第十六届CISCN复现MISC——国粹
国粹
不是我说,我当时比赛的时候,在那里叭叭叭的数的老用心了结果他是一道非常不常规的图片密码题,又是一种我没见过的题型
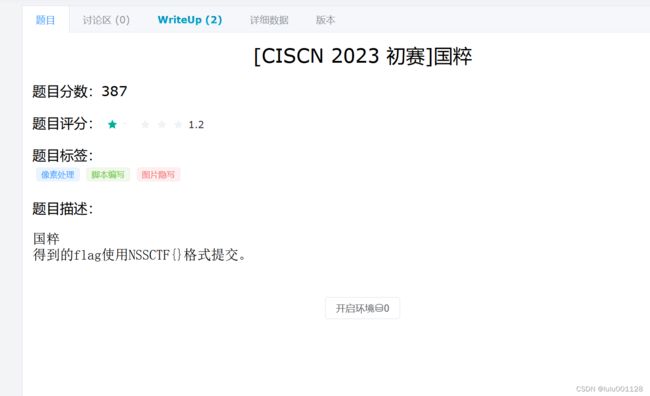
看了一些大佬的解题,知道他是一个坐标类型的图片拼凑
发现很多都提到了opencv,又是一个知识点盲区
浅浅了解一下
opencv:
OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
OpenCV主要用途的一些例子:
图像处理:OpenCV提供了一系列用于处理图像的函数和算法,包括图像滤波、图像变换、图像分割、形态学操作等。
特征检测与描述:OpenCV提供了用于检测和描述图像中的特征的函数和算法,例如SIFT、SURF、ORB、FAST等。
目标检测与识别:OpenCV提供了用于目标检测和识别的函数和算法,例如Haar Cascade分类器、HOG+SVM分类器等。
视频处理:OpenCV提供了一些用于处理视频的函数和算法,包括视频捕捉、视频压缩、视频分析等。
机器学习:OpenCV提供了一些用于机器学习的函数和算法,例如支持向量机、神经网络、K均值聚类等。
下载题目

点开图片a.png和图片k.png发现
两个图片大小一样
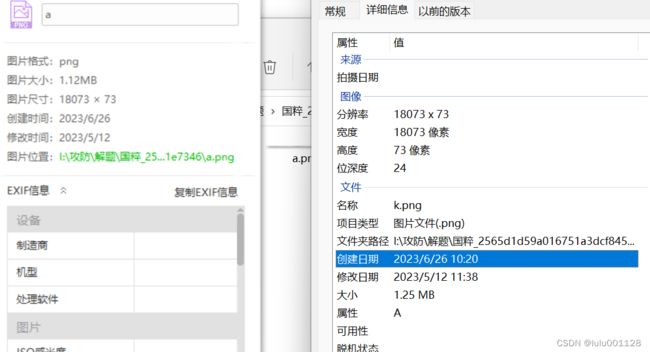
我还认真数了一波a,k,当中图片的数量,发现都是341
但是这个地方,看了一下其他的方法,发现完全是可以因式分解的
看他宽的像素值,用在线因式分解的网站对其进行分解,因为每张牌的大小都是一样的,这个数一定可以被每张牌的宽度整除;
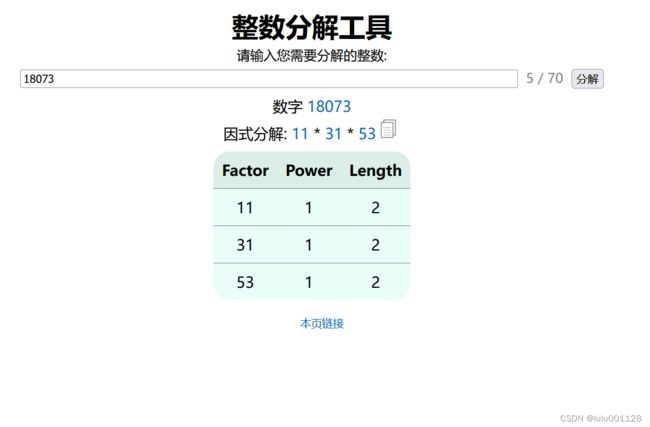
然后再画图里看一下第一张牌和第二张牌的界限宽度,没有办法准确确定,只知道大概是 50
左右的样子,然后看到有因数是 53,那么大概率每张牌的宽度就是 53 了;
然后用18073/53
大概就是一共是341张牌;
题目的图片中牌数比较少,可以直接数出来是 42 张,第二排下面多了一张 1 万,按照思路题目这
样表是作为一个对照,这些牌按照顺序依次是 1,2,3 往后推,所以已经有了一张一万,下面
多的那张是没有用的;
a、k 两张图片的牌数一样,同时发现 a 的牌会出现一些重复,非常像坐标,所以我们下面
要做的任务就是把 a、k 两张图里的牌转化为相应的数字,再把牌一一对应,组合成 x、y 坐
标;
我们首先对图片进行切割,去网上找个脚本,改改就可以;
# -*- coding: utf-8 -*-
# 青少年网络安全 2022 03 30
from PIL import Image
filename = r'what.png'
img = Image.open(filename)
size = img.size
print(size)
# 大小为根号100
# 准备将图片切割成100张小图片
weight = int(size[0] // 10)
height = int(size[1] // 10)
# 切割后的小图的宽度和高度
print(weight, height)
for j in range(10):
for i in range(10):
box = (weight * i, height * j, weight * (i + 1), height * (j + 1))
region = img.crop(box)
region.save('misc\\zxsctf_{}{}.png'.format(j, i))
图像切分脚本:
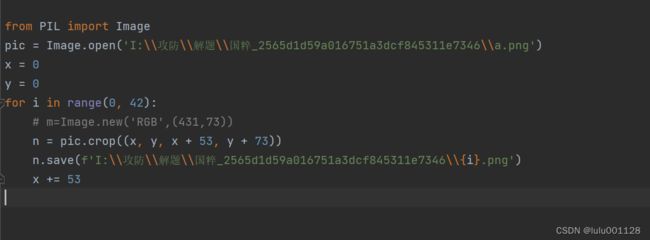
a

k
了解过程中,发现又是一个陌生的库,PIL库
Pillow 是 Python 中较为基础的图像处理库,主要用于图像的基本处理,比如裁剪图像、调整图像大小和图像颜色处理等。与 Pillow 相比,OpenCV 和 Scikit-image 的功能更为丰富,所以使用起来也更为复杂,主要应用于机器视觉、图像分析等领域,比如众所周知的“人脸识别”应用 。
Python 中的 PIL 库_python pil_SteveKenny的博客-CSDN博客
一开始我想通过比较图片 md5 的方式进行,将 key 里面的图片按照顺序生成 md5 值,将
md5 值作为键,对应的序号作为值创建字典,然后 a、k 的文件夹用 for 循环依次遍历,每
次都计算图片的 md5 值,然后去查字典,取出相应的数值,由此可以得到两个坐标数组,
但是我在 md5 的代码写完运行之后发现,两张不同图片分割后虽然内容相同,但是图片的
md5 值不同,所以要想别的办法;
将a与k图像进行识别匹配,并将坐标保存,绘制为图像
图像识别+绘图脚本
import cv2
import numpy as np
import os
import turtle as t
import time
images=[]
x=[0 for i in range(343)]
y=[0 for i in range(343)]
for cuedir,dirs,filename in os.walk('C:\\Users\\Lenovo\\Desktop\\cuted'):
for files in filename:
f=eval(files.split(".")[0])#将.前面文件名单独储存,并化为数字
images.append(f)#储存文件夹内的图片名称
images.sort()#整理文件名顺序
img_rgb = cv2.imread('C:\\Users\\Lenovo\\Desktop\\a.png')#识别图
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
#shape函数是numpy.core.fromnumeric中的函数,它的功能是读取矩阵的长度
for i in range(len(images)):
template = cv2.imread(f'C:\\Users\\Lenovo\\Desktop\\cuted\\{images[i]}.png', 0) # 识别模板
h, w = template.shape[:2] # 读取宽高
result = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)#标准相关匹配
threshold = 0.9
# 取匹配程度大于%90的坐标
loc = np.where(result >= threshold)
#print(loc)
# np.where返回的坐标值(x,y)是(h,w),注意h,w的顺序
for pt in zip(*loc[::-1]):
#print(pt)
m=pt[0]//53
x[m]=images[i]
bottom_right = (pt[0] + w, pt[1] + h)
cv2.rectangle(img_rgb, pt, bottom_right, (0, 0, 255), 2)
cv2.imwrite("C:\\Users\\Lenovo\\Desktop\\x.jpg", img_rgb)
img_rgb = cv2.imread('C:\\Users\\Lenovo\\Desktop\\k.png')#识别图
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
#shape函数的功能是读取矩阵的长度
for i in range(len(images)):
template = cv2.imread(f'C:\\Users\\Lenovo\\Desktop\\cuted\\{images[i]}.png', 0) # 识别模板
h, w = template.shape[:2] # 读取宽高
result = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)#标准相关匹配
threshold = 0.9
# 取匹配程度大于%90的坐标
loc = np.where(result >= threshold)
#print(loc)
# np.where返回的坐标值(x,y)是(h,w),注意h,w的顺序
for pt in zip(*loc[::-1]):
#print(pt)
m=pt[0]//53
y[m]=images[i]
bottom_right = (pt[0] + w, pt[1] + h)
cv2.rectangle(img_rgb, pt, bottom_right, (0, 0, 255), 2)
cv2.imwrite("C:\\Users\\Lenovo\\Desktop\\y.jpg", img_rgb)#保存识别后的图片
cv2.waitKey(0)
for i in range(0,343):
print(f'{x[i]} {y[i]}')
'''with open('C:\\Users\\Lenovo\\Desktop\\gnuplot.txt','w') as gn:
for i in range(0,342):
gn.write(f'{x[i]} {y[i]}\n')#坐标导出为一个txt文件'''
#绘制模块
t.speed(100)
t.pu()
for i in range(0,343):
t.goto(y[i]*5,-x[i]*5)
t.pd()
t.circle(1,360)
t.pu()
time.sleep(1000)#方便截图如果发现输出图片是反的,可以将x,y的位置互换一下
