrom接收数据、sendto发送数据
具体源码可以参考以下地址:
UDP设计的网络聊天室
该聊天室服务端是基于Linux环境下编写的,而客户端基于Linux环境和Win环境都有编写;
TCP简易小程序
使用TCP通信时,客户端必须先与服务端建立连接!
TCP套接字编写流程:
服务端:
1、创建套接字(socket)
2、给套接字绑定端口号和IP地址(云服务器一般不能由开发人员来绑定指定IP地址,该字段必须设为INADDR_ANY)(bind)
3、通过上述创建的套接字将自己设置为监听状态(方便接收来自客户端的连接请求)!(listen)
4、通过上面的监听套接字接收来自客户端的连接请求,并且会得到一个新的套接字,该套接字才是用来进行客户端与服务端进行网络通信的套接字;(accept)
5、与客户端进行网络通信,read/recv接收数据、write/send发送数据
客户端:
1、创建套接字
2、给套接字绑定ip地址和端口号(一般情况下,客户端的ip地址和端口号不需要由我们开发人员来绑定,因为有可能我们绑定的端口号和该主机下的其它客户端的端口号发生冲突了,要是其它客户端先运行起来,那么我们的客户端就无法启动,一启动就挂掉,对于用户来说体验非常不好,因此客户但的ip地址和端口号的bind工作一般都是交给OS来自主分配和绑定!OS会在第一次sendto数据的时候进行绑定!)
3、发送连接请求(connect)
4、与服务端进行网络通信,read/recv接收数据、write/send发送数据
TCP简易小程序
地址转换函数
本节只介绍基于IPv4的socket网络编程,sockaddr_in中的成员struct in_addr sin_addr表示32位 的IP 地址,但是我们通常用点分十进制的字符串表示IP 地址,以下函数可以在字符串表示 和in_addr表示之间转换;
字符串ip转网络序整数的函数:

网络序整数转字符串ip的函数:

其中inet_pton和inet_ntop不仅可以转换IPv4的in_addr,还可以转换IPv6的in6_addr,因此函数接口是void*addrptr
关于inet_ntoa
inet_ntoa函数的返回值是一个char类型的指针,这个char不可能指向栈区吧,要是指向栈区,外部在使用这个转换出来的ip地址时不就是野指针了吗,因此该指针需要具备较长的生命周期!因此该指针只能是指向堆区或者静态区:如果是指向堆区那么是不是需要我们手动释放?
如果是指向静态区,那么在第二次调用该函数时,是不是会造成数据覆盖呢?

man手册上说, inet_ntoa函数, 是把这个返回结果放到了静态存储区. 这个时候不需要我们手动进行释放;
那么很明显啊,当我们多次调用inet_ntoa函数时始终会将上一次的ip地址给覆盖掉啊:
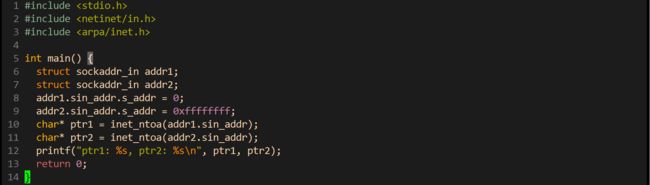
运行结果:
![]()
同时既然是静态指针,那么当多线程并发访问该函数时,是会造成线程安全问题的,inet_ntoa函数是个不可重入函数!为此官方推荐使用inet_ntop函数来进行网络序整数转换为字符串ip!
该函数使用的缓冲区是由使用者提供的!可以规避线程安全的问题!