大数据技术之Hive3
目录标题
-
- 5、DML 数据操作
-
- 5.1 数据导入
-
- 5.1.1 向表中装载数据load
- 5.1.2 通过查询语句向表中插入数据insert
- 5.1.3 查询语句中创建表并加载数据
- 5.1.4 创建表时通过 Location 指定加载数据路径
- 5.2 数据导出
-
- 5.2.1 insert导出
- 5.2.2 Hadoop 命令导出到本地
- 5.3 清除表中数据(Truncate)
- 6、查询
-
- 6.1 注意点
- 6.2 笛卡尔积
-
- 6.2.1 笛卡尔积会在下面条件中产生
- 6.3 分桶
-
- 6.3.1 分桶表数据存储
- 6.4 其他常用查询函数
- 6.5 行转列
- 6.6 列转行
5、DML 数据操作
5.1 数据导入
5.1.1 向表中装载数据load
load data [local] inpath ‘/opt/module/datas/student.txt’ [overwrite] | into table student [partition (partcoll = val1,…)]
(1)load data:表示加载数据
(2)local:表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
实操:
1,创建一张表
create table 表名(id string,name string) row format delimited fields terminated by '\t'
2,加载本地文件到hive
load data local inpath '/opt/module/dates/student.txt' into table default.student;
3,加载HDFS文件到hive
本地文件上传到HDFS
dfs -put /opt/module/datas/student.txt /user/atguigu/hive
HDFS文件再到hive
load data inpath '/user/atguigu/hive/student.txt' into table default.student;
5.1.2 通过查询语句向表中插入数据insert
1,创建分区表
create table student(id int , name string) partitioned by (month string) row format delimited fields terminated by '\t';
2,插入数据
insert into table student partition(month = '201709')values(1,'wangwu')
3,插入(根据单张表查询结果)
insert overwrite table student partition(month='201708')
select id, name from student where month='201709';
4,多插入模式(根据多张表查询结果)
from student
insert overwrite table student partition(month='201707')
select id,name where month='201709'
insert overwrite table student partition(month='201707')
select id,name where month='201709'
5.1.3 查询语句中创建表并加载数据
create table if not exists student3 as select id,name from student;
5.1.4 创建表时通过 Location 指定加载数据路径
1.创建表,并指定在 hdfs 上的位置
create table if not exists student5(id int, name string)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student5';
2,上传数据到 hdfs 上
dfs -put /opt/module/datas/student.txt /user/hive/warehouse/student5;
3,查询数据
select * from student5;
5.2 数据导出
5.2.1 insert导出
1.将查询的结果导出到本地
insert overwrite local directory '/opt/module/datas/export/student'
select * from student;
2.将查询的结果格式化导出到本地
insert overwrite local directory 'opt/module/datas/export/student1'
row format delimited fields terminated by '\t'
select * from student;
3,将查询的结果导出到 HDFS 上(没有 local)
insert overwrite directory '/user/atguigu/student2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
5.2.2 Hadoop 命令导出到本地
dfs -get /user/hive/warehouse/student/month=201709/000000_0
/opt/module/datas/export/student3.txt;
Hive Shell 命令导出

Export 导出到 HDFS 上

5.3 清除表中数据(Truncate)
注意:Truncate 只能删除管理表,不能删除外部表中数据
hive (default)> truncate table student;
6、查询
6.1 注意点
1,SQL 语言大小写不敏感


2,平均值:avg(sal)
3,like:
% 代表零个或多个字符(任意个字符)。
_ 代表一个字符。
6.2 笛卡尔积
6.2.1 笛卡尔积会在下面条件中产生
1,省略连接条件
2,连接条件无效
3,所有表中的所有行相互连接
6.3 分桶
6.3.1 分桶表数据存储
分区针对的是数据的存储路径,分桶针对的是数据文件
分区提供一个隔离数据和优化查询的便捷方法。不过,并非所有的数据集都可以形成合理的分区
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
(1).先创建分桶表,通过直接导入数据文件的方式
1,数据准备student.txt
2,创建分桶表
create table stu_buck(id int ,name string)
clustered by(id) into 4 buckets
row format delimited fields terminated by ‘\t’
3,查看表结构
desc formatted stu_buck;
Num Buckets: 4
4,导入数据到分桶表中
load data local inpath ‘/opt/module/datas/student.txt’ into table
stu_buck;
(2).创建分桶表时,数据通过子查询的方式导入
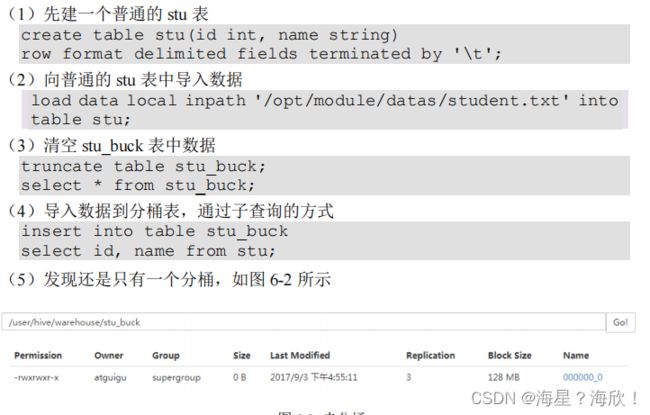
(6)需要设置一个属性
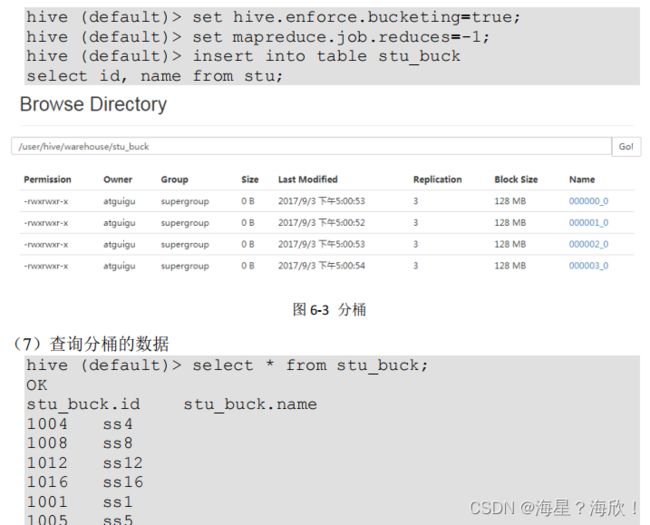
6.4 其他常用查询函数
- NVL( string1, replace_with)
NVL:给值为 NULL 的数据赋值,它的格式是 NVL( string1, replace_with)。它的功能是如果string1 为 NULL,则 NVL 函数返回 replace_with 的值,否则返回 string1 的值,如果两个参数都为 NULL ,则返回 NULL。
###如果员工的 comm 为 NULL,则用-1 代替
select nvl(comm,-1) from emp;
- date_format:格式化时间
select date_format('2019-06-29','yyyy-MM-dd');
- date_add:时间跟天数相加
select date_add('2019-06-29',5);
- data_sub :时间跟天数相减
select date_sub('2019-06-29',5);
5)datadiff :两个时间相减
select datediff('2019-06-29','2019-06-24');
#输出距离多少天
6.5 行转列
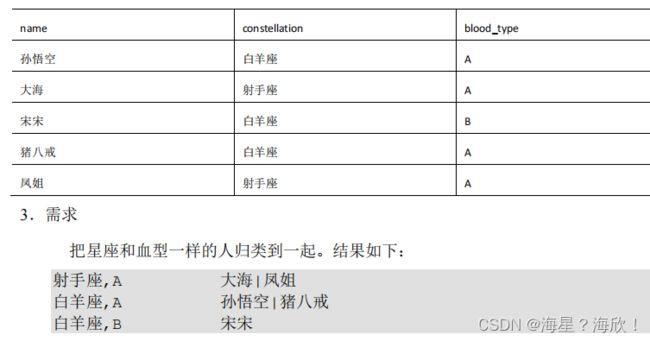
select
t1.base,
concat_ws('|', collect_set(t1.name)) name
from
(select name, concat(constellation, ",", blood_type) base
from
person_info) t1
group by
t1.base;
6.6 列转行
1.函数说明
EXPLODE(col):将 hive 一列中复杂的 array 或者 map 结构拆分成多行。
LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和 split, explode 等 UDTF 一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合

select movie, category_name
from
movie_info lateral view explode(category) table_tmp as
category_name;
三种排序:
rank() :1224
dense_rank():1223
row_number():1234