Canal安装部署与测试
文章目录
- 第一章 Canal概述
-
- 1.1 简介
- 1.2 工作原理
-
- 1.2.1 MySQL主备复制原理
- 1.2.2 canal 工作原理
- 1.3 重要版本更新说明
- 1.4 多语言
- 第二章 Canal安装部署
-
- 2.1 准备
- 2.2 canal安装
- 第三章 Canal和Kafka整合测试
- 注意事项
第一章 Canal概述
Github地址:https://github.com/alibaba/canal
1.1 简介

canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
1.2 工作原理
1.2.1 MySQL主备复制原理
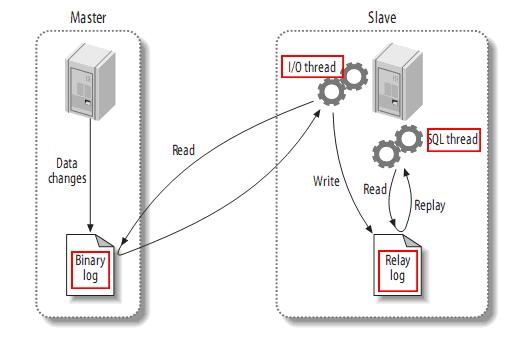
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
1.2.2 canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流),再回放中继日志
1.3 重要版本更新说明
- canal 1.1.x 版本(release_note),性能与功能层面有较大的突破,重要提升包括:
- 整体性能测试&优化,提升了150%. #726 参考: Performance
- 原生支持prometheus监控 #765 Prometheus QuickStart
- 原生支持kafka消息投递 #695 Canal Kafka/RocketMQ QuickStart
- 原生支持aliyun rds的binlog订阅 (解决自动主备切换/oss binlog离线解析) 参考: Aliyun RDS QuickStart
- 原生支持docker镜像 #801 参考: Docker QuickStart
- canal 1.1.4版本,迎来最重要的WebUI能力,引入canal-admin工程,支持面向WebUI的canal动态管理能力,支持配置、任务、日志等在线白屏运维能力,具体文档:Canal Admin Guide
1.4 多语言
canal 特别设计了 client-server 模式,交互协议使用 protobuf 3.0 , client 端可采用不同语言实现不同的消费逻辑,欢迎大家提交 pull request
- canal java 客户端: https://github.com/alibaba/canal/wiki/ClientExample
- canal c# 客户端: https://github.com/dotnetcore/CanalSharp
- canal go客户端: https://github.com/CanalClient/canal-go
- canal Python客户端: https://github.com/haozi3156666/canal-python
canal 作为 MySQL binlog 增量获取和解析工具,可将变更记录投递到 MQ 系统中,比如 Kafka/RocketMQ,可以借助于 MQ 的多语言能力
- 参考文档: Canal Kafka/RocketMQ QuickStart
第二章 Canal安装部署
2.1 准备
-
查看mysql是否开启bin-log,查询语句如下:
SHOW VARIABLES LIKE '%log_bin%'如查询出来log_bin的Value是OFF状态,则需要执行如下的开启bin-log步骤。
-
对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld] log-bin=mysql-bin # 开启 binlog binlog-format=ROW # 选择 ROW 模式 server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复 #注意,配置后需要重启msyql [root@hadoop01 ~]# systemctl restart mysqld- 注意:针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步
-
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant(如有授权用户可不执行如下命令)。
CREATE USER canal IDENTIFIED BY 'canal'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; -- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ; FLUSH PRIVILEGES;
2.2 canal安装
在 https://github.com/alibaba/canal/releases 中查找 canal 最新deploy 版本的下载链接
1.下载压缩包:
[root@hadoop01 ~]# wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
2.解压
[root@hadoop01 ~]# mkdir /usr/local/canal
[root@hadoop01 ~]# tar -zxvf /home/canal.deployer-1.1.4.tar.gz -C /usr/local/canal
3.创建测试配置直接使用自带的样例进行更改,并复制出默认配置以备后期增加库时使用,这里的每一个文件夹就代表一个数据源,多个数据源就复制出多个文件夹后在 canal.properties 的 canal.destinations 里逗号分隔进行配置:
[root@hadoop01 canal]# cp -r ./conf/example/ ./conf/test
4.修改单个数据源的配置
[root@hadoop01 canal]# vi ./conf/test/instance.properties
#修改如下
canal.instance.master.address=127.0.0.1:3306 # 数据库服务器地址
canal.instance.dbUsername=root # 数据库用户名
canal.instance.dbPassword=root # 数据库密码
#canal.instance.filter.regex=.*\\..* # 数据表过滤正则,dbName.tbName,默认的是所有库的所有表
canal.instance.filter.regex=travel.dim_product1 # 数据表过滤正则,dbName.tbName,默认的是所有库的所有表
canal.mq.topic=travel_dim_product1 # 这个数据库存储进 Kafka 时使用的 topic
5.修改 Canal 全局设置
[root@hadoop01 canal]# vi conf/canal.properties
#修改如下
canal.destinations = test # 这里配置开启的 instance,具体方法上面步骤有说明
canal.serverMode = kafka # 更改模式,直接把数据扔进 Kafka
#canal.mq.servers = 127.0.0.1:6667
canal.mq.servers = 192.168.216.111:9092,192.168.216.112:9092,192.168.216.113:9092 # Kafka 的地址
canal.mq.batchSize = 16384 # 这里没有更改,值应该小于 Kafka 的 config/producer.properties 中 batch.size,但是 Kafka 里没设置,这里也就不更改了
#canal.mq.flatMessage = false
canal.mq.flatMessage = true # 使用文本格式(JSON)进行传输,否则 Kafka 里扔进去的是二进制数据,虽然不影响,但是看起来不方便
配置文件详解:
参数名字 参数说明 默认值
canal.destinations 当前server上部署的instance列表
canal.id 每个canal server实例的唯一标识,暂无实际意义 1
canal.ip canal server绑定的本地IP信息,如果不配置,默认选择一个本机IP进行启动服务 无
canal.port canal server提供socket服务的端口 11111
canal.zkServers canal server链接zookeeper集群的链接信息
例子:127.0.0.1:2181,127.0.0.1:2182 无
canal.zookeeper.flush.period canal持久化数据到zookeeper上的更新频率,单位毫秒 1000
canal.file.data.dir canal持久化数据到file上的目录 …/conf (默认和instance.properties为同一目录,方便运维和备份)
canal.file.flush.period canal持久化数据到file上的更新频率,单位毫秒 1000
canal.instance.mysql.slaveId mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯一 1234
canal.instance.master.address mysql主库链接地址 127.0.0.1:3306
canal.instance.master.journal.name mysql主库链接时起始的binlog文件 无
canal.instance.master.position mysql主库链接时起始的binlog偏移量 无
canal.instance.master.timestamp mysql主库链接时起始的binlog的时间戳 无
canal.instance.dbUsername mysql数据库帐号 canal
canal.instance.dbPassword mysql数据库密码 canal
canal.instance.defaultDatabaseName mysql链接时默认schema
canal.instance.connectionCharset mysql 数据解析编码 UTF-8
canal.instance.filter.regex mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤) .*\\..*
6.开启 Canal
bin/startup.sh
#因为 Canal 的脚本名称都太普通,所以没有添加到 PATH 里
[root@hadoop01 canal]# ./bin/startup.sh
7.查看日志是否有异常:
[root@hadoop01 canal]# tail -f ./logs/canal/canal.log #server启动日志
[root@hadoop01 canal]# tail -f ./logs/test/test.log #instance 的日志
第三章 Canal和Kafka整合测试
kafka的安装在这儿省略,大家自行安装即可…
- 测试,连上数据库尝试执行更改 SQL
CREATE TABLE `yq` (
`dt` varchar(25) NOT NULL,
`province` varchar(255) NOT NULL,
`adds` int(11) DEFAULT '0',
`possibles` int(11) DEFAULT '0',
PRIMARY KEY (`dt`,`province`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
**查看 Kafka 中的数据,列出所有 topic:
kafka-topics.sh --list --zookeeper localhost:2181消费其中的数据:kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning此时应该已经可以列出创建表时的语句后期 Bug 修复:消费端 Kafka 不进数据,Canal 日志报错 org.apache.kafka.common.errors.RecordTooLargeException,认为是 Kafka 消息体大小限制造成的,需要同时修改 Kafka 与 Canal 消息体的最大限制修改 Kafka 配置,server.properties 中修改或添加配置项 message.max.bytes=100000000,producer.properties 中修改或添加配置项 max.request.size=100000000,consumer.properties 中修改或添加配置项 max.partition.fetch.bytes=100000000,重启 Kafka修改 Canal 配置,canal.properties 修改 canal.mq.maxRequestSize 参数值为 90000000,重启 Canal查看 Canal 日志是否报错 Could not find first log file name in binary log index file at… 如果报错则停止 Canal ,再删除实例配置下的 meta.dat 文件,再启动 Canal 即可**
- 对yq表进行update、insert、delete操作
{"data":[{"dt":"2020-7-1","province":"beijing","adds":"3","possibles":"12"}],"database":"test","es":1603647506000,"id":1,"isDdl":false,"mysqlType":{"dt":"varchar(25)","province":"varchar(255)","adds":"int(11)","possibles":"int(11)"},"old":[{"possibles":"6"}],"pkNames":["dt","province"],"sql":"","sqlType":{"dt":12,"province":12,"adds":4,"possibles":4},"table":"yq","ts":1603647506282,"type":"UPDATE"}
{"data":[{"dt":"2020-7-2","province":"beijing","adds":"10","possibles":"6"}],"database":"test","es":1603647607000,"id":2,"isDdl":false,"mysqlType":{"dt":"varchar(25)","province":"varchar(255)","adds":"int(11)","possibles":"int(11)"},"old":[{"possibles":"5"}],"pkNames":["dt","province"],"sql":"","sqlType":{"dt":12,"province":12,"adds":4,"possibles":4},"table":"yq","ts":1603647607348,"type":"UPDATE"}
{"data":[{"dt":"2020-10-26","province":"qingdao","adds":"2","possibles":"3"}],"database":"test","es":1603647656000,"id":3,"isDdl":false,"mysqlType":{"dt":"varchar(25)","province":"varchar(255)","adds":"int(11)","possibles":"int(11)"},"old":null,"pkNames":["dt","province"],"sql":"","sqlType":{"dt":12,"province":12,"adds":4,"possibles":4},"table":"yq","ts":1603647656168,"type":"INSERT"}
{"data":[{"dt":"2020-10-26","province":"qingdao","adds":"2","possibles":"3"}],"database":"test","es":1603647707000,"id":4,"isDdl":false,"mysqlType":{"dt":"varchar(25)","province":"varchar(255)","adds":"int(11)","possibles":"int(11)"},"old":null,"pkNames":["dt","province"],"sql":"","sqlType":{"dt":12,"province":12,"adds":4,"possibles":4},"table":"yq","ts":1603647707172,"type":"DELETE"}
- 关闭Canal
[root@hadoop01 canal]# ./bin/stop.sh
关闭之后,如果mysql的表数据有修改,当重启canal以后,将会把变更数据投递到kafka中!!!
注意事项
1、bin-log的存储三种Format:
mysql复制主要有三种方式:基于SQL语句的复制(statement-based replication, SBR),基于行的复制(row-based replication, RBR),混合模式复制(mixed-based replication, MBR)。对应的,binlog的格式也有三种:STATEMENT,ROW,MIXED。
① STATEMENT模式(SBR)
每一条会修改数据的sql语句会记录到binlog中。优点是并不需要记录每一条sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题)
② ROW模式(RBR)
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。
③ MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
2、canal会丢失数据吗?
建议将增量数据投递到MQ中,如果canal有异常,当恢复时候会重读中继日志
3、canal的下游怎么处理?
存储可以进行实时读写处理中---流式计算 ---> 追加到流表中、选择支持upsert 模式流表中、或者选择自己维护状态
离线,可以使用canal周期落地 --- 离线
4、canal对接kafka,kafka多分区怎么办
1、单分区能保证增量数据顺序---但是丢失并行度
2、按照维度得主键进行分区 --- 增加并行处理能力
kafka是3个分区
k-0
k-1
k-2
mysql
111
112
113
111 zs k-0
111 ls k-1
113 k-2
flink消费:
3个并行度消费
k-1 先消费
k-0 消费
5、mysql多少节点、canal多少节点
如果维度表数量在50个一下,则构建3-5个canal集群即可。
50-100个维度表,则构建7-11个左右canal即可
6、canal保留原始数据和增量数据?
ES或者HBASE:
eid
主键_version 其它字段 是否有效 起始时间 生效时间
redis:
主键 [{},{},{}] 索引+1就是版本信息