MongoDB MapReduce 聚合操作
MongoDB的聚合操作主要是对数据的批量处理。一般都是将记录按条件分组之后进行一系列求最大值,最小值,平均值的简单操作,也可以对记录进行数据统计,数据挖掘的复杂操作。聚合操作的输入是集中的文档,输出可以是一个文档也可以是多个文档。
MongoDB 提供了三种强大的聚合操作:
- 单目的聚合操作(Single Purpose Aggregation Operation)
- 聚合管道(Aggregation Pipeline)
- MapReduce 编程模型
Pipeline查询速度快于MapReduce,但是MapReduce的强大之处在于能够在多台Server上并行执行复杂的聚合逻辑。MongoDB不允许Pipeline的单个聚合操作占用过多的系统内存,如果一个聚合操作消耗20%以上的内存,那么MongoDB直接停止操作,并向客户端输出错误消息。
本篇主要讲解 MapReduce 编程模型。MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
一、MapReduce 命令
MapReduce 的基本语法如下:
>db.collection.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number,
finalize: ,
scope: ,
jsMode: ,
verbose:
}
)
使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value), 遍历 collection 中所有的记录, 将 key 与 value 传递给 Reduce 函数进行处理。
参数说明:
- map:是JavaScript 函数,负责将每一个输入文档转换为零或多个文档,通过key进行分组,生成键值对序列,作为 reduce 函数参数
- reduce:是JavaScript 函数,对map操作的输出做合并的化简的操作(将key-values变成key-value,也就是把values数组变成一个单一的值value)
- out:统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
- query: 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
- sort: 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
- limit: 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
- finalize:可以对reduce输出结果再一次修改,跟group的finalize一样,不过MapReduce没有group的4MB文档的输出限制
- scope:向map、reduce、finalize导入外部变量
- verbose:是否包括结果信息中的时间信息,默认为fasle
关于MapReduce的工作流程如下:
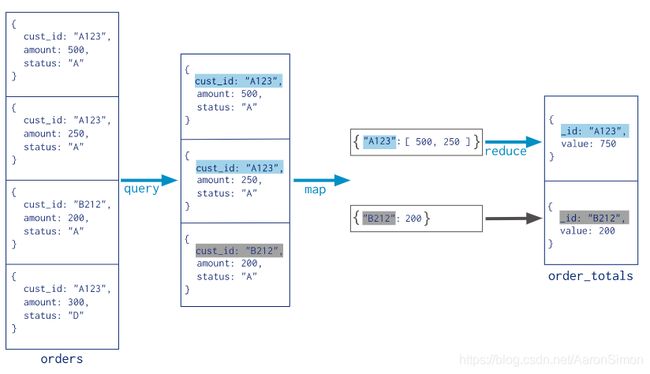
在集合 orders 中查找 status:“A” 的数据,并根据 cust_id 来分组,并计算 amount 的总和。
二、使用示例
对以下结构的文档进行统计。统计每个用户的文章数量。
>db.col.find()
{
"_id" : ObjectId("5c09dfcde354b306e46af7f3"),
"bookname" : "Java 8 实战",
"author" : "simon",
"status" : "active"
},
{
"_id" : ObjectId("5c09dfdee354b306e46af7f4"),
"bookname" : "MongoDB权威指南",
"author" : "simon",
"status" : "active"
},
{
"_id" : ObjectId("5c09dfffe354b306e46af7f5"),
"bookname" : "MyBatis 实战",
"author" : "simon",
"status" : "disabled"
},
{
"_id" : ObjectId("5c09e016e354b306e46af7f6"),
"bookname" : "MyBatis 从入门到具精通",
"author" : "Aaron",
"status" : "disabled"
},
{
"_id" : ObjectId("5c09e02ce354b306e46af7f7"),
"bookname" : "Spring Boot 2.0",
"author" : "Aaron",
"status" : "active"
},
{
"_id" : ObjectId("5c09e037e354b306e46af7f8"),
"bookname" : "Spring Cloud",
"author" : "Aaron",
"status" : "active"
},
{
"_id" : ObjectId("5c09e038e354b306e46af7f9"),
"bookname" : "Spring Cloud",
"author" : "Aaron",
"status" : "active"
}
将在 col 集合中使用 mapReduce 函数来选取已发布的文章(status:“active”),并通过author分组,计算每个用户的文章数
>db.col.mapReduce(
function() { emit(this.author,1); },
function(key, values) {return Array.sum(values)},
{
query:{status:"active"},
out:"total"
}
)
{
"result" : "total",
"timeMillis" : 422.0,
"counts" : {
"input" : 5,
"emit" : 5,
"reduce" : 2,
"output" : 2
},
"ok" : 1.0,
"_o" : {
"result" : "total",
"timeMillis" : 422,
"counts" : {
"input" : 5,
"emit" : 5,
"reduce" : 2,
"output" : 2
},
"ok" : 1.0
},
"_keys" : [
"result",
"timeMillis",
"counts",
"ok"
],
"_db" : {
"_mongo" : {
"slaveOk" : true,
"host" : "192.168.10.58:27017",
"defaultDB" : "test",
"_readMode" : "commands",
"_writeMode" : "commands"
},
"_name" : "ibase_dev"
},
"_coll" : {
"_mongo" : {
"slaveOk" : true,
"host" : "192.168.10.58:27017",
"defaultDB" : "test",
"_readMode" : "commands",
"_writeMode" : "commands"
},
"_db" : {
"_mongo" : {
"slaveOk" : true,
"host" : "192.168.10.58:27017",
"defaultDB" : "test",
"_readMode" : "commands",
"_writeMode" : "commands"
},
"_name" : "ibase_dev"
},
"_shortName" : "total",
"_fullName" : "ibase_dev.total"
}
}
从结果中可以看出,一共有5个文档服务{status:'active'}的文档,在map函数中生成了5个键值对文档,最后使用reduce函数将相同的键值分为 2 组。
具体参数说明:
- result:储存结果的collection的名字,这是个临时集合,MapReduce的连接关闭后自动就被删除了。
- timeMillis:执行花费的时间,毫秒为单位
- input:满足条件被发送到map函数的文档个数
- emit:在map函数中emit被调用的次数,也就是所有集合中的数据总量
- ouput:结果集合中的文档个数(count对调试非常有帮助),
out: { inline: 1 }不会创建集合,结果在内存中 - ok:是否成功,成功为1
- err:如果失败,这里可以有失败原因,不过从经验上来看,原因比较模糊,作用不大
查看执行结果:
>db.total.find()
{
"_id" : "Aaron",
"value" : 3.0
},
{
"_id" : "simon",
"value" : 2.0
}