C# 数据结构】Heap 堆
【C# 数据结构】Heap 堆
- 先看看C#中有那些常用的结构
- 堆的介绍
-
- 完全二叉树
- 最大堆
- Heap对类进行排序
-
-
- 实现 `IComparable
` 接口
- 实现 `IComparable
- 对CompareTo的一点解释
-
- 参考资料
先看看C#中有那些常用的结构
作为 数据结构系类文章 的开篇文章,我们先了解一下C# 有哪些常用的数据结构
C# 是一种通用、面向对象的编程语言,它提供了许多常用的数据结构,以便在开发过程中高效地存储和操作数据。以下是一些在 C# 中常用的数据结构:
-
数组 (Array):
数组是一个固定大小的、相同类型元素的集合。使用索引来访问数组中的元素。 -
列表 (List):
列表是一个动态大小的集合,可以根据需要自动增长或缩小。List 是泛型类,T 表示可以存储的元素类型。 -
链表 (LinkedList):
链表是一种数据结构,其中的元素按节点 (Node) 连接在一起,每个节点包含一个数据元素和一个指向下一个节点的引用。 -
栈 (Stack):
栈是一种后进先出 (Last-In-First-Out, LIFO) 的数据结构,只允许在顶部插入和删除元素。 -
队列 (Queue):
队列是一种先进先出 (First-In-First-Out, FIFO) 的数据结构,允许在一端插入元素,在另一端删除元素。 -
字典 (Dictionary):
字典是一种键值对 (Key-Value) 映射的集合,允许通过键来快速查找和访问值。 -
散列表 (HashSet, Hashtable):
散列表是一种根据键快速查找值的数据结构。HashSet 是一个泛型类,而 Hashtable 是非泛型的旧式实现。 -
堆 (Heap):
堆是一种特殊的树状数据结构,其中的每个节点的值都大于或小于其子节点的值。常用于优先队列等场景。 -
树 (Tree):
树是一种分层数据结构,其中的节点以层次结构进行组织。常见的树包括二叉树、二叉搜索树等。 -
图 (Graph):
图是一组节点和边的集合,用于表示各种复杂关系。常见的图算法包括深度优先搜索和广度优先搜索。
ps: 我们经常说堆栈堆栈,其实这样一看发现堆和栈的数据结构是完全不同的。
堆的介绍
完全二叉树
堆首先是个树状的结构,而且是个完全二叉树!什么是完全二叉树?
完全二叉树:二叉树除了最后一层节点外,其他层的节点个数必须是最大值,如果最后一层没有达到最大节点,则所有的节点必须偏向左边。

如何理解:其他层的节点个数必须是最大值?
就是第一层 一个节点,第二层 两个节点 第三层 四个节点,以此类推。
不过最后一层不要求节点个数是最大值。(最后一层没有达到最大节点,则所有的节点必须偏向左边)
那这个完全二叉树的定义有啥用了,为啥搞这么多规矩出来?
那是因为完全二叉树这样个树的结构,是可以通过数值存储的!(因为其节点的位置在数组中的索引之间有一种固定的关系)
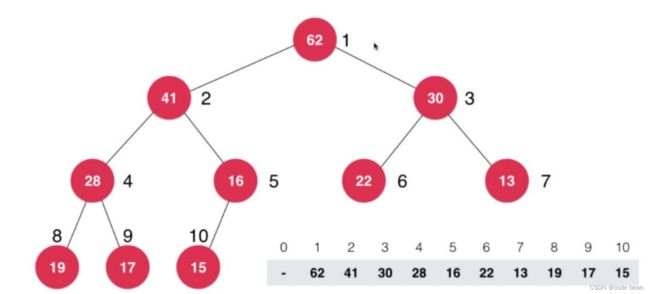
前提:数据的0号地址不使用,从1开始使用。
如果将完全二叉树从上到下、从左到右依次编号,那么节点 i 的左子节点索引为 2i,右子节点索引为 2i+1,父节点索引为 i/2(注意这里除法是计算机里整除的意思)
当然二叉树还要其他特点这里了解即可:
完美填充:完全二叉树是按照从左到右的顺序填充节点的,除了最后一层外,其他层的节点都是满的(即每个节点都有两个子节点)。最后一层的节点从左到右填充,可能是满的,也可能是部分填充,但是最后一层的节点一定是从左到右依次填充的,不会有空洞。
叶节点:所有叶节点都集中在最后一层或者倒数第二层。如果最后一层的叶节点没有填满,则它们一定是从左到右依次连续排列的。
层数:完全二叉树的层数为 h,从根节点到倒数第二层都是满的,最后一层可能不满。因此,节点总数 N 满足 N = 2^h - 1 + 最后一层节点数。
高度平衡:由于完全二叉树的特点,其左右子树的高度差不会超过 1,因此是一个高度平衡的二叉树。
最大堆
首先最大堆,必须是完全二叉树
每一个节点可以有两个子节点。任何一个节点都不不大于他的父节点
那么最大堆,树顶的位置是最大的元素
有最大堆就有最小堆:
最小堆:树顶的位置是最小的元素(堆中某个节点的值总是不小于其父节点的值)
C# 中的 Heap 实际上是最小堆(Min Heap)的实现,其中最小的元素总是位于堆的顶部。
在 C# 中,可以使用 System.Collections.Generic 命名空间中的 Heap 数据结构来实现堆(Heap)。Heap 通常用于实现优先队列等场景,其中每个元素都有一个优先级(或者键值),并且可以根据优先级高低进行插入和删除操作。
下面是如何使用 Heap 数据结构的基本步骤:
Step 1: 导入命名空间
首先,在代码文件中导入 System.Collections.Generic 命名空间,以便可以使用 Heap 类。
using System.Collections.Generic;
Step 2: 创建 Heap
使用 Heap 类创建一个堆对象。Heap 类是一个泛型类,你需要指定元素的类型。以下是一个示例创建最小堆的代码:
Heap<int> minHeap = new Heap<int>();
Step 3: 插入元素
使用 Insert 方法将元素插入堆中。插入元素后,堆会自动调整,以确保最小元素位于堆的顶部。
minHeap.Insert(10);
minHeap.Insert(5);
minHeap.Insert(15);
minHeap.Insert(3);
// 此时堆为:3 5 15 10
Step 4: 获取堆顶元素
使用 Peek 方法获取堆顶(最小)元素,但不删除它。
int minValue = minHeap.Peek();
// minValue 等于 3
// 此时堆仍为:3 5 15 10
Step 5: 弹出堆顶元素
使用 ExtractMin 方法弹出堆顶元素(即删除堆顶最小元素),并返回该元素的值。
int minValue = minHeap.ExtractMin();
// minValue 等于 3,同时堆变为:5 10 15
看到这里我们知道堆的作用其实就是优先级排序,比如计算机任务,每个任务都会有一个优先级,优先级高的任务被先处理,而且随时还可能来新的任务。 那我们为何要使用对进行排序呢?
那是因为每次来新任务时,就需要重新排序,如果是普通的排序,计算量是非常大的:


也就是说堆在实现优先级排序的时候是最合适的。
至于如何自己写代码实现一个堆,这里就不说了,继续介绍实际中会直接用到的。
现在假设我有一个类,而不是int这样的数组,我们怎么用堆排序呢?
Heap对类进行排序
当你有一个自定义的类,想要在 Heap 中根据类的某个属性来表示优先级时,你可以通过实现 IComparable 接口或者自定义比较器来实现。
假设你有一个名为 MyClass 的类,其中包含一个整数属性 Priority 用于表示优先级,那么你可以按照以下两种方法之一来使用 Heap 并根据 Priority 属性来表示优先级:
实现 IComparable 接口
让 MyClass 类实现 IComparable 接口,并在 CompareTo 方法中定义对象之间的优先级比较逻辑。
using System;
using System.Collections.Generic;
public class MyClass : IComparable<MyClass>
{
public int Priority { get; set; }
public string Data { get; set; }
// 实现 IComparable 接口中的 CompareTo 方法
public int CompareTo(MyClass other)
{
return Priority.CompareTo(other.Priority);
}
}
// 创建最小堆,根据 MyClass 的优先级属性进行比较
Heap<MyClass> minHeap = new Heap<MyClass>();
// 添加 MyClass 对象到最小堆
minHeap.Insert(new MyClass { Priority = 10, Data = "Value1" });
minHeap.Insert(new MyClass { Priority = 5, Data = "Value2" });
minHeap.Insert(new MyClass { Priority = 15, Data = "Value3" });
minHeap.Insert(new MyClass { Priority = 3, Data = "Value4" });
// 弹出堆顶元素(优先级最小的对象)
while (minHeap.Count > 0)
{
MyClass minPriorityObj = minHeap.ExtractMin();
Console.WriteLine($"Priority: {minPriorityObj.Priority}, Value: {minPriorityObj.Data}");
}
这种方法都允许你在 Heap 中根据 Priority 属性来表示对象的优先级,并按优先级顺序插入和弹出对象。
对CompareTo的一点解释
有些童鞋对这里可能有的不明白,这里稍微解释一下
public int CompareTo(MyClass other)
{
return Priority.CompareTo(other.Priority);
}
首先,C# 有跟多类实现了 实现 IComparable 接口中的 CompareTo 方法
用于比较对象之间的大小关系。这些类实现了 IComparable 接口,以允许在容器中进行自定义排序。以下是一些常见的实现了 CompareTo 方法的类:
-
Int32、Int64、Single、Double、Decimal等数值类型:这些数值类型都实现了IComparable接口,使得它们可以通过CompareTo方法进行比较。 -
DateTime类:DateTime类也实现了IComparable接口,因此你可以使用CompareTo方法来比较日期和时间的大小。 -
String类:String类实现了IComparable接口,允许你比较字符串的大小关系。它使用基于 Unicode 编码的排序规则。 -
TimeSpan类:TimeSpan类实现了IComparable接口,允许你比较时间间隔的大小关系。 -
Enum枚举类型:枚举类型实现了IComparable接口,使得枚举值之间可以通过CompareTo方法进行比较。 -
Version类:Version类用于表示软件版本号,它实现了IComparable接口,允许你比较软件版本的大小关系。
x.Priority.CompareTo(y.Priority) 是一个比较表达式,用于比较两个对象 x 和 y 的 Priority 属性的值。它会返回一个整数,指示这两个值之间的关系。
具体含义如下:
- 如果
x.Priority小于y.Priority,则表达式返回负数(通常为-1)。 - 如果
x.Priority等于y.Priority,则表达式返回零。 - 如果
x.Priority大于y.Priority,则表达式返回正数(通常为1)。
这个返回值在使用自定义比较器或实现 IComparable 接口时非常重要,因为它将用于决定如何排序或比较两个对象。根据返回值的正负,容器(如 Heap、List 等)会根据你定义的比较逻辑来确定对象的排序顺序。
例如,在上述代码中,我们使用了这个比较表达式来定义 MyClass 对象之间的优先级比较逻辑。在最小堆中,这个比较表达式的结果将决定 MyClass 对象的排序顺序,使得具有较小 Priority 属性值的对象排在堆顶,而具有较大 Priority 属性值的对象排在堆底。
所以,返回值的含义非常简单,它指示了两个对象之间的大小关系,用于实现排序和比较。
参考资料
https://coding.imooc.com/class/71.html