Leetcode题库(数据库合集)
目录
- 难度:简单
-
- 1. 组合两个表
- 2. 第二高的薪水
- 3. 第N高的薪水
- 4. 分数排名
- 5. 连续出现的数字
- 6. 超过经理收入的员工
- 7. 重新
- 8. 寻找用户推荐人
- 9. 销售员
- 10. 排名靠前的旅行者
- 11. 患某种疾病的患者
- 12. 修复表中的名字
- 13. 求关注者的数量
- 14. 可回收且低脂的产品
- 15. 计算特殊奖金
- 16. 丢失信息的雇员
- 17. 每个产品在不同商店的价格
- 18. 文章浏览
- 19. 上升的温度
- 20. 按日期分组销售产品
- 21. 员工奖金
- 22. 使用唯一标识码替换员工Id
- 23. 订单最多的客户
- 24. 判断三角形
- 25. 只出现一次的最大数字
- 26. 平均售价
- 27. 查找拥有有效邮箱的用户
- 难度:中等
-
- 1.股票的资本损益
- 2. 当选者
- 3. 页面推荐
- 4. 2016年的投资
- 5. 买下所有产品的人
- 6. 电影评分
- 6. 确认率
- 7. 按分类统计薪水
- 8. 餐馆营业额的变化增长
- 8. 即时食物配送
- 9. 至少有5名直系下属的经理
- 10. 游戏玩法分析
- 11. 好友申请:谁有最多的好友
- 12. 指定日期的产品价格
- 13. 每月交易
- 14.市场分析
- 难度:困难
-
- 1. 部门工资前三高的所有员工
- 2. 行程和用户
- 3. 体育馆的人流量
- 4. 员工薪水的中位数
- 5. 同一天的第一个电话和最后一个电话
- 5. 查询员工的累计薪水
- 6. 给定数字的频率查询中位数
- 7. 查询员工的累计薪水
- 8. 学生地理信息报告
- 9. 同一天的第一个和最后一个电话
- 10. 职员招聘人数
- 11. 职员招聘人数 ②
- 12. 找到每篇文章的主题
- 13. 生成发票
- 14. 受欢迎度百分比
- 15. 购买量严格增加的客户
- 16. 合并在一个大厅重叠的活动
- 17. 表的动态旋转
- 18. 兴趣相同的朋友
- 19. Leetcodify 好友推荐
难度:简单
1. 组合两个表
表1:Person

PersonId 是上表主键
表2: Address

AddressId 是上表主键
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:
FirstName, LastName, City, State
select a.FirstName, a.LastName, b.City, b.State
from Person a
left join Address b
on a.PersonID = b.PersonID
2. 第二高的薪水
编写一个 SQL 查询,获取 Employee 表中第二高的薪水(Salary) 。
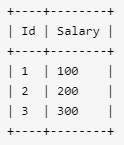
例如上述 Employee 表,SQL查询应该返回 200 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 null。

方法一:
因为排序可能会出现薪资相同的情况,
select max(Salary) as SecondHighestSalary
from (
select Salary, row_number() over (order by Salary desc) as rnk
from employee b
group by Salary
) a
where a.rnk = 2
方法二:
通过取最大值再去排除最大值去找到第二高的薪水。
select max(Salary) as SecondHighestSalary
from Employee
where Salary < (select max(Salary) from Employee)
3. 第N高的薪水
有如下两张表T
编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
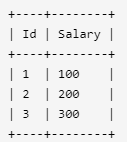
例如上述 Employee 表,n = 2 时,应返回第二高的薪水 200。如果不存在第 n 高的薪水,那么查询应返回 null。
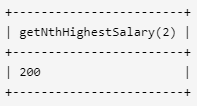
方法一:
CREATE FUNCTION getNthHighestSalary(@N INT) RETURNS INT AS
BEGIN
RETURN (
select Salary as getNthHighestSalary
from (select Salary ,dense_rank() over(order by Salary desc) as rnk
from Employee
group by Salary) a
where rnk = @N );
END
方法二:
CREATE FUNCTION getNthHighestSalary(@N INT) RETURNS INT AS
BEGIN
RETURN ( select distinct Salary
from Employee
order by Salary desc
Offset @N-1 rows
Fetch next 1 rows only);
END
4. 分数排名
编写一个 SQL 查询来实现分数排名。
如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。

例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):

select Score,DENSE_RANK() OVER(ORDER BY Score desc) as Rank
from Scores
5. 连续出现的数字
表:Logs
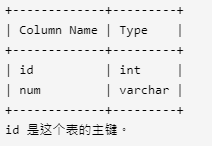
编写一个 SQL 查询,查找所有至少连续出现三次的数字。
返回的结果表中的数据可以按 任意顺序 排列。
查询结果格式如下面的例子所示:

方法一:
如果是连续100次,1000次数值相同,那么这种方法就不适用了
select distinct a.Num as ConsecutiveNums
from Logs a
inner join Logs b
on a.ID = B.ID +1 and a.NUm = b.Num
inner join Logs c
on a.ID = C.ID +2 and b.Num = c.Num
方法二:
SELECT DISTINCT Num as ConsecutiveNums
FROM (SELECT Num,COUNT(1) as SerialCount
FROM (SELECT Id,Num,row_number() over(order by id) -ROW_NUMBER() over(partition by Num order by Id) as SerialNumberSubGroup
FROM Logs) as Sub
GROUP BY Num,SerialNumberSubGroup HAVING COUNT(1) >= 3) as Result
6. 超过经理收入的员工
Employee 表包含所有员工,他们的经理也属于员工。每个员工都有一个 Id,此外还有一列对应员工的经理的 Id。

给定 Employee 表,编写一个 SQL 查询,该查询可以获取收入超过他们经理的员工的姓名。在上面的表格中,Joe 是唯一一个收入超过他的经理的员工。

7. 重新
if object_id('department','u') is not null drop table department
create table department (
id int
,revenue INT
,MONTH VARCHAR(10)
)
INSERT INTO DEPARTMENT(id,REVENUE,MONTH)
VALUES
(1,8000 , 'Jan' )
,(2,9000 , 'Jan' )
,(3,10000 , 'Feb' )
,(1,7000 , 'Feb' )
,(1,6000 , 'Mar' )
select id
,sum(case when month = 'Jan' then revenue else null end) as jan_revenue
,sum(case when month = 'Feb' then revenue else null end) as Feb_revenue
,sum(case when month = 'Mar' then revenue else null end) as Mar_revenue
,sum(case when month = 'Apr' then revenue else null end) as Apr_revenue
,sum(case when month = 'May' then revenue else null end) as May_revenue
,sum(case when month = 'Jun' then revenue else null end) as Jun_revenue
,sum(case when month = 'Jul' then revenue else null end) as Jul_revenue
,sum(case when month = 'Aug' then revenue else null end) as Aug_revenue
,sum(case when month = 'Sep' then revenue else null end) as Sep_revenue
,sum(case when month = 'Oct' then revenue else null end) as Oct_revenue
,sum(case when month = 'Nov' then revenue else null end) as Nov_revenue
,sum(case when month = 'Dec' then revenue else null end) as Dec_revenue
from DEPARTMENT
group by id
8. 寻找用户推荐人
给定表 customer ,里面保存了所有客户信息和他们的推荐人。
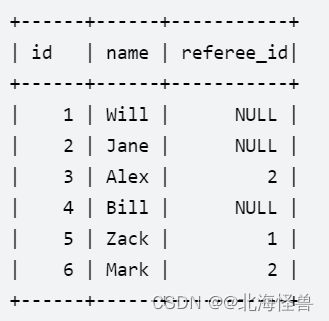
写一个查询语句,返回一个客户列表,列表中客户的推荐人的编号都 不是 2。
对于上面的示例数据,结果为:

--方法一:执行耗时852ms
select name
from customer
where isnull(referee_id,0) <> 2
--方法二:执行耗时1038ms
select name
from customer
where id not in (
select id from customer where referee_id = 2
)
9. 销售员


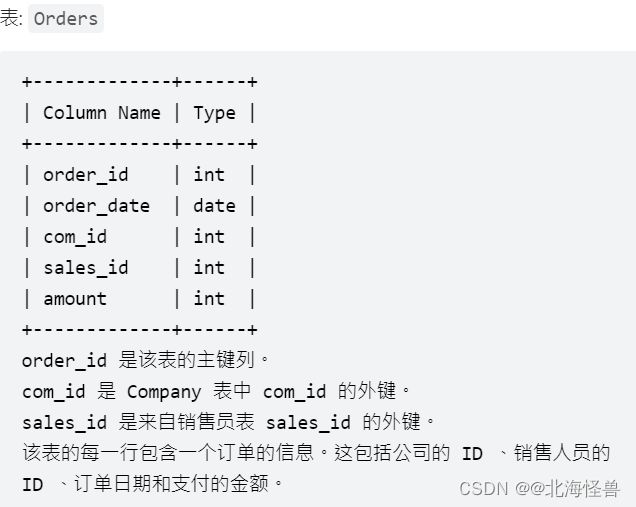
编写一个SQL查询,报告没有任何与名为 “RED” 的公司相关的订单的所有销售人员的姓名。
以 任意顺序 返回结果表。
--方法一:运行耗时903ms
SELECT s.name
FROM salesperson s
WHERE s.sales_id NOT IN (SELECT
o.sales_id
FROM orders o
LEFT JOIN company c
ON o.com_id = c.com_id
WHERE c.name = 'RED')
;
10. 排名靠前的旅行者
表:Users

表:Rides

写一段 SQL , 报告每个用户的旅行距离。
返回的结果表单,以 travelled_distance 降序排列 ,如果有两个或者更多的用户旅行了相同的距离, 那么再以 name 升序排列 。
查询结果格式如下例所示。
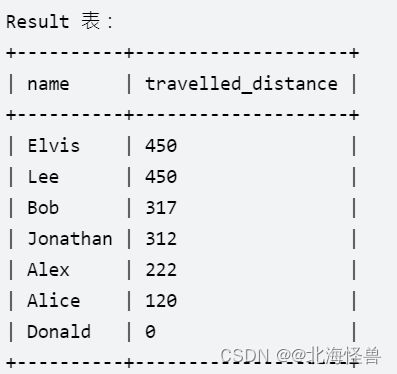
select name,travelled_distance from (
select b.id,b.name,isnull(sum(distance),0) as travelled_distance
from users b
left join rides a
on a.user_id = b.id
group by b.id,b.name ) a
order by travelled_distance desc,name asc
11. 患某种疾病的患者
患者信息表: Patients

写一条 SQL 语句,查询患有 I 类糖尿病的患者 ID (patient_id)、患者姓名(patient_name)以及其患有的所有疾病代码(conditions)。I 类糖尿病的代码总是包含前缀 DIAB1 。
按 任意顺序 返回结果表。
select *
from patients
where conditions like 'DIAB1%'
or conditions like '% DIAB1%'
12. 修复表中的名字
表: Users

编写一个 SQL 查询来修复名字,使得只有第一个字符是大写的,其余都是小写的。
返回按 user_id 排序的结果表。
select user_id,
concat(upper(left(name, 1)), lower(right(name, len(name) - 1))) name
from Users
order by user_id
13. 求关注者的数量
表: Followers

写出 SQL 语句,对于每一个用户,返回该用户的关注者数量。
按 user_id 的顺序返回结果表。
select user_id ,isnull(count(*),0) as followers_count
from Followers
group by user_id
14. 可回收且低脂的产品
表:Products

写出 SQL 语句,查找既是低脂又是可回收的产品编号。
返回结果 无顺序要求 。
select product_id from Products
where low_fats ='Y' and recyclable ='Y'
15. 计算特殊奖金
表: Employees

写出一个SQL 查询语句,计算每个雇员的奖金。如果一个雇员的id是奇数并且他的名字不是以’M’开头,那么他的奖金是他工资的100%,否则奖金为0。
Return the result table ordered by employee_id.
返回的结果集请按照employee_id排序。
select employee_id
,case when employee_id % 2 = 1 and left(name ,1) <>'M'
then salary else 0 end as bonus
from Employees
order by employee_id
16. 丢失信息的雇员
表: Employees

表: Salaries

写出一个查询语句,找到所有 丢失信息 的雇员id。当满足下面一个条件时,就被认为是雇员的信息丢失:
雇员的 姓名 丢失了,或者
雇员的 薪水信息 丢失了,或者
返回这些雇员的id employee_id , 从小到大排序 。
select employee_id from
(
select employee_id from Employees
union all
select employee_id from Salaries
)as t
group by employee_id
having count(employee_id) = 1
order by employee_id
17. 每个产品在不同商店的价格
表:Products

请你重构 Products 表,查询每个产品在不同商店的价格,使得输出的格式变为(product_id, store, price) 。如果这一产品在商店里没有出售,则不输出这一行。
输出结果表中的 顺序不作要求 。
select *from (
select product_id,store,price
from Products
unpivot(price for store in(store1 ,store2,store3 )) c)a
where price is not null
18. 文章浏览
请编写一条 SQL 查询以找出所有浏览过自己文章的作者,结果按照 id 升序排列。
查询结果的格式如下所示:

--distinct 去重
select distinct author_id as id
from Views
where author_id = viewer_id
order by author_id
--group by 去重
select author_id as id
from Views
where author_id = viewer_id
group by author_id
order by author_id
19. 上升的温度
编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 不要求顺序 。
查询结果格式如下例。

select a.id from weather a
left join weather b
on a.recordDate = dateadd(day,1,b.recordDate)
where a.temperature > b.temperature
20. 按日期分组销售产品
编写一个 SQL 查询来查找每个日期、销售的不同产品的数量及其名称。
每个日期的销售产品名称应按词典序排列。
返回按 sell_date 排序的结果表。
查询结果格式如下例所示。
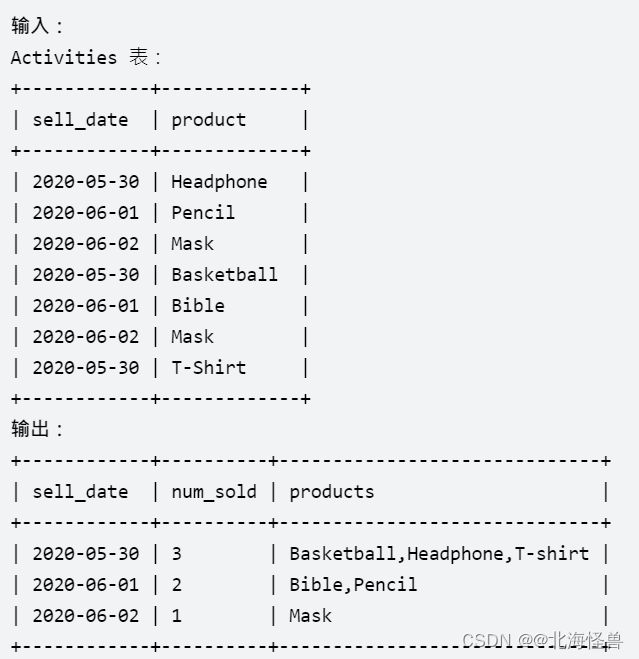
--MS SQL SERVER
select sell_date ,count(distinct product) as num_sold
,STUFF((select distinct ','+product
from activities B
where A.sell_date = B.sell_date
FOR XML PATH('')),1,1,'') as products
from activities a
group by sell_date
--MySQL
select
sell_date,
count(distinct product) as num_sold,
group_concat(distinct product order by product separator ',') as products
from Activities
group by sell_date
order by sell_date;
21. 员工奖金
选出所有 bonus < 1000 的员工的 name 及其 bonus。
--建表
if object_id('Employee','u') is not null drop table Employee
go
create table Employee(
empId int, name varchar(20), supervisor int , salary int
)
go
insert into Employee
values
(1 ,'John' ,3 , 1000 )
,(2 ,'Dan' ,3 , 2000 )
,(3 ,'Brad' ,null , 4000 )
,(4 ,'Thomas' ,3 , 4000 )
go
if object_id('Bonus','u') is not null drop table Bonus
go
create table Bonus (
empId int , bonus int
)
go
insert into Bonus
values
(2 ,500 )
,(4 ,2000)
go
--查询
select a.name,b.bonus
from employee a
left join bonus b
on a.empid = b.empid
where isnull(b.bonus,0) < 1000
22. 使用唯一标识码替换员工Id
写一段SQL查询来展示每位用户的 唯一标识码(unique ID );如果某位员工没有唯一标识码,使用 null 填充即可。
你可以以 任意 顺序返回结果表。
--建表
if object_id('Employees','u') is not null drop table Employees
go
create table Employees (
id int
, name varchar(20)
)
go
insert into Employees
values
(1 ,'Alice' )
,(7 ,'Bob' )
,(11 ,'Meir' )
,(90 ,'Winston' )
,(3 ,'Jonathan' )
go
if object_id('EmployeeUNI','u') is not null drop table EmployeeUNI
go
create table EmployeeUNI(
id int
, unique_id int
)
go
insert into EmployeeUNI
values
(3 , 1 )
,(11 , 2 )
,(90 , 3 )
go
--查询
select b.unique_id,a.name
from Employees a
left join EmployeeUNI b
on a.id = b.id
23. 订单最多的客户
编写一个SQL查询,为下了 最多订单 的客户查找 customer_number 。
测试用例生成后, 恰好有一个客户 比任何其他客户下了更多的订单。
--建表
if object_id('Orders','u') is not null drop table Orders
go
create table Orders(
order_number int
, customer_number int
)
go
insert into Orders
values
(1 ,1 )
,(2 ,2 )
,(3 ,3 )
,(4 ,3 )
go
--查询
--方法一
select customer_number from (
select *,row_number() over(order by cnt desc ) as rnk
from (select customer_number ,count(distinct order_number) as cnt
from Orders
group by customer_number ) a ) a
where rnk = 1
--方法二
select top 1 customer_number
from orders
group by customer_number
order by count(order_number) desc
24. 判断三角形
写一个SQL查询,每三个线段报告它们是否可以形成一个三角形。
以 任意顺序 返回结果表。
--建表
if object_id('Triangle','u') is not null drop table Triangle
go
create table Triangle(
x int
,y int
,z int
)
go
insert into Triangle
values
( 13, 15 ,30 )
,( 10, 20 ,15 )
go
--查询
select *,
case when x+y>z and x+z>y and y+z >x then 'Yes' else 'No' END as triangle
FROM Triangle
25. 只出现一次的最大数字
单一数字 是在 MyNumbers 表中只出现一次的数字。
请你编写一个 SQL 查询来报告最大的 单一数字 。如果不存在 单一数字 ,查询需报告 null 。
if object_id('MyNumbers','u') is not null drop table MyNumbers
go
create table MyNumbers (
num int
)
go
insert into MyNumbers
values
( 8 )
,( 8 )
,( 3 )
,( 3 )
,( 1 )
,( 4 )
,( 5 )
,( 6 )
go
--查询
select max(num) as num
from (select num
from MyNumbers
group by num
having count(*) = 1 ) a
26. 平均售价
编写SQL查询以查找每种产品的平均售价。
average_price 应该四舍五入到小数点后两位。
--建表
if object_id('Prices','u') is not null drop table Prices
go
create table Prices(
product_id int
, start_date date
, end_date date
, price int
)
go
insert into Prices
values
(1 ,'2019-02-17','2019-02-28', 5 )
,(1 ,'2019-03-01','2019-03-22', 20 )
,(2 ,'2019-02-01','2019-02-20', 15 )
,(2 ,'2019-02-21','2019-03-31', 30 )
go
if object_id('UnitsSold','u') is not null drop table UnitsSold
go
create table UnitsSold (
product_id int
,purchase_date date
, units int
)
go
insert into UnitsSold
values
(1 ,'2019-02-25', 100)
,(1 ,'2019-03-01', 15 )
,(2 ,'2019-02-10', 200)
,(2 ,'2019-03-22', 30 )
go
--查询
select product_id ,cast(sum(price * units ) * 1.0 /sum(units) as decimal(19,2)) average_price
from (
select a.*,b.units
from Prices a
left join UnitsSold b
on a.product_id = b.product_id
and b.purchase_date between a.start_date and a.end_date ) a
group by product_id
27. 查找拥有有效邮箱的用户
写一条 SQL 语句,查询拥有有效邮箱的用户。
有效的邮箱包含符合下列条件的前缀名和域名:
前缀名是包含字母(大写或小写)、数字、下划线 ‘_’、句点 ‘.’ 和/或横杠 ‘-’ 的字符串。前缀名必须以字母开头。
域名是 ‘@leetcode.com’ 。
按任意顺序返回结果表。
难度:中等
1.股票的资本损益
Stocks 表:

编写一个SQL查询来报告每支股票的资本损益。
股票的资本损益是一次或多次买卖股票后的全部收益或损失。
以任意顺序返回结果即可。
SELECT stock_name,
SUM(
CASE operation WHEN 'sell'
THEN price ELSE -price
END
) AS capital_gain_loss
FROM Stocks
GROUP BY stock_name
2. 当选者
编写一个SQL查询来报告获胜候选人的名字(即获得最多选票的候选人)。
生成测试用例以确保 只有一个候选人赢得选举。
查询结果格式如下所示。


--MS SQL Server
select name
from Candidate
where id in (
select candidateId
from (select top 1 candidateId,count(*) as cnt
from vote
group by candidateId
order by count(*) desc)a
)
--MySQL
select Name from Candidate
where id =(
select CandidateId from Vote
group by CandidateId
order by count(CandidateId) desc limit 1)
3. 页面推荐


写一段 SQL 向user_id = 1 的用户,推荐其朋友们喜欢的页面。不要推荐该用户已经喜欢的页面。
你返回的结果中不应当包含重复项。
select distinct page_id as recommended_page
from Likes
where user_id in (select user2_id
from (select user1_id , user2_id from friendship
union
select user2_id ,user1_id from friendship) a
where user1_id = 1 )
and page_id not in (select page_id from Likes where user_id = 1 )
4. 2016年的投资
写一个查询语句,将 2016 年 (TIV_2016) 所有成功投资的金额加起来,保留 2 位小数。
对于一个投保人,他在 2016 年成功投资的条件是:
他在 2015 年的投保额 (TIV_2015) 至少跟一个其他投保人在 2015 年的投保额相同。
他所在的城市必须与其他投保人都不同(也就是说维度和经度不能跟其他任何一个投保人完全相同)。
IF OBJECT_ID('insurance','U') IS NOT NULL DROP TABLE insurance
GO
CREATE TABLE insurance(
PID INT
,TIV_2015 NUMERIC(15,2)
,TIV_2016 NUMERIC(15,2)
,LAT NUMERIC(5,2)
,LON NUMERIC(5,2)
)
GO
INSERT INTO insurance
VALUES
( 1 , 224.17 , 952.73 , 32.4 , 20.2 )
,( 2 , 224.17 , 900.66 , 52.4 , 32.7 )
,( 3 , 824.61 , 645.13 , 72.4 , 45.2 )
,( 4 , 424.32 , 323.66 , 12.4 , 7.7 )
,( 5 , 424.32 , 282.9 , 12.4 , 7.7 )
,( 6 , 625.05 , 243.53 , 52.5 , 32.8 )
,( 7 , 424.32 , 968.94 , 72.5 , 45.3 )
,( 8 , 624.46 , 714.13 , 12.5 , 7.8 )
,( 9 , 425.49 , 463.85 , 32.5 , 20.3 )
,( 10 , 624.46 , 776.85 , 12.4 , 7.7 )
,( 11 , 624.46 , 692.71 , 72.5 , 45.3 )
,( 12 , 225.93 , 933 , 12.5 , 7.8 )
,( 13 , 824.61 , 786.86 , 32.6 , 20.3 )
,( 14 , 824.61 , 935.34 , 52.6 , 32.8 )
select cast(sum(TIV_2016) as numeric(15,2)) as TIV_2016
from (SELECT *,COUNT(*) over(partition by TIV_2015 ) as cnt1
FROM (SELECT PID,TIV_2015,TIV_2016,LAT,LON ,COUNT(*) OVER(PARTITION BY LAT,LON) AS CNT
FROM insurance
GROUP BY PID,TIV_2015,TIV_2016,LAT,LON) A
WHERE CNT = 1
GROUP BY PID,TIV_2015,TIV_2016,LAT,LON,cnt ) a
where cnt1 >= 2
5. 买下所有产品的人
写一条 SQL 查询语句,从 Customer 表中查询购买了 Product 表中所有产品的客户的 id。
if object_id('Customer','u') is not null drop table Customer
go
create table Customer(
customer_id int ,
product_key int
)
go
insert into Customer
values
(1 , 5 )
,(2 , 6 )
,(3 , 5 )
,(3 , 6 )
,(1 , 6 )
go
if object_id ('Product','u') is not null drop table Product
go
create table Product(
product_key int
)
go
insert into Product
values
(5)
,(6)
go
select a.customer_id
from Customer a
group by a.customer_id
having count( distinct a.product_key ) = (select count(*) from Product)
6. 电影评分
请你编写一组 SQL 查询:
查找评论电影数量最多的用户名。如果出现平局,返回字典序较小的用户名。
查找在 February 2020 平均评分最高 的电影名称。如果出现平局,返回字典序较小的电影名称。
字典序 ,即按字母在字典中出现顺序对字符串排序,字典序较小则意味着排序靠前。
select name as results from (
select a.user_id,b.name,rank() over(order by count(*) desc) as rnk1
,row_number() over(order by b.name ) as rnk
from MovieRating a
left join Users b
on a.user_id = b.user_id
group by a.user_id ,b.name ) a
where rnk1 = 1 and rnk = 1
union all
select title from (
select b.title ,sum(rating)*1.0/count(*) as Score
,rank() over(order by count(*) desc) as rnk1
,row_number() over(order by b.title ) as rnk
from MovieRating a
left join Movies b
on a.movie_id = b.movie_id
where left(created_at,7) = '2020-02'
group by b.title ) a
where rnk1 = 1 and rnk = 1
6. 确认率
用户的 确认率 是 ‘confirmed’ 消息的数量除以请求的确认消息的总数。没有请求任何确认消息的用户的确认率为 0 。确认率四舍五入到 小数点后两位 。
编写一个SQL查询来查找每个用户的 确认率 。
以 任意顺序 返回结果表。
if object_id('Signups','u') is not null drop table Signups
go
create table Signups (
user_id int
, time_stamp datetime
)
go
insert into Signups
values
(3 ,'2020-03-21 10:16:13')
,(7 ,'2020-01-04 13:57:59')
,(2 ,'2020-07-29 23:09:44')
,(6 ,'2020-12-09 10:39:37')
go
if object_id ('Confirmations','u') is not null drop table Confirmations
go
create table Confirmations(
user_id int
, time_stamp datetime
, action varchar(20) )
go
insert into Confirmations
values
( 3 , '2021-01-06 03:30:46', 'timeout' )
,( 3 , '2021-07-14 14:00:00', 'timeout' )
,( 7 , '2021-06-12 11:57:29', 'confirmed')
,( 7 , '2021-06-13 12:58:28', 'confirmed')
,( 7 , '2021-06-14 13:59:27', 'confirmed')
,( 2 , '2021-01-22 00:00:00', 'confirmed')
,( 2 , '2021-02-28 23:59:59', 'timeout' )
go
--Output
select a.user_id
, cast(sum(case when b.action = 'confirmed' then 1 else 0 end )*1.0/count(*) as decimal(19,2)) as confirmation_rate
from Signups a
left join Confirmations b
on a.user_id = b.user_id
group by a.user_id
order by a.user_id
7. 按分类统计薪水
写出一个 SQL 查询,来报告每个工资类别的银行账户数量。 工资类别如下:
“Low Salary”:所有工资 严格低于 20000 美元。
“Average Salary”: 包含 范围内的所有工资 [$20000, $50000] 。
“High Salary”:所有工资 严格大于 50000 美元。
结果表 必须 包含所有三个类别。 如果某个类别中没有帐户,则报告 0 。
按 任意顺序 返回结果表。
if object_id('Accounts','u') is not null drop table Accounts
go
create table Accounts (
account_id int
,income int
)
go
insert into Accounts
values
(3 , 108939 )
,(2 , 12747 )
,(8 , 87709 )
,(6 , 91796 )
go
select * from Accounts
with t as (
select 'Low Salary' as Category
union
select 'Average Salary'
union
select 'High Salary'
)
select a.Category ,isnull(count(b.Category),0) as accounts_count
from t a
left join (select *,case when income < 20000 then'Low Salary'
when income between 20000 and 50000 then 'Average Salary'
else 'High Salary' end as Category
from Accounts) b
on a.category = b.category
group by a.category
8. 餐馆营业额的变化增长
你是餐馆的老板,现在你想分析一下可能的营业额变化增长(每天至少有一位顾客)。
写一条 SQL 查询计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值。average_amount 要 保留两位小数。
查询结果按 visited_on 排序。
SELECT visited_on,amount,average_amount
FROM (
SELECT visited_on,
SUM(amount) OVER (ORDER BY visited_on ROWS 6 PRECEDING) AS amount,
ROUND(AVG(amount)OVER(ORDER BY visited_on ROWS 6 PRECEDING),2) AS average_amount
FROM (
SELECT visited_on,SUM(amount) AS amount
FROM Customer
GROUP BY visited_on
) TABLE_1
) TABLE_2
WHERE DATEDIFF(day,(SELECT MIN(visited_on) FROM Customer) , visited_on) >=6
SELECT TOP 1 person_name
FROM (
SELECT *,
SUM(weight) OVER (ORDER BY turn ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS curr_weight
FROM Queue) t
WHERE curr_weight <= 1000
ORDER BY curr_weight DESC
8. 即时食物配送
如果顾客期望的配送日期和下单日期相同,则该订单称为 「即时订单」,否则称为「计划订单」。
「首次订单」是顾客最早创建的订单。我们保证一个顾客只会有一个「首次订单」。
写一条 SQL 查询语句获取即时订单在所有用户的首次订单中的比例。保留两位小数。
if object_id ('Delivery','u') is not null drop table Delivery
go
create table Delivery (
delivery_id int
,customer_id int
, order_date date
,customer_pref_delivery_date date
)
go
insert into Delivery
values
( 1 ,1 , '2019-08-01' ,'2019-08-02')
,( 2 ,2 , '2019-08-02' ,'2019-08-02')
,( 3 ,1 , '2019-08-11' ,'2019-08-12')
,( 4 ,3 , '2019-08-24' ,'2019-08-24')
,( 5 ,3 , '2019-08-21' ,'2019-08-22')
,( 6 ,2 , '2019-08-11' ,'2019-08-13')
,( 7 ,4 , '2019-08-09' ,'2019-08-09')
go
select cast(sum(case when order_date = customer_pref_delivery_date then 1 else 0 end )
* 1.0 /count(*)*100 as decimal(19,2))
as immediate_percentage
from (select *
,row_number() over(Partition by customer_id order by order_date ) as rnk
from Delivery) a
where rnk = 1
9. 至少有5名直系下属的经理
编写一个SQL查询,查询至少有5名直接下属的经理 。
以 任意顺序 返回结果表。
--建表
if object_id('Employee','u') is not null drop table Employee
go
create table Employee (
id int
, name varchar(20)
, department varchar(20)
, managerId int
)
go
insert into Employee
values
(101 ,'John' ,'A', null )
,(102 ,'Dan' ,'A', '101' )
,(103 ,'James' ,'A', '101' )
,(104 ,'Amy' ,'A', '101' )
,(105 ,'Anne' ,'A', '101' )
,(106 ,'Ron' ,'B', '101' )
go
--方法一
select distinct name from Employee
where id in (
select managerid
from Employee
group by managerid
having count(distinct id ) >= 5)
--方法二
SELECT
Name
FROM
Employee AS t1 JOIN
(SELECT
ManagerId
FROM
Employee
GROUP BY ManagerId
HAVING COUNT(ManagerId) >= 5) AS t2
ON t1.Id = t2.ManagerId
10. 游戏玩法分析
编写一个 SQL 查询,报告在首次登录的第二天再次登录的玩家的比率,四舍五入到小数点后两位。换句话说,您需要计算从首次登录日期开始至少连续两天登录的玩家的数量,然后除以玩家总数。
--建表
if object_id('Activity','u') is not null drop table Activity
go
create table Activity (
player_id int
, device_id int
, event_date date
, games_played int
)
go
insert into Activity
values
( 1 ,2 ,'2016-03-01',5 )
,( 1 ,2 ,'2016-03-02',6 )
,( 2 ,3 ,'2017-06-25',1 )
,( 3 ,1 ,'2016-03-02',0 )
,( 3 ,4 ,'2018-07-03',5 )
go
--查询
with t as (select player_id id,min(event_date) mn
from activity
group by player_id)
select convert(decimal(4,2),(
select convert(float,count(0))
from t b
inner join activity a
on b.id=a.player_id and datediff(d,b.mn,a.event_date)=1
) / (select count(0) from t)) fraction
11. 好友申请:谁有最多的好友
在 Facebook 或者 Twitter 这样的社交应用中,人们经常会发好友申请也会收到其他人的好友申请。
写一个查询语句,找出拥有最多的好友的人和他拥有的好友数目。
生成的测试用例保证拥有最多好友数目的只有 1 个人。
--建表
if object_id('RequestAccepted','u') is not null drop table RequestAccepted
go
create table RequestAccepted(
requester_id int
, accepter_id int
, accept_date date
)
go
insert into RequestAccepted
values
(1 , 2 ,'2016/06/03')
,(1 , 3 ,'2016/06/08')
,(2 , 3 ,'2016/06/08')
,(3 , 4 ,'2016/06/09')
go
--查询
select top 1 requester_id as id ,count(*) as num
from (
select requester_id,accepter_id
from RequestAccepted
union
select accepter_id,requester_id
from RequestAccepted )a
group by requester_id
order by count(*) desc
12. 指定日期的产品价格
写一段 SQL来查找在 2019-08-16 时全部产品的价格,假设所有产品在修改前的价格都是 10 。
以 任意顺序 返回结果表。
--建表
if object_id('Products','u') is not null drop table Products
go
create table Products(
product_id int
, new_price int
, change_date date
)
go
insert into Products
values
( 1 ,20 ,'2019-08-14')
,( 2 ,50 ,'2019-08-14')
,( 1 ,30 ,'2019-08-15')
,( 1 ,35 ,'2019-08-16')
,( 2 ,65 ,'2019-08-17')
,( 3 ,20 ,'2019-08-18')
go
--查询
with t as (
select * from (
select *,row_number() over(partition by product_id order by change_date desc ) as rnk
from Products
where change_date <= '2019-08-16') a
where rnk = 1
)
select distinct a.Product_id ,isnull(b.new_price,10) as Price
from Products a
left join T B
ON a.product_id = b.product_id
13. 每月交易
编写一个 sql 查询来查找每个月和每个国家/地区的事务数及其总金额、已批准的事务数及其总金额。
以 任意顺序 返回结果表。
-- 建表
if object_id('Transactions','u') is not null drop table Transactions
go
create table Transactions(
id int
,country varchar (100)
,state varchar(100)
,amount int
,trans_date date
)
go
insert into Transactions
values
( 121 ,'US','approved', 1000,'2018-12-18')
,( 122 ,'US','declined', 2000,'2018-12-19')
,( 123 ,'US','approved', 2000,'2019-01-01')
,( 124 ,'DE','approved', 2000,'2019-01-07')
go
--查询
SELECT LEFT(trans_date ,7) AS month , country
,COUNT(*) AS trans_count
,SUM(CASE WHEN STATE = 'approved' THEN 1 ELSE 0 END )AS approved_count
,SUM(AMOUNT) AS trans_total_amount
,SUM(CASE WHEN STATE = 'approved' THEN AMOUNT ELSE 0 END ) AS approved_total_amount
FROM Transactions
GROUP BY LEFT(trans_date ,7) , country
14.市场分析
请写出一条SQL语句以查询每个用户的注册日期和在 2019 年作为买家的订单总数。
以 任意顺序 返回结果表。
if object_id('Users','u') is not null drop table Users
go
create table Users(
user_id int
,join_date date
,favorite_brand varchar(20)
)
go
insert into Users
values
(1 ,'2018-01-01', 'Lenovo' )
,(2 ,'2018-02-09', 'Samsung' )
,(3 ,'2018-01-19', 'LG' )
,(4 ,'2018-05-21', 'HP' )
go
if object_id ('Orders','u') is not null drop table Orders
go
create table Orders(
order_id int
,order_date date
,item_id int
,buyer_id int
,seller_id int
)
go
insert into Orders
values
(1 ,'2019-08-01',4 ,1 ,2 )
,(2 ,'2018-08-02',2 ,1 ,3 )
,(3 ,'2019-08-03',3 ,2 ,3 )
,(4 ,'2018-08-04',1 ,4 ,2 )
,(5 ,'2018-08-04',1 ,3 ,4 )
,(6 ,'2019-08-05',2 ,2 ,4 )
go
if object_id('Items','u') is not null drop table Items
go
create table Items(
item_id int
,item_brand varchar(20)
)
go
insert into Items
values
(1 ,'Samsung' )
,(2 ,'Lenovo' )
,(3 ,'LG' )
,(4 ,'HP' )
go
--查询
--方法一
select a.user_id as buyer_id ,a.join_date,isnull(b.num,0) as orders_in_2019
from Users a
left join (select buyer_id ,sum(case when left(order_date,4) = 2019 then 1 else 0 end ) as num
from Orders
group by buyer_id) b
on a.user_id = b.buyer_id
--方法二
SELECT Users.user_id AS buyer_id, join_date,
COUNT(CASE WHEN YEAR(Orders.order_date) = 2019 THEN 1 END) AS orders_in_2019
FROM Users
LEFT OUTER JOIN Orders
ON Users.user_id = Orders.buyer_id
GROUP BY Users.user_id,join_date
ORDER BY Users.user_id
难度:困难
1. 部门工资前三高的所有员工
Employee 表包含所有员工信息,每个员工有其对应的工号 Id,姓名 Name,工资 Salary 和部门编号 DepartmentId 。
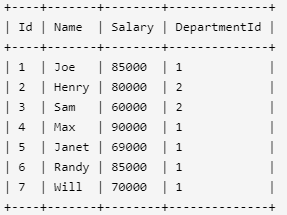
Department 表包含公司所有部门的信息。
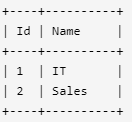
编写一个 SQL 查询,找出每个部门获得前三高工资的所有员工。例如,根据上述给定的表,查询结果应返回:
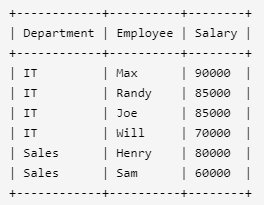
解释:
IT部门中,Max获得了最高的工资,Randy和Joe都拿到了第二高的工资,Will的工资排第三。销售部门(Sales)只有两名员工,Henry的工资最高,Sam的工资排第二。
select b.Name as Department,a.Name as Employee,a.Salary
from (select *,dense_rank() over(partition by departmentid order by Salary desc) as rnk from Employee) a
left join department b
on a.departmentid = b.Id
where a.rnk <= 3
2. 行程和用户
表:Trips

表:Users

3. 体育馆的人流量
编写一个 SQL 查询以找出每行的人数大于或等于 100 且 id 连续的三行或更多行记录。
返回按 visit_date 升序排列的结果表。
if object_id('stadium','u') is not null drop table stadium
create table stadium(
id int identity(1,1)
,visit_date date
,people int
)
insert into stadium(visit_date, people)
values
('2017-01-01' , 10 )
,('2017-01-02' , 109 )
,('2017-01-03' , 150 )
,('2017-01-04' , 99 )
,('2017-01-05' , 145 )
,('2017-01-06' , 1455 )
,('2017-01-07' , 199 )
,('2017-01-09' , 188 )
select id,visit_date,people
from (
select id, visit_date, people, count(*) over (partition by (fz)) as cnt
from (
select *, id - row_number() over (order by id ) as fz
from stadium
where people >= 100
) a
) a
where cnt > 3
4. 员工薪水的中位数
写一个SQL查询,找出每个公司的工资中位数。
以 任意顺序 返回结果表。
查询结果格式如下所示。
Employee表:

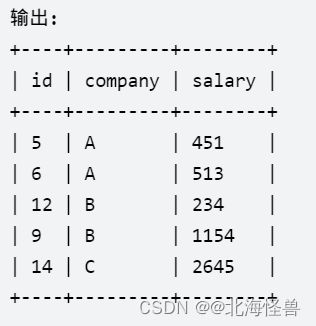
--方法一:
--注意事项:排序时用row_number,会有排名相同的情况
--中位数的逻辑了解:不论个数是奇数偶数,中位数在总数除以2和总数除以2加1之间
select id ,company,salary
from (
select *
,row_number() over(partition by company order by salary) as rnk
,count(*) over(partition by company ) as cnt
from Employee) a
where rnk BETWEEN cnt*1.0/2 AND cnt*1.0/2 + 1
5. 同一天的第一个电话和最后一个电话
编写一个 SQL 查询来找出那些ID们在任意一天的第一个电话和最后一个电话都是和同一个人的。这些电话不论是拨打者还是接收者都会被记录。
结果请放在一个任意次序约束的表中。
查询结果格式如下所示:

--MySQL
with temp as (select * from calls
union all
select recipient_id caller_id, caller_id recipient_id, call_time from calls
),
temp1 as (select
*,
dense_rank() over (partition by date_format(call_time,"%Y-%m-%d"),caller_id order by call_time asc) rk1,
dense_rank() over (partition by date_format(call_time,"%Y-%m-%d"),caller_id order by call_time desc) rk2
from temp
)
select
distinct caller_id as user_id
from temp1
where rk1 = 1 or rk2 = 1
group by caller_id, date_format(call_time,"%Y-%m-%d")
having count(distinct recipient_id) = 1
5. 查询员工的累计薪水
Employee 表保存了一年内的薪水信息。
请你编写 SQL 语句,对于每个员工,查询他除最近一个月(即最大月)之外,剩下每个月的近三个月的累计薪水(不足三个月也要计算)。
结果请按 Id 升序,然后按 Month 降序显示。
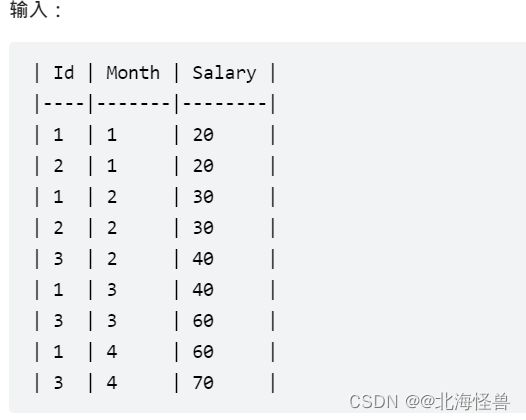
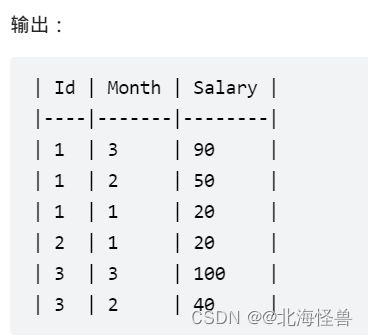
--MySQL
--注意点:剔除最大月要以员工为单位去看,还有就是其他月份算累计只要计算近三个月的
select a.id ,a.month ,sum(b.salary) as Salary
from Employee a
left join Employee b
on a.id = b.id and a.Month >= b.Month and a.Month < b.Month + 3
where (a.Id, a.Month) NOT IN (SELECT Id, MAX(Month) FROM Employee GROUP BY Id)
group by a.id ,a.month
order by id asc ,month desc
--MS SQL Server
WITH T AS (
select id,max(month) as month from Employee group by id
)
select a.id ,a.month ,sum(b.salary) as Salary
from Employee a
left join Employee b
on a.id = b.id and a.Month >= b.Month and a.Month < b.Month + 3
where NOT EXISTS (SELECT * FROM t b where a.id = b.id and a.month = b.month)
group by a.id ,a.month
order by id asc ,month desc
6. 给定数字的频率查询中位数
中位数 是将数据样本中半数较高值和半数较低值分隔开的值。
编写一个 SQL 查询,解压 Numbers 表,报告数据库中所有数字的 中位数 。结果四舍五入至 一位小数 。
查询结果如下例所示。

--中位数逻辑:按大小排序后,不论正序降序排序,中位数的排序都会大于总数的一半
select cast (sum(num)*1.0/count(num) as decimal(19,1)) as median
from
(select Num, frequency,
sum(frequency) over(order by Num asc) as total,
sum(frequency) over(order by Num desc) as total1
from Numbers
)as a
where total>=(select sum(frequency) from Numbers)/2
and total1>=(select sum(frequency) from Numbers)/2
7. 查询员工的累计薪水
Employee 表保存了一年内的薪水信息。
请你编写 SQL 语句,对于每个员工,查询他除最近一个月(即最大月)之外,剩下每个月的近三个月的累计薪水(不足三个月也要计算)。
结果请按 Id 升序,然后按 Month 降序显示。
示例:
输入:
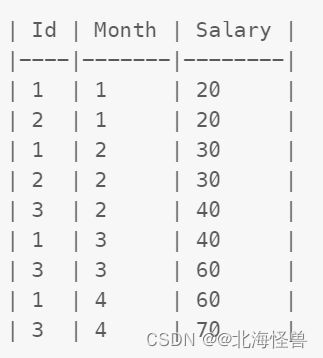
--建表
if object_id('Employee','u') is not null drop table Employee
go
create table Employee (
Id int, Month int, Salary int
)
go
insert into Employee
values
( 1 , 1 , 20 )
,( 2 , 1 , 20 )
,( 1 , 2 , 30 )
,( 2 , 2 , 30 )
,( 3 , 2 , 40 )
,( 1 , 3 , 40 )
,( 3 , 3 , 60 )
,( 1 , 4 , 60 )
,( 3 , 4 , 70 )
go
--查询
with t as (
select *
,row_number() over(partition by id order by month desc) as rnk
from Employee )
select a.id,a.month ,sum(b.salary ) as salary
from T a
left join T b
on a.id = b.id and b.month <= a.month and a.month -3 < b.month
where a.rnk <>1
group by a.id,a.month
order by a.id asc,a.month desc
8. 学生地理信息报告
一所学校有来自亚洲、欧洲和美洲的学生。
写一个查询语句实现对大洲(continent)列的 透视表 操作,使得每个学生按照姓名的字母顺序依次排列在对应的大洲下面。输出的标题应依次为美洲(America)、亚洲(Asia)和欧洲(Europe)。
测试用例的生成使得来自美国的学生人数不少于亚洲或欧洲的学生人数。
--建表
if object_id('student','u') is not null drop table student
go
create table student (
name varchar(20)
, continent varchar(20)
)
go
insert into student
values
( 'Jane' ,'America' )
,( 'Pascal' ,'Europe' )
,( 'Xi' ,'Asia' )
,( 'Jack' ,'America' )
go
--查询
with t as (select * ,row_number() over(partition by continent order by name ) as rnk
from student)
select a.name as America,b.name as Asia,c.name as Europe
from (select distinct rnk from T ) o
left join T a
on a.rnk = o.rnk and a.continent = 'America'
left join T b
on o.rnk = b.rnk and b.continent = 'Asia'
left join T c
on o.rnk = c.rnk and c.continent = 'Europe'
9. 同一天的第一个和最后一个电话
编写一个 SQL 查询来找出那些ID们在任意一天的第一个电话和最后一个电话都是和同一个人的。这些电话不论是拨打者还是接收者都会被记录。
结果请放在一个任意次序约束的表中。
--建表
if object_id ('Calls','u') is not null drop table Calls
go
create table Calls(
caller_id int
, recipient_id int
, call_time datetime
)
go
insert into Calls
values
(8 ,4 ,'2021-08-24 17:46:07')
,(4 ,8 ,'2021-08-24 19:57:13')
,(5 ,1 ,'2021-08-11 05:28:44')
,(8 ,3 ,'2021-08-17 04:04:15')
,(11 ,3 ,'2021-08-17 13:07:00')
,(8 ,11 ,'2021-08-17 22:22:22')
go
--查询
with T as (SELECT caller_id, recipient_id, call_time
FROM Calls
UNION ALL
SELECT recipient_id , caller_id , call_time
FROM Calls )
SELECT DISTINCT a.caller_id user_id
FROM (SELECT caller_id, recipient_id, dense_rank() over (PARTITION BY caller_id, cast(call_time as date) order by call_time) AS rk
FROM T) a
INNER JOIN (SELECT caller_id, recipient_id, dense_rank() over (PARTITION BY caller_id, cast(call_time as date) order by call_time DESC) AS rk
FROM T) b
ON a.caller_id = b.caller_id AND a.recipient_id = b.recipient_id AND a.rk = 1 AND b.rk = 1
10. 职员招聘人数
一家公司想雇佣新员工。公司的工资预算是 70000 美元。公司的招聘标准是:
雇佣最多的高级员工。
在雇佣最多的高级员工后,使用剩余预算雇佣最多的初级员工。
编写一个SQL查询,查找根据上述标准雇佣的高级员工和初级员工的数量。
按 任意顺序 返回结果表。

--建表
if object_id('Candidates','u') is not null drop table Candidates
go
create table Candidates(
employee_id int
, experience varchar(20)
, salary int
)
go
insert into Candidates
values
( 1 ,'Junior' ,10000)
,( 9 ,'Junior' ,10000)
,( 2 ,'Senior' ,20000)
,( 11 ,'Senior' ,20000)
,( 13 ,'Senior' ,50000)
,( 4 ,'Junior' ,40000)
go
--查询
WITH SeniorTotal AS
(SELECT employee_id, SUM(salary) OVER (ORDER BY salary) AS totalone
FROM Candidates
WHERE experience = 'Senior'),
SeniorNumber AS
(SELECT MAX(totalone) totals
FROM SeniorTotal
WHERE totalone <= 70000),
JuniorTotal AS
(SELECT employee_id, SUM(salary) OVER (ORDER BY salary) AS totaltwo
FROM Candidates
WHERE experience = 'Junior')
SELECT 'Senior' AS experience, COUNT(DISTINCT employee_id) AS accepted_candidates
FROM SeniorTotal
WHERE totalone <= 70000
UNION ALL
SELECT 'Junior' AS experience, COUNT(DISTINCT employee_id) AS accepted_candidates
FROM JuniorTotal, SeniorNumber
WHERE totaltwo < 70000 - isnull(totals, 0)
11. 职员招聘人数 ②
一家公司想雇佣新员工。公司的工资预算是 7 万美元。公司的招聘标准是:
继续雇佣薪水最低的高级职员,直到你不能再雇佣更多的高级职员。
用剩下的预算雇佣薪水最低的初级职员。
继续以最低的工资雇佣初级职员,直到你不能再雇佣更多的初级职员。
编写一个SQL查询,查找根据上述条件雇用职员的 ID。
按 任意顺序 返回结果表。

--建表
if object_id('Candidates','u') is not null drop table Candidates
go
create table Candidates(
employee_id int
, experience varchar(20)
, salary int
)
go
insert into Candidates
values
(1 ,'Junior',10000 )
,(9 ,'Junior',15000 )
,(2 ,'Senior',20000 )
,(11 ,'Senior',16000 )
,(13 ,'Senior',50000 )
,(4 ,'Junior',40000 )
go
--查询
WITH SeniorTotal AS
(SELECT employee_id, SUM(salary) OVER (ORDER BY salary) AS totalone
FROM Candidates
WHERE experience = 'Senior'),
SeniorNumber AS
(SELECT MAX(totalone) totals
FROM SeniorTotal
WHERE totalone <= 70000),
JuniorTotal AS
(SELECT employee_id, SUM(salary) OVER (ORDER BY salary) AS totaltwo
FROM Candidates
WHERE experience = 'Junior')
SELECT DISTINCT employee_id
FROM SeniorTotal
WHERE totalone <= 70000
UNION ALL
SELECT DISTINCT employee_id
FROM JuniorTotal, SeniorNumber
WHERE totaltwo < 70000 - isnull(totals, 0)
12. 找到每篇文章的主题
Leetcode 从其社交媒体网站上收集了一些帖子,并对每个帖子的主题感兴趣。每个主题可以由一个或多个关键字表示。如果某个主题的关键字存在于一个帖子的内容中 (不区分大小写),那么这个帖子就有这个主题。
编写一个 SQL 查询,根据以下规则查找每篇文章的主题:
如果帖子没有来自任何主题的关键词,那么它的主题应该是 “Ambiguous!”。
如果该帖子至少有一个主题的关键字,其主题应该是其主题的 id 按升序排列并以逗号 ‘,’ 分隔的字符串。字符串不应该包含重复的 id。
以 任意顺序 返回结果表。
--建表
if object_id('Keywords','u') is not null drop table Keywords
go
create table Keywords (
topic_id int
, word varchar(20)
)
go
insert into Keywords
values
( 1 ,'handball' )
,( 1 ,'football' )
,( 3 ,'WAR' )
,( 2 ,'Vaccine' )
go
if object_id('Posts','u') is not null drop table Posts
go
create table Posts(
post_id int
,content varchar(100)
)
go
insert into Posts
values
( 1 ,'We call it soccer They call it football hahaha' )
,( 2 ,'Americans prefer basketball while Europeans love handball and football' )
,( 3 ,'stop the war and play handball' )
,( 4 ,'warning I planted some flowers this morning and then got vaccinated' )
go
--查询
with t as (select distinct a.post_id ,a.content,b.topic_id
from Posts a
cross join Keywords b
where charindex(b.word+' ',a.content,1) <> 0
or charindex(' ' + b.word,a.content,1) <> 0 )
select post_id
,(select isnull(stuff((select ',' + cast(topic_id as varchar(20))from T where post_id = a.post_id for xml path('')),1,1,''),'Ambiguous!')) as topic
from Posts a
13. 生成发票
编写一个 SQL 查询来显示价格最高的发票的详细信息。如果两个或多个发票具有相同的价格,则返回 invoice_id 最小的发票的详细信息。
以 任意顺序 返回结果表。
--建表
if object_id('Products','u')
is not null drop table Products
go
create table Products (
product_id int
, price int
)
go
insert into Products
values
( 1 , 100 )
,( 2 , 200 )
go
if object_id('Purchases','u') is not null drop table Purchases
go
create table Purchases(
invoice_id int
,product_id int
,quantity int
)
go
insert into Purchases
values
( 1 ,1 ,2 )
,( 3 ,2 ,1 )
,( 2 ,2 ,3 )
,( 2 ,1 ,4 )
,( 4 ,1 ,10 )
go
--查询
select a.Product_id,a.quantity,sum(a.quantity * p.price) as Price
from Purchases a
left join Products p
on a.product_id = p.product_id
where invoice_id = (select invoice_id
from (select *,row_number() over(order by sumprice desc,invoice_id asc ) as rnk
from (select a.invoice_id,sum(a.quantity * P.price ) as SumPrice
from Purchases a
left join Products P
on a.product_id = P.product_id
group by a.invoice_id) a ) a
where rnk = 1 )
group by a.Product_id, a.quantity
14. 受欢迎度百分比
编写一条 SQL 查询,找出 Meta/Facebook 平台上每个用户的受欢迎度的百分比。受欢迎度百分比定义为用户拥有的朋友总数除以平台上的总用户数,然后乘以 100,并 四舍五入保留 2 位小数 。
返回按照 user1 升序 排序的结果表。
--建表
if object_id('Friends','u') is not null drop table Friends
go
create table Friends (
user1 int
, user2 int
)
go
insert into Friends
values
( 2 , 1 )
,( 1 , 3 )
,( 4 , 1 )
,( 1 , 5 )
,( 1 , 6 )
,( 2 , 6 )
,( 7 , 2 )
,( 8 , 3 )
,( 3 , 9 )
go
--查询
with T as(
select * from friends
union
select user2,user1 from friends
)
select user1
,CAST(round(count(distinct user2) * 1.0 / (select count(distinct user1) from T) * 100,2) AS DECIMAL(19,2)) as percentage_popularity
from T
GROUP BY USER1
order by user1
15. 购买量严格增加的客户
编写一个 SQL 查询,报告 总购买量 每年严格增加的客户 id。
客户在一年内的 总购买量 是该年订单价格的总和。如果某一年客户没有下任何订单,我们认为总购买量为 0。
对于每个客户,要考虑的第一个年是他们 第一次下单 的年份。
对于每个客户,要考虑的最后一年是他们 最后一次下单 的年份。
以 任意顺序 返回结果表。
-- 建表
if object_id ('Orders','u') is not null drop table Orders
go
create table Orders(
order_id int
, customer_id int
, order_date date
, price int
)
go
insert into Orders
values
(1 , 1 ,'2019-07-01',1100 )
,(2 , 1 ,'2019-11-01',1200 )
,(3 , 1 ,'2020-05-26',3000 )
,(4 , 1 ,'2021-08-31',3100 )
,(5 , 1 ,'2022-12-07',4700 )
,(6 , 2 ,'2015-01-01',700 )
,(7 , 2 ,'2017-11-07',1000 )
,(8 , 3 ,'2017-01-01',900 )
,(9 , 3 ,'2018-11-07',900 )
go
--查询
WITH T AS (
select customer_id,datepart(year,order_date) as year,sum(price ) as Price_SUM
,row_number() over(partition by customer_id order by datepart(year,order_date) ) as rnk
from Orders
group by customer_id ,datepart(year,order_date)
)
select distinct a.customer_id
from T a
left join T b
on a.customer_id = b.customer_id and a.rnk = b.rnk+1
where A.customer_id in (
SELECT a.customer_id FROM T a
group by customer_id
having max(year) - min(year ) + 1 = count(distinct year) )
and (a.rnk <> 1 and a.price_sum-b.Price_SUM > 0 )
16. 合并在一个大厅重叠的活动
编写一个 SQL 查询来合并在 同一个大厅举行 的所有重叠活动。如果两个活动 至少有一天 相同,那么它们就是重叠的。
以任意顺序返回结果表。
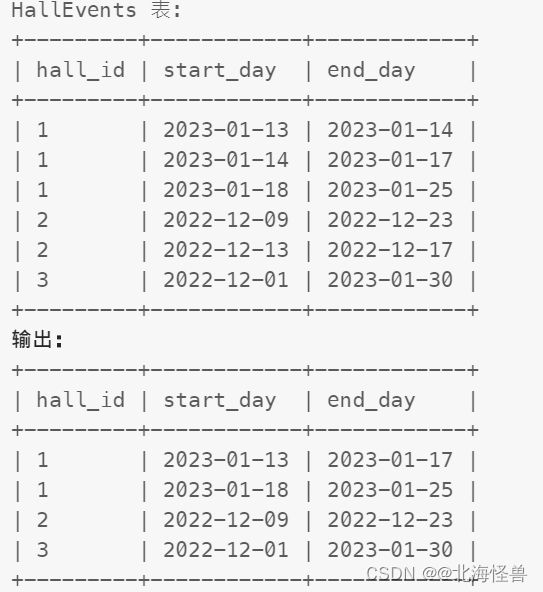
if object_id('HallEvents','u') is not null drop table HallEvents
go
create table HallEvents(
hall_id int
, start_day date
, end_day date
)
go
insert into HallEvents
values
( 2 ,'2022-12-09','2023-01-02')
,( 5 ,'2022-12-01','2022-12-02')
,( 2 ,'2023-01-12','2023-01-14')
,( 3 ,'2022-12-01','2022-12-19')
,( 4 ,'2022-12-29','2022-12-31')
,( 5 ,'2022-12-22','2023-01-18')
,( 5 ,'2022-12-04','2022-12-18')
,( 2 ,'2022-12-29','2023-01-24')
,( 2 ,'2022-12-20','2023-01-09')
,( 6 ,'2022-12-08','2022-12-31')
,( 1 ,'2022-12-14','2022-12-22')
,( 5 ,'2023-01-15','2023-01-27')
,( 1 ,'2022-12-07','2023-01-03')
,( 1 ,'2022-12-30','2023-01-27')
,( 5 ,'2022-12-01','2023-01-22')
,( 3 ,'2022-12-29','2022-12-30')
,( 3 ,'2023-01-04','2023-01-05')
,( 4 ,'2022-12-12','2022-12-17')
,(9 ,'2023-01-26','2023-01-30')
,(9 ,'2023-01-17','2023-01-28')
,(9 ,'2022-12-14','2023-01-16')
,(9 ,'2022-12-15','2023-01-02')
,(9 ,'2022-12-10','2023-01-12')
,(9 ,'2022-12-27','2023-01-06')
go
SELECT hall_id,
MIN(start_day) AS start_day,
MAX(end_day) AS end_day
FROM (
SELECT *,
SUM(range_start) OVER (PARTITION BY hall_id ORDER BY start_day) AS range_grp
FROM (
SELECT *,
CASE WHEN start_day <= LAG(max_end_day_so_far) OVER (PARTITION BY hall_id ORDER BY start_day) THEN 0
ELSE 1 END AS range_start
FROM (
SELECT hall_id,
start_day,
end_day,
MAX(end_day) OVER (PARTITION BY hall_id ORDER BY start_day) AS max_end_day_so_far
FROM HallEvents
) t
) t1
) t2
GROUP BY hall_id, range_grp;
17. 表的动态旋转
实现 PivotProducts 过程来重新组织 Products 表,以便每行都有一个商品的 id 及其在每个商店中的价格。如果商品不在商店出售,价格应为 null。表的列应该包含每个商店,并且它们应该按 字典顺序排序。
过程应该在重新组织表之后返回它。
以 任意顺序 返回结果表。
18. 兴趣相同的朋友
请写一段SQL查询获取到兴趣相同的朋友。用户 x 和 用户 y 是兴趣相同的朋友,需满足下述条件:
用户 x 和 y 是朋友,并且
用户 x and y 在同一天内听过相同的歌曲,且数量大于等于三首.
结果表 无需排序 。注意:返回的结果需要和源数据表的呈现方式相同 (例如, 需满足 user1_id < user2_id)。



--建表
if object_id('Listens','U') is not null drop table
go
create table Listens (
user_id int
, song_id int
, day date
)
go
insert into Listens
values
( 1 ,10 ,'2021-03-15')
,( 1 ,11 ,'2021-03-15')
,( 1 ,12 ,'2021-03-15')
,( 2 ,10 ,'2021-03-15')
,( 2 ,11 ,'2021-03-15')
,( 2 ,12 ,'2021-03-15')
,( 3 ,10 ,'2021-03-15')
,( 3 ,11 ,'2021-03-15')
,( 3 ,12 ,'2021-03-15')
,( 4 ,10 ,'2021-03-15')
,( 4 ,11 ,'2021-03-15')
,( 4 ,13 ,'2021-03-15')
,( 5 ,10 ,'2021-03-16')
,( 5 ,11 ,'2021-03-16')
,( 5 ,12 ,'2021-03-16')
go
if object_id('Friendship','U') is not null drop table Friendship
GO
CREATE TABLE Friendship(
user1_id int
, user2_id int
)
go
insert into Friendship
values
( 1 , 2 )
,( 2 , 4 )
,( 2 , 5 )
go
--查询
select distinct user1_id,user2_id
from Friendship f
left join Listens l1
on user1_id=l1.user_id
left join Listens l2
on user2_id=l2.user_id
where l1.song_id=l2.song_id
and l1.day=l2.day
group by user1_id,user2_id,l1.day
having count(distinct l2.song_id)>=3
19. Leetcodify 好友推荐
写出 SQL 语句,为 Leetcodify 用户推荐好友。我们将符合下列条件的用户 x 推荐给用户 y :
用户 x 和 y 不是好友,且
用户 x 和 y 在同一天收听了相同的三首或更多不同歌曲。
注意,好友推荐是单向的,这意味着如果用户 x 和用户 y 需要互相推荐给对方,结果表需要将用户 x 推荐给用户 y 并将用户 y 推荐给用户 x。另外,结果表不得出现重复项(即,用户 y 不可多次推荐给用户 x )。
按任意顺序返回结果表。
SELECT DISTINCT t.user1_id AS user_id,t.user2_id AS recommended_id
FROM
(SELECT a.user_id AS user1_id
,b.user_id AS user2_id
,a.song_id
,a.day
,COUNT(a.song_id) OVER (PARTITION BY a.day,a.user_id,b.user_id) AS cnt
FROM (SELECT DISTINCT * FROM Listens) a
INNER JOIN (SELECT DISTINCT * FROM Listens) b
ON a.user_id <> b.user_id
AND a.song_id = b.song_id
AND a.day = b.day) t
LEFT JOIN Friendship t1
ON t.user1_id = t1.user1_id AND t.user2_id = t1.user2_id
LEFT JOIN Friendship t2
ON t.user1_id = t2.user2_id AND t.user2_id = t2.user1_id
WHERE t.cnt >= 3 AND t1.user1_id IS NULL AND t2.user1_id IS NULL