-
欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手
-
️ 博客主页:一晌小贪欢的博客主页
-
该系列文章专栏:Python办公自动化专栏
-
文章作者技术和水平有限,如果文中出现错误,希望大家能指正
-
❤️ 欢迎各位佬关注! ❤️
最近接到一个需求就是客户有非常大批量的PDF版的文件,需要我提取里面的某一处信息,那么我查了一下,可以用【pdfplumber】 这个库,对PDF文件进行读取,那么接下来我写了一个TEST,我们大家一起看看吧
首先,如下图;我想提取指定的内特容,如:【拓展-中文语言包】这段文字
效果展示
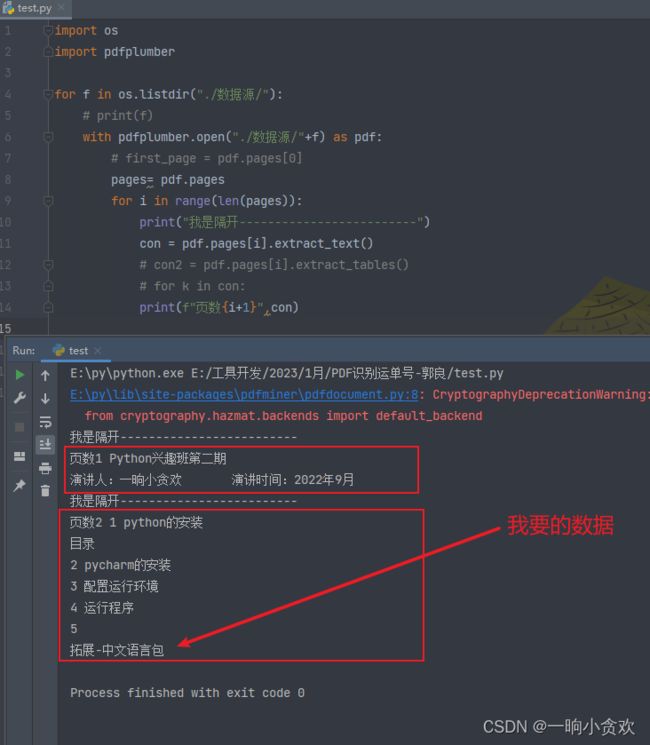
先看目录结构
就一个文件夹,叫做:【数据源】,里面可以用来存放所有的pdf
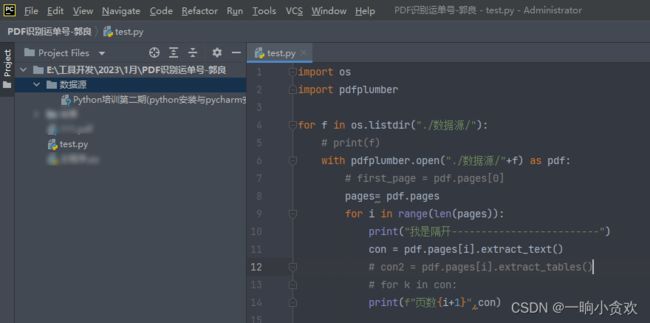
直接上代码
顺便说一下,主要用到的函数是: extract_text(),获取文本,
pdf.pages:获取所有的页数
import os
import pdfplumber
for f in os.listdir("./数据源/"):
with pdfplumber.open("./数据源/"+f) as pdf:
pages= pdf.pages
for i in range(len(pages)):
print("我是隔开-------------------------")
con = pdf.pages[i].extract_text()
print(f"页数{i+1}",con)
最后的指定数据获取,我就不展示了,大家可以切片
希望对大家有帮助
致力于办公自动化的小小程序员一枚
都看到这了,关注+点赞+收藏=不迷路!!