SystemVerilog 第2章:数据类型
在 Verilog中,初学者经常分不清reg和wire两者的区别。应该使用它们中哪一个来驱动端口?连接不同模块时又该如何做? Systemverilog对经典的reg数据类型进行了改进,使得它除了作为一个变量以外,还可以被连续赋值、门单元和模块所驱动。为了与寄存器类型相区别,这种改进的数据类型被称为1ogic。任何使用线网的地方均可以使用logic,但要求logic不能有多个结构性的驱动,例如在对双向总线建模的时候。此时,需要使用线网类型,例如wire, System Verilog会对多个数据来源进行解析以后确定最终值。
module logic_data_type(input logic rst_h);
parameter CYCLE=20;
logic clk,rst_i;
initial
begin
clk=0;
forever #(CYCLE/2) clk=~clk;
end
assign rst_i=rst_h;
endmodule由于logic类型只能有一个驱动,所以你可以使用它来查找网单中的漏洞。把你所有的信号都声明为logic而不是reg或wire,如果存在多个驱动,那么编译时就会出现错误。当然,有些信号你本来就希望它有多个驱动,例如双向总线,这些信号就需要被定义成线网类型,例如wire 。
2.1.2双状态数据类型
相比四状态数据类型, System Verilog引入的双状态数据类型有利于提高仿真器的性能并减少内存的使用量。最简单的双状态数据类型是bit,它是无符号的。另外4种带符号的双状态数据类型是byte, shorting,int和longint,如下所示:
带符号的数据类型
bit b; //双状态,单比特
bit[31:0] b32; //双状态,32比特无符号整数
int unsigned uii ; /双状态,32比特无符号整数
int i; /双状态,32比特有符号整数
byte b8; //双状态,8比特有符号整数
shorting s; //双状态,16比特有符号整数
longint p ; //双状态,64比特有符号整数
integer i4; //4状态,32比特有符号整数
time t ; //4状态,64比特无符号整数
real r ; //双状态,双精度浮点数 你也许会乐于使用诸如byte的数据类型来替代类似 logic[7:0]的声明,以使得程序更加简洁。但需要注意的是,这些新的数据类型都是带符号的,所以byte变量的最大值只有127,而不是255(它的范围是-128~127)。可以使用 byte unsigηed,但这其实比使用bit[7:0]还要麻烦。在进行随机化时,带符号变量可能会造成意想不到的结果。
在把双状态变量连接到被测设计,尤其是被测设计的输出时务必要小心。如果被测设计试图产生Ⅹ或Z,这些值会被转换成双状态值,而测试代码可能永远也察觉不了。这些值被转换成了0还是1并不必要,重要的是要随时检查未知值的传播。使用($isunknown)操作符,可以在表达式的任意位出现X或Z时返回1。
例2.3对四状态值的检查
if ($isunknown(iport)==l)
display ("@%0t: 4-state value detected on iport %b",$time, iport);使用格式符%0t和参数 $time可以打印出当前的仿真时间,打印的格式在$timeformat()子程序中指定。
2.2定宽数组
相比于 Verilog1995中的一维定宽数组, System verilog提供了更加多样的数组类型,功能上也大大增强。
2.2.1定宽数组的声明和初始化
Verilog要求在声明中必须给出数组的上下界。因为几乎所有数组都使用0作为索引下界,所以 System Verilog允许只给出数组宽度的便捷声明方式,跟C语言类似。
例2.4定宽数组的声明
int lohil15] ; / /16个整数[0]..[15
int c_style[ 16] ; //16个整数[0]...15可以通过在变量名后面指定维度的方式来创建多维定宽数组。例25创建了几个二维的整数数组,大小都是8行4列,最后一个元素的值被设置为1。多维数组在 verilog2001中已经引人,但这种紧凑型声明方式却是新的。
例2.5声明并使用多维数组
int array2[0:7][0:3];//完整的声明
int array3 [8[4i/紧凑的声明
aray2[73]=1;/设置最后一个元素 如果你的代码试图从一个越界的地址中读取数据,那么 System Verilog将返回数组元素类型的缺省值。也就是说对于一个元素为四状态类型的数组,例如logic,返回的是X,而对于双状态类型例如int或bit,则返回0。这适用于所有数组类型,包括定宽数组、动态数组、关联数组和队列,也同时适用于地址中含有X或Z的情况。线网在没有驱动的时候输出是Z。
很多 System Verilog仿真器在存放数组元素时使用32比特的字边界,所以byte,shortint和int都是存放在一个字中,而 longint则存放到两个字中。如例2.6所示,在非合并数组中,字的低位用来存放数据,高位则不使用。
仿真器通常使用两个或两个以上连续的字来存放1ogic和 integer等四状态类型,这会比仔放双状态变量多占用一倍的空间。
2.2.2常量数组
例2.7示范了如何使用常量数组,即一个单引号加大括号来初始化数组(注意这里的单引号并不同于编译器指引或宏定义中的单引号)。你可以一次性地为数组的部分或所有元素赋值。在大括号前标上重复次数可以对多个元素重复赋值,还可以为那些没有显式赋值的元素指定一个缺省值。
例2.7初始化一个数组
int ascend [4]='{0,1,2, 3}; //对4个元素进行初始化
int descend [5];
descend='{4,3,2,1,0}; //为5个元素赋值
descend[0:2]='{5,6,7}; //为前3个元素赋值
ascend='4{9}; //四个值全部为8
descend ='{9,8, default: 1}; //(9,8,1,1,12.2.3基本的数组操作—for和foreach
操作数组的最常见的方式是使用for或 foreach循环。在例2.8中, i 被声明为for循环内的局部变量。 Systemverilog的$size函数返回数组的宽度。在 foreach循环中,只需要指定数组名并在其后面的方括号中给出索引变量, System verilog便会自动遍历数组中的元素。索引变量将自动声明,并只在循环内有效。
initial
begin
bit[31:0]src[5],dst[5];
for (int i=0:i<$size(src); i++)
src[i]=i;
foreach (dst[j])
dst[j]=src[j] *2; //dst的值是src的两倍
end 注意在例2.9中,对多维数组使用 foreach的语法可能会与你设想的有所不同。使用时并不是像[i][j]这样把每个下标分别列在不同的方括号里,而是用逗号隔开后放在同一个方括号里,像[i,j]。
例2.9 初始化并遍历多维数组
int md[2][3]='{'{0,1,2},'{3,4,5}};
initial
begin
$display("Initial value: ");
foreach(md[i,j]) //这是正确的语法格式
$display("md[%0d][%0d]=%0d",i,j,md[i][j]);
$display("New value :");
md='{'{9,8,7},'{3{32'd5}}};
//对最后三个元素重复赋值5
foreach(md[i,j])
$display("md[%0d][%0d]=%0d",i,j,md[i][j]);
end 例29的输出结果如例2.10所示。例2.10多维数组元素值的打印输出结果。
如果你不需要遍历数组中的所有维度,可以在 foreach循环里忽略掉它们。例2.11把一个二维数组打印成一个方形的阵列。它在外层循环中遍历第一个维度,然后在内层循环中遍历第二个维度。
例2.11打印一个多维数组
initial
begin
byte twoD[4][6];
foreach(twoD[i,j])
twoD[i][j] =i *10 +j;
foreach(twoD[i]) //遍历第一个维度
begin
$write("%2d:",i);
foreach(twoD[,j]) //遍历第二个维度
$write("%3d",twoD[i][j]);
$display;
end
end
最后要补充的是, foreach循环会遍历原始声明中的数组范围。数组f[5]等同于f[0:4],而 foreach(f[i])等同于for(int i=0;i<=4;i++)。对于数组rev[6:2]来说,foreach(rev[i])语句等同于for(int i =6;i>=2;i--)。
2.2.4基本的数组操作一复制和比较
你可以在不使用循环的情况下对数组进行聚合比较和复制(聚合操作适用于整个数组而不是单个元素),其中比较只限于等于比较或不等于比较。例2.13列出了几个比较的例子。操作符? : 是一个袖珍型的主 if 语句,在例 2.13 中用来对两个字符串进行选择。例子最后的比较语句使用了数组的一部分,src[1:4],它实际上产生了一个有四个元素的临时数组。
例2.13数组的复制和比较操作
initial
begin
bit [31:0] src[5]='{0,1,2,3,4};
bit [31:0] dst[5]='{5,4,3,2,1};
//两个数的聚合比较
if (src==dst)
$display("src==dst");
else
$display("src!=dst");
//把src所有元素赋值给dst
dst=src;
//只改变一个元素的值
src[0]=5;
//所有元素的值是否相等(否!)
$display("src %s dst",(src==dst)? "==":"!=");
$display("src[1:4] %s dst[1:4]",(src[1:4]==dst[1:4])?"==":"!=");
end对数组的算术运算不能使用聚合操作,而应该使用循环,例如加法等运算。对于逻辑运算,例如异或等运算,只能使用循环或2.2.6节中描述的合并数组。
2.2.5同时使用位下标和数组下标
在 verilog1995中一个很不方便的地方就是数组下标和位下标不能同时使用。 Verilog2001对定宽数组取消了这个限制。例2.14打印出数组的第一个元素(二进制101)、它的最低位(1)以及紧接的高两位(二进制10)。
例2.14同时使用数组下标和位下标
initial
begin
bit[31:0] src[5]='{5{5}};
$displayb(src[0],"\n",src[0][0],"\n",src[0][2:1],"\n");
end2.2.6合并数组
对某些数据类型,你可能希望既可以把它作为一个整体来访问,也可以把它分解成更小的单元。例如,有一个32比特的寄存器,有时候希望把它看成四个8比特的数据,有时候则希望把它看成单个的无符号数据。 System Verilog的合并数组就可以实现这个功能,它既可以用作数组,也可以当成单独的数据。与非合并数组不同的是,它的存放方式是连续的比特集合,中间没有任何闲置的空间。
2.2.7合并数组的例子
声明合并数组时,合并的位和数组大小作为数据类型的一部分必须在变量名前面指定。数组大小定义的格式必须是[msb:lsb],而不是[size]。例2.15中的变量 bytes是一个有4个字节的合并数组,使用单独的32比特的字来存放,如图2.2所示。
例2.15合并数组的声明和用法(待验证)
bit [3:0][7:0] bbb; //4个字节组装成32比特数
bbb=32'h1234_4567; //bytes = 32'hCafE_Dada;
initial
begin
$displayh(bbb, //显示所有的32比特
bbb[3], //显示最高字节 "CA"
bbb[3][7]); //最高比特位"1"
end 合并和非合并数组可以混合使用。你可能会使用数组来表示存储单元,这些单元可以按比特、字节或长字的方式进行存取。在例2.16中, array是一个具有3个合并元素的非合并数组。
例2.16合并/非合并混合数组的声明
bit [3:0] [7:0] barry[3]; //合并:3*32比特
bit [31:0] lw=32'h0123_4567; //字
bit [7:0][3:0] nibbles; //合并数组
barry[0]=lw;
barry[0][3]=8'h01;
barry[0][1][6]=1'b1;
nibbles=barry[0]; //赋值合并数组的元素值 例2.15中的变量 bytes是一个具有4个字节的合并数组,以单字形式存放。 barray则是一个具有3个类似 bytes元素的数组,其存放形式如图2.3所示。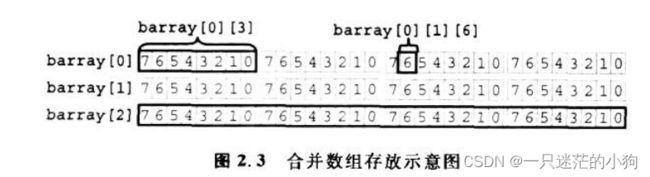
使用一个下标,可以得到一个字的数据barray[2]。使用两个下标,可以得到一个字节的数据 barray[0][3]。使用三个下标,可以访问到单个比特位 barray[0][1][6]。注意数组声明中在变量名后面指定了数组的大小, barray[3],这个维度是非合并的.所以在使用该数组时至少要有一个下标。
例2.16中的最后一行在两个合并数组间实现复制。由于操作是以比特为单位进行的,所以即使数组维度不同也可以进行复制。
2.2.8合并数组和非合并数组的选择
究竟应该选择合并数组还是非合并数组呢?当你需要和标量进行相互转换时,使用合并数组会非常方便。例如,你可能需要以字节或字为单位对存储单元进行操作。图2.3中所示的 barray可以满足这一要求。任何数组类型都可以合并,包括动态数组、队列和关联数组,2.3~2.5节中会有进一步的介绍。
如果你需要等待数组中的变化,则必须使用合并数组。当测试平台需要通过存储器数据的变化来唤醒时,你会想到使用@操作符。但这个操作符只能用于标量或者合并数组。在例2.16中,你可以把lw和 barray[0]用作敏感信号,但却不能用整个的 barray数组,除非把它扩展成:@( barray[0] or barray[1] or barray[2])。
2.3动态数组
前面介绍的基本的 verilog数组类型都是定宽数组,其宽度在编译时就确定了。但如果直到程序运行之前都还不知道数组的宽度呢?例如,你可能想在仿真开始的时候生成一批事务,事务的总量是随机的。如果把这些事务存放到一个定宽的数组里,那这个数组的宽度需要大到可以容纳最大的事务量,但实际的事务量可能会远远小于最大值,这就造成了存储空间的浪费。 System verilog提供了动态数组类型,可以在仿真时分配空间或调整宽度,这样在仿真中就可以使用最小的存储量。
动态数组在声明时使用空的下标[ ]。这意味着数组的宽度不在编译时给出,而在程序运行时再指定。数组在最开始时是空的,所以你必须调用new[] 操作符来分配空间,同时在方括号中传递数组宽度。可以把数组名传给new[ ]构造符,并把已有数组的值复制到新数组里,如例2.17所示。
例2.17使用动态数组
int dyn[],d2[]; //声明动态数组
initial
begin
dyn=new[5]; //A: 分配5个元素
foreach(dyn[j]) //B: 对元素进行初始化
dyn[j]=j;
d2=dyn; //C: 赋值一个动态数组
d2[0]=5; //D: 自改赋值值
$display(dyn[0],d2[0]); //E: 显示数值(0和5)
dyn=new[20] (dyn); //F: 分配20个整数值并进行复制
dyn=new[100]; //G: 分配100个新的整数值
dyn.delete(); //H: 删除所有元素,旧值不复存在
end 在例2.17中,A行调用new[5]分配了5个元素,动态数组dyn于是有了5个整型元素。B行把数组的索引值赋给相应的元素。C行分配了另一个数组并把dyn数组的元素值复制进去。D行和E行显示了数组dyn和d2是相互独立的。E行首先分配了20个新元素并把原来的dyn数组复制给开始的5个元素,然后释放dyn数组原有的5个元素所占用的空间,所以最终dyn指向了一个具有20个元素的数组。例2.17最后调用new[ ]分配了100个元素,但并不复制原有的值,原有的20个元素随即被释放。最后,H行删除了dyn数组。
系统函数 $size的返回值是数组的宽度。动态数组有一些内建的子程序(rourtines),例如 delete和size。如果你想声明一个常数数组但又不想统计元素的个数,可以使用动态数组并使用常量数组进行赋值。在例2.18中声明的mask数组具有9个8比特元素, System Verilog会自动统计元素的个数,这比声明一个定宽数组然后不小心把宽度错指为8要好。
例2.18使用动态数组来保存元素数量不定的列表
bit [7:0] mask[]='{8'b0000_0000,8'b0000_0001,
8'b0000_0011,8'b0000_0111,
8'b0000_1111,8'b0001_1111,
8'b0011_1111,8'b0111_1111
}只要基本数据类型相同,例如都是int,定宽数组和动态数组之间就可以相互赋值。在元素数目相同的情况下,可以把动态数组的值复制到定宽数组。当你把一个定宽数组复制给一个动态数组时, System verilog会调用构造函数new[]来分配空间并复制数值。
2.4队列
System Verilog引进了一种新的数据类型—队列,它结合了链表和数组的优点。队列与链表相似,可以在一个队列中的任何地方增加或删除元素,这类操作在性能上的损失比动态数组小得多,因为动态数组需要分配新的数组并复制所有元素的值。队列与数组相似,可以通过索引实现对任一元素的访问,而不需要像链表那样去遍历目标元素之前的所有元素。
队列的声明是使用带有美元符号的下标:[$]。队列元素的编号从0到$。例2.19示范了如何使用方法( method)在队列中增加和删除元素。注意队列的常量( literal)只有大括号而没有数组常量中开头的单引号。
System verilog的队列类似于标准模板库( standard template library)中的双端队列。你通过增加元素来创建队列, System verilog会分配额外的空间以便你能够快速插入新元素。当元素增加到超过原有空间的容量时, System verilog会自动分配更多的空间。其结果是,你可以扩大或缩小队列,但不用像动态数组那样在性能上付出很大代价, Systemerlg会随时记录闲置的空间。注意不要对队列使用构造函数new[ ]。
例2.19队列的操作
int j=1;
int q2[$]={3,4}; //队列的常量不需要使用“ ‘ ”
int q[$]={0,2,5};//{0,2,5}
initial
begin
q.insert(1,j); //{0,1,2,5}在2之前插入1
q.insert(3,q2); //{0,1,2,3,4,5}在q中插入一个队列
q.delete(1);//删除第1个元素
//下面的操作执行速度很快
q.push_front(6);//{6,0,2,3,4,5}在队列前面插入
j=q.pop_back;//{6,0,2,3,4} j=5
q.push_back(8);//{6,0,2,3,4,8} 在队列末尾插入
j=q.pop_front; //{0,2,3,4,8} j=6
foreach (q[i])
$display(q[i]); //打印整个队列
q.delete();
end 并不是所有的systemverilog仿真器都支持使用insert()对队列插入新值。
可以使用字下标串联来替代方法,如果把$放在一个范围表达式的左边,那么$将代表最小值,例如[$:2]就代表[0:2]。如果$放在表达式的右边,则代表最大值,如例2.20中初始化块的第一行里的[1:$]就表示[1:2]。
例2.20队列操作
initial
begin
q={q[0],j,q[1:$]}; //{0,1,2,5}在2之前插入1
foreach (q[i])
$display(q[i]);
q={q[0:2],q2,q[3:$]}; //{0,1,2,3,4,5}在q中插入一个队列
foreach(q[k])
$display("############ ",q[k]);
q={q[0],q[2:$]}; //{0,2,3,4,5}删除第1个元素
foreach(q[k])
$display("!!!!!!!!!!!!",q[k]);
//下面的操作执行速度很快
q={6,q}; //{6,0,2,3,4,5}在队列前面插入
foreach(q[k])
$display("############# ",q[k]);
j=q[$]; //等同于j=5
q=q[0:$-1]; //{6,0,2,3,4}从队列末尾取出数据
foreach(q[k])
$display("))))))",q[k]);
q={q,8}; //{6,0,2,3,4,8} 在队列末尾出入
foreach(q[k])
$display("&&&&&&&&&&&7 ",q[k]);
j=q[0]; //等同于j=6
q=q[1:$];
foreach(q[k])
$display("***********8",q[k]);
q={};
foreach(q[k])
$display("(((((((((((((((9 ",q[k]);
end 队列中的元素是连续存放的,所以在队列的前面或后面存取数据非常方便。无论队列有多大,这种操作所耗费的时间都是一样的。在队列中间增加或删除元素需要对已经存在的数据进行搬移以便腾出空间。相应操作所耗费的时间会随着队列的大小线性增加。你可以把定宽或动态数组的值复制给队列。
2.5关联数组
如果你只是偶尔需要创建一个大容量的数组,那么动态数组已经足够好用了,但是如果你需要超大容量的呢?假设你正在对一个有着几个G字节寻址范围的处理器进行建模。在典型的测试中,这个处理器可能只访问了用来存放可执行代码和数据的几百或几千个字节,这种情况下对几G字节的存储空间进行分配和初始化显然是浪费的。
System verilog提供了关联数组类型,用来保存稀疏矩阵的元素。这意味着当你对个非常大的地址空间进行寻址时, System Verilog只为实际写入的元素分配空间。在图2.4中,关联数组只保留0…3、42、1000、4521和200000等位置上的值。这样,用来存放这些值的空间比有200000个条目的定宽或动态数组所占用的空间要小得多。 仿真器可以采用树或哈希表的形式来存放关联数组,但有一定的额外开销。当保存索引值比较分散的数组时,例如使用32位地址或64位数据作为索引的数据包,这种额外开销显然是可以接受的。关联数组采用在方括号中放置数据类型的形式来进行声明,例如[int]或[ Packet]例2.21示范了关联数组的声明、初始化和遍历过程。
仿真器可以采用树或哈希表的形式来存放关联数组,但有一定的额外开销。当保存索引值比较分散的数组时,例如使用32位地址或64位数据作为索引的数据包,这种额外开销显然是可以接受的。关联数组采用在方括号中放置数据类型的形式来进行声明,例如[int]或[ Packet]例2.21示范了关联数组的声明、初始化和遍历过程。
例2.21关联数组的声明、初始化和使用
initial
begin
bit[63:0] assoc[bit[63:0]],idx=1;
//对稀疏分布的元素进行初始化
repeat(64)
begin
assoc[idx]=idx;
idx=idx<<1;
end
//使用foreach遍历数组
foreach(assoc[i])
$display("assoc[%h]=%h",i,assoc[i]);
//使用函数遍历数组
if (assoc.first(idx))
begin//得到第一个索引
do
$display("assoc[%h]=%h",idx,assoc[idx]);
while(assoc.next(idx));
end
//找到并删除第一个元素
assoc.first(idx);
assoc.delete(idx);
$display("The array now has %0d elements" ,assoc.num);
end 例2.21中的关联数组 assoc具有稀疏分布的元素:1、2、4、8、16等等。简单的for循环并不能遍历该数组,你需要使用 foreach循环遍历数组。如果你想控制得更好,可以在do。while循环中使用 first和next函数。这些函数可以修改索引参数的值,然后根据数组是否为空返回0或1。
和Perl语言中的哈希数组类似,关联数组也可以使用字符串索引进行寻址。例2.22使用字符串索引读取文件,并建立关联数组 switch,以实现从字符串到数字的映射。有关字符串的更多细节会在2.14节给出。如例2.22所示,可以使用函数 exists()来检查元素是否存在。如果你试图读取尚未被写入的元素, System Verilog会返回数组类型的缺省值,例如对于双状态类型是0,对于四状态类型是X。
例2.22使用带字符串索引的关联数组
int switch[string],min_address,max_address;
initial
begin
int i,r ,file;
string s;
file =$fopen("switch.txt","r");
while(!$feof(file))
begin
r=$fscanf(file,"%d %s",i,s);
switch[s]=i;
end
$fclose(file);
//获取最小地址值,缺省值为0
min_address=switch["min_address"];
//获取最大地址值,缺省为100
if (switch.exists("max_address"))
max_address=switch["max_address"];
else
max_address=1000;
//打印数组的所有元素
foreach(switch[s])
$display("switch['%s']=%0d",s,switch[s]);
end2.6链表
System verilog提供了链表数据结构,类似于标准模板库(STL)的列表容器。这个容器被定义为一个参数化的类,可以根据用户需要存放各种类型的数据。虽然 System Verilog提供了链表,但应该避免使用它,C++程序员也许很熟悉STL,但是 System Verilog的队列更加高效易用。
2.7数组的方法
System Verilog提供了很多数组的方法,可用于任何一种非合并的数组类型,包括定宽数组、动态数组、队列和关联数组。这些方法有简有繁,简单的如求当前数组的大小,复杂的如对数组进行排序。如果不带参数,则方法中的圆括号可以省略。
2.7.1数组缩减方法
基本的数组缩减方法是把一个数组缩减成一个值,如例2.23所示。最常用的缩减方法是sum,它对数组中的所有元素求和。这里必须对 System Verilog处理操作位宽的规则十分小心。缺省情况下,如果你把一个单比特数组的所有元素相加,其和也是单比特的。但如果你使用32比特的表达式,把结果保存在32比特的变量里,与一个32比特的变量进行比较,或者使用适当的with表达式, System verilog都会在数组求和的过程中使用32比特位宽。关于with表达式会在2.7.2节中描述。
bit on[10];
int total;
initial
begin
foreach(on[i]) //单比特数组
on[i]=i; //on[i]的值为0或1
//打印出单比特的和
$display("on.sum=%0d ",on.sum);
//打印出32比特的和
$display("on.sum=%0d",on.sum+32'd0);//on.sum=5;
//由于total是32比特变量,所以数组和也是32比特
total=on.sum;
$display("total =%0d ",total);
//将数组和与一个32比特的数进行比较
if(on.sum>=32'd5)
$display("sum has 5 or more 1's");
//使用带32比特有符号运算的with表达式
$display("int sum =%0d",on.sum with(int'(item)));
end 其他的数组缩减方法还有 product(积),and(与),or(或),和xor(异或)。System verilog没有提供专门从数组里随机选取一个元素的方法。所以对于定宽数组、队列、动态数组和关联数组可以使用$ urandom range($size(aay)-1),),而对于队列和动态数组还可以使用 $urandom range(array,size()-1)。有关 Surandom range的更多信息可参考6.10节
如果想从一个关联数组中随机选取一个元素,你需要逐个访问它之前的元素,原因是没有办法能够直接访问到第N个元素。例2.24示范了如何从一个以整数值作为索引的关联数组中随机选取一个元素。如果数组是以字符串作为索引,只需要将idx的类型改为 string即可。
例2.24从一个关联数组中随机选择一个元素
int aa[int],rand_idx,element,count;
initial begin
element = $urandom_range((aa.size()-1));
foreach(aa[i])
if (count++ == element)
begin
rand_idx=i;
break;
end
$display("%0d element aa[%0d]",element,rand_idx,aa[rand_idx]);
end 2.7.2数组定位方法
数组中的最大值是什么?数组中有没有包含某个特定值?要想在非合并数组中查找数据,可以使用数组定位方法。这些方法的返回值通常是一个队列。例2.25使用一个定宽数组f6,一个动态数组d[ ]和一个队列q[$]。min和mx函数能够找出数组中的最小值和最大值。注意,它们返回的是一个队列而非标量。这些方法也适用于关联数组。方法 unique返回的是在数组中具有唯一值的队列,即排除掉重复的数值。
例2.25数组定位方法:min、max、 unique
initial begin
int f[6]='{1,6,2,6,8,6};
int d []='{2,4,6,8,10};
int q[$] ={1,3,5,7},tq[$];
tq=q.min(); //{1}
//$display("th min of q is %0d",tq);
tq=d.max() ;// {10}
//$display("th max of q is %0d",tq);
tq=f.unique();//{1,6,2,8}
//$display("th unique of f is %0d",tq);
end 使用 foreach循环固然可以实现数组的完全搜索,但是如果使用 System verilog的定位方法,则只需一个操作便可完成。表达式with可以指示 System Verilog如何进行搜索。如例2.26所示。
例2.26数组定位方法:find
int d[]='{9,1,8,3,4},tq[$];
initial begin
//找出所有大于3的元素
tq=d.find with(item>3);
//等效代码
tq.delete();
foreach (d[i])
if (d[i]>3)
tq.push_back(d[i]);
foreach (tq[i])
$display(tq[i]);
$display("############");
tq=d.find_index with (item>3);
foreach (tq[i])
$display(tq[i]);
$display("_______________________");
tq=d.find_first with (item >99);
foreach (tq[i])
$display(tq[i]);
$display("****************");
tq=d.find_first_index with (item==8);
foreach (tq[i])
$display(tq[i]);
$display("^^^^^^^^^^^^");
tq=d.find_last with (item==4);
foreach (tq[i])
$display(tq[i]);
$display("&&&&&&&&&&&&&&&&&");
tq=d.find_last_index with (item==4);
foreach (tq[i])
$display(tq[i]);
$display("$$$$$$$$$$$$$$");
end 在条件语句wih中,item被称为重复参数,它代表了数组中一个单独的元素。item是缺省的名字,你也可以指定别的名字,只要在数组方法的参数列表中列出来就可以了,如例2.27所示
例2.27重复参数的声明
tq=d.find_first with (item==3);
tq=d.find_first() with (item==4);
tq=d.find_first(item) with (item==4);
tq=d.find_first(x) with (x==4); 例2.28示范了几种对数组子集进行求和的方式。第一次求和(total)是先把元素值与7进行比较,比较表达式返回1(为真)或0(为假)然后再把返回结果与对应元素相乘,所以{9,0,8,0,0,0}的元素和是17。第二次求和(tota1)则使用条件操作符?:进行计算。
例2.28数组定位方法
int count,total,d[]='{9,1,8,3,4,4};
count=d.sum with (item>7); //2:{9,8}
total =d.sum with ((item>7)*item);//17=9+8
count=d.sum with (item<8); //4:{1,3,4,4}
total =d.sum with (item<8 ? item :0); //12=1+3+4+4
count =d.sum with (item==4); //2:{4,4}
当你把数组缩减方法与条件语句with结合使用时,你会发现惊人的结果,例如sum方法。在例2.28中,sum操作符的结果是条件表达式为真的次数。对于例2.28的第一个运算语句来说,总共有两个数组元素大于7(9和8),所以 count最后得2。
返回值为索引的数组定位方法,其返回的队列类型是int而非integer,例如 find index方法。如果你在这些语句中不小心用错了数据类型,那么代码有可能通不过编译。
2.7.3数组的排序
System Verilog有几个可以改变数组中元素顺序的方法。你可以对元素进行正排序、逆排序,或是打乱它们的顺序,如例2.29所示。注意,与2.7.2节中的数组定位方法不同的是,排序方法改变了原始数组,而数组定位方法新建了一个队列来保存结果。
int d[]='{9,1,8,3,4,4};
initial begin
d.reverse();// '{4,4,3,8,1,9}
foreach (d[i])
$display(d[i]);
$display("****************");
d.sort() ; //'{1,3,4,4,8,9}
foreach (d[i])
$display(d[i]);
$display("****************");
d.rsort(); //'{9,8,4,4,3,1}
foreach (d[i])
$display(d[i]);
$display("****************");
d.shuffle(); //'{9,4,3,8,1,4}
foreach (d[i])
$display(d[i]);
$display("****************");
end reverse和 shuff1e方法不能带wih条件语句,所以它们的作用范围是整个数组。例2.30示范了如何使用子域对一个结构进行排序。结构和合并结构在2.10节会有解释。
例2.30对结构数组进行排序
struct packed {byte red,green,blue;} c[];
initial
begin
c=new[100]; //分配100个像素
foreach(c[i])
c[i]=$urandom; //填上随机数
c.sort with (item.red); //只对红色(red)像素进行排序
foreach (c[i])
$display(c[i].red);
//先对绿色(green)像素后对蓝色像素
c.sort(x) with ({x.green,x.blue});
end2.7.4使用数组定位方法建立记分板
数组定位方法可以用来建立记分板。例2.31定义了包结构( Packet),然后建立了一个由包结构队列组成的记分板。2.9节会解释如何使用 typedef创建结构。
typedef struct packed
{bit[7:0] addr;
bit [7:0] pr;
bit [15:0] data;} Packet;
Packet scb[$];
function void check_addr(bit [7:0] addr);
int intq[$];
intq=scb.find_index() with (item.addr==addr);
case (intq.size())
0:
$display("Addr %h not found in scoreboard",addr);
1:
scb.delete(intq[0]);
default:
$display("ERROR :mULTIPLE HITS FOR ADDR", addr);
endcase
endfunction :check_addr例2.31中的 check addr()函数在记分板里寻找和参数匹配的地址。 find index()方法返回一个int队列。如果该队列为空(size==0),则说明没有匹配值。如果该队列有一个成员(size==1),则说明有一个匹配,该匹配元素随后被 check addr()函数删除掉。如果该队列有多个成员(size>1),则说明记分板里有多个包地址和目标值匹配。对于包信息的存储,更好的方式是采用类,第5章会有相关介绍。而关于结构的更多信息可参见2.10节。
2.8选择存储类型
下面介绍基于灵活性、存储器用量、速度和排序要求正确选择存储类型的一些准则。这些准则只是一些经验法则,其结果可能会随着仿真器的不同而不同。
2.8.1灵活性
如果数组的索引是连续的非负整数0、1、2、3等,则应该使用定宽或动态数组。当数组的宽度在编译时已经确定时选择定宽数组,如果要等到程序运行时才知道数组宽度的话则选择动态数组。例如,长度可变的数据包使用动态数组存储会很方便。当你编写处理数组的子程序时,最好使用动态数组,因为只要在元素类型(如int、 string等)匹配的情况下,同一个子程序可以处理不同宽度的数组。同样地,只要元素类型匹配,任意长度的队列都可以传递给子程序。关联数组也可以作为参数传递,而不用考虑数组宽度的问题。相比之下,带定宽数组参数的子程序则只能接受指定宽度的数组。当数组索引不规则时,例如对于由随机数值或地址产生的稀疏分布索引,则应选择关联数组。关联数组也可以用来对基于内容寻址( content-addressable)的存储器建模。对于那些在仿真过程中元素数目变化很大的数组,例如保存预期值的记分板,队列是一个很好的选择。
2.8.2存储器用量
使用双状态类型可以减少仿真时的存储器用量。为了避免浪费空间,应尽量选择32比特的整数倍作为数据位宽。仿真器通常会把位宽小于32比特的数据存放到32比特的字里。例如,对于一个大小为1024的字节数组,如果仿真器把每个元素都存成一个32比特字,则会浪费3/4的存储空间。使用合并数组就有助于节省存储空间。对于具有一千个元素的数组,数组类型的选择对存储器用量的影响不大(除非这种数组的量非常大)。对于具有一千到一百万个活动元素的数组,定宽和动态数组具有最高的存储器使用效率。如果你需要用到大于一百万个活动元素的数组,那就有必要重新检查下算法是否有问题。因为需要额外的指针,队列的存取效率比定宽或动态数组稍差。但是,如果你把长度经常变化的数据集存放到动态存储空间里,那么你需要手工调用new[]来分配和复制内存。这个操作的代价会很高,可能会抵消使用动态存储空间所带来的全部好处。对兆字节量级的存储器建模应该使用关联数组。注意,因为指针带来的额外开销,关联数组里每个元素所占用的空间可能会比定宽或动态数组占用的空间大好几倍。
2.8.3速度
还应根据每个时钟周期内的存取次数来选择数组类型。对于少量的读写,任何类型都可以使用,因为即使有额外开销,相比整个DUT也会显得很小。但是如果数组的操作很频繁.则数组的宽度和类型就会变得很关键。
因为定宽和动态数组都是被存放在连续的存储器空间里,所以访问其中的任何元素耗时都相同,而与数组的大小无关。
队列的读写速度与定宽或动态数组基本相当。队列首尾元素的存取几乎没有任何额外开销,而在队列中间插入或删除元素则需要对很多其他元素进行搬移以便腾出空间。当你需要在一个很长的队列里插入新元素时,你的测试程序可能会变得很慢,这时最好考虑改变新元素的存储方式。
对关联数组进行读写时,仿真器必须在存储器里进行搜索。 System verilog的语言参考手册里并没有阐明这个过程是如何完成的,但最常用的方法是使用哈希表和树型结构。相比其他类型的数组,这要求更多的运算量,所以关联数组的存取速度是最慢的。
2.8.4排序
由于 System Verilog能够对任何类型的一维数组(定宽、动态、关联数组以及队列)进行排序,所以你应该根据数组中元素增加的频繁程度来选择数组的类型。如果元素是次性全部加入的话,则选择定宽或动态数组,这样你只需对数组进行一次分配。如果元素是逐个加入的话,则选择队列,因为在队列首尾加入元素的效率很高。
如果数组的值不连续且彼此互异,例如{1,10,11,50},那么你可以使用关联数组并把元素值本身作为索引。使用子程序 first、next和prev可以从数组中查找某个特定值并进而找到它的相邻值。因为链表的是双重链接的,所以可以很容易地同时找到比当前值大的值和小的值。关联数组和链表也都支持对元素的删除操作。相比之下,关联数组通过给定索引的方式来存取元素还是比链表要快得多。
例如,你可以使用一个关联数组来存放预期的32比特数值。数值生成后便直接写人索引的位置。如果想知道某个数值是否已被写入,可以使用 exists函数来检查。如果不需要某个元素时,可以使用 delete把它从关联。
2.8.5选择最优的数据结构
以下是针对数据结构选择的一些建议:
(1)网络数据包。特点:长度固定,顺序存取。针对长度固定或可变的数据包可分别采用定宽或动态数组。
(2)保存期望值的记分板。特点:仿真前长度未知,按值存取,长度经常变化。一般情况下可使用队列,这样方便在仿真期间连续增加和删除元素。如果你能够为每个事务给出一个固定的编号,例如1、2、3……,那么可以把这个编号作为队列的索引。如果事务涉及的全都是随机数值,那么只能把它们压入队列中并从中搜索特定的值。如果记分板有数百个元素,而且需要经常在元素之间进行增删操作,则使用关联数组在速度上可能会快。
(3)有序结构。如果数据按照可预见的顺序输出,那么可以使用队列;如果输出顺序不确定,则使用关联数组。如果不用对记分板进行搜索,那么只需要把预期的数值存入信箱( mailbox),如7.6节所示。
(4)对超过百万个条日的特大容量存储器进行建模。如果你不需要用到所有的存储空间,可以使用关联数组实现稀疏存储。如果你确实需要用到所有的存储空间,试试有没有其他办法可以减少数据的使用量。如果还有问题,请确保使用的是双状态的32比特合并数据。
(5)文件中的命令名或操作码。特点:把字符串转换成固定值。从文件中读出字符串,然后使用命令名作为字符串索引在关联数组中查找命令名或操作码在第5章OOP基础(面向对象编程)中还会涉及指向对象的句柄数组。
2.9使用 typedef创建新的类型
typed语句可以用来创建新的类型。例如,你要求一个算术逻辑单元(ALU)在编译时可配置,以适应8比特、16比特、24比特或32比特等不同位宽的操作数。在Verilog中,你可以为操作数的位宽和类型分别定义一个宏( macro),如例2.32所示。
例2.32 Verilog中用户自定义的类型宏
//老的Verilog风格
`define OPSIZE 8
`define OPREG reg [`OPSIZE-1:0]
`OPREG op_a,op_b; 这种情况下,你并没有创建新的类型,而只是在进行文本替换。在 System Verilog中,采用下面的代码可以创建新的类型。本书约定,所有用户自定义类型都带后缀“_t"。
例2.33 Systemverilog中用户自定义类型
//新的 Systemverilog风格
parameter OPSIZE=8;
typedef reg [OPSIZE-1:0] opreg_t;
opreg_t op_a,op_b; 一般来说,即使数据位宽不匹配例如值被扩展或截断, System Verilog都允许在这些基本类型之间进行复制而不会给出警告注意,可以把 parameter和 typedef语句放到一个程序包( package)里以使它们能被整个设计和测试平台所共用,如4.6节所示范的那样。
用户自定义的最有用的类型是双状态的32比特的无符号整数。在测试平台中,很多数值都是正整数,例如字段长度或事务次数,这种情况下如果定义有符号整数就会出问题。把对uint的定义放到通用定义程序包中,这样就可以在仿真程序的任何地方使用它。
例2.34uint的定义
typedef bit [31: 0] uint; //32比特双状态无符号数
typedef int unsigned intit;//等效的定义
对新的数组类型的定义并不是很明显。你需要把数组的下标放在新的数组名称中例2.35创建了一种新的类型, fixed array5,它是一个有着5个元素的定宽数组。例2.35接着声明了一个这种类型的数组并进行了初始化。
例2.35用户自定义数组类型
typedef int fixed_array5[5];
fixed_array5 f5;
initial
begin
foreach (f5[i])
f5[i]=i;
end2.10创建用户自定义结构
Verilog的最大缺陷之一是没有数据结构。在 System Verilog中你可以使用 struct语句创建结构,跟C语言类似。但 struct的功能比类少,所以还不如直接在测试平台中使用类,这一点在第5章中会有详述。就像 Verilog的模块( module)中同时包括数据(信号)和代码( always/ initial代码块及子程序)一样,类里面也包含数据和程序,以便于调试和重用。 struct只是把数据组织到一起。如果缺少可以操作数据的程序,那么也只是解决了一半的问题。由于 struct只是一个数据的集合,所以它是可综合的。如果你想在设计代码中对个复杂的数据类型进行建模,例如像素,可以把它放到 struct里。结构可以通过模块端口进行传递。而如果你想生成带约束的随机数据,那就应该使用类了。
2.10.1使用 struct创建新类型
你可以把若干变量组合到一个结构中。例2.36创建了一个名为 pixel的结构,它有三个无符号的字节变量,分别代表红、绿和蓝。
例2.36 创建一个pixel类型
struct {bit[7:0 ] r,g,b;}pixel; 例2.36中的声明只是创建了一个pixel变量。要想在端口和程序中共享它,则必须创建一个新的类型如例2.37所示。
例2.37pixel结构
typedef struct {bit[7:0] r,g,b;} piel_s;
pixel_s my_pixel;在struct的声明中使用后缀“_s”可以方便用户识别自定义类型,简化代码的共享和重用过程。
2.10.2对结构进行初始化
你可以在声明或者过程赋值语句中把多个值赋给一个结构体,就像数组那样。如例2.38所示,赋值时要把数值放到带单引号的大括号中。
例2.38 对struct类型进行初始化
typedef struct packed {
bit [3:0] mode;
bit [2:0] cfg;
bit en;
} st_ctrl;
module tb;
st_ctrl ctrl_reg;
initial begin
// Initialize packed structure variable
ctrl_reg = '{4'ha, 3'h5, 1};
$display ("ctrl_reg = %p", ctrl_reg);
// Change packed structure member to something else
ctrl_reg.mode = 4'h3;
$display ("ctrl_reg = %p", ctrl_reg);
// Assign a packed value to the structure variable
ctrl_reg = 8'hfa;
$display ("ctrl_reg = %p", ctrl_reg);
end
endmodule2.10.3创建可容纳不同类型的联合
在硬件中寄存器里的某些位的含义可能与其他位的值有关。例如,不同的操作码对应的处理器指令格式也不同。带立即操作数的指令,它在操作数位置上存放的是一个常量。整数指令对这个立即数的译码结果会与浮点指令大不相同。例2.39把整数i和实数f存放在同一位置上。
例2.39使用typedef创建联合
typedef union {int i;int f;} num_u;
num_u un;
un.f='{0.0};//把数值设为浮点形式这里使用后缀“_u”来表示联合类型。
如果需要以若干不同的格式对同一寄存器进行频繁读写时。联合体相当有用。但是,不要滥用,尤其不要仅仅因为想节约存储空间就使用联合。与结构相比,联合可能可以节省几个字节,但是付出的代价却是必须创建并维护一个更加复杂的数据结构。如8.4.4节中所提到的,使用一个带判别变量的简单类可以达到同样的效果。这个判别变量的好处在于它标明了需要处理的数据类型,据此可以对相应字段实施读、写和随机化等操作。假如你只需要一个数组,并想使用所有的比特来提高存储效率,那使用2.2.6节中介绍的合并数组是很合适的。
2.10.4合并结构
System Verilog提供的合并结构允许对数据在存储器中的排布方式有更多的控制。合并结构是以连续比特集的方式存放的,中间没有闲置的空间。例2.37中的 pixel结构使用了三个数值,所以它占用了三个长字的存储空间,即使它实际只需要三个字节。你可以指定把它合并到尽可能小的空间里。
例2.40 合并结构
typedef strcut packed {bit[7:0] r,g,b ;} pixel_p_s;
pixel_p_s my_pixel;当希望减少存储器的使用量或存储器的部分位代表了数值时,可以使用合并结构。例如,可以把若干个比特域合并成一个寄存器,也可以把操作码和操作数合并在一起来包含整个处理器指令
2.10.5在合并结构和非合并结构之间进行选择
当在合并和非合并结构体间选择时,必须考虑结构通常的使用方式和元素的对齐方式。如果对结构的操作很频繁,例如需要经常对整个结构体进行复制,那么使用合并结构的效率会比较高。但是,如果操作经常是针对结构内的个体成员而非整体,那就应该使用非合并结构。当结构的元素不按字节对齐,或者元素位宽与字节不匹配,又或者元素是处理器的指令字时,使用合并和非合并结构在性能上的差别会更大。对合并结构中尺寸不规则的元素进行读写,需要移位和屏蔽操作,代价很高。
2.11类型转换
Systemverilog数据类型的多样性意味着你可能需要在它们之间进行转换。如果源变量和目标变量的比特位分布完全相同,例如整数和枚举类型,那它们之间可以直接相互赋值。如果比特位分布不同,例如字节数组和字数组,则需要使用流操作符对比特分布重新安排。
2.11.1静态转换
静态转换操作不对转换值进行检查。如例2.41所示,转换时指定目标类型,并在需要转换的表达式前加上单引号即可。注意, verilog对整数和实数类型,或者不同位宽的向量之间进行隐式转换。
例2.41 在整型和实型之间进行静态转换
int i;
real r;
i=int'(10.0-0.1); //转换是非强制的
r=real'(42); //转换是非强制的2.11.2动态转换
动态转换函数 $cast允许你对越界的数值进行检查。相关内容可参见2.12.3节中对于枚举类型的解释和示例。
2.11.3流操作符
流操作符<<和>>用在赋值表达式的右边,后面带表达式、结构或数组。流操作符用于把其后的数据打包成一个比特流。操作符>>把数据从左至右变成流,而<<则把数据从右至左变成流,如例2.42所示。你也可以指定一个片段宽度,把源数据按照这个宽度分段以后再转变成流。不能将比特流结果直接赋给非合并数组,而应该在赋值表达式的左边使用流操作符把比特流拆分到非合并数组中。
例2.42基本的流操作
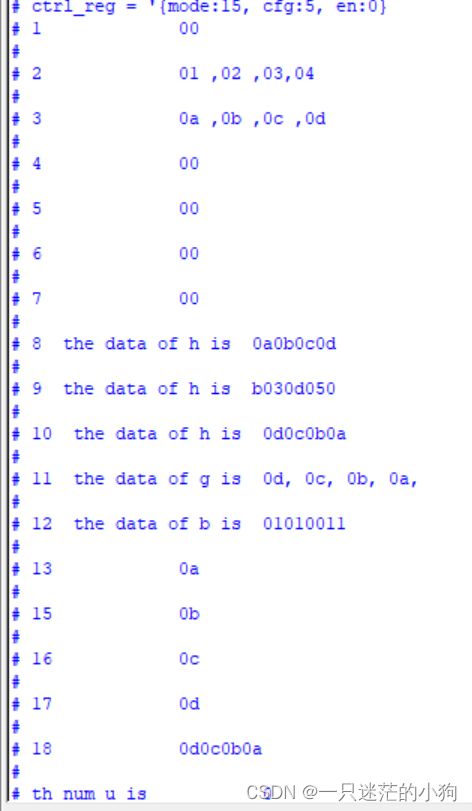
bit[7:0] b,g[4]='{8'h01,8'h02,8'h03,8'h04},j[4]='{8'ha,8'hb,8'hc,8'hd};
//对g[4],j[4]都进行初始化了bit[7:0] b,g[4],j[4]='{8'ha,8'hb,8'hc,8'hd};
//对g[4]没有初始化,默认全部为0,j[4]都进行初始化了 initial begin
int h;
bit[7:0] b,g[4]='{8'h01,8'h02,8'h03,8'h04},j[4]='{8'ha,8'hb,8'hc,8'hd};
bit [7:0] q,r,s,t;
$display("1 %h\n",b);
$display("2 %h ,%h ,%h,%h \n",g[0],g[1],g[2],g[3]);
$display("3 %h ,%h ,%h ,%h \n",j[0],j[1],j[2],j[3]);
$display("4 %h\n",q);
$display("5 %h\n",r);
$display("6 %h\n",s);
$display("7 %h\n",t);
h={>>{j}};
$display("8 the data of h is %h \n",h);
h={<<{j}};
$display("9 the data of h is %h \n",h);
h={<>{q,r,s,t}}=j;
$display("13 %h\n",q);
$display("15 %h\n",r);
$display("16 %h\n",s);
$display("17 %h\n",t);
h={>>{t,s,r,q}};
$display("18 %h\n",h);
end
也可以使用很多连接符{ }来完成同样的操作,但是流操作符用起来会更简洁并且易于阅读。如果需要打包或拆分数组,可以使用流操作符来完成具有不同尺寸元素的数组间的转换。例如,你可以将字节数组转换成字数组。对于定宽数组、动态数组和队列都可以这样。例2.43示范了队列之间的转换,这种转换同时也适用于动态数组。数组元素会根据需要自动分配。
例2.43使用流操作符进行队列间的转换
initial begin
bit [15:0] wq[$]={16'h1234,16'h5678};
bit [7:0] bq[$];
foreach(wq[i])
$display("1 %h \n",wq[i]);
//把字数组转换成字节数组
bq={>>{wq}};
foreach (bq[i])
$display("2 %h\n",bq[i]);
//把字节数组转换成字数组
bq={8'h98,8'h76,8'h54,8'h32};
foreach (bq[i])
$display("3 %h \n",bq[i]);
wq={>>{bq}};
foreach (wq[i])
$display("4 %h \n",wq[i]);
wq={<<{bq}};
foreach (wq[i])
$display("5 %h \n",wq[i]);
end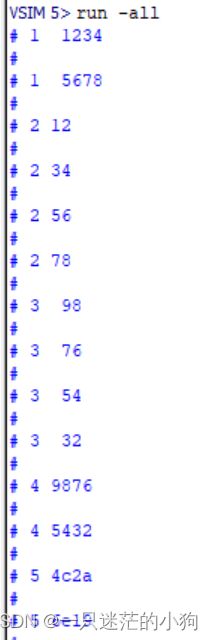
数组下标失配是在数组间进行流操作时常见的错误。数组声明中的下标[256]等同于[0:255]而非[255:0]。由于很多数组使用[high:low](由高到低)的下标形式进行声明,使用流操作把它们的值赋给带[size]下标形式的数组,会造成元素倒序。同样,如果把声明形式为bit[7:0]src[255:0]的非合并数组使用流操作赋值给声明形式为bit[7:0][255:0]dst的合并数组,则数值的顺序会被打乱。对于合并的字节数组,正确的声明形式应该是bit[255:0][7:0]dst。
流操作符也可用来将结构(例如,ATM信元)打包或拆分到字节数组中。在例2.44中使用流操作把结构转换成动态的字节数组,然后字节数组又被反过来转换成结构。
例2.44使用流操作符在结构和数组间进行转换
typedef struct {int a;
byte b;
shortint c;
int d;} my_struct_s;
module tb;
my_struct_s st = '{32'haaa_aaa,8'hbb,16'hcccc,32'hddd_dddd};
initial begin
#1000;
// $display("st.a is %h\n",st.a);
// $display("st.b is %h \n",st.b); */
// $display("st.c is %h \n",st.c);
// $display("st.d is %h \n",st.d);
byte b[];
//将结构体转换为字节数组
b={>>{st}};
foreach (b[i])
$display(" b[%i ] is %h \n",b[i]);
//将字节数组转换为结构
b='{8'h11,8'h22,8'h33,8'h44,8'h55,8'h66,8'h77,8'h88,8'h99,8'haa,8'hbb};
st={>>{b}};
$display("2 st.b is %h\n",st.b);
$display("2 st.c is %h \n",st.b);
$display("2 st.d is %h \n",st.c);
end
endmodule2.12枚举类型
在学会使用枚举类型之前,你只能使用文本宏。宏的作用范围太大,而且大多数情况下对于调试者是可见的。枚举创建了一种强大的变量类型,它仅限于一些特定名称的集合,例如指令中的操作码或者状态机中的状态名·例如,使用ADD、MOⅤE或ROTW这些名称有利于编写和维护代码,它比直接使用8'h01这样的常量或者宏要好得多。定义常量的另一种方法是使用参数。但参数需要对每个数值进行单独的定义,而枚举类型却能够自动为列表中的每个名称分配不同的数值。最简单的枚举类型声明包含了一个常量名称列表以及一个或多个变量,如例2.45所示。通过这种方式创建的是一个匿名的枚举类型,它只能用于这个例子中声明的变量。
例2.45一个简单的枚举类型
enum {RED,BLUE,GREEN} color;创建一个署名的枚举类型有利于声明更多新变量,尤其是当这些变量被用作子程序参数或模块端口时。你需要首先创建枚举类型,然后再创建相应的变量。使用内建的name()函数,你可以得到枚举变量值对应的字符串,如例2.46所示。
例2.46枚举类型
typedef enum {INIT,DECODE,IDLE} fsmstate_e;
fsmstate_e pstate,nstate;
initial begin
case (pstate)
IDLE: nstate=INIT;
INIT :nstate=DECODE;
default :nstate=IDLE;
endcase
$display("next state is %s ",nstate.name());
end这里,使用后缀“_e”来表示枚举类型。
2.12.1定义枚举值
枚举值缺省为从0开始递增的整数。你可以定义自己的枚举值。例2.47中使用INIT代表缺省值0, DECODE代表2,IDE代表3。
例2.47指定枚举值
typedef enum [{INIT, DECODE=2, IDLE }fsmtype e; 枚举常量,如例2.47中的INIT,它们的作用范围规则和变量是一样的。因此,如果你在不同的枚举类型中用到了同一个枚举常量名,例如把INIT用于不同的状态机中,那么你必须在不同的作用域里声明它们,例如模块、程序块、函数和类。
如果没有特别指出,枚举类型会被当成int类型存储。由于int类型的缺省值是0,所以在给枚举常量赋值时务必小心。在例2.48中,position会被初始化为0,这并不是一个合法的 ordinal_e变量。这种情况是语言本身所规定的,而非工具上的缺陷。因此把0指定给一个枚举常量可以避免这个错误,如例2.49所示。
例2.48 指定枚举值:不正确
typedef enum {FIRST=1,SECOND,THIRD} ordinal_e;
ordinal_e position;
例2.49指定枚举值:正确
typedef enum {FIRST=1,SECOND,THIRD} ordinal_e;
ordinal_e position;
2.12.2枚举类型的子程序
System Verilog提供了一些可以遍历枚举类型的函数:
(1) first()返回第一个枚举常量。
(2)last()返回最后一个枚举常量。
(3)next()返回下一个枚举常量。
(4)next(N)返回以后第N个枚举常量。
(5)prev()返回前一个枚举变量。
(6)prev(N)返回以前第N个枚举变量。
当到达枚举常量列表的头或尾时,函数next和prev会自动以环形方式绕回。注意,要在for循环中使用变量来遍历枚举类型中的所有成员并非易事。你可以使用 first访问第一个成员,使用next访问后面的成员。问题在于如何为循环设置终止条件。如果使用 current!= current.last,则循环会在到达最后一个成员之前终止。如果使用 current<= current.last,则会造成死循环,因为next给出的值永远也不会大于最后一个值。这类似于for循环的步长为0.3,而循环变量定义为[1:0],所以循环永远不会退出。
实际上,可以使用do..whie循环来遍历所有值,如例2.50所示。
例2.50遍历所有枚举成员
typedef enum {RED,BLUE,GREEN} color;
color col;
initial begin
col=col.first;
do
begin
$display("color =%0d /%s ",col,col.name);
col=col.next;
end
while (col!=col.first);
end2.12.3枚举类型的转换
枚举类型的缺省类型为双状态int。可以使用简单的赋值表达式把枚举变量的值直接赋给非枚举变量如int。但 System Verilog不允许在没有进行显式类型转换的情况下把整型变量赋给枚举变量。 System Verilog要求显式类型转换的目的在于让你意识到可能存在的数值越界情况。
typedef enum {RED,BLUE,GREEN} color_e;
color_e color ,c2;
int c;
initial begin
color=BLUE; //赋一个已知的合法值
c=color; //将枚举类型转换成整型
c++;
if (!$cast(color,c)) //将整型显示转换成枚举类型
$display("cast failed for c= %0d ",c);
$display("color is %d / %s",color,color.name);
c++ ;//对于枚举类型已经越界
c2=color_e'(c);//不做类型检查
$display("c2 is %0d %s ,",c2,c2.name);
end在例2.51中, $cast被当成函数进行调用,目的在于把其右边的值赋给左边的量。如果赋值成功, $cast()返回1。如果因为数值越界而导致赋值失败,则不进行任何赋值,函数返回0。如果把 $cast当成任务使用并且操作失败,则 System Verilog会打印出错误信息。你也可以像例2.51所示的那样使用 type'(val)进行类型转换,但这种方式并不进行任何类型检查,所以转换结果可能会越界。例如,在例2.51中进行静态类型转换以后,赋给c2的值实际上已经越界。所以应该尽量避免使用这种方式。
2.13常量
System verilog中有好几种类型的常量。Verilog中创建常量的最典型的方法是使用文本宏。它的好处是:宏具有全局作用范围并且可以用于位段和类型定义。它的缺点同样是因为宏具有全局作用范围,在你只需要一个局部常量时可能会引发冲突。此外,宏定义需要使用“ . ” 符号,这样它才能被编译器识别和扩展。
在 System Verilog中,参数可以在程序包里声明,因此可以在多个模块中共同使用。这种方式可以替换掉 verilog中很多用来表示常量的宏。你可以用 typedef来替换掉那些单调乏味的宏。其次还可以选择 parameter. Verilog中的 parameter并没有严格的类型界定,而且其作用范围仅限于单个模块里。 verilog2001增加了带类型的 parameter,但其有限的作用范围仍然使得它无法获得广泛应用。System verilog也支持 const修饰符,允许在变量声明时对其进行初始化,但不能在过程代码中改变其值。
例2.52 const变量的声明
const byte colon=":";在例2.52中, colon的值在 initial块开头就被初始化。 const作为子程序参数的情况将在下一章的例3.10中给出。
2.14字符串
如果你曾经使用过 verilog中的reg变量来保存字符串,那么你所受的煎熬将会结束。 System Verilog中的 string类型可以用来保存长度可变的字符串。单个字符是byte类型。长度为N的字符串中,元素编号从0到N-1。注意,跟C语言不一样的是,字符串的结尾并不带标识符null,所有尝试使用字符“\0”的操作都会被忽略。字符串使用动态的存储方式,所以不用担心存储空间会全部用完。
例2.53示范了与字符串相关的几种操作。函数getc(M返回位置M上的字节,toupper返回一个所有字符大写的字符串, tolower返回一个小写的字符串。大括号{}用于串接字符串。任务putc(M,C)把字节c写到字符串的M位上,M必须介于0和len所给出的长度之间。函数 substr( start,end)提取出从位置 start到end之间的所有字符。
例2.53字符串方法
string s;
initial begin
s="IEEE ";
$display(s.getc(0));//显示:73('I')
$display(s.tolower()); //显示:ieee
s.putc(s.len()-1,"-"); //将空格变为‘-’
s={s,"P1800"} ; //“IEEE-P1800”
$display(s.substr(2,5)); //显示:EE-P1800
//创建临时字符串,注意格式
my_log($psprintf("%s %5d",s,42));
end
task my_log(string message );
//把信息打印到日志里
$display("@ %0t :%s",$time,message );
endtask
稍加留意便可发现动态字符串的用处有多大。在别的语言如C里,你必须不停地创建临时字符串来接收函数返回的结果。在例2.53中函数 $psprintf(替代了 Verilog2001中的函数 $sformat()。这个新函数返回一个格式化的临时字符串,并且可以直接传递给其他子程序。这样你就可以不用定义新的临时字符串并在格式化语句与函数调用过程中传递这个字符串。
2.15表达式的位宽
在 Verilog中,表达式的位宽是造成行为不可预知的主要源头之一。例2.54使用四种不同方式实现1+1。方式A使用两个单比特变量,在这种精度下得到1+1=0。方式B由于赋值表达式的左边有一个8比特的变量,所以其精度是8比特,得到的结果是1+1=2。方式c采用一个哑元常数强迫 Systemverilog使用2比特精度。最后,在方式D中,第一个值在转换符的作用下被指定为2比特的值,所以结果是1+1=2。
bit [7:0] b8;
bit one=1'b1;//单比特
initial begin
$display("one+one,");
$display(one+one); //1+1=0
b8=one+one;
$display("b8 is \n");
$display(b8);
$display("one+one +2'b00使用了常量");
$display(one+one+2'b00);
$display("采用强制转换类型");
$displayb(2'(one)+one);
end有一些技巧可以避免这个问题。首先,避免像上例中方式A那样由于溢出造成精度受损的情况。也可以使用临时变量,像上例中的b8那样,以得到期望的位宽。或者,可以另外加入其他的值去强制获取最小精度,就像上例中的2'b0。最后,在 System Verilog中,还可以通过对变量进行强制转换以达到期望的精度。
2.16结束语
System verilog提供了很多新的数据类型和结构,使得你可以在较高的抽象层次上编写测试平台,而不用担心比特层次的表示问题。队列很适合用于创建记分板,你可以在上面频繁地增加或删除数据。动态数组允许你在程序运行时再指定数组宽度,为测试平台提供了极大的灵活性。关联数组可用于稀疏存储和一些只有单一索引的记分板。枚举类型通过创建具名常量列表而使得你的代码更便于读写。但你不应该满足于使用这些数据结构来写测试程序。第5章里所讲述的 SystemⅤerilog的OOP特性将帮你在更高抽象层次上设计代码,进而提高代码的稳健性和可重用性。