ELK学习笔记
1、为什么需要用ELK
对于常见的无状态服务查日志时,由于是分布式的,日志会落到多台服务器上,一台一台grep太费劲,所以需要一个地方可以统一查询日志。
一个集中式日志系统包含下面几个特点:
- 搜集:采集多种来源的日志数据
- 传输:可以稳定地把日志从各个来源传输到日志搜集系统
- 存储:日志搜集系统存储日志数据
- 分析:支持UI页面分析查询
- 告警:能够发送错误告警
ELK利用三个开源软件Elasticsearch , Logstash, Kibana的完美组合,提供了一套提供了一套完整的解决方案,成为了目前主流的日志系统。
2、ELK简介
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana。ELK还新增了一个FileBeat,它是一个轻量级日志搜集工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash。
2.1、Elasticsearch
ES是开源的分布式搜索引擎。提供搜集、分析、存储三大功能。
ES的特点:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
2.2、Logstash
Logstash是日志的搜集、分析、过滤的工具。工作方式一般为C/S架构,client安装在需要搜集日志的主机上,server端将搜集到的各客户端的日志进行过滤、修改,然后发送到ES上。
2.3、Kibana
Kibana为ES和Logstash提供友好的Web页面来做日志查询。
2.4、Filebeat
Filebeat是本地文件的日志数据采集器。 作为客户端的agent安装,Filebeat监控日志目录或特定的日志文件,tail file,并将它们转发给Logstash、ES、kafka等。
3、Flume简介
Flume是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据的简单处理,并写到各种数据接收方的能力。
事件(Event)是Flume的基本单位,Event由Agent外部的Source生成,携带日志数据(字字节数组的形式)和头信息,Source会把Event推入(一个或多个)Channel(可看做是缓冲区)中,Channel保存Event直到Sink处理完该Event。Sink负责持久化日志,或把日志推到另一个Source。
3.1 Flume的可靠性保障
Flume提供了三种基本的可靠性保障,从强到弱依次是:
- end-to-end:搜集数据的agent首先将日志写到磁盘上,当数据传输成功后,再删除;如果数据传输失败,做从磁盘中取出重新发送。
- store-on-failure:当数据接收方crash时,将数据写入到本地磁盘;当数据接收方恢复后,从磁盘读取数据继续发送。
- best-effort:数据推给数据接收方,不进行收到后确认。
3.2 Flume核心概念
- Client:用于生产数据,运行在一个独立的线程。
- Event:一个数据单元,消息头和消息体组成。
- Flow:Event从源点到达目的点的迁移的抽象。
- Agent:一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks)
- Source:数据收集组件。(source从Client收集数据,传递给Channel)
- Channel:中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 sources 和 sinks ,这个有点像一个队列)
- Sink:从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
3.3 Flume与Logstash的区别
1、Flume是一个分布式的、高可靠的、高可用的将大批量的不同数据源的日志数据收集、聚合、移动到数据中心(HDFS)进行存储的系统。即是日志采集和汇总的工具
2、Logstash、FileBeat是ES栈的日志数据抽取工具,他们和Flume很类似,前者是轻量级、后者是重量级,若项目组使用的是ES栈技术,那完全可以使用Logstash取代Flume。
4、ELK的架构
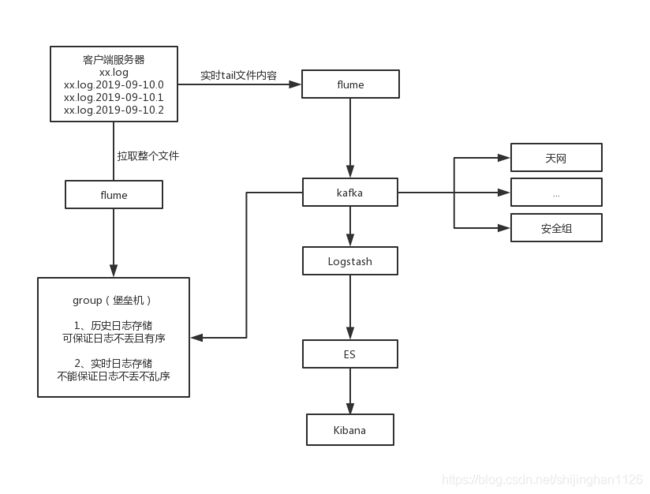
当前架构的执行流程:
1、客户端产生日志后,通过flume的agent实时生成数据到flume的服务端,然后flume服务端把日志写入到kafka。
2、业务系统如天网系统、安全组等可自行消费kafka来获取全量日志。
3、Logstash消费kafka中的日志,并写入ES,然后由Kibana来展示查询ES。
4、堡垒机消费kafka作为实时日志,可供业务方自己通过grep等命令进行查询。
5、当客户端每生成一个日志文件后,flume会把整个文件拉取到堡垒机上,作为全量的历史日志。历史日志不会丢消息,也不会消息乱序。
5、为什么采用当前架构
5.1、简单粗暴的ELK架构
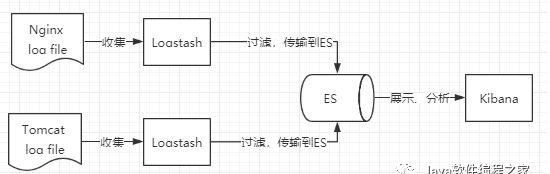
这种方式对于数据源服务器(例如tomcat log file)的性能影响很大,因为logstash需要安全在数据源服务器上,然后对搜集到的数据进行实时过滤,然后再写入到ES中。这样logstash的性能与ES的写入的吞吐量,会影响数据源服务器的性能。所以,通常加入MQ来进行缓冲,例如:
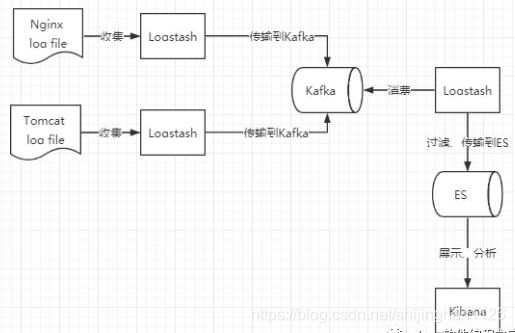
通过kafka进行异步缓冲后,数据源服务器只要写入到kafka后,就算数据写入成功。然后由logstash消费完kafka后,在进行数据过滤后,再写入ES。
这样此架构对比现有架构,唯一不同就是flume和logstash的区别,待确认问题:
1)为什么用flume而不用logstash
2)数据过滤用的是flume还是logstash
3)几台logstash,几台flume,是否是并行的?
6、当前架构存在的问题
6.1、个别日志有丢失情况
实时日志丢失原因,有两点:
1、在flume1.6中,通过 tail -f 来搜集不断增加的文件中的日志,但是日志文件个数也是变化的。所以仅用 tail -f 会导致日志丢失。
在 flume 1.7 中,通过TAILDIRl解决了此问题,TAILDIRl可监控一个目录的变化,而不是一个文件。
参考:https://blog.csdn.net/qq_36932624/article/details/81477766
2、flume的Channel采用MemoryChannel,即内存队列:
1)在flume agent宕机时候导致数据在内存中丢失
2)Channel存储数据已满,导致Source不再写入数据,造成未写入的数据丢失。
参考:https://blog.csdn.net/wx1528159409/article/details/88737287
6.2、日志延迟的原因
从数据源服务器flume agent到flume服务端这段传输会有数据延迟。
问题:为什么会有数据延迟呢?flume没有做日志过滤,然后直接写入到了kafka。
6.3、是否可以把历史和实时日志进行合并
目前,历史日志和实时日志各保留了一份,这对于大数据量的ELK中的日志是非常耗费资源的。为什么不能把历史和实时的日志一共只保存一份呢?
先看历史日志和实时日志分别存在的作用:
6.3.1、历史日志
历史日志,在每生成一个日志文件后,把整个文件copy到堡垒机,可保证日志内容不丢、不乱序。
6.3.2、实时日志
实时日志,可在历史日志还没有生成的时候,可直接通过grep来做日志查询,但实时日志不能保证消息不丢不乱序。
6.3.3 解决方案
可在历史日志生成后,把实时数据进行删除。这样相当于实时日志仅临时存在,不会耗费多少资源。