【MySQL】基本查询(插入查询结果、聚合函数、分组查询)
目录
- 一、插入查询结果
- 二、聚合函数
- 三、分组查询(group by & having)
- 四、SQL查询的执行顺序
- 五、OJ练习
一、插入查询结果
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...
案例:删除表中重复数据
--创建初始重复表
mysql> CREATE TABLE duplicate_table (id int, name varchar(20));
Query OK, 0 rows affected (0.03 sec)
--插入重复数据
mysql> INSERT INTO duplicate_table VALUES
-> (100, 'aaa'),
-> (100, 'aaa'),
-> (200, 'bbb'),
-> (200, 'bbb'),
-> (200, 'bbb'),
-> (300, 'ccc');
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
--查询表中数据
mysql> select * from duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 100 | aaa |
| 200 | bbb |
| 200 | bbb |
| 200 | bbb |
| 300 | ccc |
+------+------+
6 rows in set (0.00 sec)
--新建一个相同表结构的空表
mysql> create table no_duplicate_table like duplicate_table;
Query OK, 0 rows affected (0.02 sec)
--把去重后的结果插入空表中
mysql> insert into no_duplicate_table select distinct *from duplicate_table;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
//查询表内数据
mysql> select * from no_duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+
3 rows in set (0.00 sec)
//修改两个表名,把去重后的表该为该名字
mysql> rename table duplicate_table to old_duplicate_table,no_duplicate_table to duplicate_table;
Query OK, 0 rows affected (0.02 sec)
mysql> select * from duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+
3 rows in set (0.00 sec)
这里通过rename修改表名是为了等表的操作结束后,统一放入,更新,生效,节省时间
二、聚合函数
MySQL中的聚合函数常用于对数据进行计算和统计,以下是几种常见的聚合函数
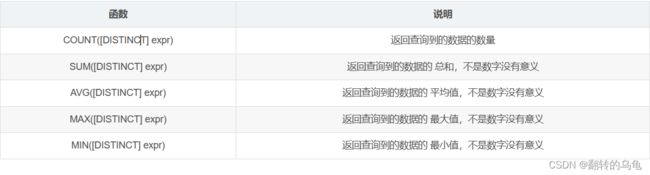
案例:
- 统计班级共有多少同学
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 134 | 98 | 56 |
| 3 | 猪悟能 | 176 | 98 | 90 |
| 4 | 曹孟德 | 140 | 90 | 67 |
| 5 | 刘玄德 | 110 | 115 | 45 |
| 6 | 孙权 | 140 | 73 | 78 |
| 7 | 宋公明 | 150 | 95 | 30 |
+----+-----------+---------+------+---------+
6 rows in set (0.00 sec)
mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 6 |
+----------+
1 row in set (0.00 sec)
mysql> select count(1) from exam_result;
+----------+
| count(1) |
+----------+
| 6 |
+----------+
1 row in set (0.00 sec)
-- 统计班级的数学成绩有多少个(去重)
mysql> select math from exam_result;
+------+
| math |
+------+
| 98 |
| 98 |
| 90 |
| 115 |
| 73 |
| 95 |
+------+
6 rows in set (0.01 sec)
mysql> select count(distinct math) from exam_result;
+----------------------+
| count(distinct math) |
+----------------------+
| 5 |
+----------------------+
1 row in set (0.00 sec)
-- 统计数学成绩总分
mysql> select sum(math) from exam_result;
+-----------+
| sum(math) |
+-----------+
| 569 |
+-----------+
1 row in set (0.00 sec)
--统计数学成绩的平均分
mysql> select avg(math) from exam_result;
+-------------------+
| avg(math) |
+-------------------+
| 94.83333333333333 |
+-------------------+
1 row in set (0.00 sec)
--统计英语成绩不及格的人数
mysql> select count(*) from exam_result where english<60;
+----------+
| count(*) |
+----------+
| 3 |
+----------+
1 row in set (0.00 sec)
--返回英语最高分
mysql> select max(english) from exam_result;
+--------------+
| max(english) |
+--------------+
| 90 |
+--------------+
1 row in set (0.00 sec)
--返回 > 70 分以上的数学最低分
mysql> select min(math) from exam_result where math>70;
+-----------+
| min(math) |
+-----------+
| 73 |
+-----------+
1 row in set (0.00 sec)
三、分组查询(group by & having)
分组的目的是为了方便进行聚合统计
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;
案例:
EMP员工表
DEPT部门表
SALGRADE工资等级表
- 显示每个部门的平均工资和最高工资
group by ‘列名’:分组是以同一列不同行数据来进行分组的;分组过后,每组内的【分组列名如deptno】,一定是一样的,可以被聚合压缩
mysql> select deptno,avg(sal) 平均工资, max(sal) '最高工资' from emp group by deptno;
+--------+--------------+--------------+
| deptno | 平均工资 | 最高工资 |
+--------+--------------+--------------+
| 10 | 2916.666667 | 5000.00 |
| 20 | 2175.000000 | 3000.00 |
| 30 | 1566.666667 | 2850.00 |
+--------+--------------+--------------+
3 rows in set (0.00 sec)
- 显示每个部门的每种岗位的平均工资和最低工资
mysql> select deptno, job,avg(sal) 平均工资, min(sal)最低工资 from emp group by deptno, job;
+--------+-----------+--------------+--------------+
| deptno | job | 平均工资 | 最低工资 |
+--------+-----------+--------------+--------------+
| 10 | CLERK | 1300.000000 | 1300.00 |
| 10 | MANAGER | 2450.000000 | 2450.00 |
| 10 | PRESIDENT | 5000.000000 | 5000.00 |
| 20 | ANALYST | 3000.000000 | 3000.00 |
| 20 | CLERK | 950.000000 | 800.00 |
| 20 | MANAGER | 2975.000000 | 2975.00 |
| 30 | CLERK | 950.000000 | 950.00 |
| 30 | MANAGER | 2850.000000 | 2850.00 |
| 30 | SALESMAN | 1400.000000 | 1250.00 |
+--------+-----------+--------------+--------------+
9 rows in set (0.00 sec)
注意事项:在group by之后出现的字段是可以在select 之后出现的,还有聚合函数,正常分组出现的字段在聚合条件中可以输出,其他会报错
select ename,deptno,job,avg(sal)平均,min(sal) 最低 from emp group by deptno,job;
上面的代码因为分组条件中没有用到ename 所以报错
- 显示平均工资低于2000的部门和它的平均工资
mysql> select deptno,avg(sal) deptavg from emp group by deptno having deptavg<2000;
+--------+-------------+
| deptno | deptavg |
+--------+-------------+
| 30 | 1566.666667 |
+--------+-------------+
1 row in set (0.00 sec)
- 除SMITH外,显示平均工资低于2000的每个部门的每种岗位的和它的平均工资
mysql> select deptno,job,avg(sal) deptavg from emp where ename!='SMITH' group by deptno,job having deptavg<2000;
+--------+----------+-------------+
| deptno | job | deptavg |
+--------+----------+-------------+
| 10 | CLERK | 1300.000000 |
| 20 | CLERK | 1100.000000 |
| 30 | CLERK | 950.000000 |
| 30 | SALESMAN | 1400.000000 |
+--------+----------+-------------+
4 rows in set (0.00 sec)
四、SQL查询的执行顺序
SQL查询中各个关键字的执行先后顺序 :from > on> join > where > group by > with > having > select>distinct > order by > limit
五、OJ练习
1.批量插入数据
答案:
insert into actor values(1,'PENELOPE','GUINESS','2006-02-15 12:34:33'),(2,'NICK','WAHLBERG','2006-02-15 12:34:33');
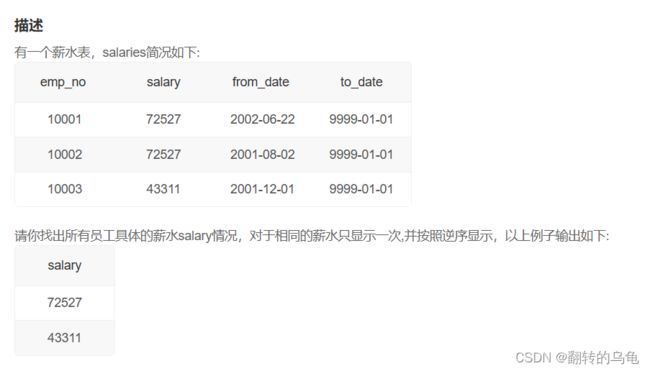
2.找出所有员工薪水情况
答案:
select distinct salary from salaries order by salary desc;
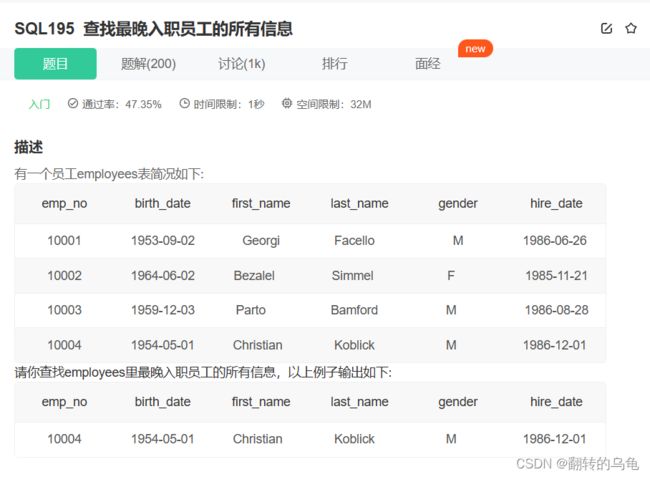
3.查找最晚入职员工的所有信息
答案:
select * from employees order by hire_date desc limit 1;
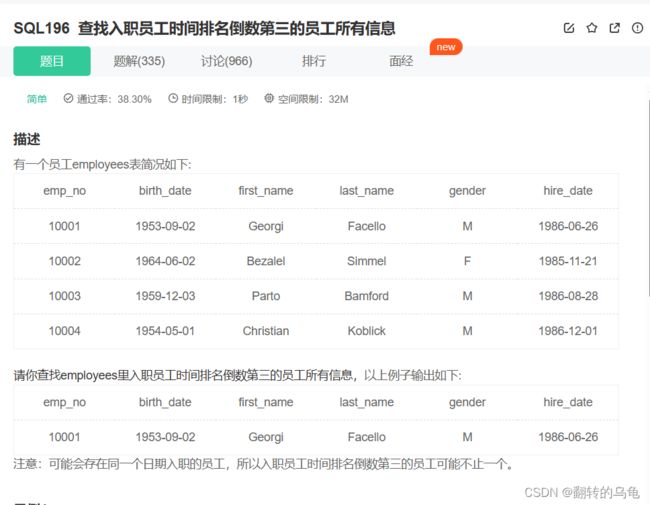
4.查找入职员工时间排名倒数第三的员工所有信息
答案:
select * from employees where hire_date=(select distinct hire_date from employees order by hire_date desc limit 2,1);
5.查找薪水记录超过15条的员工号emp_no以及其对应的记录次数t
分组+聚合函数
答案:
select emp_no,count(*) t from salaries group by emp_no having t>15;

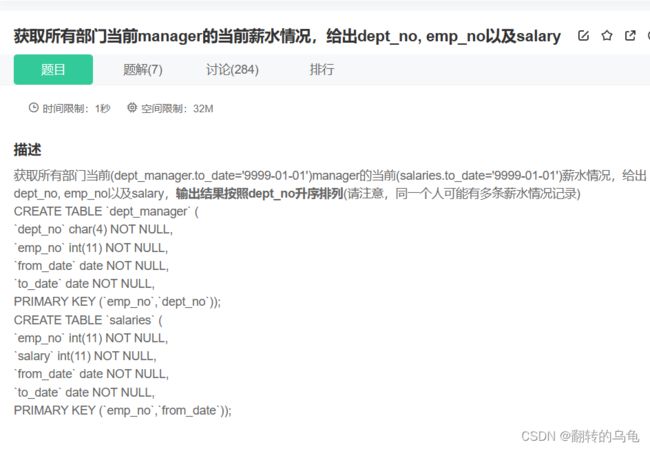
6.获取所有部门薪水
答案:
SELECT dm.dept_no, dm.emp_no, s.salary
FROM dept_manager dm
JOIN salaries s ON dm.emp_no = s.emp_no
WHERE dm.to_date = '9999-01-01' AND s.to_date = '9999-01-01'
ORDER BY dm.dept_no ASC;
--或者
SELECT
dm.dept_no,
dm.emp_no,
(
SELECT s.salary
FROM salaries s
WHERE s.emp_no = dm.emp_no
AND s.to_date = '9999-01-01'
LIMIT 1
) AS salary
FROM
dept_manager dm
WHERE
dm.to_date = '9999-01-01'
ORDER BY
dm.dept_no ASC;
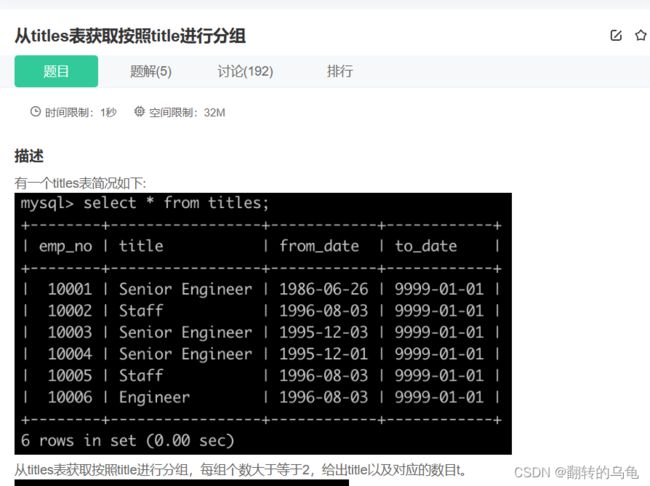
7.从titles表获取按照title进行分组
答案:
select title,count(title) t from titles group by title having t>=2;
8.查找重复数据
答案
select email from Person group by email having count(email)>1;
9.查找大国
select name,population,area from World where area>=3000000 or population>=25000000;
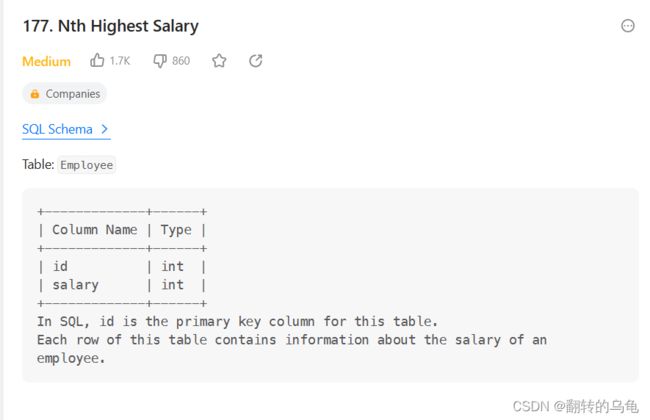
10.给定一个Employee表,要找出其中第N高的薪资(Salary)
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
SET N = N - 1;
RETURN (
select distinct(Salary) as getNthHighestSalary
from Employee
GROUP BY Salary
ORDER BY Salary DESC
limit 1 offset N
);
END