HDFS之存储优化纠删码原理、纠删码案例实操 、异构存储(冷热数据分离)
1、纠删码原理
HDFS默认情况下,一个文件有3个副本,这样提高了数据的可靠性,但也带来了2倍的冗余开销。Hadoop3.x引入了纠删码,采用计算的方式,可以节省约50%左右的存储空间。
1.2、纠删码操作相关的命令
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs ec Usage: bin/hdfs ec [COMMAND] [-listPolicies] [-addPolicies -policyFile] [-getPolicy -path ] [-removePolicy -policy ] [-setPolicy -path [-policy ] [-replicate]] [-unsetPolicy -path ] [-listCodecs] [-enablePolicy -policy ] [-disablePolicy -policy ] [-help ]. 1.3、查看当前支持的纠删码策略
[atguigu@hadoop102 hadoop-3.1.3] hdfs ec -listPolicies Erasure Coding Policies: ErasureCodingPolicy=[Name=RS-10-4-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=10, numParityUnits=4]], CellSize=1048576, Id=5], State=DISABLED ErasureCodingPolicy=[Name=RS-3-2-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=3, numParityUnits=2]], CellSize=1048576, Id=2], State=DISABLED ErasureCodingPolicy=[Name=RS-6-3-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=1], State=ENABLED ErasureCodingPolicy=[Name=RS-LEGACY-6-3-1024k, Schema=[ECSchema=[Codec=rs-legacy, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=3], State=DISABLED ErasureCodingPolicy=[Name=XOR-2-1-1024k, Schema=[ECSchema=[Codec=xor, numDataUnits=2, numParityUnits=1]], CellSize=1048576, Id=4], State=DISABLED1.4、纠删码策略解释:
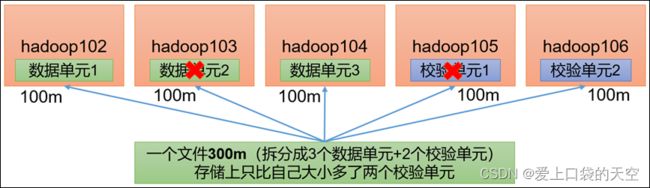
RS-3-2-1024k:使用RS编码,每3个数据单元,生成2个校验单元,共5个单元,也就是说:这5个单元中,只要有任意的3个单元存在(不管是数据单元还是校验单元,只要总数=3),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
RS-10-4-1024k:使用RS编码,每10个数据单元(cell),生成4个校验单元,共14个单元,也就是说:这14个单元中,只要有任意的10个单元存在(不管是数据单元还是校验单元,只要总数=10),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
RS-6-3-1024k:使用RS编码,每6个数据单元,生成3个校验单元,共9个单元,也就是说:这9个单元中,只要有任意的6个单元存在(不管是数据单元还是校验单元,只要总数=6),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
RS-LEGACY-6-3-1024k:策略和上面的RS-6-3-1024k一样,只是编码的算法用的是rs-legacy。
XOR-2-1-1024k:使用XOR编码(速度比RS编码快),每2个数据单元,生成1个校验单元,共3个单元,也就是说:这3个单元中,只要有任意的2个单元存在(不管是数据单元还是校验单元,只要总数= 2),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。

2、纠删码案例实操
纠删码策略是给具体一个路径设置。所有往此路径下存储的文件,都会执行此策略。
默认只开启对RS-6-3-1024k策略的支持,如要使用别的策略需要提前启用。
1)需求:将/input目录设置为RS-3-2-1024k策略
2)具体步骤
(1)开启对RS-3-2-1024k策略的支持
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs ec -enablePolicy -policy RS-3-2-1024k Erasure coding policy RS-3-2-1024k is enabled(2)在HDFS创建目录,并设置RS-3-2-1024k策略
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfs -mkdir /input [atguigu@hadoop202 hadoop-3.1.3]$ hdfs ec -setPolicy -path /input -policy RS-3-2-1024k(3)上传文件,并查看文件编码后的存储情况
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfs -put web.log /input注:你所上传的文件需要大于2M才能看出效果。(低于2M,只有一个数据单元和两个校验单元)
(4)查看存储路径的数据单元和校验单元,并作破坏实验

3、异构存储(冷热数据分离)
异构存储主要解决,不同的数据,存储在不同类型的硬盘中,达到最佳性能的问题。
3.1、存储类型和存储策略
3.2、异构存储Shell操作
(1)查看当前有哪些存储策略可以用
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -listPolicies(2)为指定路径(数据存储目录)设置指定的存储策略
hdfs storagepolicies -setStoragePolicy -path xxx -policy xxx(3)获取指定路径(数据存储目录或文件)的存储策略
hdfs storagepolicies -getStoragePolicy -path xxx(4)取消存储策略;执行改命令之后该目录或者文件,以其上级的目录为准,如果是根目录,那么就是HOT
hdfs storagepolicies -unsetStoragePolicy -path xxx(5)查看文件块的分布
bin/hdfs fsck xxx -files -blocks -locations(6)查看集群节点
hadoop dfsadmin -report3.3、测试环境准备
1)测试环境描述
服务器规模:5台
集群配置:副本数为2,创建好带有存储类型的目录(提前创建)
集群规划:
2)配置文件信息
(1)为hadoop102节点的hdfs-site.xml添加如下信息
dfs.replication 2 dfs.storage.policy.enabled true dfs.datanode.data.dir [SSD]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[RAM_DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/ram_disk (2)为hadoop103节点的hdfs-site.xml添加如下信息
dfs.replication 2 dfs.storage.policy.enabled true dfs.datanode.data.dir [SSD]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/disk (3)为hadoop104节点的hdfs-site.xml添加如下信息
dfs.replication 2 dfs.storage.policy.enabled true dfs.datanode.data.dir [RAM_DISK]file:///opt/module/hdfsdata/ram_disk,[DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/disk (4)为hadoop105节点的hdfs-site.xml添加如下信息
dfs.replication 2 dfs.storage.policy.enabled true dfs.datanode.data.dir [ARCHIVE]file:///opt/module/hadoop-3.1.3/hdfsdata/archive (5)为hadoop106节点的hdfs-site.xml添加如下信息
dfs.replication 2 dfs.storage.policy.enabled true dfs.datanode.data.dir [ARCHIVE]file:///opt/module/hadoop-3.1.3/hdfsdata/archive 3)数据准备
(1)启动集群
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs namenode -format [atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh start(2)并在HDFS上创建文件目录
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /hdfsdata(3)并将文件资料上传
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/NOTICE.txt /hdfsdata3.4、HOT存储策略案例
(1)最开始我们未设置存储策略的情况下,我们获取该目录的存储策略
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -getStoragePolicy -path /hdfsdata(2)我们查看上传的文件块分布
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]未设置存储策略,所有文件块都存储在DISK下。所以,默认存储策略为HOT
3.5、WARM存储策略测试
(1)接下来我们为数据降温
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy WARM(2)再次查看文件块分布,我们可以看到文件块依然放在原处。
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations
(3)我们需要让他HDFS按照存储策略自行移动文件块
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata(4)再次查看文件块分布
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.105:9866,DS-d46d08e1-80c6-4fca-b0a2-4a3dd7ec7459,ARCHIVE], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]文件块一半在DISK,一半在ARCHIVE,符合我们设置的WARM策略
3.6、COLD策略测试
(1)我们继续将数据降温为cold
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy COLD注意:当我们将目录设置为COLD并且我们未配置ARCHIVE存储目录的情况下,不可以向该目录直接上传文件,会报出异常。
(2)手动转移
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata(3)检查文件块的分布
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.105:9866,DS-d46d08e1-80c6-4fca-b0a2-4a3dd7ec7459,ARCHIVE], DatanodeInfoWithStorage[192.168.10.106:9866,DS-827b3f8b-84d7-47c6-8a14-0166096f919d,ARCHIVE]]所有文件块都在ARCHIVE,符合COLD存储策略。
3.6、ONE_SSD策略测试
(1)接下来我们将存储策略从默认的HOT更改为One_SSD
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy One_SSD(2)手动转移文件块
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata(3)转移完成后,我们查看文件块分布,
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2481a204-59dd-46c0-9f87-ec4647ad429a,SSD]]文件块分布为一半在SSD,一半在DISK,符合One_SSD存储策略。
3.7、ALL_SSD策略测试
(1)接下来,我们再将存储策略更改为All_SSD
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy All_SSD(2)手动转移文件块
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata(3)查看文件块分布,我们可以看到,
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.102:9866,DS-c997cfb4-16dc-4e69-a0c4-9411a1b0c1eb,SSD], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2481a204-59dd-46c0-9f87-ec4647ad429a,SSD]]所有的文件块都存储在SSD,符合All_SSD存储策略。
3.8、LAZY_PERSIST策略测试
(1)继续改变策略,将存储策略改为lazy_persist
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy lazy_persist(2)手动转移文件块
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata(3)查看文件块分布
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]这里我们发现所有的文件块都是存储在DISK,按照理论一个副本存储在RAM_DISK,其他副本存储在DISK中,这是因为,我们还需要配置“dfs.datanode.max.locked.memory”,“dfs.block.size”参数。
那么出现存储策略为LAZY_PERSIST时,文件块副本都存储在DISK上的原因有如下两点:
(1)当客户端所在的DataNode节点没有RAM_DISK时,则会写入客户端所在的DataNode节点的DISK磁盘,其余副本会写入其他节点的DISK磁盘。
(2)当客户端所在的DataNode有RAM_DISK,但“dfs.datanode.max.locked.memory”参数值未设置或者设置过小(小于“dfs.block.size”参数值)时,则会写入客户端所在的DataNode节点的DISK磁盘,其余副本会写入其他节点的DISK磁盘。
但是由于虚拟机的“max locked memory”为64KB,所以,如果参数配置过大,还会报出错误:
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain java.lang.RuntimeException: Cannot start datanode because the configured max locked memory size (dfs.datanode.max.locked.memory) of 209715200 bytes is more than the datanode's available RLIMIT_MEMLOCK ulimit of 65536 bytes.我们可以通过该命令查询此参数的内存
[atguigu@hadoop102 hadoop-3.1.3]$ ulimit -a max locked memory (kbytes, -l) 64


